
কীভাবে গুণগত ডেটা বিশ্লেষণ করতে হয় তা জানার উপায় খুঁজছি এক্সেল-এ ? তাহলে এটি আপনার জন্য সঠিক নিবন্ধ। যখন ডেটা গণনা করা যায় না এবং সংখ্যাসূচক মান ব্যবহার করে ব্যাখ্যা করা কঠিন, তারপর ডেটা গুণগত . আমরা এটি গুণগত সংগ্রহ করতে পারি ডেটা ফোকাস গ্রুপ আলোচনা থেকে, গভীর ইন্টারভিউ, বাক্য সমাপ্তি, শব্দ সংঘ, নৈমিত্তিক কথোপকথন ইত্যাদি।
এক্সেলে গুণগত ডেটা বিশ্লেষণের 8 ধাপ
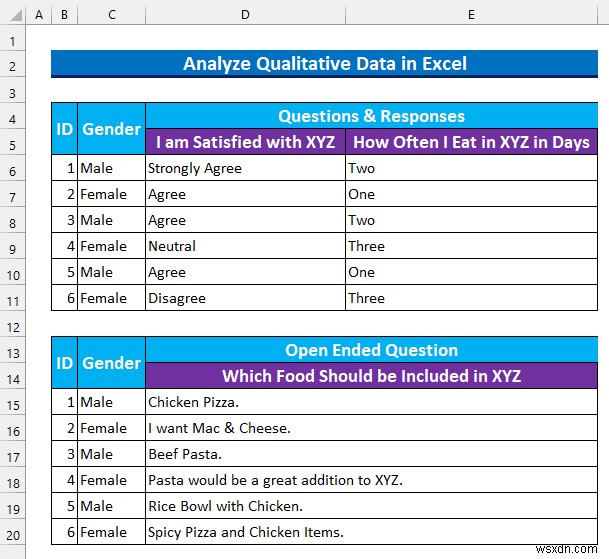
আমরা আমাদের পন্থা প্রদর্শনের জন্য একটি সমীক্ষা প্রশ্নাবলী থেকে তিনটি উত্তর নিয়েছি৷ এখানে, XYZ একটি ক্যাফে একটি শহরের শেষে এবং ছাত্ররা মাঝে মাঝে সেখানে আড্ডা দেয়। তিনটি প্রশ্ন নিম্নরূপ:
- প্রথমত, একটি লাইকার্ট স্কেল প্রশ্ন “আমিXYZ নিয়ে সন্তুষ্ট ” এই প্রশ্নের উত্তর দেওয়ার জন্য 5টি স্তর রয়েছে৷
- পরবর্তী, একটি বহু-পছন্দের প্রশ্ন “আমি কত ঘন ঘন XYZ এ খাই দিনের মধ্যে"। অংশগ্রহণকারীরা 3 এর মধ্যে একটি বেছে নিতে পারেন৷ বিকল্প।
- অবশেষে, একটি উন্মুক্ত প্রশ্ন:“কোন খাবারXYZ-এ অন্তর্ভুক্ত করা উচিত ” যেকোন দৈর্ঘ্যের পাঠ্য এখানে গ্রহণযোগ্য।
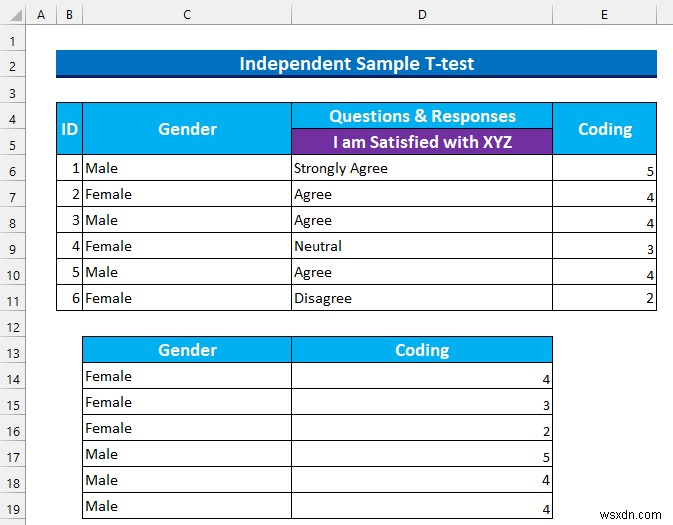
সাধারণত, আমাদের ডেটাসেটে আছে 3 কলাম:“ID ”, “লিঙ্গ ”, এবং “প্রশ্নগুলি৷ & প্রতিক্রিয়া ” তদুপরি, নীচের স্ন্যাপশটে, তিনটি প্রশ্ন একটি কম্প্যাক্ট কাঠামোতে দেখানো হয়েছে। আমরা আলোচনা করব কিভাবে প্রতিটি প্রকার থেকে তথ্য লাভ করা যায়।
পদক্ষেপ 1:এক্সেলে বিশ্লেষণ করার জন্য কোড এবং গুণগত ডেটা সাজান
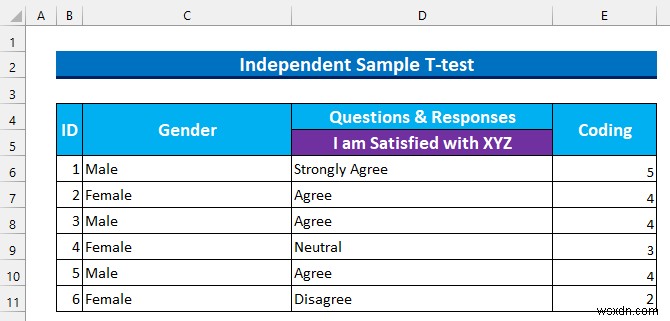
আমরা গুণগত ডেটা রূপান্তর করব কোড ব্যবহার করে সংখ্যাসূচক মানগুলিতে। তারপর, আমরা ডেটা সাজাব পরবর্তী ধাপের জন্য প্রস্তুত করতে। আমাদের লাইকার্ট স্কেল আছে 5 স্তর, তাই মান এই মত হবে:
- পুরোপুরি একমত -> 5 .
- সম্মত -> 4 .
- নিরপেক্ষ -> 3 .
- অসম্মতি -> 2 .
- পুরোপুরি দ্বিমত -> 1 .
- সুতরাং, আমরা সেল পরিসরে মান ইনপুট করতে এটি ব্যবহার করি E6:E11 .
- তারপর, আমরা “লিঙ্গ আলাদা করি ” এবং “কোডিং ” বিভিন্ন কক্ষের পরিসরে কলাম।
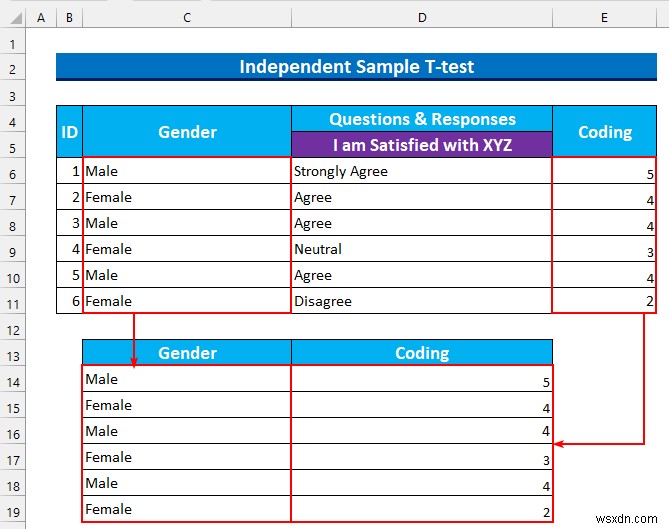
- পরে, সেল রেঞ্জ নির্বাচন করুন C14:D19 এবং প্রসঙ্গ মেনু আনতে ডান-ক্লিক করুন .
- পরে, সাজানো থেকে >>> "A থেকে Z সাজান নির্বাচন করুন৷ ”।
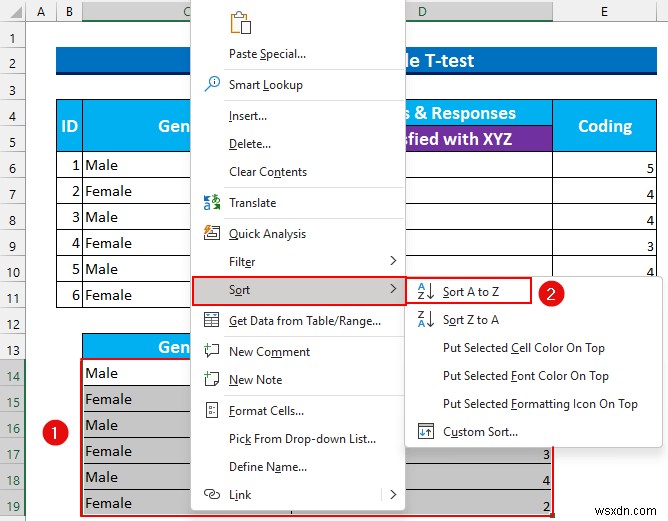
- অতএব, একই লিঙ্গের জন্য আমাদের মান একসাথে থাকবে।
আরো পড়ুন:এক্সেলে ডেটা বিশ্লেষণ কীভাবে ব্যবহার করবেন (৫টি সহজ পদ্ধতি)
ধাপ 2:বিশ্লেষণ টুলপ্যাক সক্ষম করুন
আমাদের ডেটা বিশ্লেষণ সক্ষম করতে হবে এক্সেল -এ বৈশিষ্ট্য কোনো পরিসংখ্যানগত পরীক্ষা করার আগে।
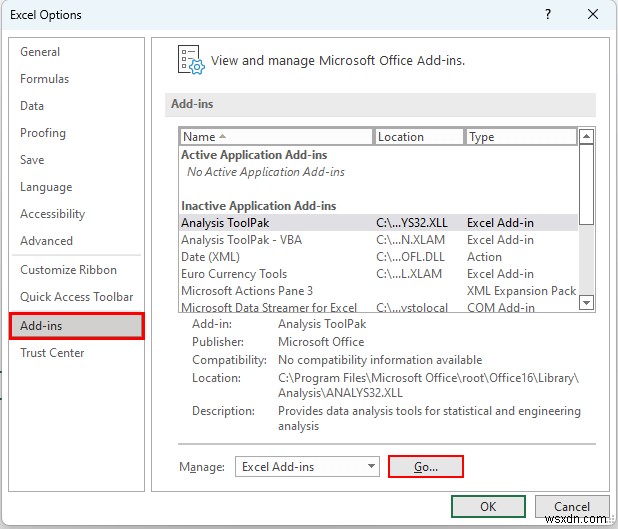
- শুরু করতে, ALT টিপুন , F , তারপর T এক্সেল বিকল্পগুলি আনতে উইন্ডো।
- তারপর, অ্যাড-ইনস থেকে >>> “যাও… নির্বাচন করুন ”।
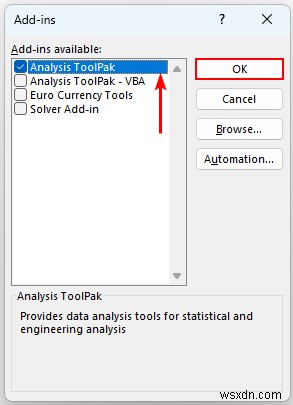
- তাই, অ্যাড-ইন ডায়ালগ বক্স পপ আপ হবে।
- পরে, “বিশ্লেষণ টুলপ্যাক নির্বাচন করুন ” এবং ঠিক আছে টিপুন .
- অবশেষে, আমরা ডেটা বিশ্লেষণ দেখতে পাব ডেটা-এর ভিতরে কমান্ড ট্যাব।
আরো পড়ুন:[স্থির:] ডেটা বিশ্লেষণ এক্সেলে দেখানো হচ্ছে না (2 কার্যকরী সমাধান)
পদক্ষেপ 3:গুণগত ডেটার সাথে মানে তুলনা করার জন্য T-পরীক্ষা
আমরা “টু-স্যাম্পল টি-টেস্ট ব্যবহার করব ”, যা “স্বতন্ত্র নমুনা টি-পরীক্ষা নামেও পরিচিত গুণগত ডেটা বিশ্লেষণ করতে . আমাদের দুটি অনুমান বা অনুমান আছে:
নাল হাইপোথিসিস H 0 : “দুটি দলXYZ নিয়ে সমানভাবে সন্তুষ্ট৷ ”।
বিকল্প হাইপোথিসিস H a : “দুটি দলXYZ নিয়ে সমানভাবে সন্তুষ্ট নয় ”।
যদি আমরা আমাদের p-value খুঁজে পাই 0.05 থেকে কম তাহলে আমরা শূন্য হাইপোথিসিস প্রত্যাখ্যান করতে ব্যর্থ হব . অন্যথায়, আমরা শূন্য হাইপোথিসিস প্রত্যাখ্যান করব .
- শেষ ধাপে, আমরা বিশ্লেষণ টুলপ্যাক সক্ষম করেছি . এটি বিশ্লেষণ এর অধীনে প্রদর্শিত হবে৷ বিভাগ।
- তারপর, “ডেটা অ্যানালাইসিস-এ ক্লিক করুন ”।
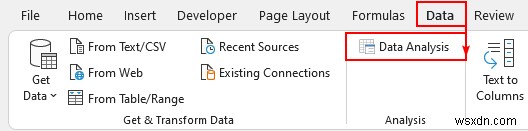
- এরপর, "t-পরীক্ষা:অসম বৈচিত্র্য অনুমান করা দুই-নমুনা নির্বাচন করুন ” এবং ঠিক আছে টিপুন .
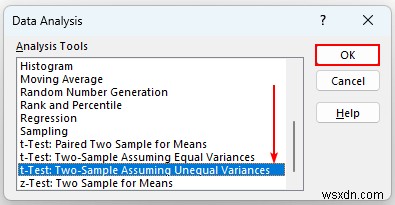
- পরে, একটি ডায়ালগ বক্স প্রদর্শিত হবে. এই বিকল্পগুলি নির্বাচন করুন:
- ভেরিয়েবল 1 রেঞ্জ – D14:D16 .
- ভেরিয়েবল ২ রেঞ্জ – D17:D19 .
- আমরা এটিও অদলবদল করতে পারি, নির্বিশেষে আউটপুট একই হবে।
- এর পর, “আউটপুট রেঞ্জ নির্বাচন করুন ” এবং সেল C21 আউটপুট অবস্থান হিসাবে।
- তারপর, ঠিক আছে টিপুন .
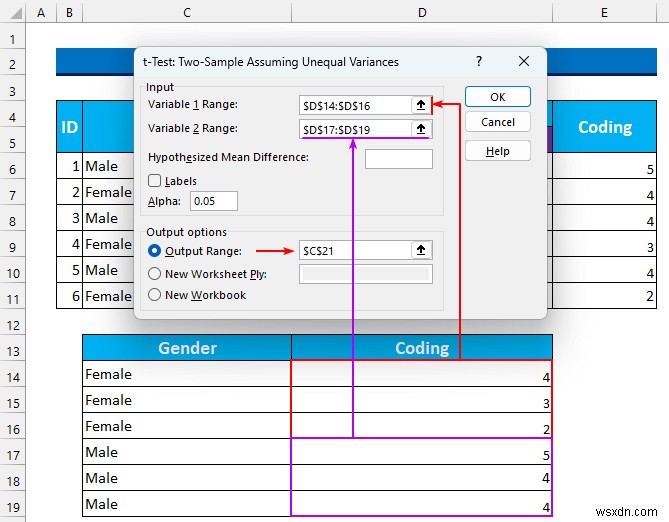
- সুতরাং, আউটপুট এরকম হবে।
- এরপর, আমরা দেখতে পাচ্ছি গড় হল 3 এবং 4.33 . এই পার্থক্যটি তাৎপর্যপূর্ণ নাকি p-value ব্যবহার করে নয় তা আমরা পরীক্ষা করব . উপরন্তু, বৈচিত্রগুলি হল 1 এবং 0.33 , তাই অসম বৈচিত্রের আমাদের অনুমান সঠিক ছিল। যদি এই মানটি প্রায় অভিন্ন হয় তবে আপনাকে এটিকে "t-টেস্ট:দুই-নমুনা অনুমান সমান বৈচিত্র্য এ পরিবর্তন করতে হবে ”।
- অতএব, আমাদের P(T<=t) টু-টেইলে মনোনিবেশ করতে হবে মান শুধুমাত্র। এটি 0.05 থেকে কম হওয়া দরকার তাৎপর্যপূর্ণ হতে যেমনটি (0.14 যদি আমরা রাউন্ড আপ করি) 0.05 এর চেয়ে বেশি , তাই, আমরা শূন্য অনুমানকে প্রত্যাখ্যান করি .
- সুতরাং, বিশ্লেষণ থেকে, আমরা বলতে পারি যে পুরুষ এবং মহিলাদের মধ্যে সন্তুষ্টির বিভিন্ন স্তর রয়েছে ক্যাফে XYZ , যা পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ .

পদক্ষেপ 4:চি-স্কয়ার টেস্টের জন্য ক্যাটাগরিক্যাল ডেটাসেট প্রস্তুত করুন
আমরা SUM ব্যবহার করব৷ এবং COUNTIFS এই ধাপে ফাংশন। এখন, আমরা দ্বিতীয় প্রশ্নের বিশ্লেষণ নিয়ে আলোচনা করব। আমরা চি-স্কোয়ার ব্যবহার করি পরীক্ষা দুটি শ্রেণীবদ্ধ তথ্যের মধ্যে সম্পর্ক খুঁজে বের করতে। উপরন্তু, এটি প্রত্যাশিত এবং পর্যবেক্ষিত মানগুলির মধ্যে একটি পার্থক্য ফিরিয়ে দিতে পারে। XYZ ক্যাফেতে খাওয়ার সময় এবং লিঙ্গের মধ্যে কোন সম্পর্ক আছে কিনা তা আমরা খুঁজে পেতে চাই। .
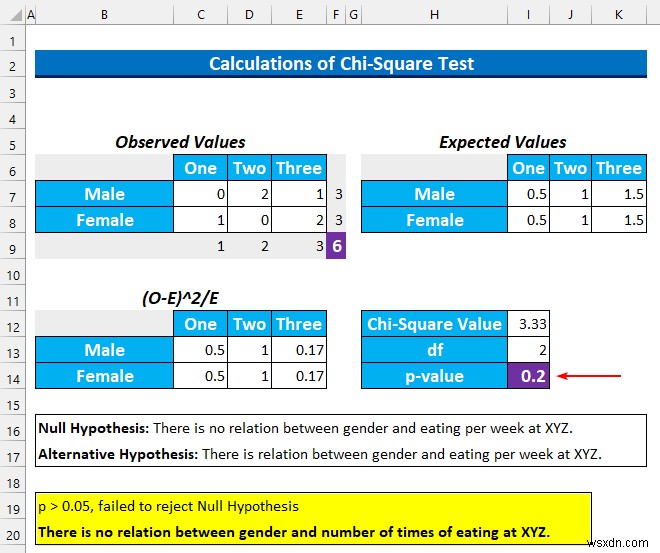
নাল হাইপোথিসিস H 0 : “XYZ-এ প্রতি সপ্তাহে লিঙ্গ এবং খাওয়ার মধ্যে কোনও সম্পর্ক নেই৷ ”।
বিকল্প হাইপোথিসিস H a : “XYZ-এ প্রতি সপ্তাহে লিঙ্গ এবং খাওয়ার মধ্যে সম্পর্ক রয়েছে৷ ”।
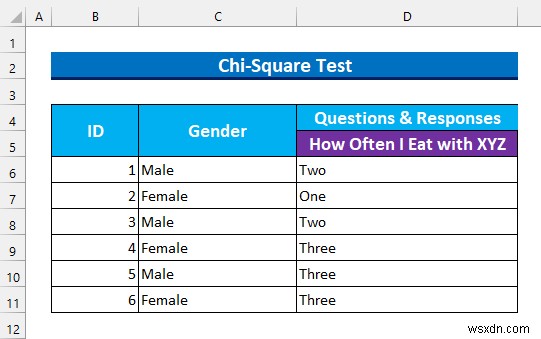
- প্রথমে, আমরা রেঞ্জের নাম দেব C6:C11 হিসাবে “লিঙ্গ ” এবং D6:D11 হিসাবে “টাইমস ”।
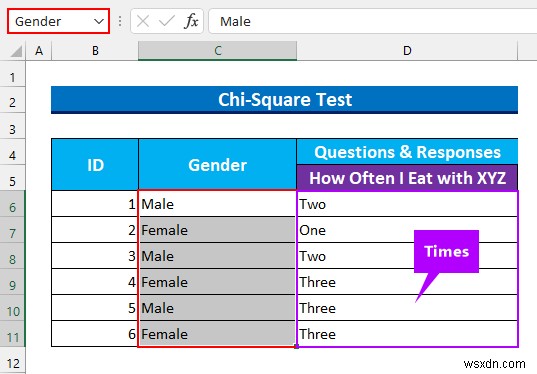
- এরপর, আমরা চি-স্কোয়ার গণনা করার জন্য একটি টেমপ্লেট তৈরি করব মান।
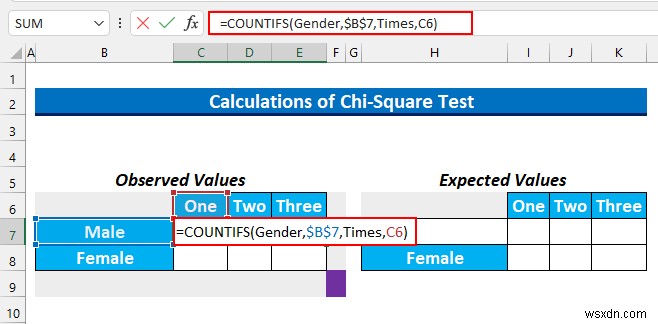
- তারপর, আমরা সেল রেঞ্জ C7:E7 নির্বাচন করব এবং নিম্নলিখিত সূত্র টাইপ করুন।
=COUNTIFS(Gender,$B$7,Times,C6)
এই সূত্রটি পুরুষ এবং এক সহ কোষের সংখ্যা খুঁজে পায় ক্যাফে XYZ-এ প্রতি সপ্তাহে খাওয়ার সময় .
- এরপর, CTRL+ENTER টিপুন . এটি সূত্রটি স্বয়ংক্রিয়ভাবে পূরণ করবে .
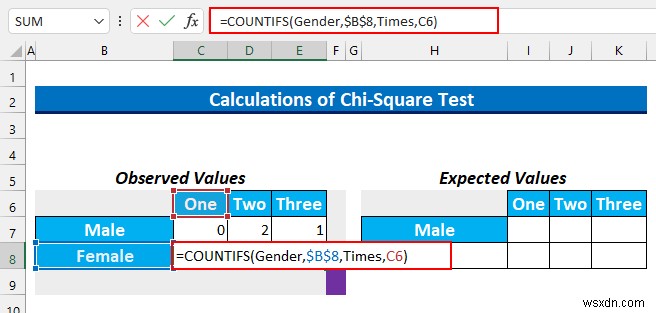
- এর পরে, আমরা সেল রেঞ্জ নির্বাচন করব C8:E8 এবং নিম্নলিখিত সূত্র টাইপ করুন।
=COUNTIFS(Gender,$B$8,Times,C6)
এই সূত্রটি স্ত্রী এবং একটি ধারণকারী কোষের সংখ্যা খুঁজে বের করে ক্যাফে XYZ-এ প্রতি সপ্তাহে খাওয়ার সময় .
- তারপর, CTRL+ENTER টিপুন .
- পরে, আমরা সারি এবং কলাম যোগ করব।
- সেল পরিসর নির্বাচন করুন C9:E9 এবং এই সূত্রটি টাইপ করুন।
=SUM(C7:C8)
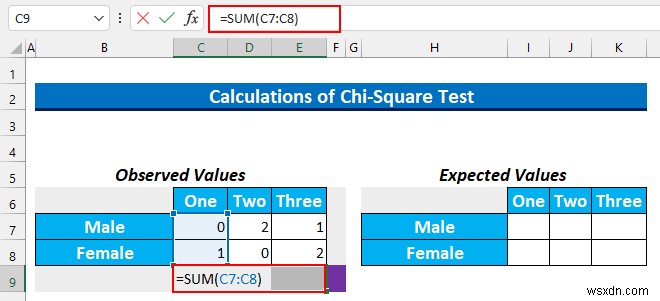
- CTRL+ENTER টিপুন .
- তারপর, সেল রেঞ্জটি নির্বাচন করুন F7:F8 এবং এই সূত্রটি টাইপ করুন।
=SUM(C7:E7)
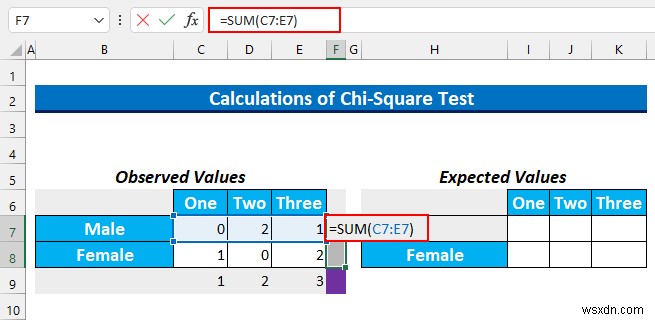
- CTRL+ENTER টিপুন .
- তারপর, আমরা 6 টাইপ করব কক্ষে F9 যেহেতু উত্তরদাতাদের সংখ্যা ছিল 6 .
- এখন, আমরা প্রত্যাশিত মানগুলি খুঁজে পাব। এটি খুঁজতে, সূত্রটি হল সারি মোট * কলাম মোট/মোট .
- এর পর, সেল রেঞ্জে এই সূত্রটি টাইপ করুন I7:K7 আগে থেকে নির্বাচন করে।
=$F$7*C9/$F$9
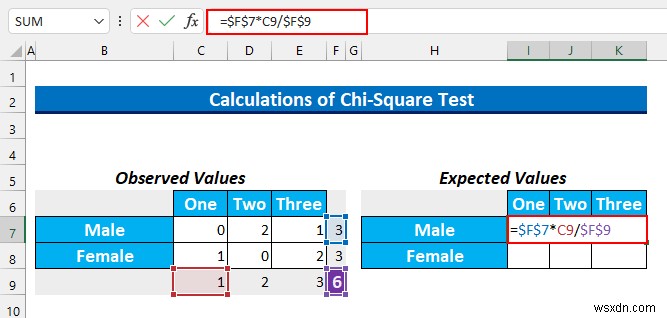
- CTRL+ENTER টিপুন .
- তারপর, সেল রেঞ্জ I8:K8 নির্বাচন করুন এবং এই সূত্রটি টাইপ করুন।
=$F$8*C9/$F$9
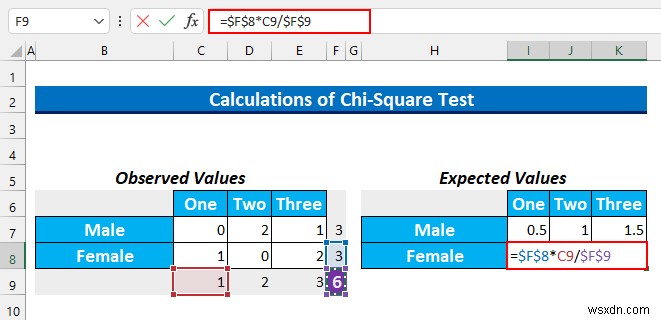
- এর পর, CTRL+ENTER টিপুন .
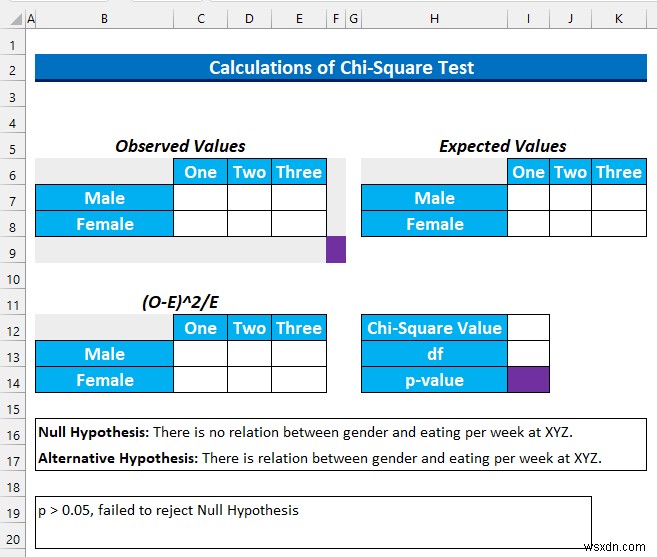
- এখন, আমরা খুঁজে পাব চি-স্কোয়ার্ড মান।
- সুতরাং, সেল পরিসরটি নির্বাচন করুন C13:E14 এবং নিম্নলিখিত সূত্র টাইপ করুন।
=(C7-I7)^2/I7
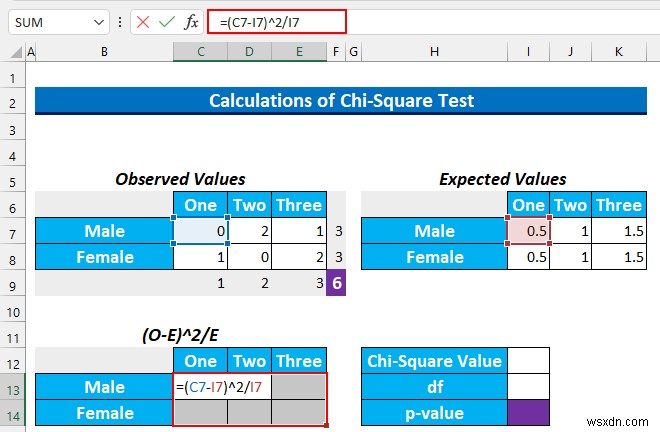
- এর পর, CTRL+ENTER টিপুন .
- তারপর, আমরা I12 কক্ষে এই মানগুলি যোগ করব এই সূত্রটি টাইপ করে।
=SUM(C13:E14)
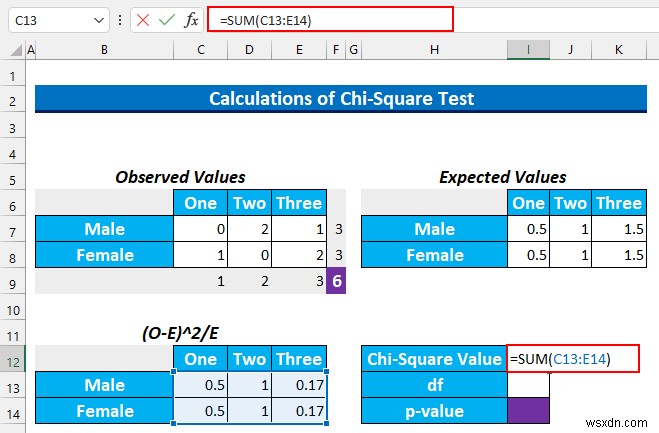
- পরে, ENTER টিপুন .
- এখন, df মানে স্বাধীনতার ডিগ্রি . এটি খুঁজে পাওয়ার সূত্রটি হল (কলামের সংখ্যা -1) * (সারির সংখ্যা -1) ব্যবহার করা . আমাদের 2 আছে সারি এবং 3 কলাম. অতএব, আমাদের df (3-1)*(2-1) =2 হবে৷ .
আরো পড়ুন:কিভাবে এক্সেলে বড় ডেটা সেট বিশ্লেষণ করবেন (6 কার্যকরী পদ্ধতি)
একই রকম পড়া
- এক্সেলে বিক্রয় ডেটা কীভাবে বিশ্লেষণ করবেন (10টি সহজ উপায়)
- পিভট টেবিল ব্যবহার করে এক্সেলে ডেটা বিশ্লেষণ করুন (9টি উপযুক্ত উদাহরণ)
- এক্সেলে টাইম-স্কেল করা ডেটা কীভাবে বিশ্লেষণ করবেন (সহজ পদক্ষেপ সহ)
ধাপ 5:চি-স্কয়ার টেস্টের মাধ্যমে এক্সেলে শ্রেণীগত গুণগত ডেটা বিশ্লেষণ করুন
আমরা CHISQ.DIST.RT ব্যবহার করব p-মান খুঁজতে এই পরীক্ষার জন্য।
- সুতরাং, এই সূত্রটি সেলে I14 টাইপ করুন .
=CHISQ.DIST.RT(I12,I13)
এই ফাংশনটি "চি-স্কোয়ার্ড ডিস্ট্রিবিউশনের ডান-টেইল্ড সম্ভাব্যতা" প্রদান করে।
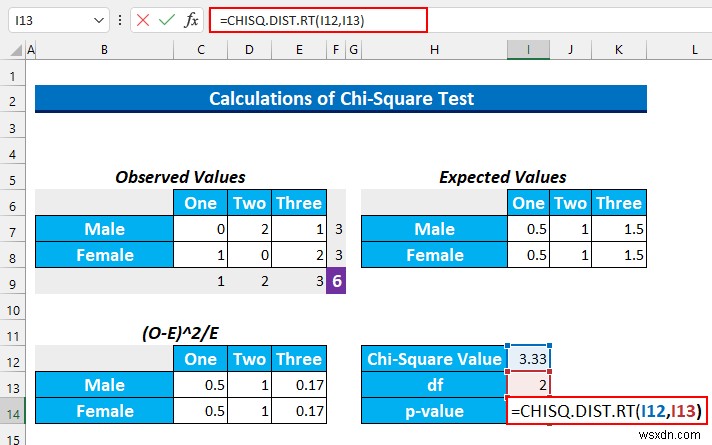
- এর পর, ENTER টিপুন . আমরা 0.2 এর মান পাব যা 0.05 থেকে বড় . সুতরাং, আমরা শূন্য অনুমানকে প্রত্যাখ্যান করতে ব্যর্থ হব . সহজ ভাষায়, আমরা বলতে পারি যে দুটি বিভাগের মধ্যে কোনো সম্পর্ক নেই।
পদক্ষেপ 6:ওপেন-এন্ডেড কোয়ালিটেটিভ ডেটার জন্য অনুভূতি বিশ্লেষণ
এখন, আমরা আমাদের শেষ প্রশ্ন এবং উত্তরগুলি দেখব৷ আমরা প্রতিক্রিয়াগুলির থিমগুলি খুঁজে বের করার জন্য ম্যানুয়াল প্রক্রিয়া ব্যবহার করব৷ আমরা ডেটাসেটে দুটি কলাম যোগ করেছি:“বিষয়1 ” এবং “বিষয়2 ”।

- তারপর, আমরা প্রতিক্রিয়াগুলি পড়ব এবং তাদের সাথে খাবারের বিষয় সংযুক্ত করব। যেমন, “চিকেন পিজ্জা ” আছে 2 বিষয়:“মুরগি ” এবং “পিজা ” ইত্যাদি।
- এর পর, আমরা শুধুমাত্র একটি নতুন টেবিলে অনন্য বিষয় যোগ করেছি।
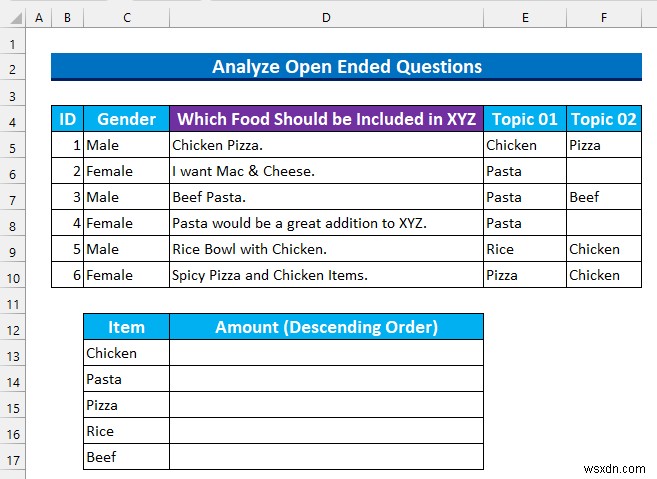
পদক্ষেপ 7:ওপেন-এন্ডেড গুণগত ডেটা বিশ্লেষণ করতে COUNTIF ফাংশন ব্যবহার করুন
আমরা COUNTIF ফাংশন ব্যবহার করব ফ্রিকোয়েন্সি ডিস্ট্রিবিউশনের অন্তর্দৃষ্টি পেতে।
- প্রথমে, সেল রেঞ্জ নির্বাচন করুন D13:D17 এবং নিম্নলিখিত সূত্র টাইপ করুন।
=COUNTIF($E$5:$F$10,C13)
এই সূত্রটি F5:F10 পরিসরে মানের সংখ্যা গণনা করে যে সেল C13 থেকে একটি মান আছে .
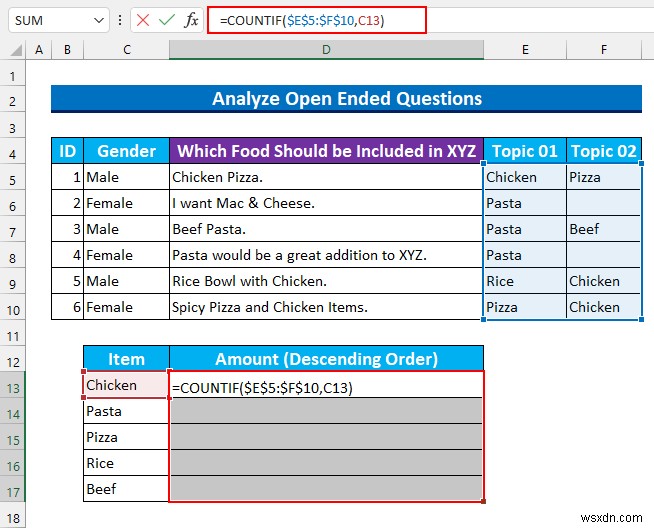
- পরে, অটোফিল করতে সূত্র, CTRL+ENTER টিপুন .
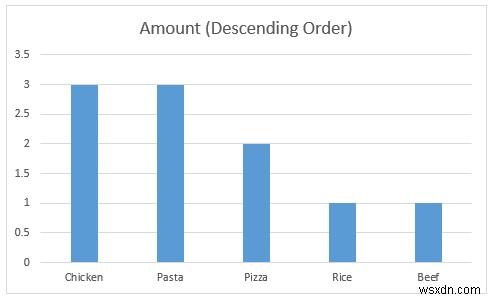
- এরপর, আমরা একটি চার্ট সন্নিবেশ করব ফ্রিকোয়েন্সি বন্টন কল্পনা করতে।
ধাপ 8:ওপেন-এন্ডেড কোয়ালিটেটিভ ডেটা ভিজ্যুয়ালাইজ করার জন্য ক্লাস্টারড কলাম চার্ট
এই ধাপে, আমরা একটি ক্লাস্টারড কলাম চার্ট তৈরি করব গুণগত ডেটা বুঝতে আরো স্পষ্টভাবে।
- সুতরাং, সেল রেঞ্জটি নির্বাচন করুন C12:D17 এবং সন্নিবেশ ট্যাব থেকে, প্রস্তাবিত চার্ট নির্বাচন করুন .
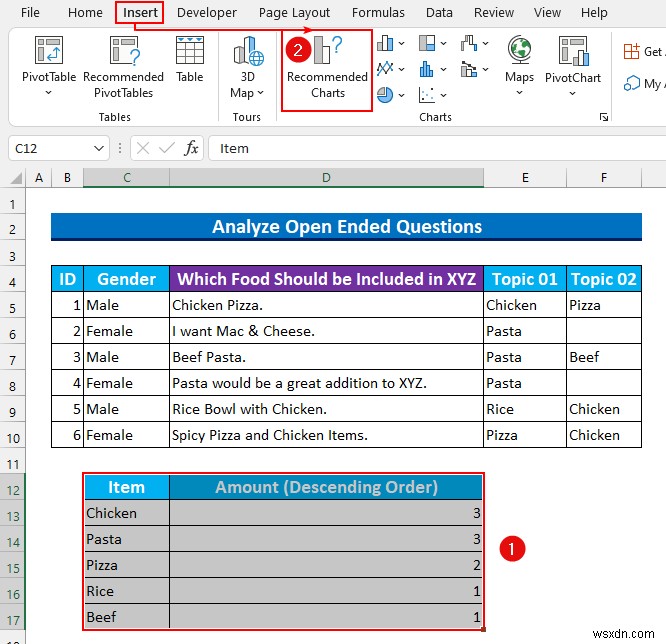
- তারপর, চার্ট ঢোকান ডায়ালগ বক্স প্রদর্শিত হবে এবং গুচ্ছ কলাম ডিফল্টরূপে নির্বাচিত হবে। যদি না হয় তাহলে এটি নির্বাচন করুন৷
- এর পর, ঠিক আছে টিপুন .
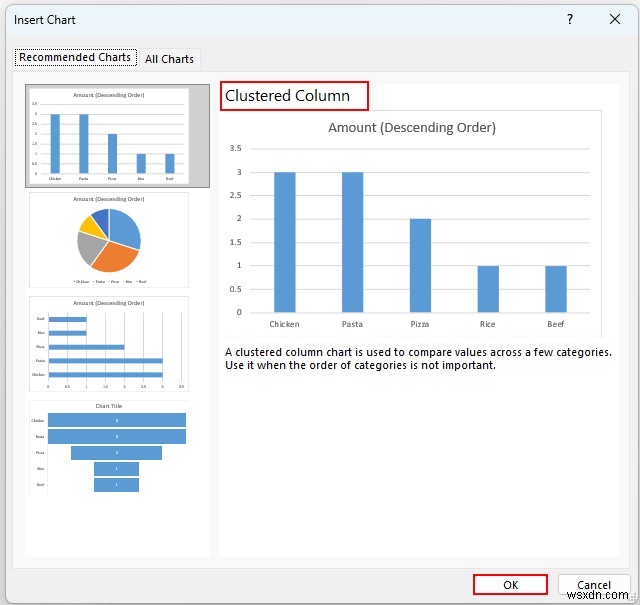
- তারপর, আমরা দেখতে পাব যে গ্রাহকরা চিকেন চান৷ , পাস্তা, এবং পিজা উপরের 3 হিসাবে XYZ ক্যাফেতে খাবারের আইটেম . XYZ ক্যাফে এর ব্যবস্থাপনা আরও আয়ের জন্য এই পণ্যগুলির আরও অফার করতে বেছে নিতে পারে৷ ৷
সারাংশ
- আমরা t-পরীক্ষা ব্যবহার করি যখন আমরা তুলনা মানে দুটি গ্রুপের মধ্যে এবং চি-স্কয়ার টেস্ট যখন আমরা শ্রেণীগত মান নিয়ে কাজ করি .
- আমাদের ডেটাসেটের জন্য, আমরা আমাদের সমীক্ষা প্রশ্নাবলীর তিনটি প্রশ্ন থেকে এই ফলাফলগুলি পাই-
- ক্যাফে XYZ এর সাথে পুরুষ এবং মহিলাদের বিভিন্ন স্তরের সন্তুষ্টি রয়েছে .
- লিঙ্গ এবং ক্যাফে XYZ-এ খাওয়ার সংখ্যা সম্পর্কিত নয়।
- ছাত্র বা গ্রাহকরা মুরগি চান , পাস্তা , এবং পিজ্জা ক্যাফে XYZ-এ অন্তর্ভুক্ত করার জন্য শীর্ষ তিনটি আইটেম হিসেবে .
অভ্যাস বিভাগ
আমরা Excel-এ প্রতিটি পদ্ধতির জন্য একটি অনুশীলন ডেটাসেট যোগ করেছি ফাইল অতএব, আপনি সহজেই আমাদের পদ্ধতি অনুসরণ করতে পারেন।
উপসংহার
আমরা আপনাকে দেখিয়েছি 8 ৷ গুণগত ডেটা বিশ্লেষণ করার পদক্ষেপ এক্সেল-এ . আপনি যদি এই পদ্ধতিগুলি সম্পর্কে কোনও সমস্যার সম্মুখীন হন বা আমার জন্য কোনও প্রতিক্রিয়া থাকে তবে নীচে মন্তব্য করুন। তাছাড়া, আপনি আমাদের সাইটে যেতে পারেন ExcelDemy আরও এক্সেল-সম্পর্কিত এর জন্য প্রবন্ধ পড়ার জন্য ধন্যবাদ, ভালো থাকুন!
সম্পর্কিত প্রবন্ধ
- কিভাবে এক্সেলে qPCR ডেটা বিশ্লেষণ করবেন (2 সহজ পদ্ধতি)
- এক্সেল ডেটা বিশ্লেষণ ব্যবহার করে কেস স্টাডি সম্পাদন করুন
- এক্সেলে টেক্সট ডেটা কীভাবে বিশ্লেষণ করবেন (5টি উপযুক্ত উপায়)
