
পদ্ধতি 1 - কেন্দ্রীয় প্রবণতা এবং পরিবর্তনশীলতা গণনা করা
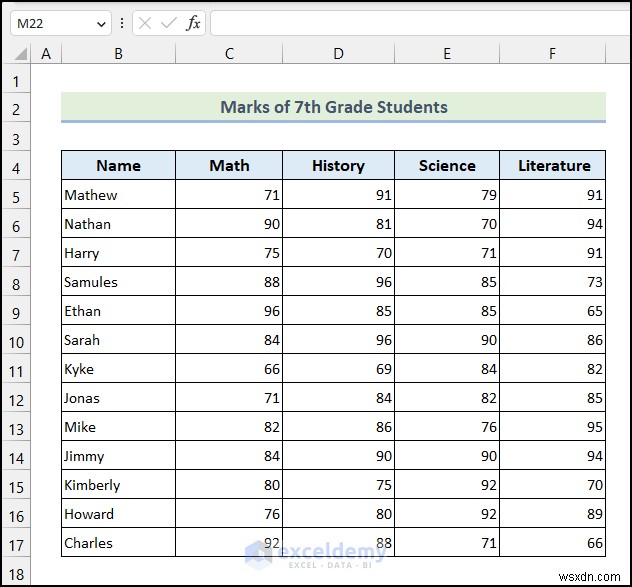
7ম-গ্রেডের ছাত্রদের উপরের ডেটাসেট মার্কগুলি গণিতের উপর ভিত্তি করে দেওয়া হয়েছে , ইতিহাস , বিজ্ঞান , এবং সাহিত্য বিষয়।
1.1 গড় ফাংশন ব্যবহার করা
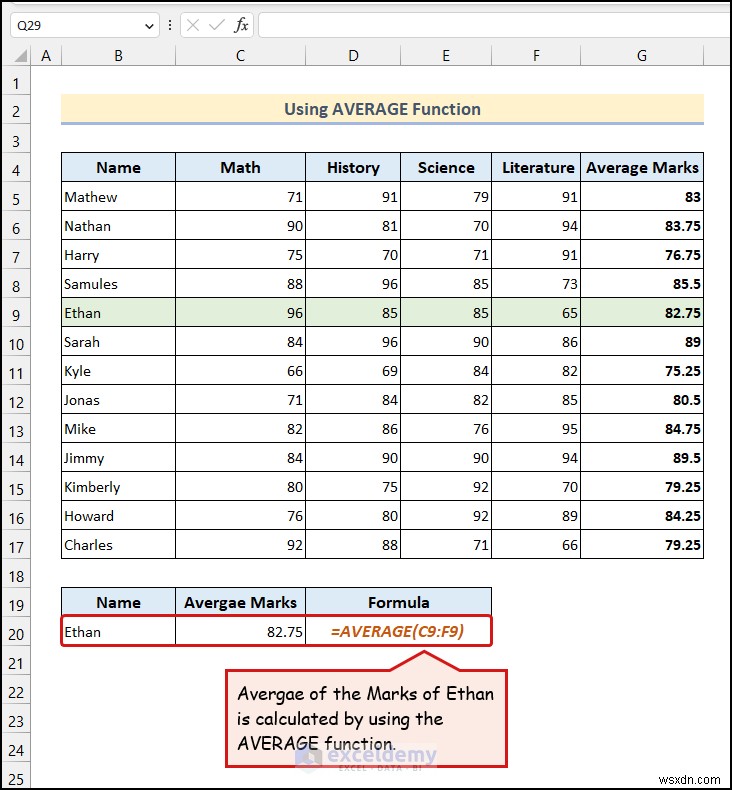
আপনি গড় মার্কস দেখতে পাচ্ছেন ইথান এর জন্য সেলে C20 .
এখানে, আমরা AVERAGE ফাংশন ব্যবহার করেছি , যা একটি ডেটাসেটের গাণিতিক গড় প্রদান করে।
- নিম্নলিখিত সূত্রটি C20 সেল এ লিখুন:
এখানে, কক্ষের পরিসর C9:F9 ইথান-এর জন্য বিভিন্ন বিষয়ের মার্ক বোঝায় .
1.2 AVERAGEIF এবং AVERAGEIFS ফাংশন নিয়োগ করা
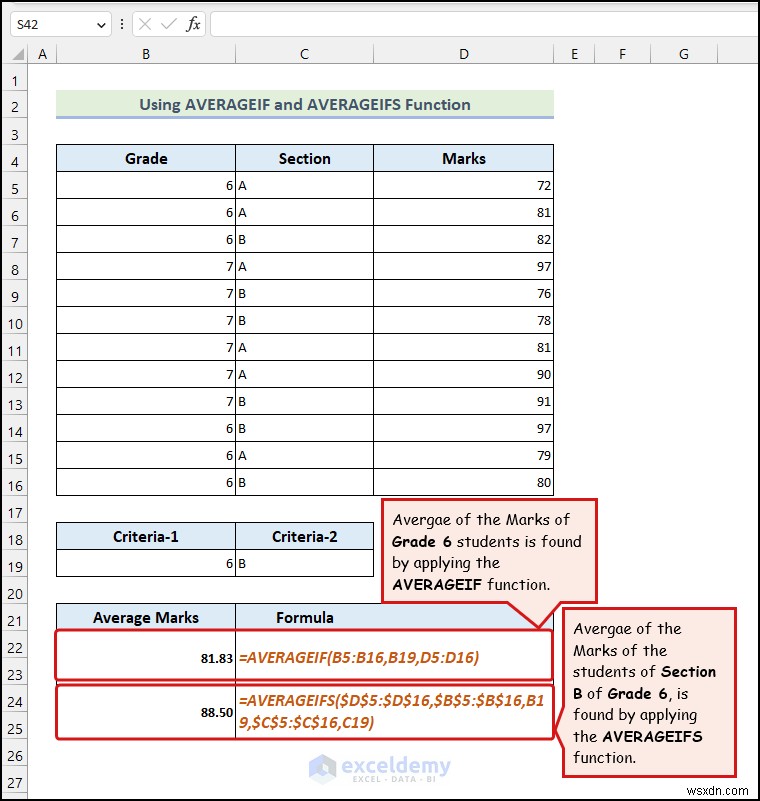
উপরের ডেটাসেট AVERAGEIF -এর বিভিন্ন ব্যবহার প্রদর্শন করে এবং AVERAGEIFS ফাংশন।
আপনি গ্রেড 6 ছাত্রদের দ্বারা প্রাপ্ত নম্বরের গড় খুঁজে পেতে চান। এটি করতে,
- সেলে নিচের সূত্রটি লিখুন B22:
=AVERAGEIF(B5:B16,B19,D5:D16)
এখানে, সেল B19 মানদণ্ড নির্দেশ করে যার ভিত্তিতে আমরা গড় মার্কস খুঁজে পাব .
আসুন অন্য একটি পরিস্থিতি ধরে নেওয়া যাক যেখানে আমরা গড় মার্কস খুঁজে পেতে চাই দুটি মানদণ্ডের উপর ভিত্তি করে ছাত্রদের:তাদের গ্রেড এবং বিভাগ .
- সেলে নিচের সূত্রটি লিখুন C24 :
=AVERAGEIFS($D$5:$D$16,$B$5:$B$16,B19,$C$5:$C$16,C19)
এখানে, কক্ষের পরিসর$D$5:$D$16 চিহ্নের কোষ নির্দেশ করে কলাম, কক্ষের পরিসর $B$5:$B$16 গ্রেডের কোষকে বোঝায় কলাম, এবং কক্ষের পরিসর $C$5:$C$16 বিভাগের কোষ নির্দেশ করে কলাম কোষ B19 এবং C19 দুটি মানদণ্ড প্রতিনিধিত্ব করে .
1.3 হারমান এবং জিওমিয়ান ফাংশন ব্যবহার করা
ধরা যাক আমাদের ডেটা হিসাবে আমাদের ছয়টি সংখ্যা রয়েছে। সংখ্যাগুলি হল 1,2,3,4,5 এবং 6৷ তাহলে আমাদের হারমোনিক গড় মান নিম্নরূপ হবে৷
Harmonic Mean = 11+1/2+1/3+1/4+1/5+1/66 = 2.4489
জিওমিয়ান ফাংশন জ্যামিতিক গড় গণনা করে একটি নির্বাচিত ডেটাসেটের। জ্যামিতিক গড় গণনা করা হয় নম মূল খুঁজে বের করে n গুণ করার পর একটি ডেটাসেটের মান। এখানে, n একটি ডেটাসেটের মোট মানের সংখ্যা। উদাহরণস্বরূপ, ধরা যাক আমাদের আছে 5 আমাদের ডেটাসেট হিসাবে সংখ্যা। এগুলি হল 1, 2, 3, 4, এবং 5। সুতরাং, জ্যামিতিক গড় হবে,
Geometric Mean = 51*2*3*4*5 = 2.6051.
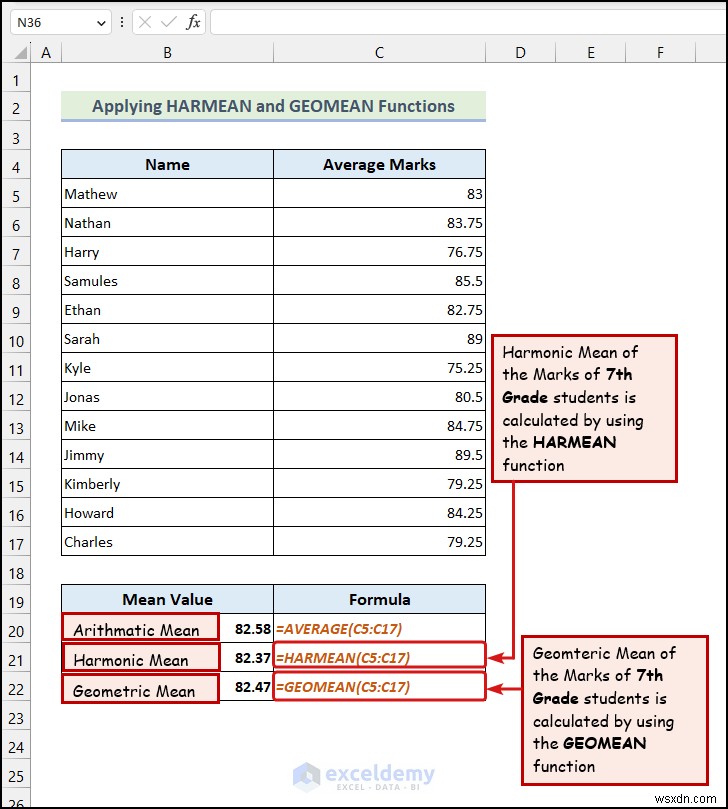
উপরের চিত্রটি হারমান উভয় ব্যবহার করার একটি বাস্তব উদাহরণ প্রদর্শন করে এবং GEOMEAN ফাংশন।
- B21 -এ হারমোনিক গড় গণনা করার সূত্র সেল হল:
এখানে, কক্ষের পরিসরC5:C17 গড় চিহ্নের কোষের প্রতিনিধিত্ব করে কলাম
একটি জিনিস পরিষ্কার:হারমোনিক গড় মান, এই ক্ষেত্রে, গড় মার্কের গড় মান থেকে কম। পাটিগণিতের গড় হল 82.58 , কিন্তু হারমোনিক গড় হল82.37 . এর মানে এটি গড় মার্কস এর বড় মানের মানকে সীমিত করে .
- জ্যামিতিক গড় খুঁজে বের করার ক্ষেত্রে, আমরা কক্ষে নিম্নলিখিত সূত্রটি ব্যবহার করেছি C22:
হারমোনিক গড়ের মতো, জ্যামিতিক গড় (82.47 ) পাটিগণিত গড় (82.58) থেকে আলাদা . বিনিয়োগকারীরা জ্যামিতিক গড় ব্যবহার করে কারণ এটি একটি আরও সঠিক গড় মান প্রদান করে যখনই সারি মানগুলি বিভিন্ন সময়কাল জুড়ে দেওয়া হয়।
1.4 স্ট্যান্ডার্ডাইজ ফাংশন প্রয়োগ করা
পদক্ষেপ :
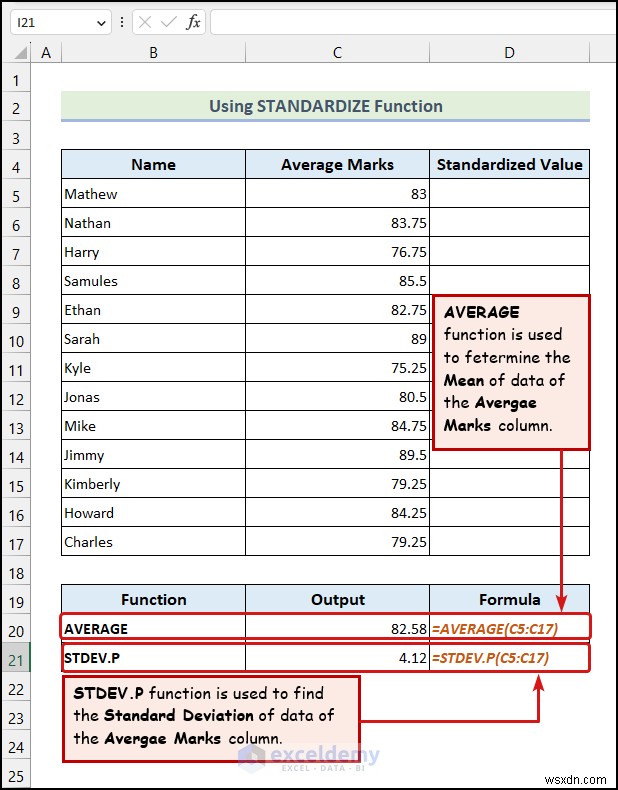
- Cগড় এবং মানক বিচ্যুতি গণনা করুন ডেটাসেটের।
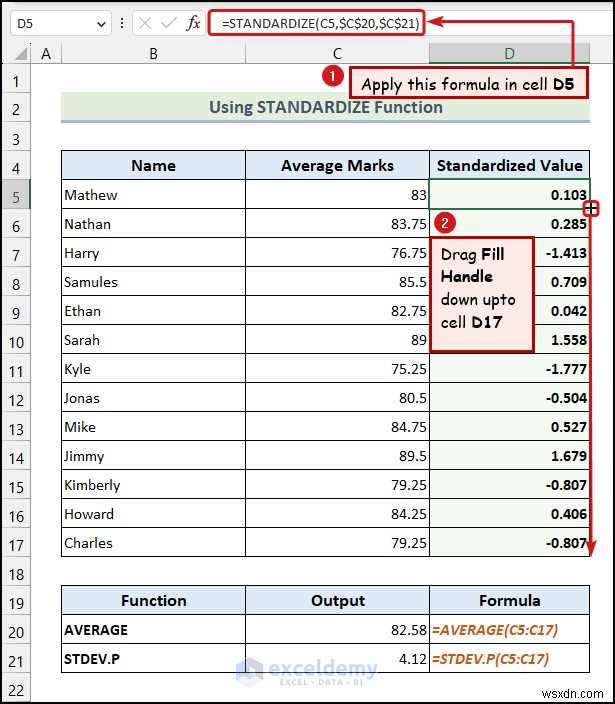
- সেলে নিচের সূত্রটি লিখুন D5:
=STANDARDIZE(C5,$C$20,$C$21)
এখানে, সেল C5 গড় মার্কস প্রতিনিধিত্ব করে ম্যাথিউ এর , সেল $C$20 গড় মান নির্দেশ করে , এবং সেল $C$21 STDEV.P(স্ট্যান্ডার্ড ডেভিয়েশন)কে বোঝায় মান
আপনি MODE.SNGL ব্যবহার করতে পারেন৷ , মিডিয়ান , VAR.S , VAR.P , STDEV.S , এবং STDEV.P এক্সেলে আরও পরিসংখ্যানগতভাবে ডেটা বিশ্লেষণ করার ফাংশন।
পদ্ধতি 2 - কম্পিউটিং রিলেটিভ স্ট্যান্ডিং
ধরা যাক উভয়ই 5ম এবং ৬ষ্ঠ -র্যাঙ্ক করা মান একই। সেই ক্ষেত্রে, RANK.EQ ফাংশন 5 র্যাঙ্ক ফিরিয়ে দেবে উভয় মানের জন্য, এবং পরবর্তী র্যাঙ্ক মানটি হবে র্যাঙ্ক 7 . এখানে, আমাদের মোট মার্কস আছে ৭ম গ্রেড ছাত্র আমাদের ডেটাসেট হিসাবে।
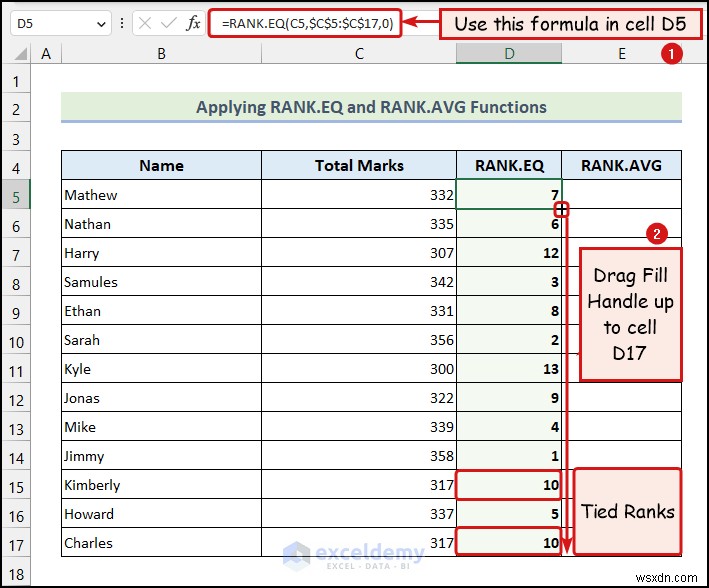
এখানে, আপনি দেখতে পাচ্ছেন যে দশম এবং 11 তম মান বাঁধা ছিল। সুতরাং, RANK.EQ ফাংশন 10 র্যাঙ্ক ফিরিয়ে দিয়েছে উভয় মানের জন্য।
- আমরা D5 কক্ষে নিম্নলিখিত সূত্রটি প্রয়োগ করেছি .
=RANK.EQ(C5,$C$5:$C$17,0)
এখানে, সেল C5 মোট চিহ্নের প্রথম কক্ষকে বোঝায় কলাম, এবং কক্ষের পরিসর $C$5:$C$17 মোট চিহ্নের কোষের প্রতিনিধিত্ব করে কলাম
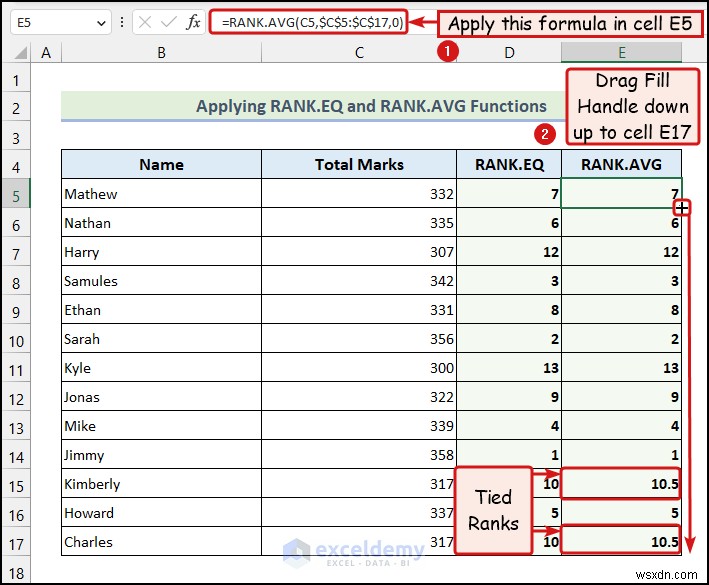
এখানে, দশম এবং 11 তম মান বাঁধা ছিল, তাই RANK.AVG ফাংশন গড়ে 10.5 ফেরত দিয়েছে উভয় মানের জন্য।
RANK.AVG ফাংশন একটি ডেটাসেটের আপেক্ষিক র্যাঙ্কও প্রদান করে। কিন্তু, বন্ধনের ক্ষেত্রে, এটি একটি গড় র্যাঙ্ক ফিরিয়ে দেবে বাঁধা মান জন্য. উদাহরণস্বরূপ, ধরা যাক 4র্থ এবং 5ম-র্যাঙ্কযুক্ত মানগুলি আবদ্ধ। সুতরাং, RANK.AVG ফাংশন 4.5 একটি র্যাঙ্ক প্রদান করবে উভয় মানের জন্য। পরবর্তী মানের র্যাঙ্ক হবে 6 . এখন, চলুন RANK.AVG ব্যবহার করার জন্য নীচে বর্ণিত নির্দেশাবলী ব্যবহার করা যাক পরিসংখ্যানগতভাবে ডেটা বিশ্লেষণ করার জন্য এক্সেলে ফাংশন।
- আমরা সেল E5:-এ নিম্নলিখিত সূত্রটি ব্যবহার করেছি
=RANK.AVG(C5,$C$5:$C$17,0)
উপরন্তু, আপনি PERCENTRANK.INCও ব্যবহার করতে পারেন , PERCENTRANK.EXC , PERCENTILE.INC , PERCENTILE.EXC , QUARTILE.INC এবং QUARTILE.EXC ফাংশন এক্সেলে ডেটার আপেক্ষিক অবস্থান গণনা করতে।
পদ্ধতি 3 - পারস্পরিক সম্পর্ক এবং রিগ্রেশন নির্ধারণ
3.1 SLOPE, INTERCEPT, এবং STYEX ফাংশন ব্যবহার করে
STYEX ফাংশন আমাদের Y মান এর মানক ত্রুটি দেয় প্রদত্ত X মান এর জন্য . আমরা Y মান ভবিষ্যদ্বাণী করতে এটি ব্যবহার করতে পারি একটি X মান থেকে .
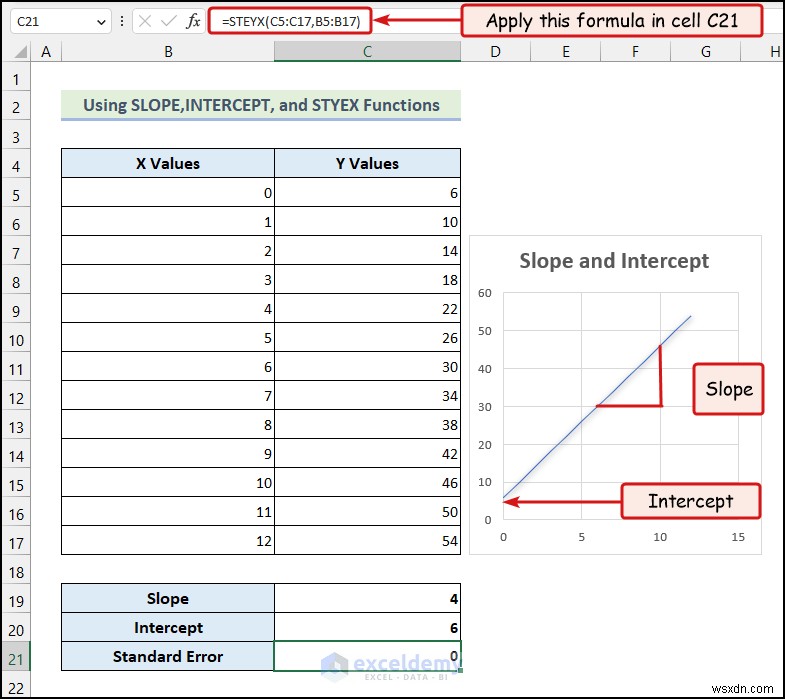
পদক্ষেপ :
- সেলে নিচে দেওয়া সূত্রটি লিখুন C21:
এখানে, কক্ষের পরিসর C5:C17 Y মানগুলির কোষগুলি নির্দেশ করে৷ কলাম, এবং কক্ষের পরিসর B5:B17 X মানগুলির কোষগুলিকে বোঝায়৷ কলাম
- ENTER টিপুন .
আপনার স্ট্যান্ডার্ড ত্রুটি থাকবে৷ Y মানগুলির প্রদত্ত X মান এর জন্য ঘরে C21।
3.2 CORREL ফাংশন প্রয়োগ করা
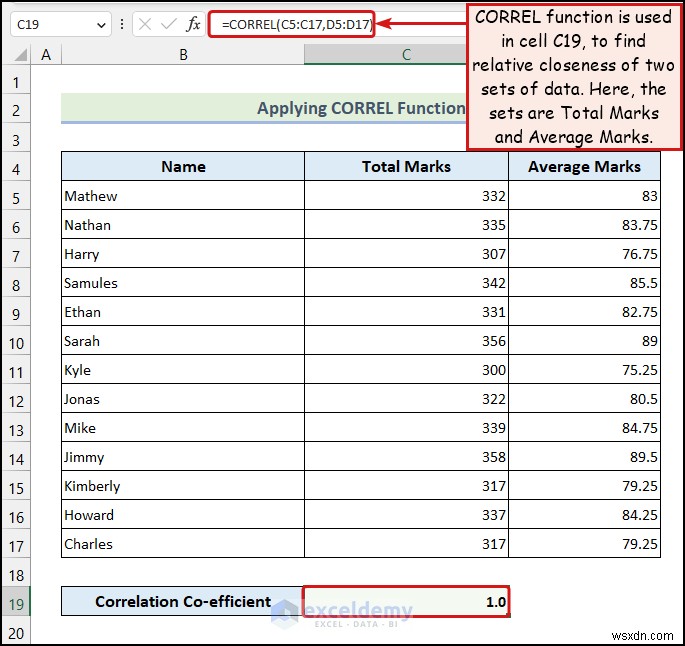
CORREL ফাংশন ডেটার দুটি সেট কতটা ঘনিষ্ঠভাবে সম্পর্কিত তা খুঁজে পেতে আমাদের সাহায্য করে।
- আমরা C19 -এ নিম্নলিখিত সূত্রটি ব্যবহার করেছি সেল:
এখানে, পরিসর C5:C17 মোট চিহ্নের কোষ নির্দেশ করে কলাম, এবং পরিসর D5:D17 গড় চিহ্নের কোষগুলিকে বোঝায় কলাম
4. পরিসংখ্যানগত বিশ্লেষণের জন্য অ্যারে ফাংশন প্রয়োগ করা হচ্ছে
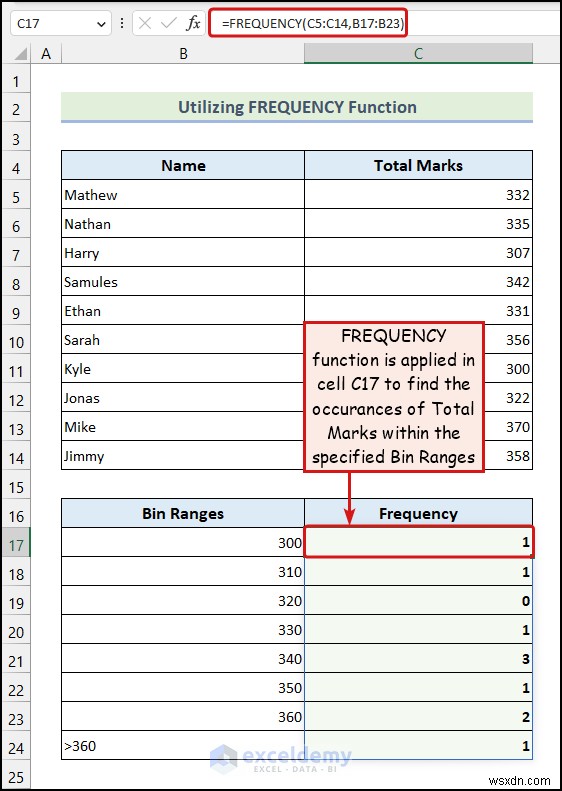
এখানে, প্রতিটি বিন রেঞ্জ, এর বিপরীতে আমাদের ফ্রিকোয়েন্সি রয়েছে নিম্নলিখিত ছবিতে প্রদর্শিত হিসাবে. আমরা FREQUENCY ফাংশন ব্যবহার করেছি এক্সেলের পরিসংখ্যানগতভাবে ডেটা বিশ্লেষণ করার জন্য, সবচেয়ে বেশি ব্যবহৃত অ্যারে ফাংশনগুলির মধ্যে একটি৷
- সেলে নিচের সূত্রটি লিখুন C17 :
=FREQUENCY(C5:C14,B17:B23)
এখানে, পরিসর B17:B23 প্রথম সাত প্রতিনিধিত্ব করে বিন রেঞ্জের কোষ কলাম
আপনি MODE.MULT ফাংশন ব্যবহার করতে পারেন৷ , LINEST ফাংশন , TREND ফাংশন , এবং GROWTH ফাংশন পরিসংখ্যানগতভাবে এক্সেলে ডেটা বিশ্লেষণ করতে।
দ্রষ্টব্য: যদি আপনি Excel এর একটি পুরানো সংস্করণ ব্যবহার করেন, তাহলে আপনাকে CTRL + SHIFT + ENTER টিপতে হতে পারে অ্যারে সূত্র ব্যবহার করতে। যেমন আমরা এক্সেল 365 ব্যবহার করি, শুধু ENTER টিপে আমাদের জন্য করবে৷৷
পদ্ধতি 5 - মুভিং এভারেজ গণনা করতে ডেটা বিশ্লেষণ টুলপ্যাক ব্যবহার করা
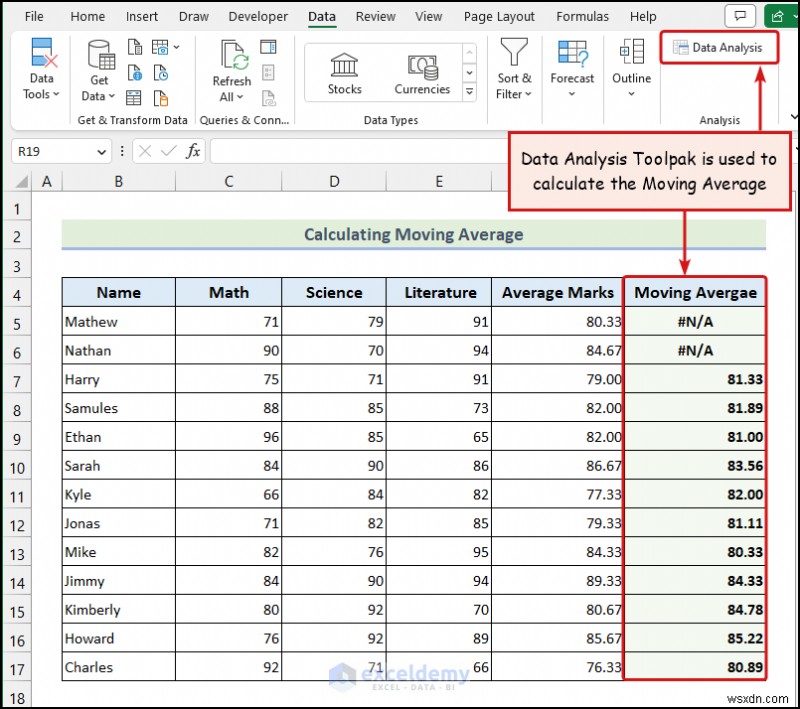
উপরের চিত্রটি চলন্ত গড় প্রতিনিধিত্ব করে আমাদের ডেটাসেটের। ডেটা অ্যানালাইসিস টুলপ্যাক বিকল্পটি Excel রিবন-এ নেই ডিফল্টরূপে আপনাকে এই বৈশিষ্ট্যটি ম্যানুয়ালি সক্রিয় করতে হবে। আপনি ডেটা অ্যানালাইসিস টুলপ্যাক সক্রিয় করতে এবং এর বিভিন্ন ব্যবহার সম্পর্কে জানতে এই নিবন্ধটি অনুসরণ করতে পারেন .
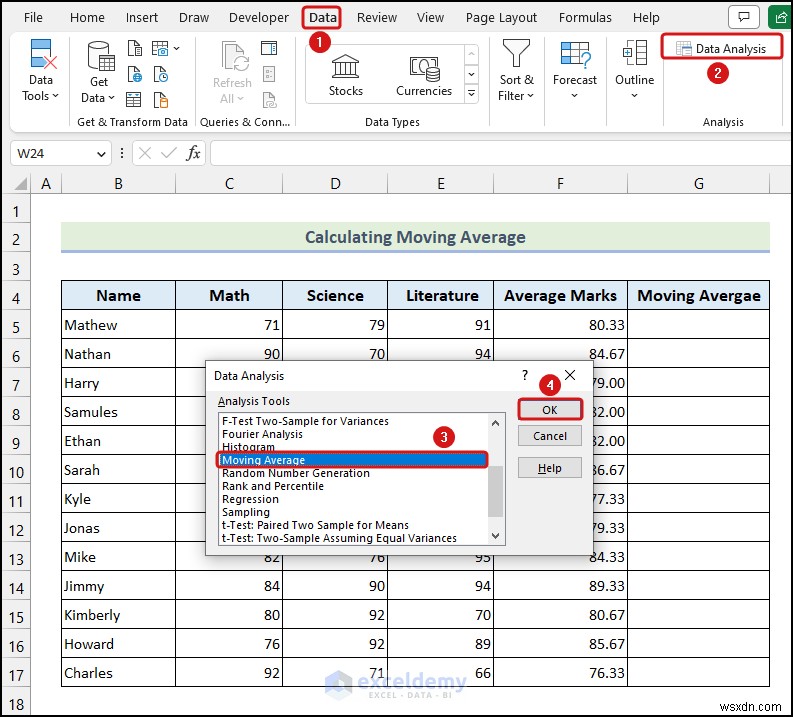
- ডেটা -এ যান রিবন থেকে ট্যাব>> ডেটা বিশ্লেষণ বেছে নিন বিশ্লেষণ থেকে বিকল্প গ্রুপ।
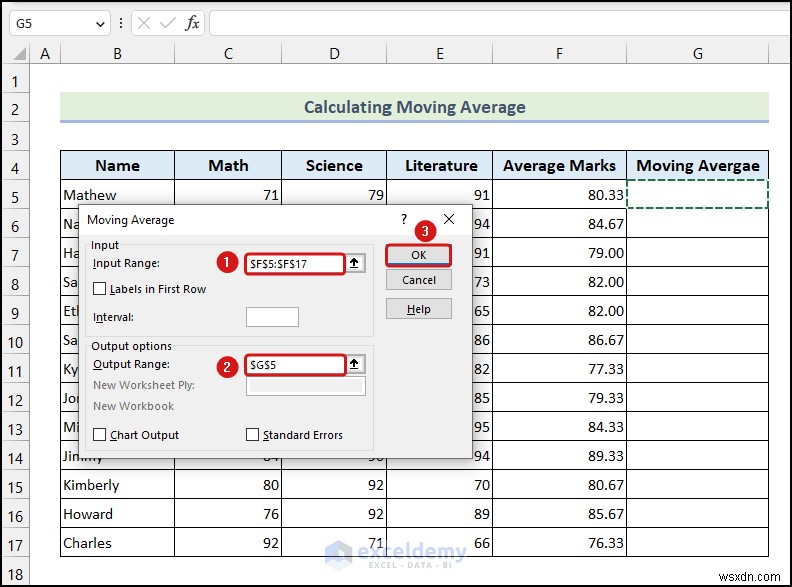
ডেটা বিশ্লেষণ ডায়ালগ বক্স আপনার ওয়ার্কশীটে প্রদর্শিত হবে, যেমন উপরের ছবিতে দেখানো হয়েছে।
- ইনপুট রেঞ্জ-এ যান গড় চিহ্নের ঘর নির্বাচন করতে ক্ষেত্র কলাম>> আউটপুট রেঞ্জ -এ ক্লিক করুন ক্ষেত্র এবং সেল G5 নির্বাচন করুন>> ঠিক আছে ক্লিক করুন .
এক্সেলের কিছু সাধারণ ডেটা বিশ্লেষণ টুলস
- আনোভা:একক ফ্যাক্টর → এটি দুই বা ততোধিক পর্যবেক্ষণের জন্য ভিন্নতা বিশ্লেষণ করে।
- আনোভা:প্রতিলিপি সহ দুই ফ্যাক্টর → ভেরিয়েবলের স্তরগুলির প্রতিটি সংমিশ্রণের জন্য, এটি দুটি স্বাধীন ভেরিয়েবল এবং বিভিন্ন পর্যবেক্ষণের সাথে বৈচিত্র্যের একটি বিশ্লেষণ তৈরি করে৷
- আনোভা:প্রতিলিপি ছাড়া দুটি ফ্যাক্টর → ভেরিয়েবলের স্তরগুলির প্রতিটি সংমিশ্রণের জন্য, এটি দুটি স্বাধীন ভেরিয়েবল এবং একটি একক পর্যবেক্ষণের সাথে বৈচিত্র্যের একটি বিশ্লেষণ তৈরি করে৷
- পারস্পরিক সম্পর্ক → যখন মানুষের একটি নমুনায় দুটির বেশি পরিমাপ থাকে, তখন প্রতিটি সম্ভাব্য জোড়া পরিমাপের জন্য পারস্পরিক সম্পর্ক সহগগুলির একটি ম্যাট্রিক্স গণনা করা হয়৷
- Covariance → যখন মানুষের একটি নমুনায় দুটির বেশি পরিমাপ থাকে, তখন প্রতিটি সম্ভাব্য জোড়া পরিমাপের জন্য কোভারিয়েন্স সহগগুলির একটি ম্যাট্রিক্স গণনা করা হয়৷
- বর্ণনামূলক পরিসংখ্যান → এটি কোষের একটি নির্দিষ্ট পরিসরের মধ্যে কেন্দ্রীয় প্রবণতা, পরিবর্তনশীলতা এবং মানগুলির অন্যান্য বৈশিষ্ট্যগুলির সংক্ষিপ্তসার করে একটি প্রতিবেদন তৈরি করে৷
- Exponential Smoothing → এটি পূর্ববর্তী মান এবং পূর্ববর্তী ভবিষ্যদ্বাণীগুলির ক্রম ব্যবহার করে একটি অনুক্রমের পরবর্তী মানের পূর্বাভাস দেয়৷
- ভিন্নতার জন্য এফ-টেস্ট দুই-নমুনা → এটি একটি এফ-টেস্ট সম্পাদন করে দুটি ভিন্নতার তুলনা করে।
- হিস্টোগ্রাম → এটি একটি নির্বাচিত সেল পরিসরের মধ্যে মানগুলির ফ্রিকোয়েন্সি বিতরণের একটি সারণী চিত্র তৈরি করে৷
- র্যান্ডম নম্বর জেনারেশন → সাতটি সম্ভাব্য ডিস্ট্রিবিউশনের একটির উপর ভিত্তি করে, একটি নির্দিষ্ট পরিমাণ এলোমেলো সংখ্যা তৈরি করে।
- র্যাঙ্ক এবং পারসেন্টাইল → এটি একটি সারণী তৈরি করে যা প্রতিটি মানকে তার অর্ডিনিয়াল এবং পার্সেন্টাইল র্যাঙ্ক সহ মানগুলির একটি সেটে প্রদর্শন করে৷
- রিগ্রেশন → এটি ডেটার একটি সেটে প্রয়োগ করা রৈখিক রিগ্রেশন পরিসংখ্যানের একটি প্রতিবেদন তৈরি করে যাতে একটি নির্ভরশীল ভেরিয়েবল এবং এক বা একাধিক স্বাধীন ভেরিয়েবল অন্তর্ভুক্ত থাকে৷
- নমুনা → এটি নির্দিষ্ট পরিসরের কোষ থেকে মানগুলির একটি নমুনা তৈরি করে৷ ৷
আপনি ডেটা বিশ্লেষণ টুলপ্যাক-এ নিম্নলিখিত বিশ্লেষণ সরঞ্জামগুলি পাবেন .
মনে রাখার বিষয়গুলি
- এক্সেলে যেকোন ডেটা বিশ্লেষণ করার আগে, আপনাকে অবশ্যই আপনার ডেটার ধরন সম্পর্কে পরিষ্কার হতে হবে, যেমন, একটানা বা শ্রেণীবদ্ধ৷
- এরপর, আপনাকে পরিসংখ্যানগত বিশ্লেষণের সরঞ্জামগুলির সমৃদ্ধ তালিকা থেকে নির্বাচন করতে হবে, যেমন টি-টেস্ট, ANOVA, রিগ্রেশন এবং পারস্পরিক সম্পর্ক।
- আপনি একবার আপনার বিশ্লেষণ পরিচালনা করলে, আপনার ফলাফলগুলিকে অর্থপূর্ণভাবে ব্যাখ্যা করা গুরুত্বপূর্ণ। এর অর্থ হল সংখ্যাগুলি কী বোঝায় এবং সেগুলি আপনার গবেষণা প্রশ্নের সাথে কীভাবে সম্পর্কিত।
- অবশেষে, ত্রুটিগুলি পরীক্ষা করে আপনার ফলাফল যাচাই করা এবং আপনার বিশ্লেষণটি শক্তিশালী কিনা তা নিশ্চিত করা গুরুত্বপূর্ণ। এর মধ্যে রয়েছে বহিরাগতদের জন্য পরীক্ষা করা, অনুমান পরীক্ষা করা এবং সংবেদনশীলতা বিশ্লেষণ করা।
অভ্যাস বিভাগ
এক্সেল ওয়ার্কবুকে , আমরা একটি অভ্যাস বিভাগ প্রদান করেছি ওয়ার্কশীটের ডান দিকে।
অনুশীলন ওয়ার্কবুকের প্রতিটি ওয়ার্কশীটে একটি নমুনা অনুশীলন বিভাগ দেওয়া আছে।
অভ্যাস ওয়ার্কবুক ডাউনলোড করুন
নিচের ওয়ার্কবুক ডাউনলোড করুন এবং অনুশীলন করুন।
সমাধান সহ বিনামূল্যে উন্নত এক্সেল ব্যায়াম পান!