
ভ্যারিয়েন্স বা ANOVA এর বিশ্লেষণ একটি দরকারী বিশ্লেষণ। 1918 সালে প্রক্রিয়াটির বিকাশের শুরু থেকেই, এটি ব্যাপকভাবে ব্যবহৃত হয়েছে। এটি গড় এবং বিভিন্ন গোষ্ঠীর মধ্যে পরিসংখ্যানগত পার্থক্য দেখায় এবং তাদের প্রতিটি মান কতটা সম্পর্কযুক্ত তা নির্ধারণ করে। একটি নেস্টেড ANOVA হল যেখানে এই গোষ্ঠীগুলিকে অনেকগুলি গোষ্ঠীতে বিভক্ত করা হয় যেগুলির সাথে আমরা পৃথকভাবে সম্পর্ক স্থাপন করতে পারি বা নাও করতে পারি। এই নিবন্ধটি নেস্টেড ANOVA এর ওভারভিউ এবং কিভাবে Excel এ বিশ্লেষণ সম্পাদন করতে হয় তা নিয়ে আলোচনা করবে।
আপনি নীচের লিঙ্ক থেকে প্রদর্শনের জন্য ব্যবহৃত ওয়ার্কবুকটি ডাউনলোড করতে পারেন।
ANOVA বিশ্লেষণ কি?
ANOVA হল একটি পরিসংখ্যানগত পদ্ধতি যা ডেটাসেটের মধ্যে পরিলক্ষিত বৈচিত্র বিশ্লেষণ করতে ব্যবহৃত হয়। এটি সম্পাদন করার জন্য, আমাদের ডেটাসেটটিকে দুটি বিভাগে ভাগ করতে হবে- পদ্ধতিগত এবং এলোমেলো কারণ৷
ANOVA আমাদের নির্ধারণ করতে দেয় যে কোন উপাদানগুলি একটি নির্দিষ্ট ডেটা সেটকে উল্লেখযোগ্যভাবে প্রভাবিত করে। বিশ্লেষণ শেষ করার পরে, একজন বিশ্লেষক সাধারণত পদ্ধতিগত কারণগুলির উপর অতিরিক্ত বিশ্লেষণ করেন যা ডেটা সেটের অসঙ্গতিপূর্ণ প্রকৃতিকে উল্লেখযোগ্যভাবে প্রভাবিত করে। সেই ক্ষেত্রে, আনুমানিক রিগ্রেশন বিশ্লেষণের সাথে প্রাসঙ্গিক অতিরিক্ত ডেটা তৈরি করতে তাকে ANOVA ফলাফলগুলি ব্যবহার করতে হবে। ANOVA অনেক ডেটা সেট তুলনা করে দেখতে পারে যে তাদের মধ্যে কোনো লিঙ্ক আছে কিনা।
ANOVA দুই ধরনের, একটি হল একক ফ্যাক্টর এবং আরেকটি হল দুটি কারণ। একটি একক ফ্যাক্টরের মধ্যে, ANOVA একটি একক চলকের উপর একটি ফ্যাক্টরের প্রভাব খুঁজে পায়। অন্যদিকে, দুটি ফ্যাক্টর ANOVA-তে একাধিক নির্ভরশীল ভেরিয়েবল রয়েছে।
নেস্টেড ANOVA এর ওভারভিউ
একটি নেস্টেড আনোভা, নাম অনুসারে, অন্তত একটি ফ্যাক্টর অন্যটির ভিতরে থাকে৷
ধরা যাক দুটি আলাদা জায়গায় একটি নির্দিষ্ট সংস্থার দুটি স্টোর রয়েছে। উদাহরণস্বরূপ, 2 টি দল আছে- প্রথম স্টোরে A এবং B টিম এবং দ্বিতীয় C এবং D টিম। তাদের নিজ নিজ দলের মধ্যে নির্ধারিত বিক্রয় দোকানের মধ্যে নেস্ট করা হবে।
রূপকভাবে, এটি এরকম হবে।
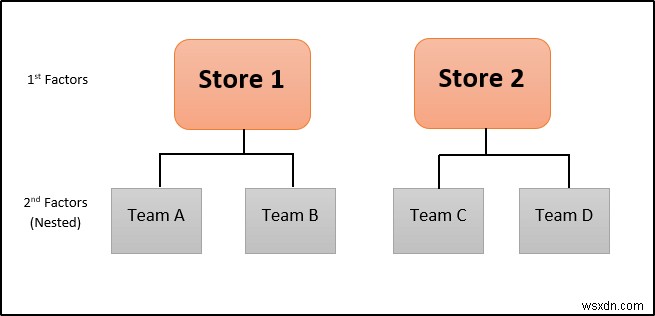
আপনি চিত্র থেকে দেখতে পাচ্ছেন, দ্বিতীয় ফ্যাক্টরটি প্রথম ফ্যাক্টরের ভিতরে থাকে। তাই, এই ধরনের বিক্রয়ের ANOVA বিশ্লেষণ নেস্টেড ANOVA বিভাগে হবে।
এখন রিডিং বা ডেটা এন্ট্রি থেকে ডেটা এখন স্প্রেডশীটে এইরকম দেখাবে৷
৷
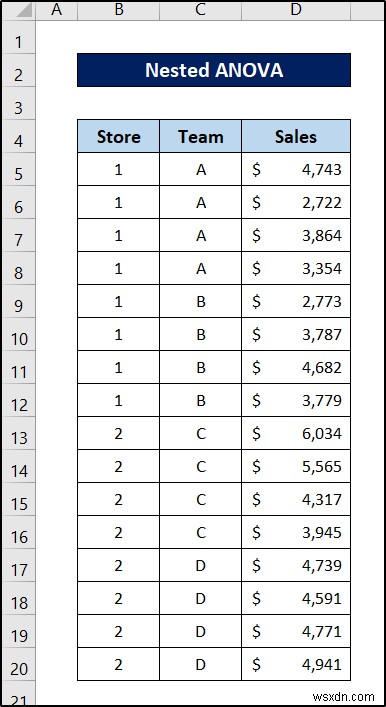
এই ডেটা থেকে, আমরা দুটি জিনিস বিশ্লেষণ করতে পারি- প্রতিটি দোকানে বিক্রয় সমান (ফ্যাক্টর 1) এবং প্রতিটি দল (ফ্যাক্টর 2)?
এই ডেটাতে ANOVA সম্পাদন করার পরে (পরবর্তী বিভাগে এটির আরও কিছু), আমরা এরকম কিছু খুঁজে পাব।
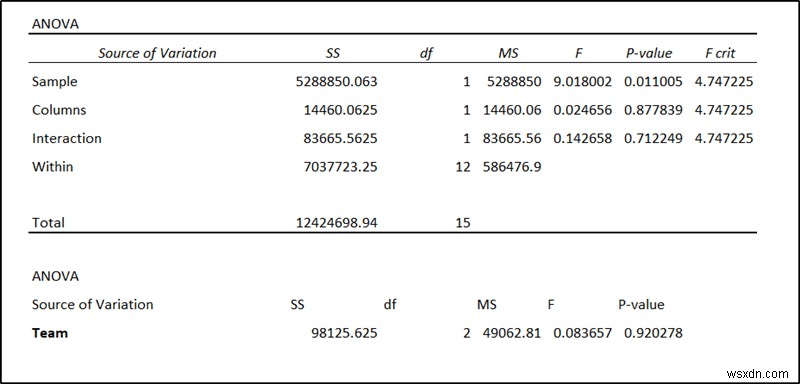
এখানে p-মানগুলি প্রতিটি ফ্যাক্টরের তাৎপর্য বিচার করবে। এই ডেটা থেকে, আমরা দেখতে পাচ্ছি যে স্টোরের একটি পরিসংখ্যানগতভাবে উল্লেখযোগ্য প্রভাব রয়েছে যখন তাদের মধ্যে থাকা দলগুলি তা করে না৷
এই গণনা এবং ব্যাখ্যা পরবর্তী বিভাগে আছে.
এক্সেলে নেস্টেড আনোভা কীভাবে সম্পাদন করবেন
এক্সেলে ANOVA নেস্টেড করার কোনো সরাসরি উপায় নেই৷ কিন্তু আমরা এখনও ডেটাসেট পরিবর্তন করে এবং কিছু ম্যানুয়াল গণনা করে অপারেশন করতে পারি। আমরা ডেটা অ্যানালাইসিস টুলপ্যাক ব্যবহার করব এর প্রতিলিপি সহ দুই ফ্যাক্টর এখানে বৈশিষ্ট্য। মনে রাখবেন, আপনার কাছে ডেটা অ্যানালাইসিস টুলপ্যাক নাও থাকতে পারে আপনার রিবনে ডিফল্টরূপে। কীভাবে দেখতে এখানে ক্লিক করুন ডেটা বিশ্লেষণ টুলপ্যাক সক্ষম করুন . শেষ পর্যন্ত, আমাদের প্রয়োজন হবে F.DIST.RT ফাংশন ম্যানুয়াল গণনার জন্য।
কিন্তু প্রথমে, আমাদের মূল কাঁচা ডেটাসেটে কিছু পরিবর্তন করতে হবে। কারণ আমরা টু ফ্যাক্টর উইথ রেপ্লিকেশন সম্পাদন করব চালু কর. আগের বিভাগ থেকে কাঁচা ডেটাসেট নেওয়া যাক।
এখন এক্সেলে নেস্টেড আনোভা সম্পাদনের পদক্ষেপগুলি দেখতে এই পদক্ষেপগুলি অনুসরণ করুন৷
৷পদক্ষেপ:
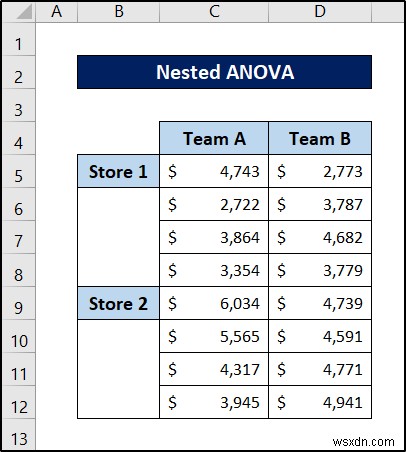
- প্রথমে, ডেটাসেটটিকে নিচের মত করে সাজান। আমরা A এবং B এর অধীনে টিম C এবং D এর বিক্রয় মান অন্তর্ভুক্ত করেছি যাতে Excel সেগুলি পড়তে পারে।
- এখন ডেটা -এ যান আপনার রিবনে ট্যাব।
- তারপর ডেটা বিশ্লেষণ নির্বাচন করুন বিশ্লেষণ থেকে গ্রুপ বিভাগ।

- ডেটা বিশ্লেষণ বক্স প্রদর্শিত হবে।
- এখন আনোভা:প্রতিলিপি সহ দুই-ফ্যাক্টর নির্বাচন করুন বিশ্লেষণ টুলস এর অধীনে
- তারপর ঠিক আছে এ ক্লিক করুন .
- পরবর্তী, আনোভা:প্রতিলিপি সহ দুই-ফ্যাক্টর বক্স প্রদর্শিত হবে। বাক্সে নিম্নলিখিত বিবরণ নির্বাচন করুন।
- প্রথমে, পরিসর লিখুন B4:D12 ইনপুট পরিসর হিসাবে।
- দ্বিতীয়, 4 সন্নিবেশ করান নমুনা প্রতি সারি -এ ক্ষেত্র, যেহেতু আমাদের প্রতিটি নেস্টেড ফ্যাক্টরের জন্য চারটি এন্ট্রি আছে।
- আপনি আলফা পরিবর্তন করতে পারেন মান খুব যদি আপনি চান। কিন্তু আমরা এটি 0 রাখব 05 আপাতত।
- তৃতীয়, আপনি আউটপুট বিকল্পের অধীনে আপনার ফলাফলগুলি কোথায় প্রদর্শন করতে চান তা নির্বাচন করতে পারেন .
- যখন আপনি এই সব দিয়ে শেষ করেন, তখন ঠিক আছে এ ক্লিক করুন .
- ফলে, ফলাফল আপনার নির্বাচিত স্থানে পপ আপ হবে। আমরা শেষ অংশটি ANOVA এর অধীনে ব্যবহার করব এক্সেলে নেস্টেড আনোভা বিশ্লেষণের জন্য।
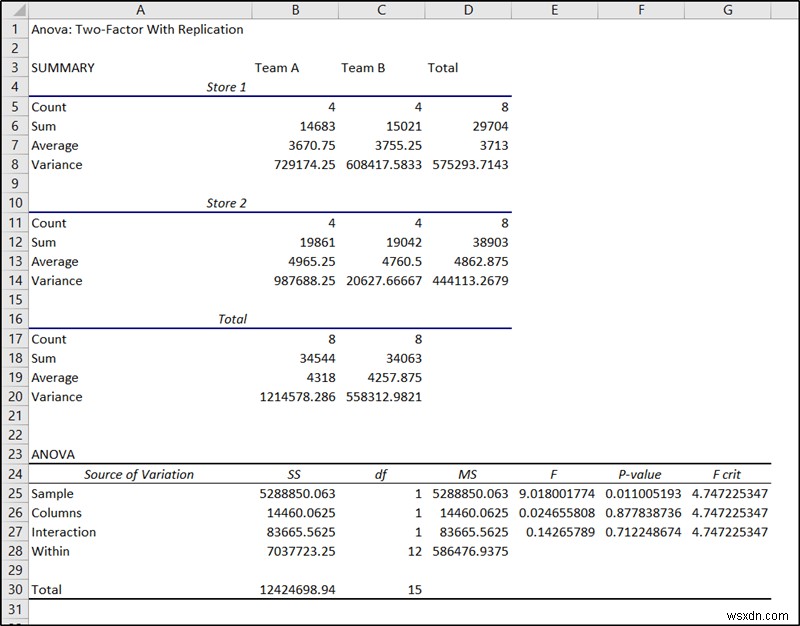
- কক্ষে নমুনার p-মান F25 নমুনার তাৎপর্য নির্দেশ করে যা এই ক্ষেত্রে, প্রথম ফ্যাক্টর, স্টোর।
- অন্যান্য কারণের তাৎপর্যের জন্য, আমাদের এখন কিছু ম্যানুয়াল গণনা করতে হবে।
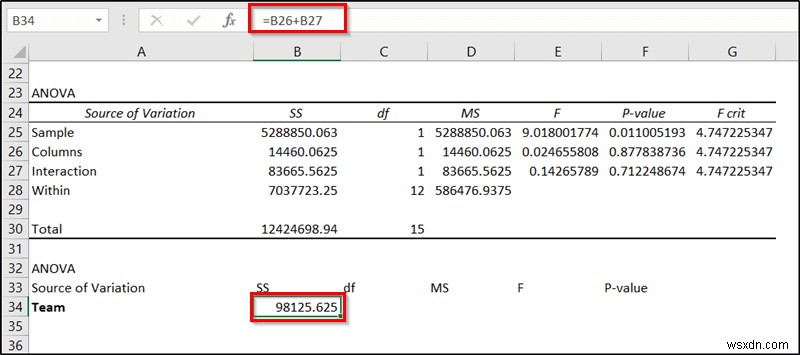
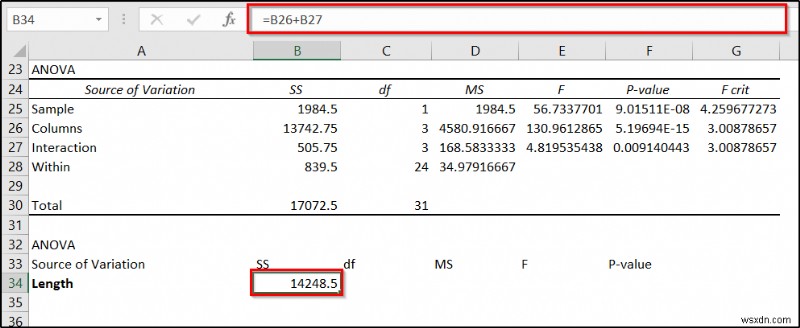
- প্রথমে, সেল B34 নির্বাচন করুন এবং নিম্নলিখিত সূত্রটি লিখুন।
=B26+B27
- তারপর এন্টার টিপুন .
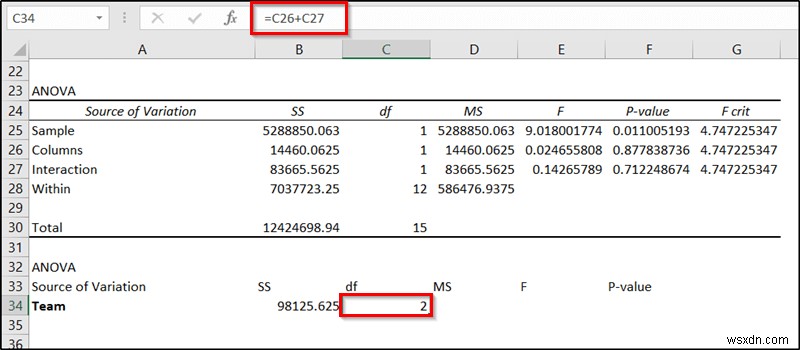
- এখন C34 ঘরে নিচের সূত্রটি লিখুন এবং Enter টিপুন .
=C26+C27
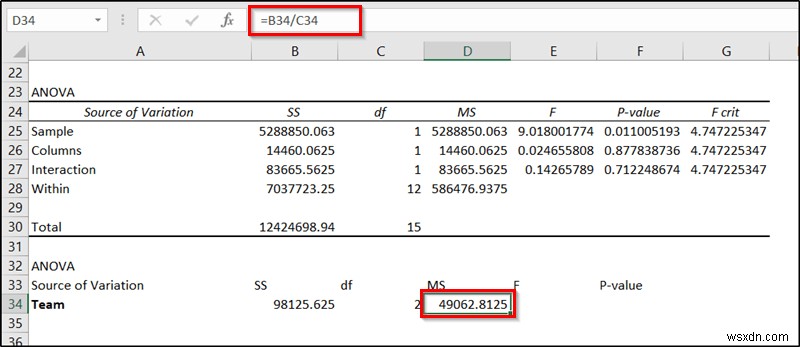
- এরপর, D34 কক্ষে নিম্নলিখিত সূত্রটি সন্নিবেশ করুন এবং Enter টিপুন .
=B34/C34
- এর পর, E34 কক্ষে নিম্নলিখিত সূত্রটি ব্যবহার করুন .
=D34/D28
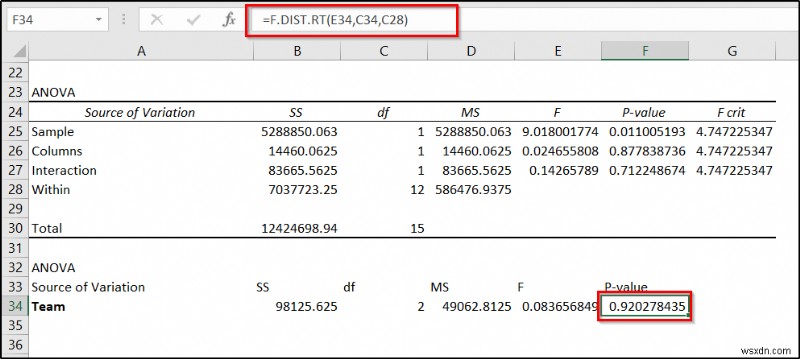
- অবশেষে, সেল F34 -এ নিম্নলিখিত সূত্রটি ব্যবহার করুন এবং তারপর Enter টিপুন .
=F.DIST.RT(E34,C34,C28)
ফলাফলের ব্যাখ্যা
যদি একটি ANOVA বিশ্লেষণ থেকে একটি ফ্যাক্টরের একটি p-মান 0.05 এর কম একটি মান দেয় তবে এটি ডেটাতে একটি উল্লেখযোগ্য প্রভাব ফেলে। এই উদাহরণে, আমাদের দুটি ফ্যাক্টর ছিল- স্টোর এবং দল, যেখানে দলগুলি স্টোরের ভিতরে নেস্ট করা হয়েছিল। এই ডেটার জন্য দোকানের p-মান হল F25 কক্ষে৷ এবং টিমের p-মান সেলে F34 .
আপনি ফলাফল থেকে দেখতে পাচ্ছেন যে দোকানের পি-মান হল 0.011005 যা 0.05 এর চেয়ে কম। এটি এই ফ্যাক্টরের বিক্রয়ের উপর একটি উল্লেখযোগ্য প্রভাব নির্দেশ করে। ফ্যাক্টর দলের p-মান 0.9202 যা 0.05 এর চেয়ে বেশি। যা ডেটা বা বিক্রয়ের উপর উল্লেখযোগ্য প্রভাব নির্দেশ করে না। তাই আমরা নিরাপদে উপসংহারে পৌঁছাতে পারি যে এই ক্ষেত্রে দলের জন্য কর্মচারীদের সংমিশ্রণের চেয়ে স্টোরের অবস্থান বেশি গুরুত্বপূর্ণ৷
এইভাবে আমরা এক্সেলে একটি নেস্টেড আনোভা সম্পাদন করতে পারি।
Excel-এ Nested ANOVA-এর 2 উপযুক্ত উদাহরণ
নেস্টেড আনোভা সম্পাদনের সাধারণ ধারণা এক্সেলে একই। এখন আমরা বিভিন্ন ক্ষেত্রে এর ব্যবহার প্রদর্শনের জন্য দুটি ভিন্ন উদাহরণে একই প্রয়োগ করব। মনে রাখবেন যে, আমাদের দরকার ডেটা অ্যানালাইসিস টুলপ্যাক রিবনে উপলব্ধ। যদি আপনার কাছে না থাকে তবে কীভাবে দেখতে এখানে ক্লিক করুন ডেটা বিশ্লেষণ টুলপ্যাক সক্ষম করুন .
1. বিভিন্ন দৈর্ঘ্যের সাথে প্রতিরোধের ভিন্নতা গণনা করা হচ্ছে
এই প্রথম উদাহরণে, আমরা নিম্নলিখিত ডেটাসেট ব্যবহার করব।
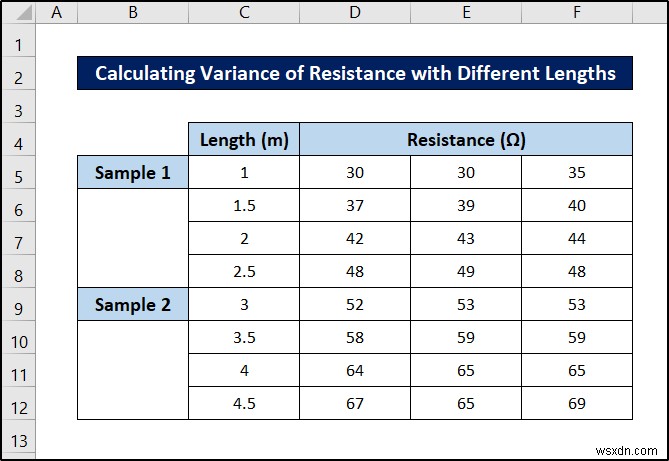
আপনি বলতে পারেন এখানে দুটি নেস্ট রয়েছে- প্রতিরোধের মানগুলি দৈর্ঘ্যের ভিতরে থাকে, যা ঘুরে ঘুরে বিভিন্ন নমুনার ভিতরে থাকে৷
কিন্তু মূল ধারণা হল প্রতিলিপি সহ দুই-ফ্যাক্টর ব্যবহার করা ডেটাসেটের জন্য। তাই আমাদের এইভাবে ডেটাসেট দরকার। এবং ঠিক আগের মতই, আমাদের F.DIST.RT ফাংশন দরকার শেষ পর্যন্ত ম্যানুয়াল গণনার জন্য। এক্সেলের এই নেস্টেড ডেটাসেটে আমরা কীভাবে ANOVA সম্পাদন করতে পারি তা দেখতে ধাপগুলি অনুসরণ করুন।
পদক্ষেপ:
- প্রথমে, ডেটা -এ যান আপনার রিবনে ট্যাব।
- তারপর ডেটা বিশ্লেষণ নির্বাচন করুন বিশ্লেষণ থেকে গ্রুপ বিভাগ।
- ডেটা বিশ্লেষণ বক্স প্রদর্শিত হবে।
- এখন আনোভা:প্রতিলিপি সহ দুই-ফ্যাক্টর নির্বাচন করুন বিশ্লেষণ টুলস এর অধীনে
- তারপর ঠিক আছে এ ক্লিক করুন .
- পরবর্তী, আনোভা:প্রতিলিপি সহ দুই-ফ্যাক্টর বক্স প্রদর্শিত হবে। বাক্সে নিম্নলিখিত বিবরণ নির্বাচন করুন।
- প্রথমে, পরিসর লিখুন B4:F12 ইনপুট পরিসর হিসাবে।
- দ্বিতীয়, 4 সন্নিবেশ করান নমুনা প্রতি সারি -এ ক্ষেত্র, যেহেতু আমাদের প্রতিটি নেস্টেড ফ্যাক্টরের জন্য চারটি এন্ট্রি আছে।
- আপনি আলফা পরিবর্তন করতে পারেন মান খুব যদি আপনি চান। কিন্তু আমরা এটি 05 এ রাখব আপাতত।
- তৃতীয়, আপনি আউটপুট বিকল্পের অধীনে আপনার ফলাফলগুলি কোথায় প্রদর্শন করতে চান তা নির্বাচন করতে পারেন .
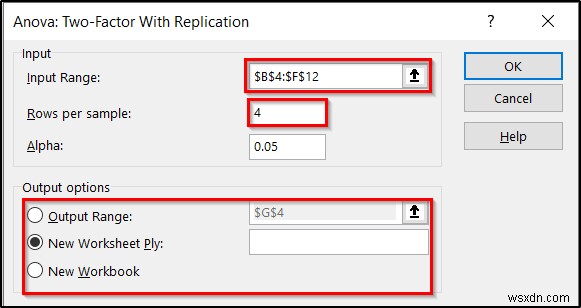
- যখন আপনি এই সব দিয়ে শেষ করেন, তখন ঠিক আছে এ ক্লিক করুন .
- ফলে, ফলাফল আপনার নির্বাচিত স্থানে পপ আপ হবে। আমরা শেষ অংশটি ANOVA এর অধীনে ব্যবহার করব এক্সেলে নেস্টেড আনোভা বিশ্লেষণের জন্য।
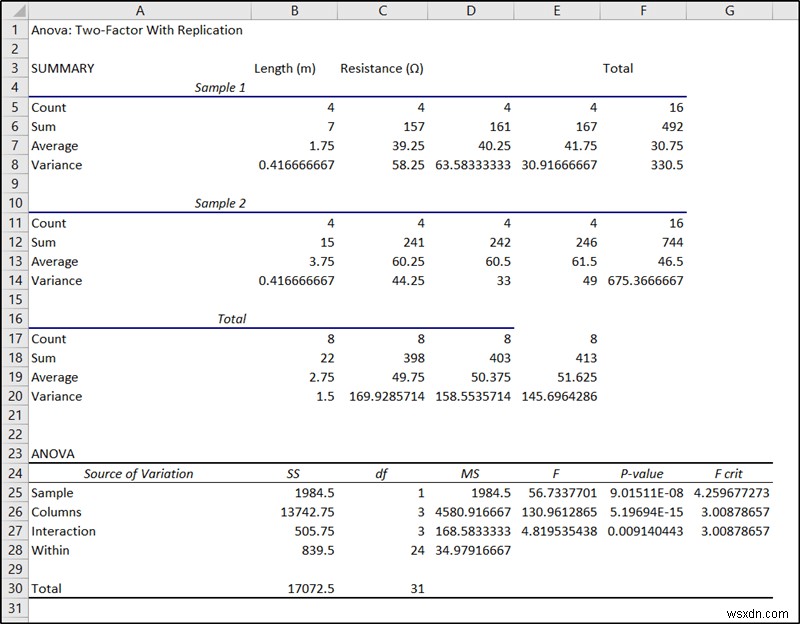
- কক্ষে নমুনার p-মান F25 নমুনার তাৎপর্য নির্দেশ করে যা এই ক্ষেত্রে, প্রথম ফ্যাক্টর, নমুনা।
- এখন সেল B34 নির্বাচন করুন এবং নিম্নলিখিত সূত্রটি লিখুন।
=B26+B27
- তারপর এন্টার টিপুন .
- এখন C34 ঘরে নিচের সূত্রটি লিখুন এবং Enter টিপুন .
=C26+C27
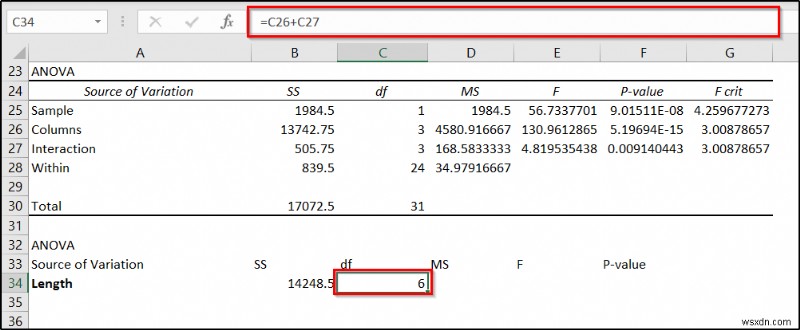
- এরপর, D34 কক্ষে নিম্নলিখিত সূত্রটি সন্নিবেশ করুন এবং Enter টিপুন .
=B34/C34
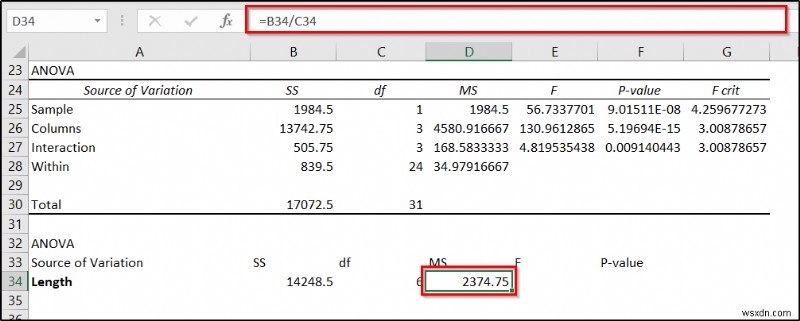
- এর পর, E34 কক্ষে নিম্নলিখিত সূত্রটি ব্যবহার করুন .
=D34/D28
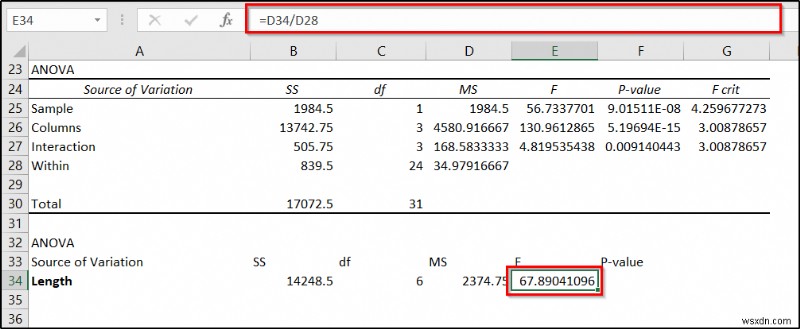
- অবশেষে, সেল F34 -এ নিম্নলিখিত সূত্রটি ব্যবহার করুন এবং তারপর Enter টিপুন .
=F.DIST.RT(E34,C34,C28)
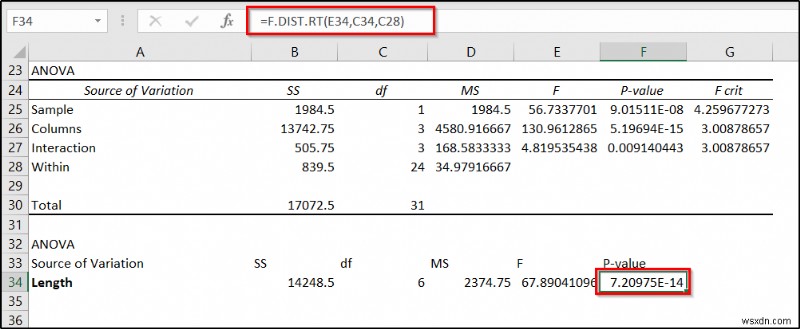
ফলাফলের ব্যাখ্যা
চূড়ান্ত ফলাফলে, কক্ষে p-মান F25 নমুনার তাৎপর্য (বিভিন্ন দৈর্ঘ্যের) এবং কক্ষের মান নির্দেশ করে F34 প্রতিরোধের উপর দৈর্ঘ্যের তাৎপর্য নির্দেশ করে। যেহেতু তাদের উভয়ই 0.05 এর আলফা মানের নিচে, তারা উভয়ই এই উদাহরণে উল্লেখযোগ্য ফ্যাক্টর।
আরো পড়ুন: এক্সেল এ ANOVA ফলাফল কিভাবে ব্যাখ্যা করবেন (3 উপায়)
একই রকম পড়া
- এক্সেল এ রিগ্রেশন কিভাবে সম্পাদন করতে হয় এবং ANOVA এর ব্যাখ্যা
- এক্সেলে এক উপায়ে আনোভা করুন (২টি উপযুক্ত উদাহরণ)
- এক্সেলে আনোভা ফলাফল কীভাবে গ্রাফ করবেন (৩টি উপযুক্ত উদাহরণ)
- এক্সেলে অ্যানোভা কিভাবে পুনরাবৃত্তি করা যায় (সহজ পদক্ষেপ সহ)
2. বিভিন্ন বিভাগ থেকে চিহ্নের ভিন্নতা বিশ্লেষণ করা
এই দ্বিতীয় উদাহরণে, আমরা নিম্নলিখিত ডেটাসেট ব্যবহার করব।
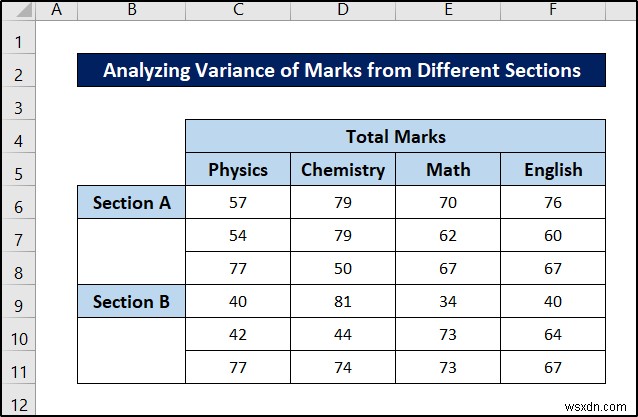
আবার, এটি একটি দ্বি-মুখী ANOVA-এর জন্য একটি ডেটাসেটের মতো দেখতে হতে পারে৷ কিন্তু এটি এক্সেলে বিশ্লেষণ করার জন্য একটি পুনর্বিন্যস্ত নেস্টেড আনোভা। এবং ঠিক আগের মতই, আমাদের F.DIST.RT ফাংশন দরকার শেষ পর্যন্ত ম্যানুয়াল গণনার জন্য।
আপনি কিভাবে Excel এ নেস্টেড ANOVA সম্পাদন করতে পারেন তা দেখতে এই পদক্ষেপগুলি অনুসরণ করুন৷
৷পদক্ষেপ:
- প্রথমে, ডেটা -এ যান আপনার রিবনে ট্যাব।
- তারপর ডেটা বিশ্লেষণ নির্বাচন করুন বিশ্লেষণ থেকে গ্রুপ বিভাগ।
- ডেটা বিশ্লেষণ বক্স প্রদর্শিত হবে।
- এখন আনোভা:প্রতিলিপি সহ দুই-ফ্যাক্টর নির্বাচন করুন বিশ্লেষণ টুলস এর অধীনে
- তারপর ঠিক আছে এ ক্লিক করুন .
- পরবর্তী, আনোভা:প্রতিলিপি সহ দুই-ফ্যাক্টর বক্স প্রদর্শিত হবে। বাক্সে নিম্নলিখিত বিবরণ নির্বাচন করুন।
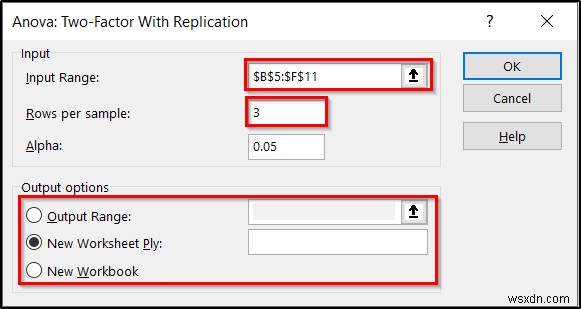
- First, enter the range B5:F11 as the input range.
- Second, insert 3 in the Rows per sample field, as we have three entries for each of the nested factors.
- You can change the Alpha value too if you like. But we will keep it at 05 for now.
- Third, you can select where you want your results to display under the Output options .
- When you are done with all of these, click on OK .
- As a result, the result will pop up at the location you selected. We will use the last portion under ANOVA for the nested ANOVA analysis in Excel.
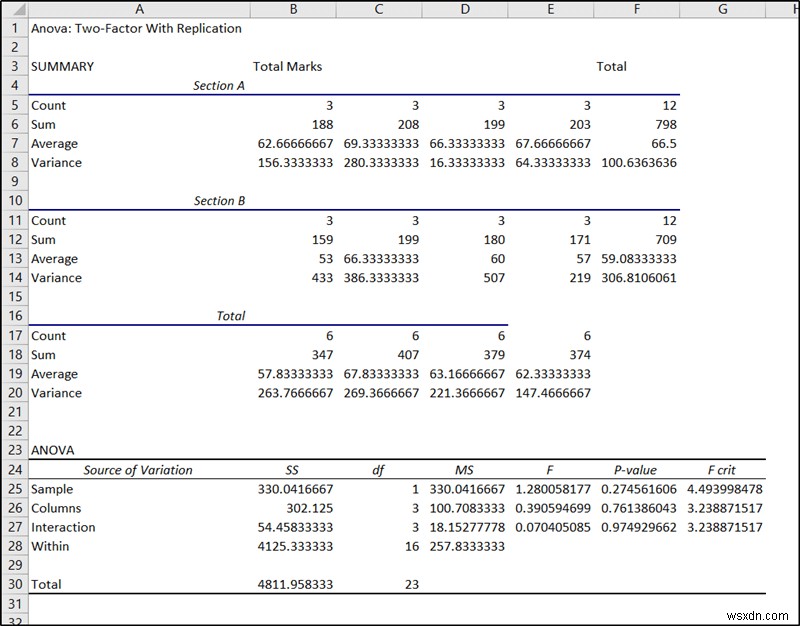
- The p-value of the sample in cell F25 indicates the significance of the sample which is, in this case, the first factor, section.
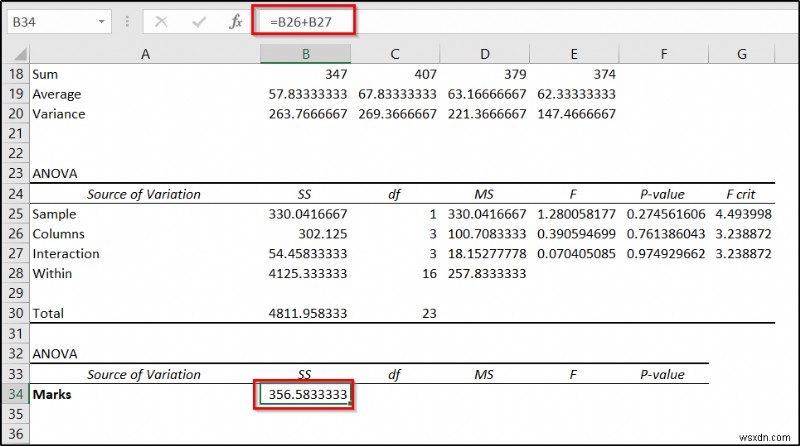
- Now select cell B34 এবং নিম্নলিখিত সূত্রটি লিখুন।
=B26+B27
- Then press Enter .
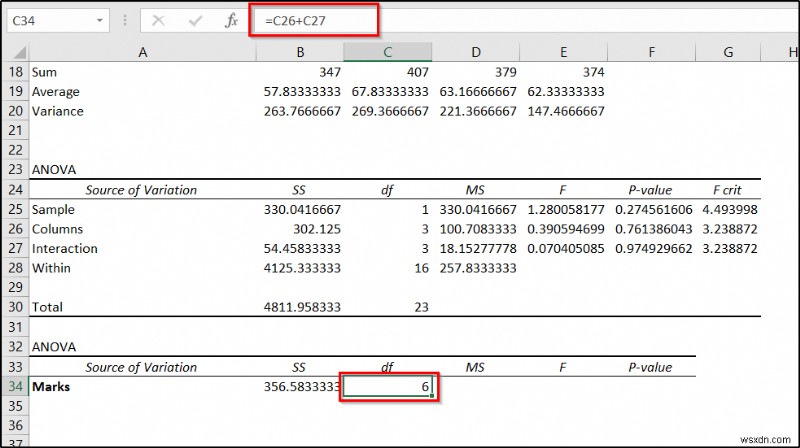
- Now enter the following formula in cell C34 এবং Enter টিপুন .
=C26+C27
- Next, insert the following formula in cell D34 এবং Enter টিপুন .
=B34/C34
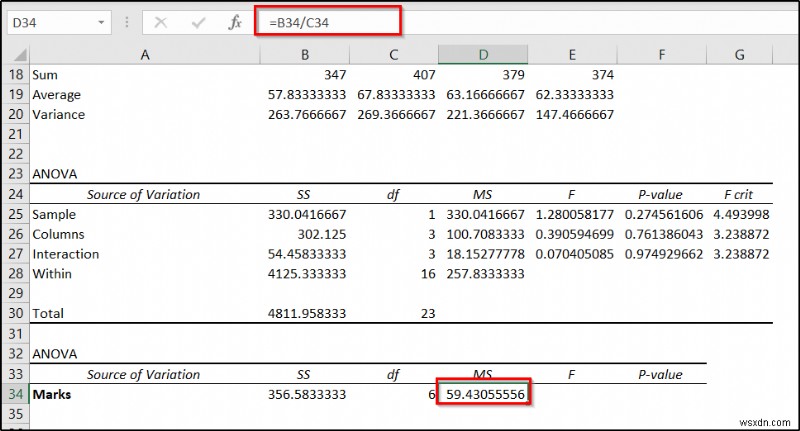
- After that, use the following formula in cell E34 .
=D34/D28
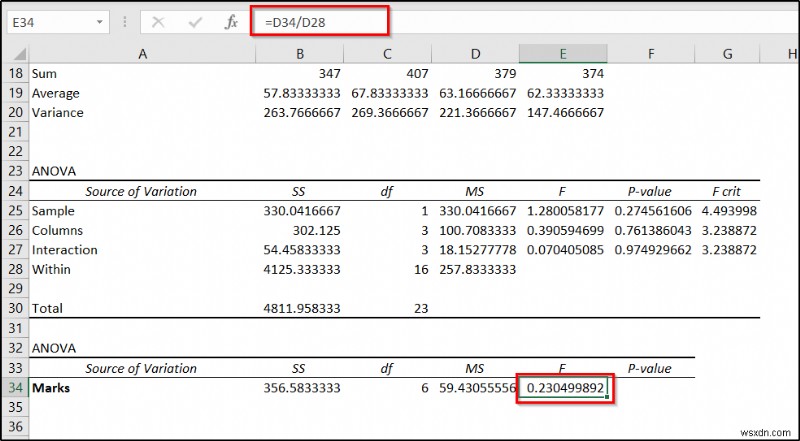
- Finally, use the following formula in cell F34 and then press Enter .
=F.DIST.RT(E34,C34,C28)
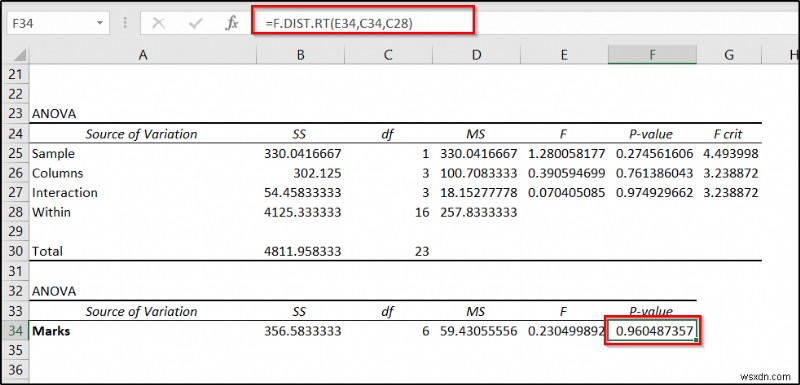
Interpretation of the Result
The p-value in cell F25 indicates the significance of the section on the statistics. This value is greater than the alpha value of 0.05. So this doesn’t have much significance. The cell value of F34 is the p-value of subject marks in the dataset. This, too, is higher than 0.05. So, again, this doesn’t have any significant effect on the marks on different subjects in different sections too for this dataset.
This is another example of how we can perform nested ANOVA in Excel.
আরো পড়ুন: How to Calculate P Value in Excel ANOVA (3 Suitable Examples)
Things You Should Remember About Nested ANOVA
- A nested ANOVA can have more than two factors. Like the one used in the first example of the previous section, a factor can be nested into one factor. That factor can also be nested into another one on the hierarchy along with other factors of the same level.
- A nested ANOVA is different than a two-way ANOVA. A two-factor ANOVA consists of two factors. Meanwhile, a nested ANOVA must have one of those factors nested inside the other. Which isn’t the case for the two-way ANOVA.
উপসংহার
So this was the method to perform a nested ANOVA in Excel. Hopefully, you have grasped the concept of using nested ANOVA in Excel with the two-way replication feature and can use it accordingly for your datasets. আমি আশা করি আপনি এই গাইডটি সহায়ক এবং তথ্যপূর্ণ পেয়েছেন। আপনার যদি কোন প্রশ্ন বা পরামর্শ থাকে, তাহলে নিচের মন্তব্যে আমাদের জানান।
এই ধরনের আরও গাইডের জন্য, Exceldemy.com দেখুন .
সম্পর্কিত প্রবন্ধ
- How to Apply Rows Per Sample ANOVA in Excel (2 Easy Methods)
- How to Make an ANOVA Table in Excel (3 Suitable Ways)
- Randomized Block Design ANOVA in Excel (with Easy Steps)
- How to Use ANOVA Two Factor Without Replication in Excel
