

এক্সেল এর সরলতা এবং নমনীয়তার কারণে অনেক ডেটা বিশ্লেষকের জন্য একটি গো-টু টুল। কিন্তু বৃহৎ, পুনরাবৃত্তিমূলক বা জটিল ডেটা কাজের জন্য, পাইথন গতি, অটোমেশন এবং উন্নত বিশ্লেষণ প্রদান করে। পাইথনের সাথে এক্সেলকে একীভূত করার মাধ্যমে, আপনি উভয় জগতের সেরা সুবিধা পেতে পারেন।
এই টিউটোরিয়ালে, আমরা দেখাব কিভাবে একটি শক্তিশালী ডেটা সায়েন্স ওয়ার্কফ্লো এর জন্য পাইথনের সাথে এক্সেলকে একত্রিত করা যায়।
প্রয়োজনীয় টুল এবং সেটআপ
পাইথনের সাথে এক্সেল একত্রিত করার আগে, পরিবেশ সেট আপ করুন। এটি নিশ্চিত করে যে আপনার কর্মপ্রবাহটি প্রথম ধাপ থেকেই মসৃণ এবং উত্পাদনশীল।
পূর্বশর্ত:
- Microsoft Excel :প্রাথমিক তথ্য পর্যালোচনা এবং প্রতিবেদনের জন্য।
- Python 3.x :আপনার ডেটা বিজ্ঞান কর্মপ্রবাহের ইঞ্জিন৷ ৷
- পাইথন লাইব্রেরি :
- পান্ডা তথ্য বিশ্লেষণের জন্য।
- matplotlib প্লট করার জন্য।
- openpyxl (ঐচ্ছিক, এক্সেল ফাইল লেখার জন্য)।
- numpy (সংখ্যা)।
- matplotlib/seaborn ভিজ্যুয়ালাইজেশনের জন্য।
পাইথন লাইব্রেরি ইনস্টল করুন:
pip install pandas matplotlib openpyxl
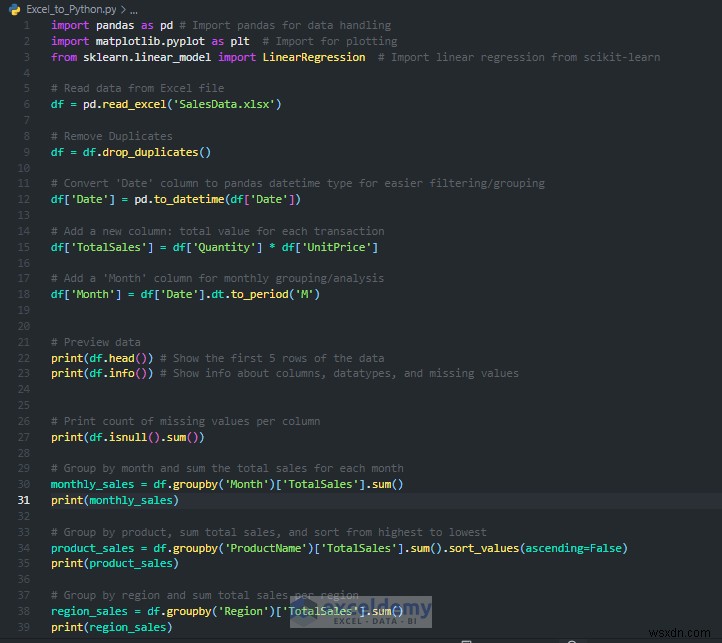
1. পাইথনে ডেটা পড়ুন
আপনি পান্ডা ব্যবহার করে পাইথনে আপনার ডেটা লোড করতে পারেন, যা ট্যাবুলার ডেটা ম্যানিপুলেট এবং বিশ্লেষণ করা সহজ করে তোলে৷
import pandas as pd
# Read data from Excel file
df = pd.read_excel('SalesData.xlsx')
# Preview data
print(df.head()) # Show the first 5 rows of the data
print(df.info()) # Show info about columns, datatypes, and missing values
- pd.read_csv() এক্সেল ফাইলটিকে একটি পান্ডাস ডেটাফ্রেমে পড়ে।
- df.head() প্রথম পাঁচটি সারি প্রদর্শন করে, এটি দ্রুত পরীক্ষা করার জন্য দুর্দান্ত৷
- df.info() সারি, কলাম এবং ডেটাটাইপের সংখ্যা দেখায়।
আপনি আপনার বিক্রয় ডেটার প্রথম কয়েকটি সারি দেখতে পাবেন, যেমন একটি সারাংশ সহ:
TransactionID Date CustomerID ProductID ProductName Category Quantity UnitPrice Region Channel SalesRep 0 100001 2024-01-02 C-100 P-101 Laptop Electronics 2.0 800.0 East Online Smith 1 100002 2024-01-02 C-101 P-102 Printer Electronics 1.0 200.0 West Retail Johnson 2 100003 2024-01-03 C-102 P-103 Mouse Electronics 5.0 25.0 North Online Lee 3 100004 2024-01-04 C-103 P-104 Desk Furniture 1.0 150.0 South Retail Brown 4 100005 2024-01-05 C-104 P-105 Monitor Electronics 3.0 175.0 NaN Online Davis <class 'pandas.core.frame.DataFrame'> RangeIndex: 63 entries, 0 to 62 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 TransactionID 63 non-null int64 1 Date 62 non-null datetime64[ns] 2 CustomerID 62 non-null object 3 ProductID 61 non-null object 4 ProductName 63 non-null object 5 Category 61 non-null object 6 Quantity 61 non-null float64 7 UnitPrice 62 non-null float64 8 Region 62 non-null object 9 Channel 62 non-null object 10 SalesRep 62 non-null object dtypes: datetime64[ns](1), float64(2), int64(1), object(7) memory usage: 5.5+ KB None
2. ডেটা ক্লিনিং এবং ট্রান্সফরমেশন
কাঁচা ডেটা বিশ্লেষণের জন্য খুব কমই প্রস্তুত। এই ধাপে, আপনি অনুপস্থিত মানগুলি ঠিক করবেন, কলামগুলিকে সঠিক প্রকারে রূপান্তর করবেন এবং নতুন গণনা করা ক্ষেত্র যোগ করবেন।
সদৃশগুলি সরান:৷
# Remove Duplicates df = df.drop_duplicates()
- ডুপ্লিকেট মান ফেলে দেয়।
অনুপস্থিত মান পরীক্ষা করুন:
# Print count of missing values per column print(df.isnull().sum())
- এটি দেখায় প্রতিটি কলামে কতগুলি অনুপস্থিত (NaN) মান রয়েছে। যদি কোনটি পাওয়া যায়, আপনি সেগুলি ফেলে দেওয়ার বা পূরণ করার সিদ্ধান্ত নিতে পারেন৷
#Output: TransactionID 0 Date 1 CustomerID 1 ProductID 2 ProductName 0 Category 2 Quantity 2 UnitPrice 1 Region 1 Channel 1 SalesRep 1 dtype: int64
ডেটা প্রকার রূপান্তর করুন:
# Convert 'Date' column to pandas datetime type for easier filtering/grouping df['Date'] = pd.to_datetime(df['Date'])
- এটি সহজ ফিল্টারিং এবং গ্রুপিংয়ের জন্য তারিখ কলামকে পাঠ্য থেকে পান্ডা ডেটটাইম ফর্ম্যাটে রূপান্তর করে৷
একটি 'টোটাল সেলস' কলাম তৈরি করুন:
# Add a new column: total value for each transaction df['TotalSales'] = df['Quantity'] * df['UnitPrice']
- প্রতিটি লেনদেনের মোট মূল্য দেখানো একটি নতুন কলাম যোগ করে।
সময় সিরিজ বিশ্লেষণের জন্য মাস বের করুন:
df['Month'] = df['Date'].dt.to_period('M')
- এটি গ্রুপ করার জন্য একটি মাস কলাম তৈরি করে এবং মাস অনুসারে বিক্রয় বিশ্লেষণ করে।
- এখন পরিষ্কার করা ডেটার পূর্বরূপ দেখতে print(df.head()) ব্যবহার করুন।
#Ouput: TransactionID Date CustomerID ProductID ProductName Category ... UnitPrice Region Channel SalesRep TotalSales Month 0 100001 2024-01-02 C-100 P-101 Laptop Electronics ... 800.0 East Online Smith 1600.0 2024-01 1 100002 2024-01-02 C-101 P-102 Printer Electronics ... 200.0 West Retail Johnson 200.0 2024-01 2 100003 2024-01-03 C-102 P-103 Mouse Electronics ... 25.0 North Online Lee 125.0 2024-01 3 100004 2024-01-04 C-103 P-104 Desk Furniture ... 150.0 South Retail Brown 150.0 2024-01 4 100005 2024-01-05 C-104 P-105 Monitor Electronics ... 175.0 NaN Online Davis 525.0 2024-01
3. আপনার ডেটা বিশ্লেষণ করুন
একটি পরিষ্কার ডেটাসেটের সাহায্যে, আপনি এখন এমন অন্তর্দৃষ্টি তৈরি করতে পারেন যা ব্যবসার মূল্যকে চালিত করে। এর মধ্যে রয়েছে মাস, পণ্য এবং অঞ্চল অনুসারে মোট বিক্রয়।
মাস অনুসারে মোট বিক্রয়:
# Group by month and sum the total sales for each month
monthly_sales = df.groupby('Month')['TotalSales'].sum()
print(monthly_sales)
- মাস অনুসারে ডেটা গোষ্ঠী করে এবং প্রতি মাসের জন্য মোট বিক্রয় যোগ করে।
#Output: Month 2024-01 9075.0 2024-02 9800.0 2024-03 9075.0 Freq: M, Name: TotalSales, dtype: float64
সর্বোচ্চ বিক্রিত পণ্য:
# Group by product, sum total sales, and sort from highest to lowest
product_sales = df.groupby('ProductName')['TotalSales'].sum().sort_values(ascending=False)
print(product_sales)
- পণ্য প্রতি বিক্রয়ের যোগফল, তারপর সেগুলিকে সর্বাধিক থেকে কম জনপ্রিয় পর্যন্ত সাজান৷ ৷
#Output: ProductName Laptop 15200.0 Monitor 3850.0 Printer 3200.0 Desk 2550.0 Chair 2325.0 Mouse 1125.0 Name: TotalSales, dtype: float64
অঞ্চল অনুসারে বিক্রয়:
# Group by region and sum total sales per region
region_sales = df.groupby('Region')['TotalSales'].sum()
print(region_sales)
- প্রতিটি অঞ্চল দ্বারা মোট বিক্রয় সমষ্টি।
#Output: Region East 6075.0 North 5925.0 South 8225.0 West 7500.0
4. মূল অন্তর্দৃষ্টি ভিজ্যুয়ালাইজ করুন
ভিজ্যুয়ালাইজ করার সময় ডেটা আরও শক্তিশালী। আসুন আপনাকে এবং স্টেকহোল্ডারদের মূল প্রবণতাগুলিকে এক নজরে বুঝতে সাহায্য করার জন্য দ্রুত চার্ট তৈরি করি৷
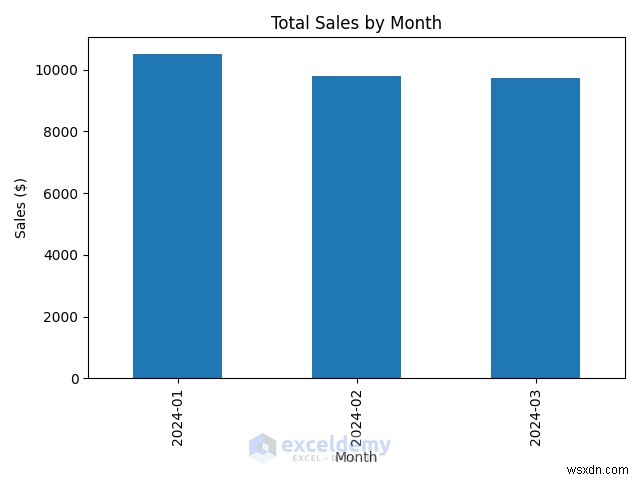
4.1. মাসিক বিক্রয় প্রবণতা
import matplotlib.pyplot as plt # Import for plotting
# Create a bar chart of sales by month
monthly_sales.plot(
kind='bar',
title='Total Sales by Month',
ylabel='Sales ($)',
xlabel='Month'
)
plt.tight_layout() # Avoid label overlap
plt.savefig('monthly_sales.png') # Save the figure as a PNG file
plt.show() # Display the chart - বার চার্ট হিসাবে মাসিক বিক্রয় প্লট করে।
- plt.savefig প্রতিবেদনের জন্য চার্ট সংরক্ষণ করে
- একটি বার চার্ট প্রতি মাসে বিক্রয় পরিবর্তন দেখাবে।
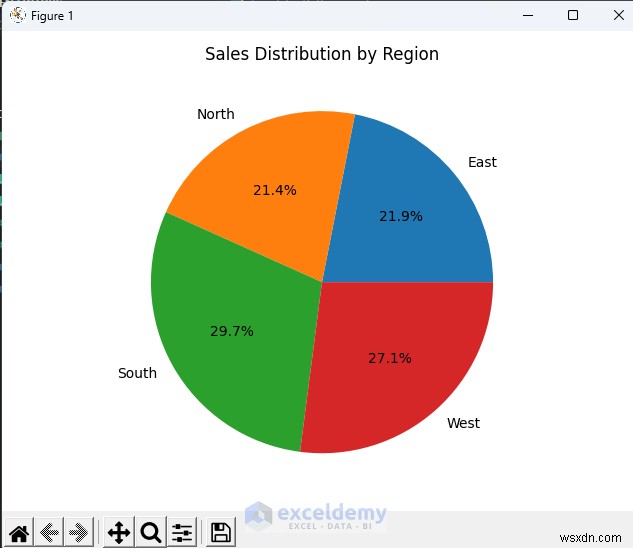
4.2. অঞ্চল অনুসারে বিক্রয়
# Pie chart of sales by region
region_sales.plot(
kind='pie',
autopct='%1.1f%%',
title='Sales Distribution by Region'
)
plt.ylabel('') # Remove default y-label
plt.tight_layout()
plt.savefig('region_sales.png')
plt.show()
- অঞ্চল অনুসারে বিক্রয়ের পাই চার্ট, ব্যবস্থাপনা বা বিপণনের জন্য দুর্দান্ত।
5. উন্নত বিশ্লেষণ এবং মডেলিং
মৌলিক গ্রুপিং এবং সারাংশের বাইরে, Python উন্নত পরিসংখ্যান বিশ্লেষণ, পিভট টেবিল এবং এমনকি মেশিন লার্নিং সক্ষম করে, সব কিছু মাত্র কোডের কয়েকটি লাইন দিয়ে। আসুন আরও বেশি অন্তর্দৃষ্টি আনলক করতে ডেটার গভীরে খনন করি৷
৷5.1. বর্ণনামূলক পরিসংখ্যান
বর্ণনামূলক পরিসংখ্যান আপনাকে আপনার ডেটাসেটের একটি দ্রুত সারাংশ দেয়, মানে, মানক বিচ্যুতি এবং সাংখ্যিক কলামগুলির জন্য কোয়ান্টাইলগুলি দেখায়৷
# Show summary statistics for numeric columns (mean, std, min, max, quartiles, etc.) print(df.describe())
- df.describe() দ্রুত সমস্ত সাংখ্যিক কলামের সংক্ষিপ্তসার (যেমন পরিমাণ, ইউনিটমূল্য, মোট বিক্রয়)।
#Output: TransactionID Quantity UnitPrice TotalSales count 61.000000 59.000000 60.000000 59.000000 mean 100030.180328 2.542373 262.083333 478.813559 std 17.497150 1.534905 277.339497 527.085627 min 100001.000000 1.000000 25.000000 75.000000 25% 100015.000000 1.000000 75.000000 162.500000 50% 100030.000000 2.000000 175.000000 300.000000 75% 100045.000000 3.000000 200.000000 525.000000 max 100060.000000 7.000000 800.000000 2400.000000
5.2. পান্ডায় পিভট টেবিল
Excel এ ইন্টারেক্টিভ রিপোর্টিংয়ের জন্য পিভট টেবিল শক্তিশালী, এবং পান্ডারাও সেগুলি করতে পারে।
# Create a pivot table: sum TotalSales for each Region pivot = df.pivot_table(index='Region', values='TotalSales', aggfunc='sum') print(pivot)
- পিভট_টেবিল() এক্সেলের পিভট টেবিলের অনুরূপ প্রতিটি অঞ্চলের জন্য মোট বিক্রয়ের সারসংক্ষেপ।
#Output TotalSales Region East 6075.0 North 5925.0 South 8225.0 West 7500.0
5.3. সহজ মেশিন লার্নিং উদাহরণ
দেখা যাক একটি সাধারণ রৈখিক রিগ্রেশন (মেশিন লার্নিং) মডেল ব্যবহার করে বিক্রি হওয়া পরিমাণ থেকে আমরা মোট বিক্রয় অনুমান করতে পারি কিনা।
from sklearn.linear_model import LinearRegression # Import linear regression from scikit-learn
# Prepare features and target variable
X = df[['Quantity']] # Feature: Quantity sold
y = df['TotalSales'] # Target: Total sales value
# Create and fit the regression model
model = LinearRegression()
model.fit(X, y)
# Print the regression coefficient (slope)
print('Coefficient:', model.coef_)
# Print the intercept (base value when Quantity=0)
print('Intercept:', model.intercept_) - স্কিট-লার্ন থেকে লিনিয়ার রিগ্রেশন আমদানি করে।
- মোট বিক্রির পূর্বাভাস দিতে পরিমাণ ব্যবহার করে।
- মডেলের সাথে মানানসই এবং গুণাঙ্ক প্রিন্ট করে (বিক্রীত অতিরিক্ত ইউনিট প্রতি কত বিক্রয় বৃদ্ধি পায়)।
#Output: Coefficient: [-37.65294772] Intercept: 596.8483500185391
6. রপ্তানি করা পরিচ্ছন্ন/বিশ্লেষিত ডেটা এক্সেলে ফিরে যান
আপনার ডেটা পরিষ্কার, বিশ্লেষণ এবং মডেল করার পরে, আপনি একটি মাল্টি-শীট এক্সেল ফাইলে আপনার সারাংশ টেবিল এবং অন্তর্দৃষ্টি রপ্তানি করতে পারেন। এটি আপনার সমস্ত মূল অনুসন্ধানগুলিকে একত্রে রাখে এবং এক্সেলে পর্যালোচনার জন্য প্রস্তুত৷
৷# Export summary and advanced analysis tables to a multi-sheet Excel file
with pd.ExcelWriter('sales_summary.xlsx') as writer:
# Monthly summary
monthly_sales.to_frame().to_excel(writer, sheet_name='Monthly Sales')
# Product summary
product_sales.to_frame().to_excel(writer, sheet_name='Product Sales')
# Region summary
region_sales.to_frame().to_excel(writer, sheet_name='Region Sales')
# Pivot table (total sales by region)
pivot.to_excel(writer, sheet_name='Pivot Table')
# Optionally, you can export descriptive statistics
df.describe().to_excel(writer, sheet_name='Descriptive Stats')
- প্রসঙ্গ ম্যানেজার (সাথে ... লেখক হিসাবে): নিশ্চিত করে Excel ফাইলটি সঠিকভাবে সংরক্ষিত এবং লেখার পরে বন্ধ করা হয়েছে।
- .to_excel() প্রতিটি টেবিলের জন্য: সহজে অ্যাক্সেসের জন্য প্রতিটি ডেটাফ্রেম বা সারাংশ তার নিজস্ব শীটে সংরক্ষণ করে৷
- কাস্টম শীটের নাম: প্রতিটি পত্রকের নামকরণ করা হয়েছে স্পষ্টতার জন্য, আপনার বিশ্লেষণের ধাপের সাথে মিলে যায়।
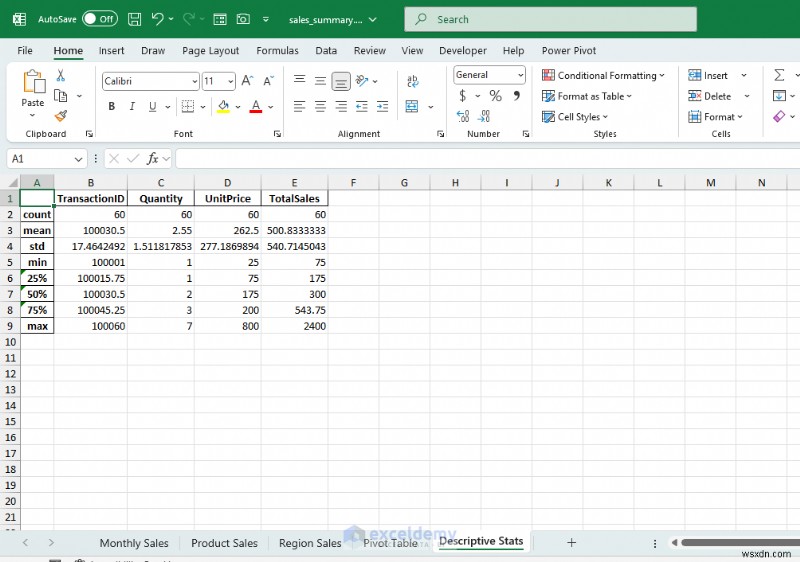
- sales_summary.xlsx খুলুন এক্সেলে।
- আপনি মাসিক বিক্রয়, পণ্য বিক্রয়, অঞ্চল বিক্রয়, আপনার পিভট টেবিল এবং বর্ণনামূলক পরিসংখ্যানের জন্য পৃথক শীট দেখতে পাবেন।
7. আপনার কর্মপ্রবাহ স্বয়ংক্রিয় এবং স্কেল করুন
পাইথন ব্যবহার করে, আপনি পুনরাবৃত্ত প্রতিবেদন বা বিশ্লেষণ স্বয়ংক্রিয় করতে পারেন। পরের বার যখন আপনি একটি নতুন এক্সেল ফাইল পাবেন, শুধু ফাইলটি প্রতিস্থাপন করুন এবং আপনার স্ক্রিপ্ট পুনরায় চালান; সমস্ত বিশ্লেষণ এবং রিপোর্ট অবিলম্বে রিফ্রেশ করা হয়.
- সমস্ত বিশ্লেষণ কোড একটি পাইথন ফাইলে রাখুন।
- আপনার রিপোর্ট আপডেট করতে, CSV প্রতিস্থাপন করুন এবং চালান:
python Excel_to_Python.py
- আরও বেশি ক্ষমতার জন্য, আপনি এটিকে একটি সাপ্তাহিক/মাসিক কাজ হিসাবে নির্ধারণ করতে পারেন।
উপসংহার
এক্সেলের স্বজ্ঞাত ডেটা এন্ট্রি এবং পাইথনের ডেটা সায়েন্স পাওয়ারের সাথে রিপোর্টিং একত্রিত করে, আপনি বড়, অগোছালো ডেটাসেটগুলিকে দক্ষতার সাথে প্রক্রিয়া এবং বিশ্লেষণ করতে পারেন। এটি পুনরাবৃত্তিমূলক প্রতিবেদনের কাজগুলিকে স্বয়ংক্রিয় করে। মেশিন লার্নিং এবং উন্নত ভিজ্যুয়ালাইজেশন আনলক করে। আপনাকে রাতারাতি পাইথন বিশেষজ্ঞ হওয়ার দরকার নেই। একটি সহজ কাজ দিয়ে শুরু করুন; একবার এটি কাজ করে, আরও একটি ধাপ যোগ করুন। আপনি এটি জানার আগে, আপনি জটিল প্রতিবেদনগুলি স্বয়ংক্রিয়ভাবে তৈরি করবেন।
সমাধান সহ বিনামূল্যে উন্নত এক্সেল ব্যায়াম পান!