
“সরলতা হল চূড়ান্ত পরিশীলিততা” —লিওনার্দো দা ভিঞ্চি
“বেশিরভাগ তথ্যই অপ্রাসঙ্গিক এবং বেশিরভাগ প্রচেষ্টাই নষ্ট হয়, কিন্তু শুধুমাত্র বিশেষজ্ঞই জানেন কী উপেক্ষা করতে হবে ”—জেমস ক্লিয়ার, পারমাণবিক অভ্যাস
আপনার কাছে অনেকগুলি বিভিন্ন সিস্টেম সহ অভিনব ডেটা পাইপলাইন রয়েছে৷ এটি পৃষ্ঠে খুব পরিশীলিত দেখায়, তবে এটি আসলে হুডের নীচে একটি জটিল জগাখিচুড়ি। বিভিন্ন অংশকে সংযুক্ত করার জন্য এটির অনেক প্লাম্বিং কাজের প্রয়োজন হতে পারে, এটির জন্য ক্রমাগত পর্যবেক্ষণের প্রয়োজন হতে পারে, এটি চালানো, ডিবাগ এবং পরিচালনা করার জন্য অনন্য দক্ষতা সহ একটি বড় দলের প্রয়োজন হতে পারে। উল্লেখ করার মতো নয়, আপনি যত বেশি সিস্টেম ব্যবহার করবেন, তত বেশি জায়গায় আপনি আপনার ডেটা নকল করছেন এবং এটি সিঙ্কের বাইরে বা বাসি হওয়ার সম্ভাবনা তত বেশি। উপরন্তু, যেহেতু এই সাবসিস্টেমগুলির প্রত্যেকটি বিভিন্ন কোম্পানির দ্বারা স্বাধীনভাবে বিকশিত হয়েছে, তাদের আপগ্রেড বা বাগ ফিক্সগুলি আপনার পাইপলাইন এবং আপনার ডেটা স্তরকে ভেঙে দিতে পারে।
আপনি যদি সতর্ক না হন, তাহলে নিচের তিন মিনিটের ভিডিওতে চিত্রিত হিসাবে আপনি নিম্নলিখিত পরিস্থিতির সাথে শেষ হতে পারেন। আমি আপনাকে অগ্রসর হওয়ার আগে এটি দেখার সুপারিশ করছি৷
৷
জটিলতা দেখা দেয় কারণ যদিও প্রতিটি সিস্টেম পৃষ্ঠায় সহজ মনে হতে পারে, তবুও তারা আসলে নিম্নলিখিত ভেরিয়েবলগুলিকে আপনার পাইপলাইনে নিয়ে আসে এবং এক টন জটিলতা যোগ করতে পারে:
- প্রটোকল—কীভাবে সিস্টেম ডেটা পরিবহন করে? (HTTP, TCP, REST, GraphQL, FTP, JDBC)
- ডেটা ফরম্যাট—সিস্টেমটি কোন ফর্ম্যাট সমর্থন করে? (বাইনারী, CSV, JSON, Avro)
- ডেটা স্কিমা এবং বিবর্তন—কীভাবে ডেটা সংরক্ষণ করা হয়? (সারণী, স্ট্রীম, গ্রাফ, নথি)
- SDKs এবং APIs — সিস্টেম কি প্রয়োজনীয় SDK এবং API প্রদান করে?
- ACID এবং BASE—এটি কি ACID বা BASE সামঞ্জস্য প্রদান করে?
- মাইগ্রেশন—সিস্টেমটি কি সমস্ত ডেটা সিস্টেমের মধ্যে বা দূরে স্থানান্তর করার একটি সহজ উপায় প্রদান করে?
- স্থায়িত্ব—কিসের নিশ্চয়তা দেয় সিস্টেমের স্থায়িত্বের কাছাকাছি?
- ইলিটি—প্রাপ্যতার আশেপাশে সিস্টেমের কী গ্যারান্টি আছে? (99.9%, 99.999%)
- স্কেলেবিলিটি—এটি কিভাবে মাপ করে?
- নিরাপত্তা—সিস্টেমটি কতটা নিরাপদ?
- পারফরম্যান্স—ডাটা প্রক্রিয়াকরণে সিস্টেম কত দ্রুত?
- হোস্টিং অপশন—এটি কি হোস্ট করা বা অন-প্রিমিসে নাকি একটি মিশ্রণ?
- ক্লাউডস—এটি কি আমার মেঘ, অঞ্চল ইত্যাদিতে কাজ করে?
- অতিরিক্ত সিস্টেম—এতে কি অতিরিক্ত সিস্টেমের প্রয়োজন আছে? (যেমন কাফকার জন্য চিড়িয়াখানা)
ডেটা ফরম্যাট, স্কিমা এবং প্রোটোকলের মতো ভেরিয়েবলগুলিকে "ট্রান্সফর্মেশন ওভারহেড" বলা হয়। অন্যান্য ভেরিয়েবল যেমন কর্মক্ষমতা, স্থায়িত্ব এবং স্কেলেবিলিটি "পাইপলাইন ওভারহেড" নামে পরিচিত। একসাথে রাখুন, এই শ্রেণীবিভাগগুলি "প্রতিবন্ধকতা অমিল" হিসাবে পরিচিত যাকে অবদান রাখে। যদি আমরা এটি পরিমাপ করতে পারি, আমরা জটিলতা গণনা করতে পারি এবং আমাদের সিস্টেমকে সরল করতে এটি ব্যবহার করতে পারি। আমরা কিছুক্ষণের মধ্যে এটিতে পৌঁছাব।
এখন, আপনি যুক্তি দিতে পারেন যে আপনার সিস্টেম, যদিও এটি জটিল বলে মনে হতে পারে, আসলে এটি আপনার প্রয়োজনের জন্য সবচেয়ে সহজ সিস্টেম। কিন্তু কিভাবে আপনি এটা প্রমাণ করতে পারেন?
অন্য কথায়, আপনি কীভাবে সত্যিই পরিমাপ করবেন এবং বলবেন যে আপনার ডেটা স্তর সত্যিই সহজ বা জটিল? এবং দ্বিতীয়ত, আপনি আরও বৈশিষ্ট্য যুক্ত করার সাথে সাথে আপনার সিস্টেমটি সহজ থাকবে কিনা তা আপনি কীভাবে অনুমান করতে পারেন? অর্থাৎ, আপনি যদি আপনার রোডম্যাপে আরও বৈশিষ্ট্য যোগ করেন, তাহলে আপনাকে কি আরও সিস্টেম যোগ করতে হবে?
এখানেই "ইম্পিডেন্স অমিল পরীক্ষা" আসে৷ তবে আসুন প্রথমে দেখে নেওয়া যাক একটি প্রতিবন্ধকতা অমিল কী এবং তারপরে আমরা নিজেই পরীক্ষায় নামব৷
ইম্পিডেন্স মিসম্যাচ কি?
শব্দটি বৈদ্যুতিক প্রকৌশলে বৈদ্যুতিক প্রতিবন্ধকতার অমিল ব্যাখ্যা করার জন্য উদ্ভূত হয়েছিল, যার ফলে শক্তির ক্ষতি হয় যখন শক্তি A বিন্দু থেকে বি পয়েন্টে স্থানান্তরিত হয়।
সহজভাবে বললে, এর অর্থ হল আপনার যা আছে তা আপনার যা প্রয়োজন তা মেলে না। এটি ব্যবহার করার জন্য, আপনি বর্তমানে যা আছে তা গ্রহণ করুন, আপনার যা প্রয়োজন তা রূপান্তর করুন এবং তারপরে এটি ব্যবহার করুন। অতঃপর অমিল এবং অমিল ফিক্স করার সাথে যুক্ত একটি ওভারহেড আছে।
আমাদের ক্ষেত্রে, আপনার কাছে কিছু আকারে বা কিছু পরিমাণে ডেটা রয়েছে এবং আমরা এটি ব্যবহার করার আগে আপনাকে এটি রূপান্তর করতে হবে। রূপান্তরটি একাধিকবার ঘটতে পারে এবং এমনকি এর মধ্যে একাধিক সিস্টেম ব্যবহার করতে পারে৷
ডাটাবেস জগতে, প্রতিবন্ধকতা অমিল দুটি কারণে ঘটে:
- ট্রান্সফরমেশনাল ওভারহেড:সিস্টেম যেভাবে ডেটা প্রসেস করে বা স্টোর করে ডেটা আসলে কেমন দেখায়, বা আপনি এটি সম্পর্কে কীভাবে চিন্তা করেন তার থেকে আলাদা। উদাহরণস্বরূপ:আপনার সার্ভারে, আপনার কাছে অনেক ডেটা স্ট্রাকচারে ডেটা সংরক্ষণ করার নমনীয়তা রয়েছে, যেমন সংগ্রহ, স্ট্রীম, তালিকা, সেট, অ্যারে ইত্যাদি। এটি আপনাকে স্বাভাবিকভাবে আপনার ডেটা মডেল করতে সহায়তা করে। যাইহোক, তারপরে আপনাকে RDBMS বা JSON ডকুমেন্ট স্টোরের টেবিলে এই ডেটা ম্যাপ করতে হবে, যাতে সেগুলি সংরক্ষণ করা যায়। তারপর ডেটা পড়ার জন্য বিপরীতটি করুন। উল্লেখ্য যে অবজেক্ট-ওরিয়েন্টেড ল্যাঙ্গুয়েজ মডেল এবং রিলেশনাল টেবিল মডেলের মধ্যে নির্দিষ্ট অমিলকে বলা হয়, "অবজেক্ট-রিলেশনাল ইম্পিডেন্স অমিল।"
- পাইপলাইন ওভারহেড:ডেটার পরিমাণ এবং সার্ভারে আপনি যে ডেটা প্রক্রিয়া করেন তার পরিমাণ আপনার ডাটাবেস পরিচালনা করতে পারে তার থেকে আলাদা। উদাহরণ স্বরূপ:আপনি যদি মোবাইল ডিভাইস থেকে আসা লক্ষ লক্ষ ইভেন্টগুলিকে প্রসেস করছেন, তাহলে আপনার সাধারণ RDBMS বা ডকুমেন্ট স্টোর এটি সংরক্ষণ করতে সক্ষম নাও হতে পারে, অথবা সেই ইভেন্টগুলিকে সহজেই একত্রিত করতে বা গণনা করতে API প্রদান করতে পারে। সুতরাং এটি প্রক্রিয়া করার জন্য আপনার বিশেষ স্ট্রিম-প্রসেসিং সিস্টেমের প্রয়োজন, যেমন কাফকা বা রেডিস স্ট্রীমস, এবং এছাড়াও, এটি সংরক্ষণ করার জন্য একটি ডেটা গুদামও হতে পারে৷
ইম্পিডেন্স মিসম্যাচ টেস্ট
পরীক্ষার লক্ষ্য হল সামগ্রিক প্ল্যাটফর্মের জটিলতা পরিমাপ করা এবং ভবিষ্যতে আপনি আরও বৈশিষ্ট্য যোগ করার সাথে সাথে জটিলতা বাড়বে বা সঙ্কুচিত হবে কিনা।
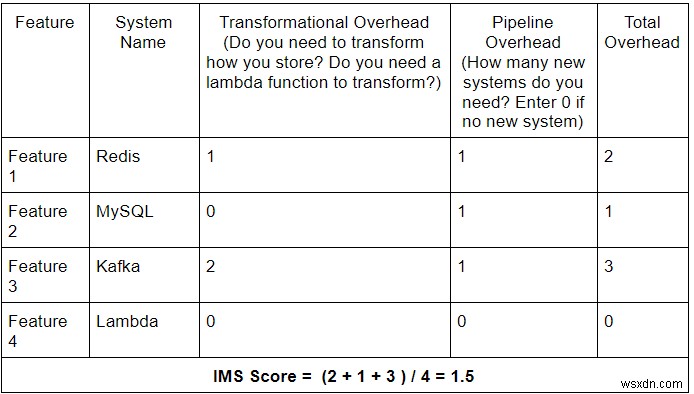
পরীক্ষাটি যেভাবে কাজ করে তা হল একটি "ইম্পিড্যান্স মিসম্যাচ স্কোর" (IMS) ব্যবহার করে "ট্রান্সফরমেশনাল ওভারহেড" এবং "পাইপলাইন ওভারহেড" গণনা করা। এটি আপনাকে বলবে যে আপনার সিস্টেমটি ইতিমধ্যেই অন্যান্য সিস্টেমের তুলনায় জটিল কিনা এবং আপনি আরও বৈশিষ্ট্য যোগ করার সাথে সাথে সেই জটিলতা সময়ের সাথে সাথে বৃদ্ধি পাচ্ছে কিনা৷
এখানে IMS গণনা করার সূত্র:

সূত্রটি সহজভাবে উভয় ধরনের ওভারহেড যোগ করে এবং তারপর বৈশিষ্ট্যের সংখ্যা দ্বারা ভাগ করে। এইভাবে, আপনি মোট ওভারহেড/বৈশিষ্ট্য পাবেন (যেমন জটিলতা স্কোর)।
এটি আরও ভালভাবে বোঝার জন্য, আসুন চারটি ভিন্ন সাধারণ ডেটা পাইপলাইন তুলনা করি এবং তাদের স্কোর গণনা করি। এবং দ্বিতীয়ত, আসুন কল্পনা করি যে আমরা দুটি ধাপে একটি সাধারণ অ্যাপ তৈরি করছি, যাতে আমরা দেখতে পারি যে আমরা সময়ের সাথে সাথে আরও বৈশিষ্ট্য যুক্ত করার সাথে সাথে IMS স্কোর কীভাবে পরিবর্তিত হয়৷
ফেজ 1:একটি রিয়েল-টাইম ড্যাশবোর্ড তৈরি করা
বলুন যে আপনি মোবাইল ডিভাইস থেকে লক্ষ লক্ষ বোতাম-ক্লিক ইভেন্ট পাচ্ছেন এবং কোনো ড্রপ বা স্পাইক থাকলে আপনার একটি সতর্কতা প্রয়োজন। উপরন্তু, আপনি এই সম্পূর্ণ জিনিসটিকে আপনার বৃহত্তর অ্যাপ্লিকেশনের বৈশিষ্ট্য হিসাবে বিবেচনা করছেন।
কেস 1:বলুন আপনি এই ইভেন্টগুলি সঞ্চয় করার জন্য একটি RDBMS ব্যবহার করেছেন, যদিও টেবিলগুলি ফিট নাও হতে পারে৷

- পরিবর্তনমূলক ওভারহেড =1
- আপনাকে ইভেন্ট স্ট্রিমগুলিকে টেবিলে রূপান্তর করতে হবে৷
- পাইপলাইন ওভারহেড =1
- আপনার পাইপলাইনে একটি একক DB আছে।
- বৈশিষ্ট্যের সংখ্যা =1
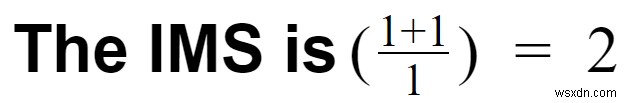
কেস 2:বলুন আপনি এই ইভেন্টগুলি প্রক্রিয়া করার জন্য কাফকা ব্যবহার করেছেন এবং তারপর সেগুলি RDBMS-এ সংরক্ষণ করেছেন৷
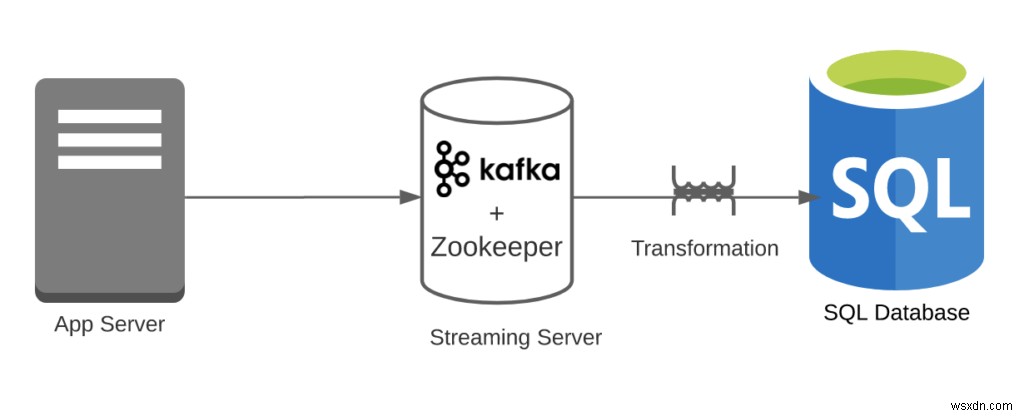
- পরিবর্তনমূলক ওভারহেড =1
- কাফকা সহজেই ক্লিক স্ট্রীম পরিচালনা করতে পারে; যাইহোক, কাফকা থেকে RDBMS একটি ওভারহেড।
- পাইপলাইন ওভারহেড =2
- আপনার দুটি সিস্টেম আছে (RDBMS এবং Kafka)। উল্লেখ্য যে আমরা Zookeeper উপেক্ষা করছি।
- বৈশিষ্ট্যের সংখ্যা =1
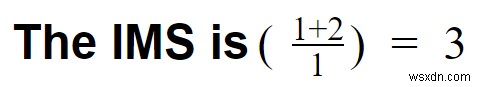
কেস 3:বলুন আপনি এই ইভেন্টগুলি প্রক্রিয়া করার জন্য কাফকা ব্যবহার করেছেন এবং তারপরে সেগুলিকে KsqlDB-তে সংরক্ষণ করেছেন৷
- ট্রান্সফরমেশনাল ওভারহেড =0
- কাফকা সহজেই ক্লিক স্ট্রীম পরিচালনা করতে পারে
- পাইপলাইন ওভারহেড =1
- আপনার শুধু একটি সিস্টেম আছে ( Kafka + KSqlDB)। মনে রাখবেন যে আমরা চিড়িয়াখানাকে উপেক্ষা করছি।
- বৈশিষ্ট্যের সংখ্যা =1
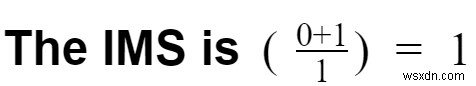
কেস 4:বলুন আপনি এই ইভেন্টগুলি প্রক্রিয়া করার জন্য Redis স্ট্রীমগুলি ব্যবহার করেছেন এবং তারপরে সেগুলি RedisTimeseries-এ সংরক্ষণ করেছেন (উভয়টাই Redis-এর অংশ এবং Redis-এর সাথে স্থানীয়ভাবে কাজ করে)।

- ট্রান্সফরমেশনাল ওভারহেড =0
- রেডিস স্ট্রিম সহজেই ক্লিক স্ট্রীম পরিচালনা করতে পারে
- পাইপলাইন ওভারহেড =1
- আপনার শুধুমাত্র একটি সিস্টেম আছে (Redis স্ট্রিম + RedisTimeSeries)
- বৈশিষ্ট্যের সংখ্যা =1
পর্যায় 1 এর পরে উপসংহার:
আমরা এই উদাহরণে চারটি সিস্টেমের তুলনা করেছি এবং খুঁজে পেয়েছি যে "কেস 3" বা "কেস 4" হল 1-এর IMS-এর সাথে সবচেয়ে সহজ। এই মুহুর্তে, তারা উভয়ই একই, কিন্তু আমরা আরও বৈশিষ্ট্য যোগ করলে কি তারা একই থাকবে? ?
আসুন আমাদের সিস্টেমে আরও বৈশিষ্ট্য যোগ করি এবং দেখুন কিভাবে IMS ধরে রাখে।
ফেজ 2:আইপি-হোয়াইটলিস্টিং সহ একটি রিয়েল-টাইম ড্যাশবোর্ড তৈরি করা
ধরা যাক আপনি একই অ্যাপ তৈরি করছেন কিন্তু নিশ্চিত করতে চান যে সেগুলি শুধুমাত্র সাদা-তালিকাভুক্ত IP ঠিকানাগুলি থেকে এসেছে। এখন আপনি একটি নতুন বৈশিষ্ট্য যোগ করছেন৷
৷কেস 1:বলুন যে আপনি এই ইভেন্টগুলি সঞ্চয় করার জন্য RDBMS ব্যবহার করেছেন, যদিও টেবিলগুলি ফিট নাও হতে পারে এবং তারা IP-হোয়াইটলিস্টিংয়ের জন্য Redis বা MemCached ব্যবহার করেছে৷
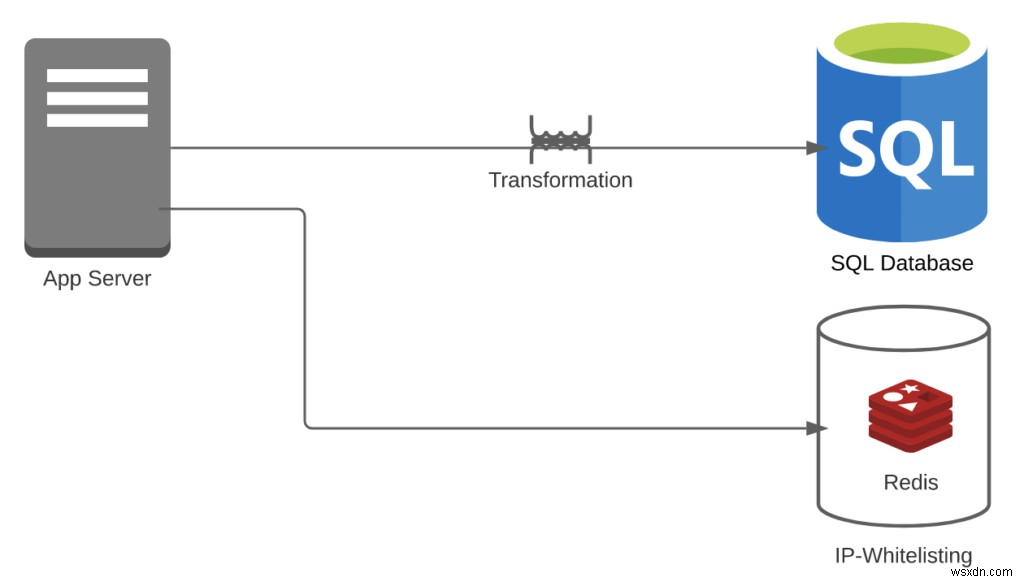
- পরিবর্তনমূলক ওভারহেড =1
- আইপি-হোয়াইটলিস্টিংয়ের জন্য, আপনার কোনো রূপান্তরের প্রয়োজন নেই। যাইহোক, আপনাকে ইভেন্ট স্ট্রীমগুলিকে টেবিলে রূপান্তর করতে হবে
- পাইপলাইন ওভারহেড =2
- আপনার Redis + RDBMS আছে
- বৈশিষ্ট্যের সংখ্যা =2

কেস 2:বলুন আপনি Redis + Kafka + RDBMS ব্যবহার করছেন।
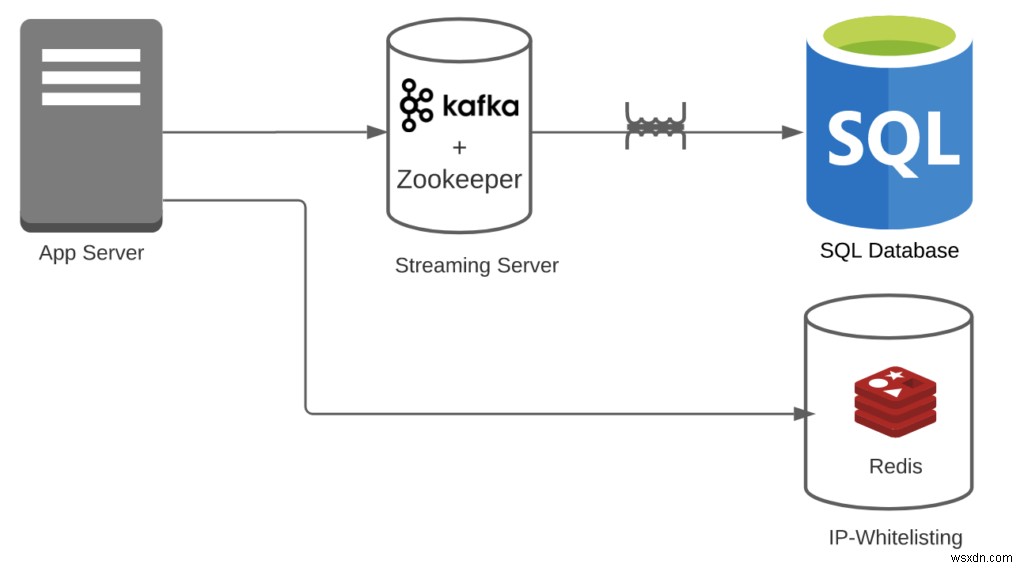
- পরিবর্তনমূলক ওভারহেড =1
- আইপি-হোয়াইটলিস্টিংয়ের জন্য, আপনার কোনো রূপান্তরের প্রয়োজন নেই। এছাড়াও, কাফকা সহজেই স্ট্রীম পরিচালনা করতে পারে।
- পাইপলাইন ওভারহেড =3
- আপনার Redis + Kafka + RDBMS আছে। দ্রষ্টব্য:আমরা উপেক্ষা করছি যে কাফকারও চিড়িয়াখানার প্রয়োজন। যদি আপনি এটি যোগ করেন, তাহলে সংখ্যা আরও নিচে নেমে যাবে।
- বৈশিষ্ট্যের সংখ্যা =2

কেস 3:বলুন আপনি Redis + Kafka + KsqlDB ব্যবহার করছেন।
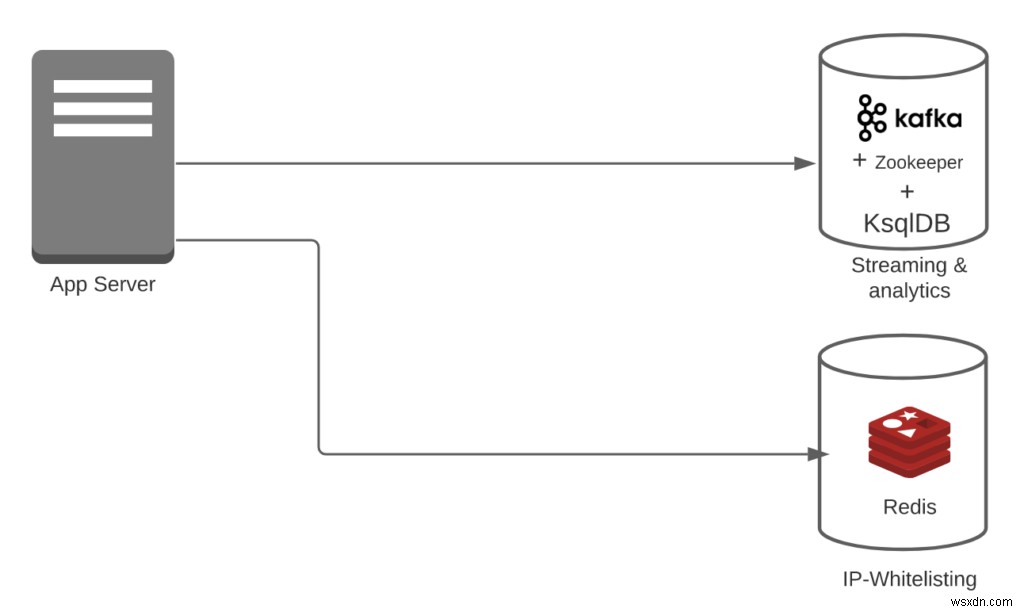
- ট্রান্সফরমেশনাল ওভারহেড =0
- আইপি-হোয়াইটলিস্টিংয়ের জন্য, আপনার কোনো রূপান্তরের প্রয়োজন নেই। এছাড়াও, Kafka এবং KsqlDB সহজেই স্ট্রীম পরিচালনা করতে পারে।
- পাইপলাইন ওভারহেড =2
- আপনার কাছে Redis + (Kafka + KsqlDB) আছে। দ্রষ্টব্য:এই ক্ষেত্রে, আমরা একই সিস্টেমের কাফকা + KsqlDB অংশ বিবেচনা করছি৷
- বৈশিষ্ট্যের সংখ্যা =2

কেস 4:বলুন আপনি Redis + Redis Streams + RedisTimeSeries ব্যবহার করছেন।

- ট্রান্সফরমেশনাল ওভারহেড =0
- আইপি-হোয়াইটলিস্টিংয়ের জন্য, আপনার কোনো রূপান্তরের প্রয়োজন নেই। এছাড়াও, Redis স্ট্রিম এবং RedisTimeseries সহজেই স্ট্রিম এবং সতর্কতাগুলি পরিচালনা করতে পারে৷
- পাইপলাইন ওভারহেড =1
- আপনার কাছে Redis + Redis স্ট্রিম + Redis TimeSeries আছে। দ্রষ্টব্য:এই ক্ষেত্রে, তিনটিই একই সিস্টেমের অংশ৷
- বৈশিষ্ট্যের সংখ্যা =2

ফেজ 2 এর পরে উপসংহার:
যখন আমরা একটি অতিরিক্ত বৈশিষ্ট্য যোগ করি,
- কেস 1 ফেজ-1 এ 2 এ ছিল এবং 1.5 এ নেমে গেছে।
- কেস 2টি ফেজ-1-এ 3 এ ছিল এবং 2 এ নেমে গেছে
- কেস 3 ফেজ-1 এ 1 এ ছিল এবং 1 এ রয়ে গেছে
- কেস 4 ফেজ-1 এ 1 এ ছিল এবং 0.5 এ নেমে গেছে (সেরা)
সুতরাং আমাদের উদাহরণে, কেস 4, যার একটি সর্বনিম্ন IMS স্কোর ছিল 1, আসলে আমরা নতুন বৈশিষ্ট্য যুক্ত করার সাথে সাথে এটি আরও ভাল হয়েছে এবং এটি 0.5 এ শেষ হয়েছে।
অনুগ্রহ করে মনে রাখবেন:আপনি যদি আরও বা ভিন্ন বৈশিষ্ট্য যোগ করেন, তাহলে কেস 4 সবচেয়ে সহজ নাও থাকতে পারে। কিন্তু এটি আইএমএস স্কোরের ধারণা। সহজভাবে সমস্ত বৈশিষ্ট্য তালিকাভুক্ত করুন, বিভিন্ন আর্কিটেকচারের তুলনা করুন এবং আপনার ব্যবহারের ক্ষেত্রে কোনটি সেরা তা দেখুন৷
এটি ব্যবহার করা আরও সহজ করার জন্য, আমরা আপনাকে একটি ক্যালকুলেটর প্রদান করছি যা আপনি IMS স্কোর গণনা করার জন্য একটি সাধারণ স্প্রেডশীটে প্রয়োগ করতে পারেন৷
IMS ক্যালকুলেটর
আপনি এটি কীভাবে ব্যবহার করেন তা এখানে:
- প্রতিটি ডেটা স্তর বা ডেটা পাইপলাইনের জন্য, সহজভাবে তালিকাভুক্ত করুন:
- আপনার বর্তমানে যে বৈশিষ্ট্যগুলি রয়েছে৷
- যে বৈশিষ্ট্যগুলি রোডম্যাপে রয়েছে৷ এটি গুরুত্বপূর্ণ, কারণ আপনি নিশ্চিত করতে চান যে আপনার ডেটা স্তর কোনও অতিরিক্ত ওভারহেড ছাড়াই আসন্ন বৈশিষ্ট্যগুলিকে সমর্থন করতে পারে৷
- তারপর প্রতিটি বৈশিষ্ট্যের জন্য ট্রান্সফরমেশনাল ওভারহেড এবং পাইপলাইন ওভারহেড ম্যাপ করুন।
- এবং অবশেষে, সমস্ত ওভারহেডের যোগফলকে বৈশিষ্ট্যের সংখ্যা দিয়ে ভাগ করুন।
- বিভিন্ন সিস্টেমের পাইপলাইনগুলির তুলনা ও বৈসাদৃশ্যের জন্য ধাপ 2 এবং 3 পুনরাবৃত্তি করুন৷
ডেটা পাইপলাইন 1
ডেটা পাইপলাইন 2

সারাংশ
পরিণাম সম্পর্কে চিন্তা না করেই দূরে চলে যাওয়া এবং একটি জটিল ডেটা স্তর তৈরি করা খুব সহজ। আপনার সিদ্ধান্ত সম্পর্কে সচেতন হতে সাহায্য করার জন্য IMS স্কোর তৈরি করা হয়েছে।
আপনি আইএমএস স্কোর ব্যবহার করে সহজেই আপনার ব্যবহারের ক্ষেত্রে একাধিক সিস্টেমের তুলনা এবং বৈসাদৃশ্য করতে পারেন এবং দেখতে পারেন যে আপনার বৈশিষ্ট্যগুলির সেটের জন্য কোনটি সত্যিই সেরা। আপনার সিস্টেম বৈশিষ্ট্য সম্প্রসারণ ধরে রাখতে পারে এবং যতটা সম্ভব সহজ থাকা চালিয়ে যেতে পারে তা আপনি যাচাই করতে পারেন।
সর্বদা মনে রাখবেন:
“সরলতা হল চূড়ান্ত পরিশীলিততা” — লিওনার্দো দা ভিঞ্চি
“বেশিরভাগ তথ্যই অপ্রাসঙ্গিক এবং বেশিরভাগ প্রচেষ্টাই নষ্ট হয়, কিন্তু শুধুমাত্র বিশেষজ্ঞই জানেন কী উপেক্ষা করতে হবে ” — জেমস ক্লিয়ার, অ্যাটমিক হ্যাবিটস
