
মাইক্রোসফ্ট এক্সেল ডেটা সংরক্ষণ এবং বিশ্লেষণের জন্য একটি দুর্দান্ত সরঞ্জাম। এটি পরিসংখ্যানগত সরঞ্জাম এবং সূত্রের বিস্তৃত পরিসর অফার করে, যা বিভিন্ন ডেটাসেটের মূল পরিসংখ্যান নির্ধারণ করা সহজ করে তোলে। এই নিবন্ধে, আমরা ব্যাখ্যা করব কিভাবে এক্সেলে স্ট্যান্ডার্ড ত্রুটি গণনা করা যায় (এবং এটি প্রথমে কী)।
মানক ত্রুটি কি?
স্ট্যান্ডার্ড ত্রুটি আপনাকে দেখতে দেয় যে নমুনা ডেটা একটি বড় ডেটাসেটের সাথে কতটা সঠিকভাবে ফিট করে। অন্য কথায়, এটি গণনা করে যে সমগ্র জনসংখ্যার জন্য ডেটা বিতরণ কতটা সঠিক।
এটি আদর্শ বিচ্যুতি গণনা করে এটি করে, যা সমগ্র ডেটাসেটের গড় থেকে আপনার নমুনার গড় কতদূর বিচ্যুত হয়।
স্ট্যান্ডার্ড ত্রুটির সূত্র হল:
যেখানে সমগ্র ডেটাসেটের জন্য আদর্শ বিচ্যুতি এবং নমুনা আকারের বর্গমূল।
একটি উদাহরণ দিয়ে আদর্শ ত্রুটির ধারণাটি ব্যাখ্যা করতে, 500 জন শিক্ষার্থী সহ একটি স্কুল কল্পনা করুন। আমরা ছাত্রদের গড় উচ্চতা অনুমান করতে চাই, তাই আমরা 30 জন ছাত্র নির্বাচন করি এবং তাদের পরিমাপ করি। এই নমুনার গড় উচ্চতা 160 সেমি।
যাইহোক, যদি আমরা আরও 30 জন শিক্ষার্থীর নমুনা নিই, আমরা দেখতে পাই যে গড় উচ্চতা 152 সেমি।
প্রকৃত জনসংখ্যা গড়ের বিপরীতে এই নমুনা গড়গুলির পার্থক্য হল মানক ত্রুটি। প্রমিত ত্রুটি যত কম হবে, নমুনার গড় জনসংখ্যার তত বেশি প্রতিনিধিত্ব করবে। ত্রুটিটি যত বড় হবে, এটি তত কম প্রতিনিধিত্ব করবে এবং ডেটা তত বেশি পরিবর্তনশীল৷
৷মাইক্রোসফ্ট এক্সেল স্ট্যান্ডার্ড বিচ্যুতি এবং সংখ্যার সেটের বর্গমূল গণনা করার জন্য অন্তর্নির্মিত সূত্র সরবরাহ করে, যা স্ট্যান্ডার্ড ত্রুটি গণনা করা খুব সহজ করে তোলে। একটি সাধারণ উদাহরণ ব্যবহার করে এই সূত্রগুলি কীভাবে ব্যবহার করবেন তা এখানে:
- নিচের মতো একটি কলামে আপনার ডেটা সাজান।
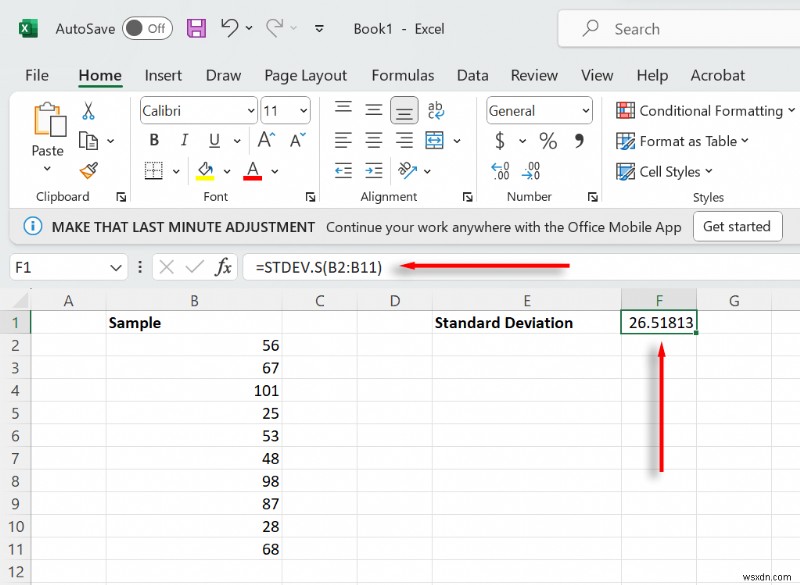
- প্রথমে, আমাদের আপনার নমুনার আদর্শ বিচ্যুতি গণনা করতে হবে। এটি করতে, একটি ঘর নির্বাচন করুন, তারপর টাইপ করুন =STDEV.S(B2:B11) (আপনার নমুনা পরিসীমা নির্বাচন করুন) এবং এন্টার টিপুন। STDEV.S ব্যবহার করা নিশ্চিত করুন কারণ এটি সম্পূর্ণ জনসংখ্যার পরিবর্তে একটি নমুনার জন্য আদর্শ বিচ্যুতি প্রদান করে৷
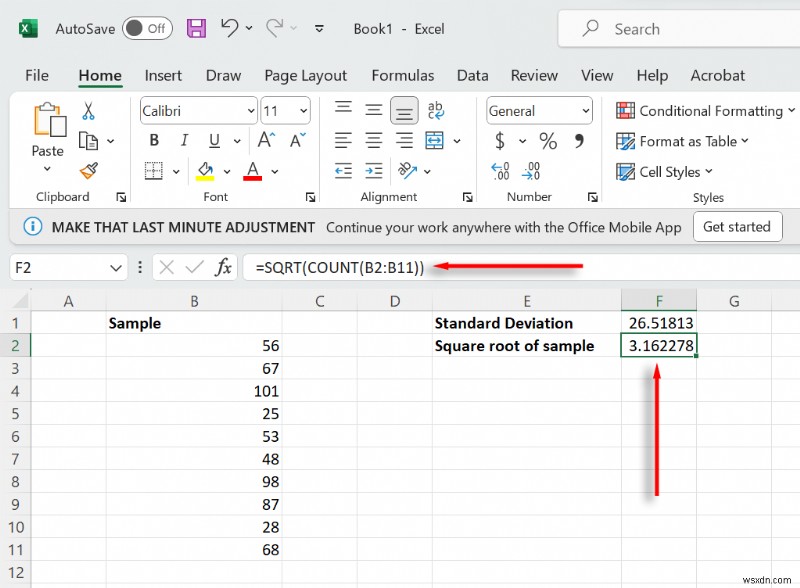
- এরপর, আমাদের নমুনা আকারের বর্গমূল গণনা করতে হবে। এটি করতে, একটি দ্বিতীয় ঘর নির্বাচন করুন এবং SQRT(COUNT(B2:B11)) টাইপ করুন (আপনার নমুনা পরিসীমা নির্বাচন করুন)। তারপর, এন্টার টিপুন।
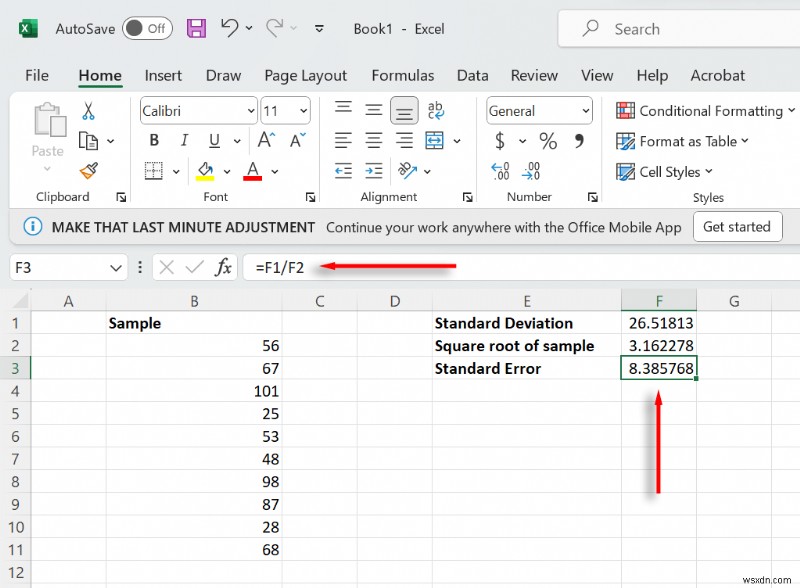
- অবশেষে, আমাদের আদর্শ বিচ্যুতিকে নমুনা আকারের বর্গমূল দিয়ে ভাগ করতে হবে। একটি তৃতীয় কক্ষ নির্বাচন করুন এবং টাইপ করুন =F1/F2, প্রতিটি মানের প্রতিনিধিত্বকারী কোষ নির্বাচন করুন। এন্টার টিপুন।
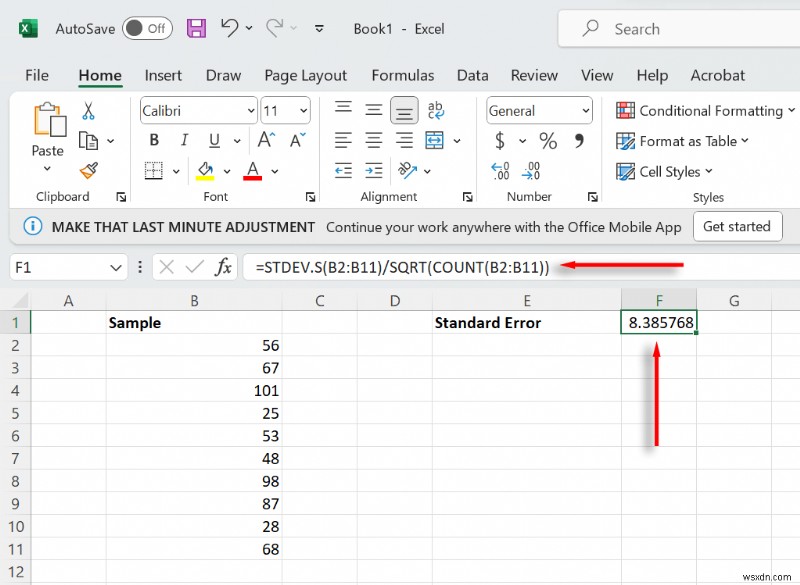
সেল এখন আপনার নমুনার মান ত্রুটি প্রদর্শন করা উচিত. আপনি এই দুটি সূত্রকে একটি সমীকরণে একত্রিত করতে পারেন। শুধু টাইপ করুন =STDEV(B2:B11)/SQRT(COUNT(B2:B11)) (A1:A10 এর পরিবর্তে আপনার ডেটা পরিসর নির্বাচন করুন)।
দ্রষ্টব্য:সঠিক ফাংশন সিনট্যাক্স অনুসরণ করা নিশ্চিত করুন যাতে আপনার সূত্রগুলি ডিজাইন করা হিসাবে কাজ করে। আপনি সিনট্যাক্স সম্পর্কে নিশ্চিত না হলে, আপনি স্ট্যান্ডার্ড ত্রুটি সূত্রের প্রতিটি অংশকে আলাদা করে একটি তৃতীয় কক্ষে ভাগ করতে পারেন।
সতর্কতার দিক থেকে ত্রুটি
Microsoft Excel পরিসংখ্যানগত বিশ্লেষণের জন্য একটি শক্তিশালী হাতিয়ার। এটি অন্য প্রকারের বৈচিত্র্য এবং ঋণ পরিশোধের হিসাব করতেও ব্যবহার করা যেতে পারে - এবং এটিই সব নয়। আশা করি, আপনি এখন মানক ত্রুটি গণনা করতে সক্ষম হয়েছেন এবং আপনি আপনার বিশ্লেষণের পরবর্তী অংশে যেতে পারেন।
