

এক্সেল একটি শক্তিশালী ডাটা ম্যানেজমেন্ট এবং অ্যানালাইসিস টুল। এটি দ্রুত রিপোর্টিং এবং গণনার জন্য নিখুঁত, কিন্তু কাজ অগোছালো, পুনরাবৃত্তিমূলক বা খুব বড় হলে পাইথন সাহায্য করে। পাইথন অটোমেশন, উন্নত বিশ্লেষণ এবং ইন্টিগ্রেশন সম্ভাবনাগুলি খুলে দেয় যা এক্সেলের অন্তর্নির্মিত বৈশিষ্ট্যগুলির বাইরে যায়। পাইথন লাইব্রেরি যেমন পান্ডা ডেটা ম্যানিপুলেশন এবং openpyxl এর জন্য সরাসরি এক্সেল ফাইল হ্যান্ডলিং এর জন্য এটি নির্বিঘ্ন করুন।
এই টিউটোরিয়ালে, আমরা এক্সেল + পাইথন দিয়ে আপনি করতে পারেন এমন পাঁচটি জিনিস দেখাব।
এক্সেল এবং পাইথনের সাথে আপনি যে পাঁচটি জিনিস করতে পারেন তা অন্বেষণ করতে নমুনা বিক্রয় ডেটা বিবেচনা করুন৷
1. অগোছালো এক্সেল ডেটা পরিষ্কার এবং মানসম্মত করুন (পুনরায়)
এক্সেলে অগোছালো ডেটা থাকা সাধারণ ব্যাপার, কারণ বাস্তব-বিশ্বের ডেটা খুব কমই পরিষ্কার থাকে। প্রায়শই, ডেটাতে অতিরিক্ত স্পেস, মিশ্র ক্যাপিটালাইজেশন, পাঠ্য হিসাবে সংরক্ষিত সংখ্যা, অসামঞ্জস্যপূর্ণ বিন্যাস, অনুপস্থিত মান, ডুপ্লিকেট এন্ট্রি বা ডেটা থাকে যা বিশ্লেষণের আগে পুনর্গঠনের প্রয়োজন হয়। এই সমস্যা সূত্র এবং বিশ্লেষণ নষ্ট করে দেয়।
পাইথন ডাটা-ক্লিনিং কাজে পারদর্শী। আপনি স্ক্রিপ্ট লিখতে পারেন যা বিভিন্ন ফাইল জুড়ে ডেটা বিন্যাসকে মানসম্মত করে, বুদ্ধিমান পদ্ধতি ব্যবহার করে অনুপস্থিত মানগুলি পূরণ করতে, নকলগুলি সরাতে, প্যাটার্নের উপর ভিত্তি করে কলামগুলিকে বিভক্ত বা একত্রিত করতে এবং ব্যবসায়িক নিয়মের বিরুদ্ধে ডেটা যাচাই করতে পারে। এই পদক্ষেপগুলির জন্য এক্সেলে কয়েক ঘন্টা ম্যানুয়াল অনুসন্ধান এবং প্রতিস্থাপন অপারেশনের প্রয়োজন হতে পারে। পাইথন ব্যবহার করে, আপনি একটি পুনরাবৃত্তিযোগ্য স্ক্রিপ্ট তৈরি করতে পারেন যা সেকেন্ডে হাজার হাজার সারি প্রক্রিয়া করে।
ধরুন আপনি অগোছালো বিক্রয় ডেটা পেয়েছেন। আসুন একটি পাইথন স্ক্রিপ্ট ব্যবহার করি যা অগোছালো ডেটা পড়ে, কলামগুলি পরিষ্কার করে এবং মানসম্মত করে এবং গণনা করা ক্ষেত্রগুলি যোগ করে৷
- রাজস্ব =একক * একক মূল্য
- NetRevenue =রাজস্ব * (1 – DiscountPct)
import pandas as pd
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="Sales Data")
# Clean types
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
df["DiscountPct"] = pd.to_numeric(df["DiscountPct"], errors="coerce").fillna(0.0)
df["Returned"] = (
df["Returned"].astype(str).str.strip().str.lower()
.map({"yes": True, "no": False})
.fillna(False)
)
# Add calculated fields
df["Revenue"] = df["Units"] * df["UnitPrice"]
df["NetRevenue"] = df["Revenue"] * (1 - df["DiscountPct"])
# Write back into the SAME file as a NEW sheet
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="CleanData", index=False)
print("Saved CleanData sheet inside:", file_path)
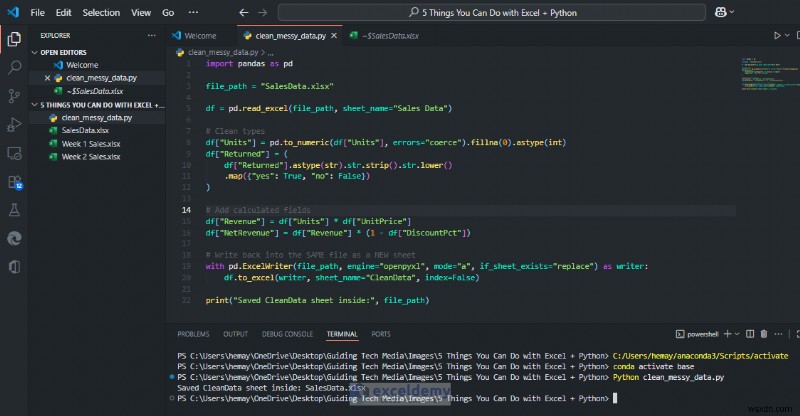
আপনি একটি পরিষ্কার ডেটাসেট সহ একটি নতুন শীট পাবেন যা পিভট, চার্ট বা লুকআপগুলিকে ভাঙবে না। এক্সেল-এ, আপনি পরিষ্কার করা ডেটা থেকে পিভট/চার্ট ব্যবহার চালিয়ে যেতে পারেন, জেনে রাখুন এটি প্রতিবারে সামঞ্জস্যপূর্ণ।
2. স্বয়ংক্রিয়ভাবে সারাংশ তৈরি করুন (পুনরাবৃত্তিযোগ্য প্রতিবেদন)
এক্সেলের সারি সীমা রয়েছে এবং জটিল গণনার সাথে ধীর হতে পারে। পাইথনের পান্ডা লাইব্রেরি বড় ডেটাসেটগুলি দক্ষতার সাথে পরিচালনা করে এবং অনেক দ্রুত গণনা সম্পাদন করে৷
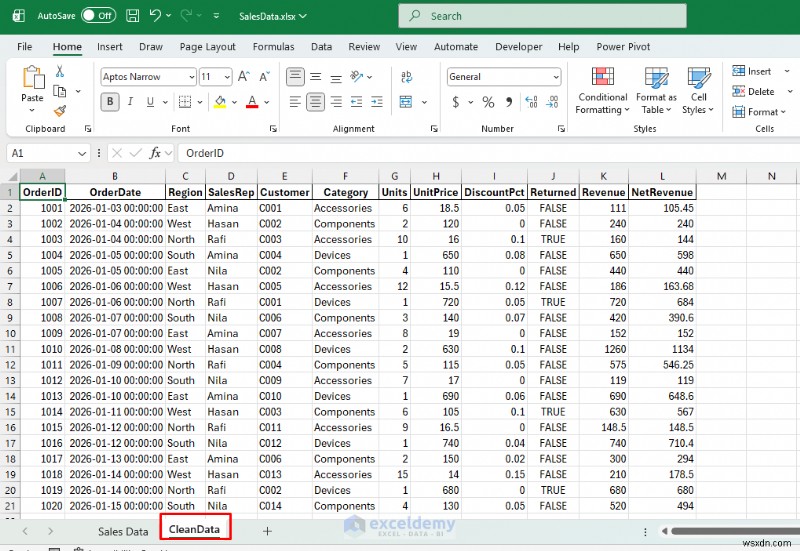
পান্ডাদের সাথে , আপনি লক্ষ লক্ষ রেকর্ড সমন্বিত ডেটাসেটগুলির সাথে কাজ করতে পারেন, জটিল গ্রুপিং এবং একত্রীকরণ ক্রিয়াকলাপ সম্পাদন করতে পারেন এবং পরিসংখ্যানগত বিশ্লেষণগুলি সম্পাদন করতে পারেন যা Excel এ অব্যবহারিক হতে পারে৷ পাইথন পিভট-স্টাইলের সারাংশ তৈরি করতে পারে এবং সেগুলিকে এক্সেলে রপ্তানি করতে পারে। ধরুন আপনি অঞ্চল এবং বিভাগ দ্বারা একটি দ্রুত সারাংশ চান, কিন্তু আপনি প্রতিবার পিভটগুলি পুনর্নির্মাণ করতে চান না৷
import pandas as pd
file_path = "SalesData.xlsx"
clean_sheet = "CleanData"
out_sheet = "Summary"
df = pd.read_excel(file_path, sheet_name=clean_sheet)
summary = (
df.groupby(["Region", "Category"], as_index=False)
.agg(
Orders=("OrderID", "count"),
Units=("Units", "sum"),
NetRevenue=("NetRevenue", "sum"),
Returns=("Returned", "sum")
)
)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
summary.to_excel(writer, sheet_name=out_sheet, index=False)
print(f"✅ Saved '{out_sheet}' sheet inside: {file_path}")
আপনি অঞ্চল অনুসারে একটি আয়ের সারাংশ পাবেন—একটি ভাগ করার জন্য প্রস্তুত পিভট-স্টাইল শীট যা আপনি যখনই স্ক্রিপ্ট পুনরায় চালান তখনই আপডেট হয়৷
3. এক্সেল ডেটা থেকে চার্ট তৈরি করুন (ম্যানুয়াল ফর্ম্যাটিং ছাড়াই)
চার্ট প্রায়ই রিপোর্টিং সবচেয়ে সময় গ্রাসকারী অংশ. এক্সেল স্ট্যান্ডার্ড চার্ট অফার করে, কিন্তু পাইথনের ভিজ্যুয়ালাইজেশন লাইব্রেরি যেমন Matplotlib , সমুদ্রজাত , এবং প্লটলি অনেক বেশী নমনীয়তা এবং পরিশীলিত প্রদান. আপনি কাস্টম ভিজ্যুয়ালাইজেশন তৈরি করতে পারেন যা আপনার ডেটা পরিবর্তন হলে স্বয়ংক্রিয়ভাবে আপডেট হয়, ব্যবহারকারীরা অন্বেষণ করতে পারে এমন ইন্টারেক্টিভ ড্যাশবোর্ড তৈরি করে বা প্রতিটি উপাদানের উপর সুনির্দিষ্ট নিয়ন্ত্রণের সাথে প্রকাশনা-মানের গ্রাফিক্স তৈরি করে।
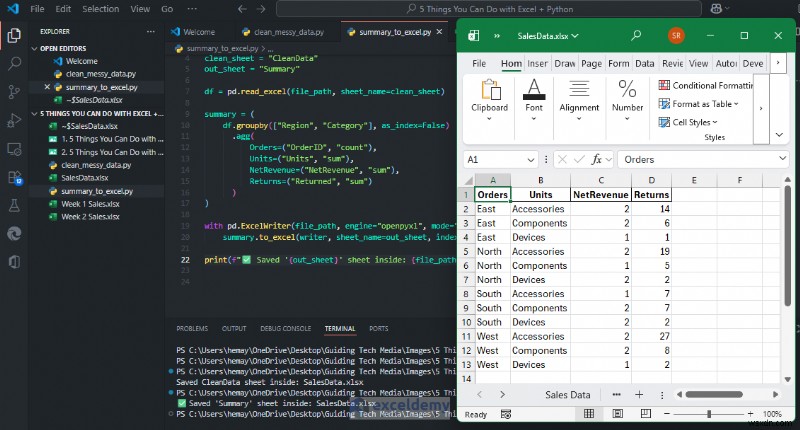
আসুন অঞ্চল অনুসারে পারফরম্যান্স কল্পনা করি (অঞ্চল অনুসারে NetRevenue)।
import pandas as pd
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
file_path = "SalesData.xlsx"
source_sheet = "CleanData"
output_sheet = "RegionChart" # data + chart in this one sheet
# Prepare chart data (NetRevenue by Region)
df = pd.read_excel(file_path, sheet_name=source_sheet)
chart_data = (
df.groupby("Region", as_index=False)["NetRevenue"]
.sum()
.sort_values("NetRevenue", ascending=False)
)
# Write chart data into output_sheet (same workbook)
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
chart_data.to_excel(writer, sheet_name=output_sheet, index=False)
# Add the native Excel chart on the same sheet
wb = load_workbook(file_path)
ws = wb[output_sheet]
chart = BarChart()
chart.title = "Net Revenue by Region"
chart.y_axis.title = "Net Revenue"
chart.x_axis.title = "Region"
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, "D2") # place chart to the right of the data table
wb.save(file_path)
print(f"✅ Chart Created: {output_sheet}")
এখন আপনার কাছে একটি বার চার্ট সহ অঞ্চল অনুসারে আয়ের সারসংক্ষেপ রয়েছে৷
৷
4. অনেকগুলো এক্সেল ফাইল এক মাস্টার টেবিলে মার্জ করুন
বিভিন্ন উত্স থেকে সাপ্তাহিক, মাসিক বা ত্রৈমাসিক ডেটা একত্রিত করা সাধারণ। বিভিন্ন ব্যক্তি বা দল থেকে এক্সেল ফাইল একত্রিত করা ধীর এবং ত্রুটি-প্রবণ। পাইথন সেকেন্ডের মধ্যে তাদের একত্রিত করতে পারে এবং সোর্স ফাইল ট্র্যাক করতে পারে।
আসুন সাপ্তাহিক ফাইলগুলিকে সাপ্তাহিক প্রতিবেদন/ নামে একটি ফোল্ডারে মার্জ করি (সমস্ত একই কলাম সহ)।
import pandas as pd
from pathlib import Path
base_folder = Path(__file__).resolve().parent
folder = base_folder / "Weekly Reports"
files = sorted(folder.glob("*.xlsx"))
files = [f for f in files if not f.name.startswith("~$")] # ignore Excel lock files
print("Looking in:", folder)
print("Files found:", [f.name for f in files])
frames = []
for f in files:
temp = pd.read_excel(f)
temp["SourceFile"] = f.name
frames.append(temp)
master = pd.concat(frames, ignore_index=True)
master.to_excel(base_folder / "master_report.xlsx", index=False)
print("Saved: master_report.xlsx")
আপনি একটি সোর্সফাইল সহ একটি একত্রিত টেবিল পাবেন নিরীক্ষার জন্য কলাম। প্রতি সপ্তাহে, আপনাকে শুধু স্ক্রিপ্ট চালাতে হবে।
5. এক্সেল সহজে করতে পারে না এমন কিছু ভবিষ্যদ্বাণী করুন (মেশিন লার্নিং উদাহরণ)
আপনি প্যাটার্ন (ডিসকাউন্ট, বিভাগ, ইউনিট, মূল্য) ব্যবহার করে রিটার্ন ঝুঁকি অনুমান করতে পারেন, তারপরে সম্ভাব্যতা লিখুন যাতে এক্সেল ব্যবহারকারীরা ফিল্টার এবং সাজাতে পারে। পাইথন সহজেই এই ধরনের মেশিন লার্নিং অপারেশন করতে পারে।
আমাদের একটি ছোট ডেটাসেট; এখনও, এটি কর্মপ্রবাহ দেখায়৷
৷import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
file_path = "SalesData.xlsx"
df = pd.read_excel(file_path, sheet_name="CleanData")
X = df[["Region", "SalesRep", "Category", "Units", "UnitPrice", "DiscountPct"]]
y = df["Returned"].astype(int)
cat_cols = ["Region", "SalesRep", "Category"]
num_cols = ["Units", "UnitPrice", "DiscountPct"]
preprocess = ColumnTransformer(
transformers=[
("cat", OneHotEncoder(handle_unknown="ignore"), cat_cols),
("num", "passthrough", num_cols),
]
)
model = Pipeline(steps=[
("prep", preprocess),
("clf", LogisticRegression(max_iter=1000))
])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model.fit(X_train, y_train)
# Predict probability of return for all rows
df["ReturnProb"] = model.predict_proba(X)[:, 1]
with pd.ExcelWriter(file_path, engine="openpyxl", mode="a", if_sheet_exists="replace") as writer:
df.to_excel(writer, sheet_name="WithReturnRisk", index=False)
Excel এ, WithReturnRisk অন্বেষণ করুন এবং ReturnProb ফিল্টার করুন কোন অর্ডারগুলি ঝুঁকিপূর্ণ তা দেখতে উচ্চ থেকে নিম্ন পর্যন্ত৷
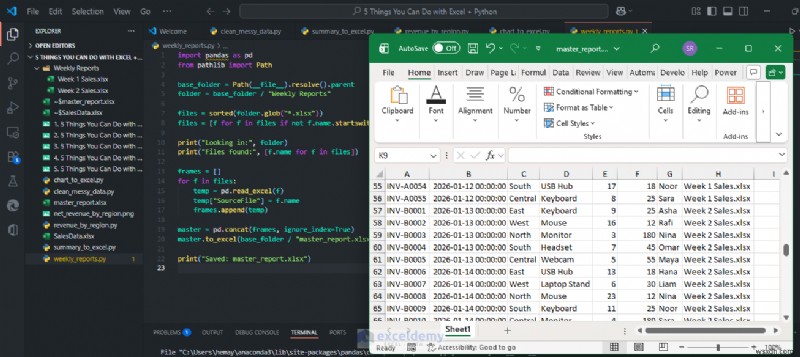
এক্সেলে পাইথন (যদি আপনার এক্সেলে পাওয়া যায়)
যদি আপনার কম্পিউটারে এক্সেলে পাইথন (প্রিভিউ) থাকে, তাহলে আপনি সরাসরি একটি ঘরে পাইথন চালাতে পারেন এবং ফলাফলটি শীটে ফেরত দিতে পারেন। (Excel-এ Python-এর Microsoft-এর ওভারভিউ দেখুন .) এখানে একটি সাধারণ উদাহরণ যা একটি ছোট পরিসর পড়ে, পাঠ্য পরিষ্কার করে, রাজস্ব গণনা করে এবং একটি পরিষ্কার টেবিল ফেরত দেয়৷
- Excel এ, আপনার ডেটাসেট লিখুন
- একটি খালি ঘরে ক্লিক করুন
- সূত্র-এ যান ট্যাব>> পাইথন সন্নিবেশ করুন নির্বাচন করুন
- পাইথন স্ক্রিপ্ট পেস্ট করুন
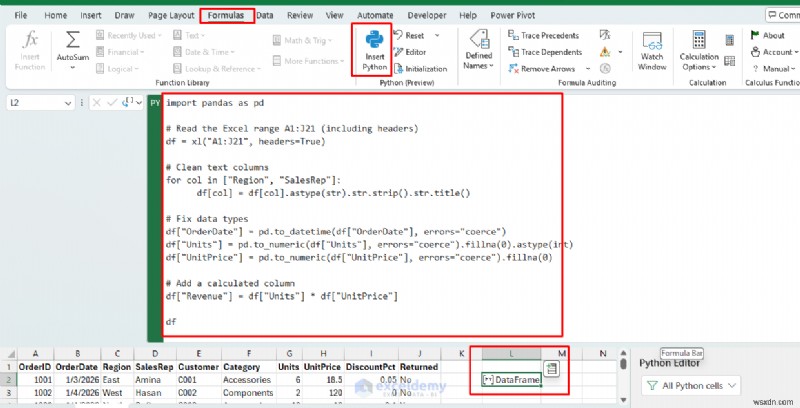
import pandas as pd
# Read the Excel range A1:J21 (including headers)
df = xl("A1:J21", headers=True)
# Clean text columns
for col in ["Region", "SalesRep"]:
df[col] = df[col].astype(str).str.strip().str.title()
# Fix data types
df["OrderDate"] = pd.to_datetime(df["OrderDate"], errors="coerce")
df["Units"] = pd.to_numeric(df["Units"], errors="coerce").fillna(0).astype(int)
df["UnitPrice"] = pd.to_numeric(df["UnitPrice"], errors="coerce").fillna(0.0)
# Add a calculated column
df["Revenue"] = df["Units"] * df["UnitPrice"]
df
এটি ডেটাফ্রেম ফিরিয়ে দেবে , যা পাইথনের টেবিল অবজেক্ট। এক্সেল এটিকে একটি টেবিল পূর্বরূপ (এবং একটি কার্ড) হিসাবে দেখায়।
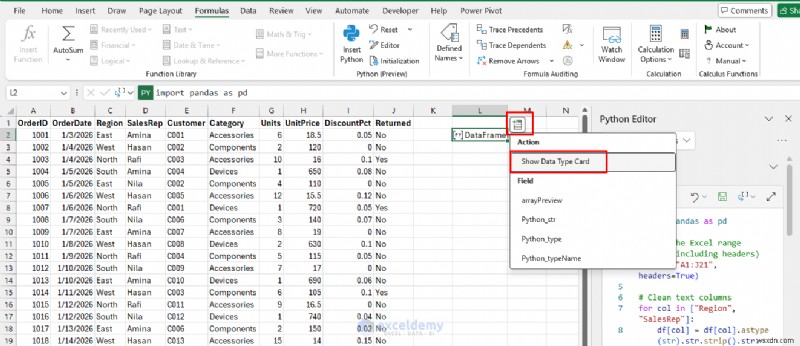
এখন একটি পরিষ্কার টেবিল হিসাবে সেলগুলিতে আউটপুটটি "স্পিল" করুন৷
- ডেটা সন্নিবেশ করুন এ ক্লিক করুন ডেটাফ্রেম থেকে>> ডেটা টাইপ কার্ড দেখান নির্বাচন করুন টেবিলের পূর্বরূপ দেখতে
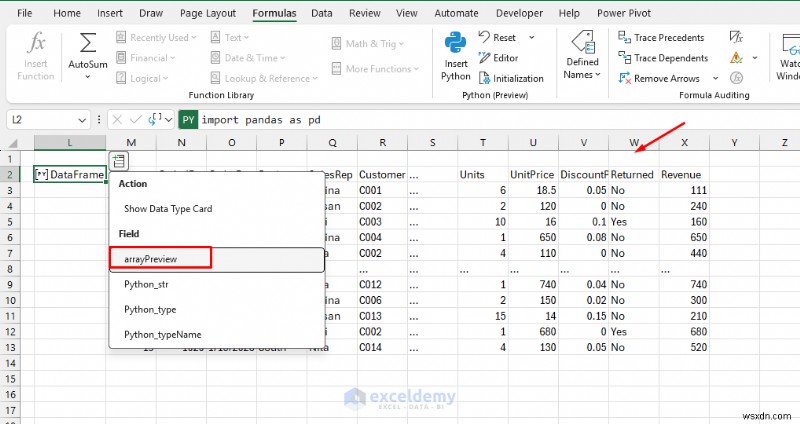
- অ্যারেপ্রিভিউ নির্বাচন করুন টেবিলটিকে এক্সেলে আনতে
- আপনার কাছে এখন মানসম্মত পাঠ্য এবং একটি নতুন রাজস্ব আছে কলাম
উপসংহার
এই নিবন্ধটি দেখায় যে আপনি এক্সেল + পাইথন দিয়ে পাঁচটি জিনিস করতে পারেন। পাইথনের সাথে এক্সেল আরও শক্তিশালী হয়ে ওঠে; অগোছালো ডেটাসেটগুলি পরিষ্কার করা, পিভট-স্টাইলের সারাংশ তৈরি করা, চার্টগুলি স্বয়ংক্রিয় করা, অনেকগুলি এক্সেল ফাইল মার্জ করা এবং সহজ মেশিন লার্নিং অন্তর্দৃষ্টি যোগ করা সহজ হয়ে যায়৷ এক্সেল এবং পাইথন একত্রিত করা কর্মপ্রবাহকে স্ট্রীমলাইন করে, ডেটা আমদানি/রপ্তানি থেকে অটোমেশন এবং ভিজ্যুয়ালাইজেশন পর্যন্ত। ছোট স্ক্রিপ্ট দিয়ে শুরু করুন এবং আরও লাইব্রেরি নিয়ে পরীক্ষা করুন।
সমাধান সহ বিনামূল্যে উন্নত এক্সেল ব্যায়াম পান!