

এক্সেল ডেটা বিশ্লেষণের জন্য সবচেয়ে শক্তিশালী টুলগুলির মধ্যে একটি, তবে এর সীমা রয়েছে। যখন ডেটাসেটগুলি লক্ষ লক্ষ সারিতে পরিণত হয়, যখন রিপোর্টগুলি স্বয়ংক্রিয়ভাবে চালানোর প্রয়োজন হয়, বা যখন বিশ্লেষণের জন্য মেশিন লার্নিং প্রয়োজন হয়, তখন একা Excel তার বয়স দেখাতে শুরু করে। পাইথন এই শূন্যস্থান পূরণ করে। পাইথন ইন্টিগ্রেশন এক্সেলকে একটি প্রথাগত স্প্রেডশীট টুল থেকে আরও শক্তিশালী ডেটা বিশ্লেষণ প্ল্যাটফর্মে রূপান্তরিত করেছে। পাইথন সরাসরি এক্সেলের মধ্যে উপলব্ধ থাকায়, বিশ্লেষকরা এখন তাদের ওয়ার্কবুক ছাড়াই উন্নত গণনা করতে, ভবিষ্যদ্বাণীমূলক মডেল তৈরি করতে এবং পরিশীলিত ভিজ্যুয়ালাইজেশন তৈরি করতে পারে।
এই টিউটোরিয়ালে, আমরা উন্নত এক্সেল ডেটা বিশ্লেষণের জন্য পাঁচটি পাইথন লাইব্রেরি দেখাব যা প্রতিটি পেশাদারের ব্যবহার করা উচিত। এই লাইব্রেরিগুলি আপনাকে সরাসরি এক্সেলের মধ্যে উন্নত ডেটা ম্যানিপুলেশন, ভিজ্যুয়ালাইজেশন এবং মেশিন লার্নিং করতে দেয়৷
1. পান্ডাস - ডেটা ম্যানিপুলেশন এবং বিশ্লেষণের মূল
আপনি যদি এক্সেল বিশ্লেষণের জন্য শুধুমাত্র একটি পাইথন লাইব্রেরি শিখেন, তাহলে পান্ডা শিখুন প্রথম পাইথনে প্রায় প্রতিটি উন্নত এক্সেল-সম্পর্কিত কাজের ভিত্তি হল পান্ডাস। এটি এক্সেল ডেটাকে শক্তিশালী ডেটাফ্রেমে পরিণত করে পরিষ্কার, রূপান্তর, ফিল্টারিং, গ্রুপিং, মার্জ, একত্রিত করা এবং বড় ডেটাসেটগুলি দক্ষতার সাথে অন্বেষণ করার জন্য৷
এক্সেল পেশাদারদের জন্য মূল শক্তি:
- নেটিভভাবে pd.read_excel() দিয়ে এক্সেল ফাইল পড়ুন এবং লিখুন এবং df.to_excel()
- অগোছালো ডেটা পরিচালনা করুন:সদৃশগুলি সরান, অনুপস্থিত মানগুলি পূরণ করুন এবং ফর্ম্যাটগুলিকে মানসম্মত করুন
- পিভটটেবলের বাইরে যায় এমন যুক্তির সাথে উন্নত গ্রুপিং এবং একত্রীকরণ সম্পাদন করুন
- একাধিক শীট বা ফাইল একত্রিত করুন বা যোগদান করুন
- df.describe() দিয়ে পরিসংখ্যানগত সারাংশ তৈরি করুন
- কোডের কয়েকটি লাইন চালান এবং প্রতিবার একই ফলাফল পান
উদাহরণ:অগোছালো ডেটা পরিষ্কার করা
একটি সাধারণ এক্সেল মাথাব্যথা হল মিশ্র ধরনের, অনুপস্থিত মান এবং অসঙ্গত বিন্যাস সহ ডেটা গ্রহণ করা। পান্ডাসের সাথে, আপনি একটি পুনরাবৃত্তিযোগ্য স্ক্রিপ্টে সবকিছু ঠিক করতে পারেন৷
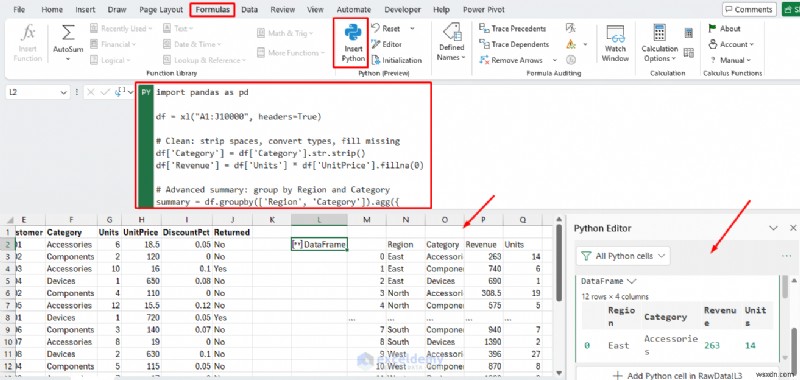
এক্সেলে পাইথন:
import pandas as pd
df = xl("A1:J10000", headers=True)
# Clean: strip spaces, convert types, fill missing
df['Category'] = df['Category'].str.strip()
df['Revenue'] = df['Units'] * df['UnitPrice'].fillna(0)
# Advanced summary: group by Region and Category
summary = df.groupby(['Region', 'Category']).agg({
'Revenue': 'sum',
'Units': 'sum'
}).reset_index()
summary
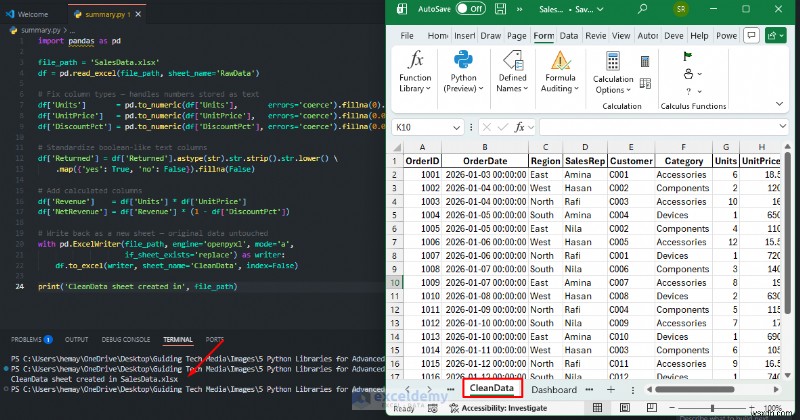
ভিএস কোডে পাইথন:
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='RawData')
# Fix column types — handles numbers stored as text
df['Units'] = pd.to_numeric(df['Units'], errors='coerce').fillna(0).astype(int)
df['UnitPrice'] = pd.to_numeric(df['UnitPrice'], errors='coerce').fillna(0.0)
df['DiscountPct'] = pd.to_numeric(df['DiscountPct'], errors='coerce').fillna(0.0)
# Standardize boolean-like text columns
df['Returned'] = df['Returned'].astype(str).str.strip().str.lower() \
.map({'yes': True, 'no': False}).fillna(False)
# Add calculated columns
df['Revenue'] = df['Units'] * df['UnitPrice']
df['NetRevenue'] = df['Revenue'] * (1 - df['DiscountPct'])
# Write back as a new sheet — original data untouched
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
df.to_excel(writer, sheet_name='CleanData', index=False)
print('CleanData sheet created in', file_path)
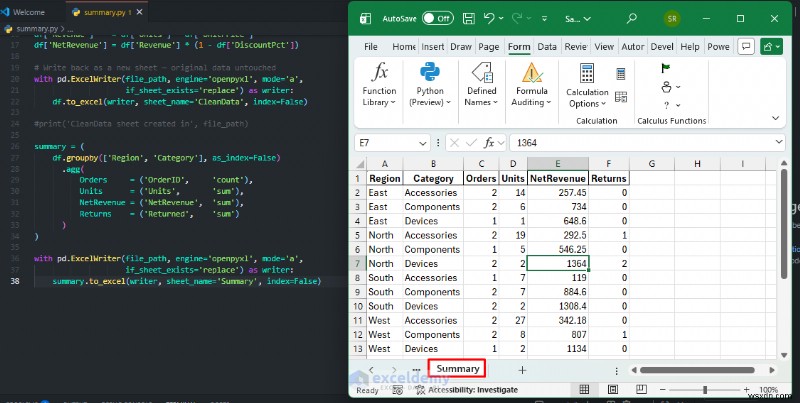
স্বয়ংক্রিয় সারাংশ রিপোর্ট
একটি পান্ডা গ্রুপবি দিয়ে ম্যানুয়াল PivotTables প্রতিস্থাপন করুন ওয়ার্কফ্লো যা সেকেন্ডে চলে এবং প্রতিবার আপনার ডেটা আপডেট করার সময় একটি রেডি-টু-শেয়ার শীট রপ্তানি করে:
summary = (
df.groupby(['Region', 'Category'], as_index=False)
.agg(
Orders = ('OrderID', 'count'),
Units = ('Units', 'sum'),
NetRevenue = ('NetRevenue', 'sum'),
Returns = ('Returned', 'sum')
)
)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
summary.to_excel(writer, sheet_name='Summary', index=False)
কখন ব্যবহার করবেন: আপনি PivotTable-শৈলীর আউটপুট পান, কিন্তু ক্লিনআপ এবং লজিক একই ওয়ার্কফ্লোতে ঘটে। তার মানে কম ভাঙা রিপোর্ট এবং কম ম্যানুয়াল হস্তক্ষেপ। নেটিভ এক্সেলের জন্য খুব বড় বা খুব জটিল ডেটাসেটগুলি পরিচালনা করার জন্য পাওয়ার ব্যবহারকারীরা পান্ডাসের উপর নির্ভর করে, বিশেষ করে যখন একটি ডেটাসেট কয়েক হাজার সারি অতিক্রম করে, যখন আপনাকে একটি পরিষ্কার বা সংক্ষিপ্তকরণের পদক্ষেপ পুনরাবৃত্তি করতে হয়, বা যখন আপনাকে একাধিক উত্স থেকে স্বয়ংক্রিয়ভাবে ডেটা মার্জ করতে হয়৷
2. OpenPyXL – অ্যাডভান্সড এক্সেল ফাইল ম্যানিপুলেশন এবং নেটিভ ফরম্যাটিং
যখন পান্ডা ডেটা পরিচালনা করে, OpenPyXL .xlsx-এর উপর সূক্ষ্ম-দানাযুক্ত নিয়ন্ত্রণে পারদর্শী ফাইল:সেল ফরম্যাটিং, চার্ট, টেবিল, শৈলী, সূত্র এবং ছবি যোগ করা এক্সেল-নেটিভ বৈশিষ্ট্যগুলি না হারিয়ে। এটি আপনাকে সরাসরি .xlsx এর সাথে কাজ করতে দেয় ফাইল, যাতে আপনার পাইথন ওয়ার্কফ্লো শুধুমাত্র কাঁচা বিশ্লেষণের পরিবর্তে এক্সেল-রেডি আউটপুট তৈরি করতে পারে।
এক্সেল পেশাদারদের জন্য মূল শক্তি:
- প্রোগ্রাম্যাটিকভাবে ওয়ার্কবুক তৈরি ও পরিবর্তন করুন
- নতুন শীটে পরিষ্কার করা টেবিল রপ্তানি করুন
- এক্সেল ফর্ম্যাটে সরাসরি পেশাদার চার্ট যোগ করুন যা স্বয়ংক্রিয়ভাবে আপডেট হয়
- পুরনো রিপোর্ট ট্যাবগুলি স্বয়ংক্রিয়ভাবে প্রতিস্থাপন করুন
- নির্দিষ্ট কক্ষে শর্তসাপেক্ষ বিন্যাস, সীমানা, ফন্ট এবং শৈলী প্রয়োগ করুন
- Excel সূত্র যেমন =SUM() ইনজেক্ট করুন অথবা =VLOOKUP() কোষে
- শীটগুলিকে সুরক্ষিত করুন, প্যানগুলিকে ফ্রিজ করুন এবং কলামের প্রস্থগুলি প্রোগ্রামগতভাবে সেট করুন
- অ-পাইথন ব্যবহারকারীদের জন্য ওয়ার্কবুক-ভিত্তিক বিতরণযোগ্য তৈরি করুন
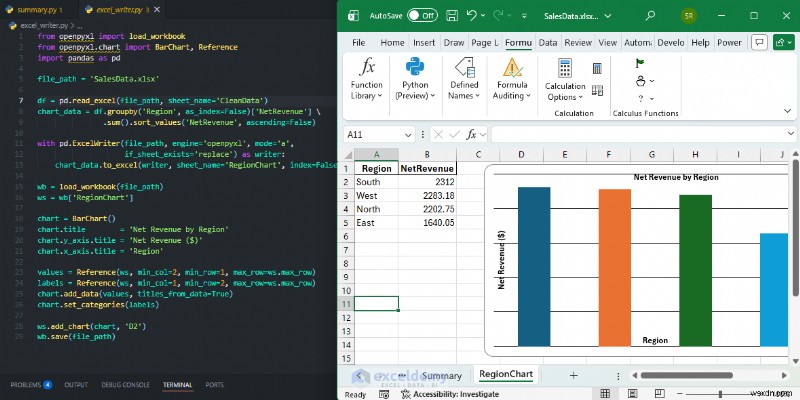
উদাহরণ:আপনার ওয়ার্কবুকে একটি নেটিভ চার্ট যোগ করা
পান্ডা দিয়ে পরিষ্কার ডেটা তৈরি করার পরে, এক্সেল ম্যানুয়ালি না খুলে একটি পেশাদার বার চার্ট যোগ করতে openpyxl ব্যবহার করুন৷
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='CleanData')
chart_data = df.groupby('Region', as_index=False)['NetRevenue'] \
.sum().sort_values('NetRevenue', ascending=False)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
chart_data.to_excel(writer, sheet_name='RegionChart', index=False)
wb = load_workbook(file_path)
ws = wb['RegionChart']
chart = BarChart()
chart.title = 'Net Revenue by Region'
chart.y_axis.title = 'Net Revenue ($)'
chart.x_axis.title = 'Region'
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, 'D2')
wb.save(file_path)
কখন ব্যবহার করবেন: পান্ডা আপনাকে তথ্য বিশ্লেষণ করতে সাহায্য করে। openpyxl আপনাকে এটি সরবরাহ করতে সহায়তা করে। যখন আপনার পিক্সেল-নিখুঁত এক্সেল আউটপুট যেমন হাতে তৈরি করা রিপোর্ট এবং ড্যাশবোর্ডের প্রয়োজন হয় এবং ফলাফলটি যখন .xlsx-এ থাকতে হয় তখন OpenPyXL ব্যবহার করুন নেটিভ এক্সেল চার্ট এবং সহকর্মীরা সম্পাদনা চালিয়ে যেতে পারে এমন বিন্যাস সহ ফাইল৷
3. Matplotlib – এক্সেল চার্টের বাইরে শক্তিশালী ভিজ্যুয়ালাইজেশন
এক্সেল চার্ট সুবিধাজনক, কিন্তু Matplotlib বিশ্লেষকদের অনেক বেশি নিয়ন্ত্রণ দেয়। ম্যাটপ্লটলিব হল স্থির, প্রকাশনা-মানের প্লট তৈরি করার জন্য যেতে যেতে লাইব্রেরি। এটি অত্যন্ত কাস্টমাইজযোগ্য এবং দ্রুত অনুসন্ধানমূলক বিশ্লেষণের জন্য পান্ডাদের সাথে ভালভাবে সংহত করে৷
এক্সেল পেশাদারদের জন্য মূল শক্তি:
- উন্নত প্লট তৈরি করুন যেমন হিটম্যাপ, ট্রেন্ডলাইন সহ স্ক্যাটার প্লট, বক্স প্লট, হিস্টোগ্রাম এবং 3D চার্ট
- ফন্ট, রঙ, গ্রিডলাইন, টিক চিহ্ন এবং কিংবদন্তির উপর আরো নিয়ন্ত্রণ লাভ করুন
- মাল্টি-প্যানেল সাবপ্লট লেআউট তৈরি করুন যা একসাথে একাধিক চার্ট দেখায়
- ইমেজ, PDF, বা SVG-এ রপ্তানি করুন বা OpenPyXL এর সাথে এক্সেলে ভিজ্যুয়াল এম্বেড করুন
- কাস্টম লেবেল এবং তীর দিয়ে ডেটা পয়েন্ট টীকা করুন
উদাহরণ:একটি মাল্টি-প্যানেল সেলস ড্যাশবোর্ড তৈরি করা
আসুন একটি দুই-প্যানেল চার্ট তৈরি করি:বাম দিকে একটি মাসিক আয়ের প্রবণতা এবং ডানদিকে একটি বিভাগ ভাঙ্গন৷ তারপরে আমরা এটিকে একটি উচ্চ-রেজোলিউশন চিত্র হিসাবে সংরক্ষণ করব, যে কোনও প্রতিবেদনের জন্য প্রস্তুত৷
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
df['Month'] = pd.to_datetime(df['OrderDate']).dt.to_period('M')
monthly = df.groupby('Month')['NetRevenue'].sum()
cat_rev = df.groupby('Category')['NetRevenue'].sum().sort_values(ascending=True)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
fig.suptitle('Sales Performance Dashboard', fontsize=16, fontweight='bold')
# Left panel — monthly revenue line chart
ax1.plot(list(monthly.index.astype(str)), monthly.values,
marker='o', color='#1E5FAD', linewidth=2)
ax1.set_title('Monthly Net Revenue')
ax1.set_xlabel('Month')
ax1.set_ylabel('Revenue ($)')
ax1.yaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
ax1.tick_params(axis='x', rotation=45)
ax1.grid(axis='y', linestyle='--', alpha=0.5)
# Right panel — revenue by category horizontal bar chart
ax2.barh(cat_rev.index, cat_rev.values, color='#217346')
ax2.set_title('Revenue by Category')
ax2.set_xlabel('Revenue ($)')
ax2.xaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
plt.tight_layout()
plt.savefig('sales_dashboard.png', dpi=150, bbox_inches='tight')
print('Dashboard saved as sales_dashboard.png')
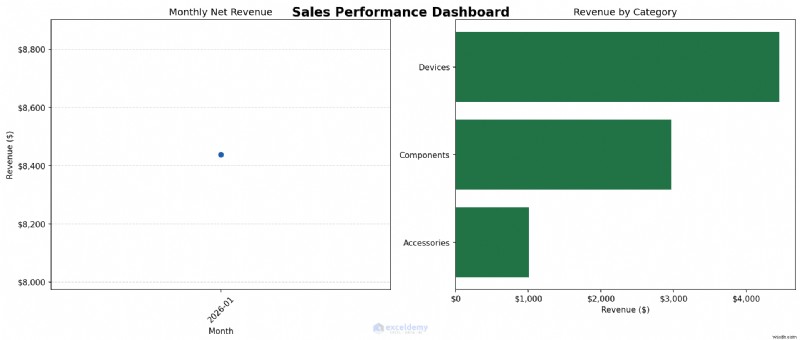
কখন ব্যবহার করবেন: প্রথমে বিশ্লেষণ চার্ট তৈরি করতে পাইথন ব্যবহার করুন। তারপর সিদ্ধান্ত নিন যে চার্টটি একটি পাইথন আউটপুট থাকবে কিনা বা চূড়ান্ত ড্যাশবোর্ড বিন্যাসের জন্য সংক্ষিপ্ত ডেটা এক্সেলে ফেরত দেওয়া উচিত কিনা। যখন আপনার রিপোর্ট বা উপস্থাপনার জন্য চার্টের প্রয়োজন হয়, অথবা যখন ধারাবাহিক স্টাইলিং সহ আপডেট করা ডেটা থেকে বারবার একই চার্ট তৈরি করতে হয় তখন Matplotlib ব্যবহার করুন৷
4. সিবোর্ন - পরিসংখ্যানগত ডেটা ভিজ্যুয়ালাইজেশন
সমুদ্রজাত ম্যাটপ্লটলিব তৈরি করে এবং পরিসংখ্যানগত ভিজ্যুয়ালাইজেশনের উপর ফোকাস করে। এটি দৃশ্যত আকর্ষণীয় চার্ট তৈরিকে সহজ করে যা প্যাটার্ন এবং পারস্পরিক সম্পর্ককে হাইলাইট করে। যেখানে Matplotlib-এর একটি পলিশড চার্টের জন্য কয়েক ডজন লাইনের প্রয়োজন হতে পারে, সেখানে Seaborn প্রায়ই আকর্ষণীয় ডিফল্ট স্টাইলিং সহ এক বা দুটি লাইনে একই ফলাফল অর্জন করতে পারে। এটি আপনার ডেটাতে লুকিয়ে থাকা বিতরণ, পারস্পরিক সম্পর্ক এবং প্যাটার্নগুলি প্রকাশ করতে পারদর্শী৷
এক্সেল পেশাদারদের জন্য মূল শক্তি:
- দ্রুত পরিসংখ্যান চার্ট তৈরি করুন
- অন্বেষণমূলক ডেটা বিশ্লেষণের জন্য ভাল কাজ করুন
- কলামগুলি কীভাবে একে অপরের সাথে সম্পর্কিত তা দেখতে পারস্পরিক সম্পর্ক হিটম্যাপ তৈরি করুন
- ঘনত্ব বক্ররেখা সহ বিতরণ প্লট তৈরি করুন
- বক্স প্লট এবং বেহালা প্লট ব্যবহার করুন দৃশ্যত গ্রুপ তুলনা করতে
- সংখ্যার কলাম জুড়ে একটি স্বয়ংক্রিয় স্ক্যাটারপ্লট ম্যাট্রিক্সের জন্য জোড়া প্লট তৈরি করুন
- একক লাইনে আত্মবিশ্বাসের ব্যবধান সহ রিগ্রেশন প্লট তৈরি করুন
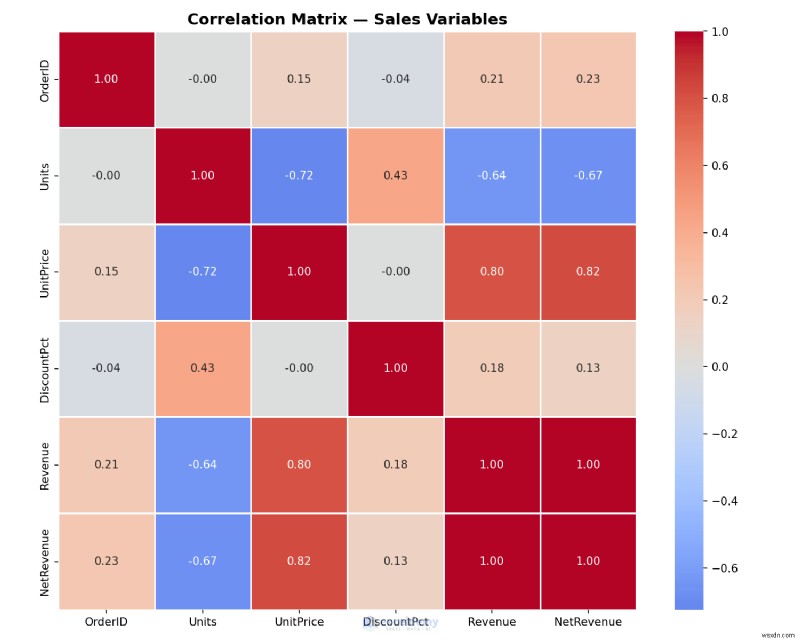
উদাহরণ:একটি পারস্পরিক সম্পর্ক হিটম্যাপ তৈরি করা
আপনার এক্সেল ডেটাতে লুকানো নিদর্শনগুলি খুঁজুন:কোন ভেরিয়েবলগুলি একসাথে চলে? একটি হিটম্যাপ এটির দ্রুত উত্তর দিতে পারে এবং এক্সেলের অন্তর্নির্মিত সরঞ্জামগুলি সাধারণত যা প্রদান করে তার থেকেও ভাল।
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
correlation = df.select_dtypes(include='number').corr()
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation,
annot=True, # show correlation values in each cell
fmt='.2f',
cmap='coolwarm', # red = positive, blue = negative
center=0,
square=True,
linewidths=0.5
)
plt.title('Correlation Matrix — Sales Variables', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('correlation_heatmap.png', dpi=150)
print('Heatmap saved!')
উদাহরণ:এক লাইনে একটি বক্স প্লট তৈরি করা
বহিরাগতদের তাৎক্ষণিকভাবে চিহ্নিত করতে অঞ্চল জুড়ে রাজস্ব বিতরণের তুলনা করুন।
plt.figure(figsize=(10, 6))
sns.boxplot(data=df, x='Region', y='NetRevenue', hue='Region', palette='Set2', legend=False)
plt.title('Revenue Distribution by Region')
plt.ylabel('Net Revenue ($)')
plt.tight_layout()
plt.savefig('region_boxplot.png', dpi=150)
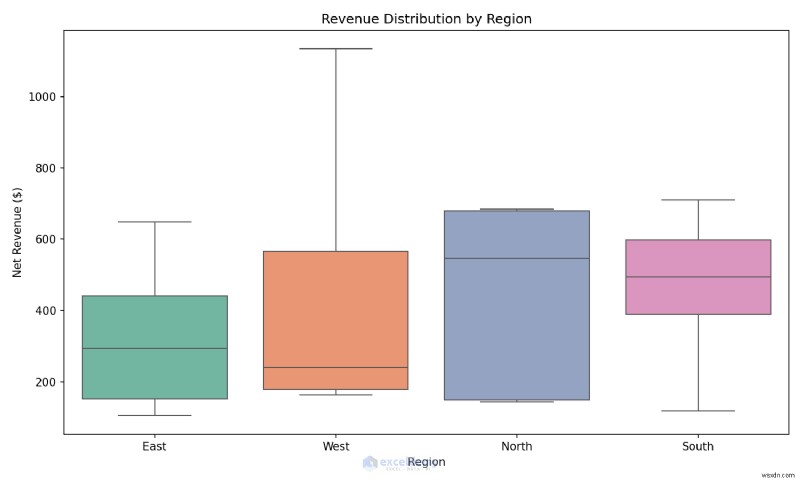
কখন ব্যবহার করবেন: যখন আপনি আনুষ্ঠানিক প্রতিবেদন তৈরি করার আগে বিতরণ, আউটলার এবং সম্পর্কগুলি দ্রুত বুঝতে চান তখন অনুসন্ধানমূলক বিশ্লেষণের সময় Seaborn ব্যবহার করুন৷
5. স্কিট-লার্ন - এক্সেল ডেটাতে সরাসরি মেশিন লার্নিং
এটি সেই লাইব্রেরি যা আপনাকে রিপোর্টিং থেকে সিদ্ধান্ত সমর্থনে নিয়ে যায়। স্কিট-লার্ন আপনার এক্সেল ওয়ার্কফ্লোতে পেশাদার মেশিন লার্নিং নিয়ে আসে। এটি এক্সেল ব্যবহারকারীদের জন্য ভবিষ্যদ্বাণীমূলক বিশ্লেষণ সক্ষম করে, যার মধ্যে রিগ্রেশন, শ্রেণীবিভাগ, ক্লাস্টারিং এবং পূর্বাভাস যা নেটিভ এক্সেল সহজে পরিচালনা করতে পারে না। আপনার ডেটাতে কী ঘটেছে তা বর্ণনা করার পরিবর্তে, এটি আপনাকে বিক্রয়ের পূর্বাভাস দেওয়া থেকে শুরু করে গ্রাহকদের শ্রেণীবিভাগ করা পর্যন্ত অসঙ্গতিগুলি সনাক্ত করা পর্যন্ত পরবর্তী কী ঘটতে পারে তা অনুমান করতে সহায়তা করে৷
এক্সেল পেশাদারদের জন্য মূল শক্তি:
- সংখ্যাসূচক ফলাফল বা বিভাগ যেমন মন্থন ঝুঁকি বা বিক্রয় পূর্বাভাস পূর্বাভাস দিতে লিনিয়ার এবং লজিস্টিক রিগ্রেশন
- ব্যাখ্যাযোগ্য ভবিষ্যদ্বাণীর জন্য সিদ্ধান্ত গাছ এবং এলোমেলো বন
- K- মানে স্বয়ংক্রিয়ভাবে অনুরূপ রেকর্ডগুলিকে গোষ্ঠীভুক্ত করা
- মডেলের নির্ভুলতা পরিমাপের জন্য ট্রেন-টেস্ট স্প্লিটিং এবং ক্রস-ভ্যালিডেশন
- ফিচার স্কেলিং, এনকোডিং এবং প্রিপ্রসেসিং পাইপলাইন
- ফিল্টারিং এবং বাছাই করার জন্য পূর্বাভাসগুলি Excel এ ফেরত দিন
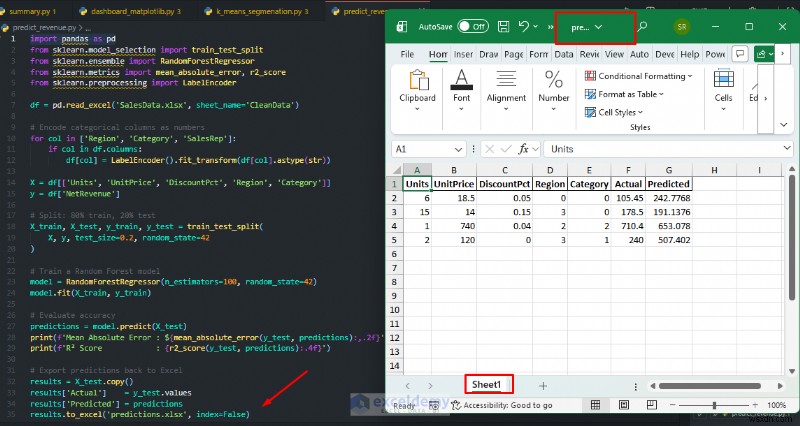
উদাহরণ:নেট আয়ের পূর্বাভাস
আপনার ঐতিহাসিক বিক্রয় ডেটার উপর একটি মডেল প্রশিক্ষিত করুন, তারপর নতুন অর্ডারের জন্য আয়ের পূর্বাভাস দিতে এটি ব্যবহার করুন, যা একটি বিশ্লেষণ এক্সেল নেটিভভাবে কাজ করতে পারে না।
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.preprocessing import LabelEncoder
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
# Encode categorical columns as numbers
for col in ['Region', 'Category', 'SalesRep']:
if col in df.columns:
df[col] = LabelEncoder().fit_transform(df[col].astype(str))
X = df[['Units', 'UnitPrice', 'DiscountPct', 'Region', 'Category']]
y = df['NetRevenue']
# Split: 80% train, 20% test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train a Random Forest model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Evaluate accuracy
predictions = model.predict(X_test)
print(f'Mean Absolute Error: ${mean_absolute_error(y_test, predictions):,.2f}')
print(f'R² Score: {r2_score(y_test, predictions):.4f}')
# Export predictions back to Excel
results = X_test.copy()
results['Actual'] = y_test.values
results['Predicted'] = predictions
results.to_excel('predictions.xlsx', index=False)
print('Predictions exported to predictions.xlsx')
K- মানে গ্রাহক বিভাজন:
ক্রয় আচরণের উপর ভিত্তি করে গ্রাহকদের স্বয়ংক্রিয়ভাবে গ্রুপে ভাগ করুন, কোনো ম্যানুয়াল মানদণ্ডের প্রয়োজন নেই।
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
customer = df.groupby('Customer').agg(
TotalOrders = ('OrderID', 'count'),
TotalRevenue = ('NetRevenue', 'sum'),
AvgDiscount = ('DiscountPct', 'mean')
).reset_index()
X_scaled = StandardScaler().fit_transform(
customer[['TotalOrders', 'TotalRevenue', 'AvgDiscount']]
)
customer['Segment'] = KMeans(n_clusters=3, random_state=42, n_init=10) \
.fit_predict(X_scaled)
customer.to_excel('customer_segments.xlsx', index=False)
print('Segmentation complete! See customer_segments.xlsx')
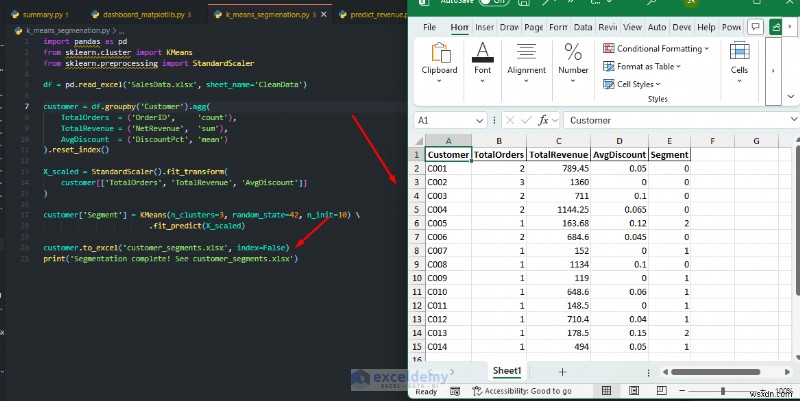
কখন ব্যবহার করবেন: আপনি একটি ওয়ার্কশীটে আবার ভবিষ্যদ্বাণী লিখতে পারেন, তারপর এক্সেল ব্যবহারকারীদের ফিল্টার, বাছাই, চার্ট, বা সূত্র এবং শর্তসাপেক্ষ বিন্যাসের সাথে ফলাফলগুলি একত্রিত করতে দিন। এটি পেশাদারদের সরাসরি স্প্রেডশীটে মেশিন লার্নিং অন্তর্দৃষ্টি যোগ করতে দেয়। আপনি যখন ভবিষ্যতের মানগুলির পূর্বাভাস দিতে হবে, রেকর্ড শ্রেণীবদ্ধ করতে হবে, বা PivotTables প্রকাশ করতে পারে না এমন প্রাকৃতিক গ্রুপিং আবিষ্কার করতে হবে তখন Scikit-learn ব্যবহার করুন৷
বোনাস:Xlwings – দ্বি-মুখী অটোমেশন এবং লাইভ এক্সেল ইন্টিগ্রেশন
xlwings লাইব্রেরি রিয়েল টাইমে একটি এক্সেল উদাহরণ চালায়। এটি পাইথন এবং এক্সেলকে সেতু করে, সত্যিকারের অটোমেশন সক্ষম করে। ওপেনপিএক্সএল স্ট্যাটিক ফাইলগুলি পড়ার এবং লেখার সময়, xlwings এক্সেল খুলতে পারে, এটিকে লাইভ ম্যানিপুলেট করতে পারে, পাইথনে মানগুলি পড়তে পারে, এক্সেল বোতামগুলি থেকে পাইথন ফাংশনগুলি ট্রিগার করতে পারে এবং কোষগুলিতে প্রদর্শিত সম্পূর্ণ UDF (ব্যবহারকারী-সংজ্ঞায়িত ফাংশন) তৈরি করতে পারে। এটি অনেক VBA-ভিত্তিক কর্মপ্রবাহের একটি আধুনিক বিকল্প৷
৷এক্সেল পেশাদারদের জন্য মূল শক্তি:
- একটি লাইভ এক্সেল সেশন নিয়ন্ত্রণ করুন:প্রোগ্রামিকভাবে ওয়ার্কবুক খুলুন, পড়ুন, লিখুন এবং বন্ধ করুন
- ইউডিএফ হিসাবে এক্সেল সেল থেকে সরাসরি কলযোগ্য পাইথন ফাংশনগুলি লিখুন
- পুনরাবৃত্ত কাজগুলিকে স্বয়ংক্রিয় করুন যেমন ডেটা রিফ্রেশ করা এবং রিপোর্ট তৈরি করা
- পান্ডাস ডেটাফ্রেম এবং ম্যাটপ্লোটলিব চার্ট সরাসরি নামযুক্ত রেঞ্জে পুশ করুন
- এক্সেল বোতাম দ্বারা ট্রিগার করা পাইথন স্ক্রিপ্ট চালান
- Windows এবং macOS উভয়েই কাজ করে
- ডেক্সটপ ওয়ার্কফ্লোগুলির জন্য এক্সেলের পাইথনের একটি শক্তিশালী বিকল্প বা পরিপূরক হিসাবে পরিবেশন করুন
আপনি xlwings ব্যবহার করতে পারেন যখন আপনার এক্সেলের সাথে লাইভ, দ্বিমুখী মিথস্ক্রিয়া, VBA ম্যাক্রো প্রতিস্থাপন করার সময়, ইন্টারেক্টিভ ড্যাশবোর্ড তৈরি করার সময় বা অ-প্রযুক্তিগত সহকর্মীদের একটি বোতাম ক্লিকের মাধ্যমে পাইথন বিশ্লেষণগুলিকে ট্রিগার করার অনুমতি দেওয়ার সময় ব্যবহার করতে পারেন।
বিভিন্ন এক্সেল পেশাদারদের জন্য সেরা লাইব্রেরি স্ট্যাক নির্বাচন করা
প্রতিটি বিশ্লেষকের একবারে পাঁচটি লাইব্রেরির প্রয়োজন হয় না। তাদের গ্রহণ করার একটি ব্যবহারিক উপায় হল ভূমিকা দ্বারা।
- রিপোর্টিং বিশ্লেষকদের জন্য: এই সমন্বয় আপনাকে ডেটা পরিষ্কার করতে, সারাংশ তৈরি করতে, চার্ট তৈরি করতে এবং পালিশ ওয়ার্কবুক আউটপুট রপ্তানি করতে দেয়৷
- পান্ডা
- ম্যাটপ্লটলিব
- Openpyxl
- অর্থ এবং অপারেশন বিশ্লেষকদের জন্য: এই স্ট্যাকটি মডেলিং, কেপিআই গণনা, বরাদ্দ এবং পুনরাবৃত্তিযোগ্য মাসিক প্রতিবেদনের জন্য ভাল কাজ করে৷
- পান্ডা
- সমুদ্রজাত
- Openpyxl
- উন্নত অ্যানালিটিক্স টিমের জন্য: এই সংমিশ্রণটি আপনাকে ডেটা প্রস্তুতি থেকে শুরু করে ভবিষ্যদ্বাণীমূলক স্কোরিং থেকে ওয়ার্কবুক ডেলিভারি পর্যন্ত সম্পূর্ণ পাইপলাইন দেয়৷
- পান্ডা
- ম্যাটপ্লটলিব
- স্কিট-লার্ন
- Openpyxl
- সমুদ্রজাত
চূড়ান্ত চিন্তা
উন্নত এক্সেল ডেটা বিশ্লেষণের জন্য এই পাঁচটি পাইথন লাইব্রেরি যা প্রত্যেক প্রো-এর ব্যবহার করা উচিত। এই সরঞ্জামগুলিকে আয়ত্ত করুন, এবং আপনি একটি সাধারণ স্প্রেডশীট অ্যাপ্লিকেশন থেকে এক্সেলকে আরও সক্ষম বিশ্লেষণ প্ল্যাটফর্মে রূপান্তর করতে পারেন৷ একটি বুদ্ধিমান শিক্ষার পথ হল পান্ডা দিয়ে শুরু করা, তারপরে openpyxl যোগ করা, তারপরে Matplotlib এবং Seaborn একসাথে শেখা, এবং তারপরে Scikit-learn সামলাতে হবে। প্রতিটি লাইব্রেরি একই .xlsx দিয়ে কাজ করে আপনি ইতিমধ্যে ব্যবহার করা ফাইল. আরও দক্ষ ডেটা বিশ্লেষক হওয়ার জন্য তাদের অন্বেষণ শুরু করুন৷
৷ সমাধান সহ বিনামূল্যে উন্নত এক্সেল ব্যায়াম পান!