পাইথন ডেটা বিশ্লেষণ এবং ভিজ্যুয়ালাইজেশনের জন্য অনেকগুলি লাইব্রেরি সরবরাহ করে যা মূলত নম্পি, পান্ডা, ম্যাটপ্লটলিব, সিবোর্ন ইত্যাদি। এই বিভাগে, আমরা ডাটা বিশ্লেষণ এবং ভিজ্যুয়ালাইজেশনের জন্য পান্ডাস লাইব্রেরি নিয়ে আলোচনা করতে যাচ্ছি যা নম্পির উপরে নির্মিত একটি ওপেন সোর্স লাইব্রেরি।
এটি আমাদের দ্রুত বিশ্লেষণ এবং ডেটা পরিষ্কার এবং প্রস্তুতির অনুমতি দেয়৷ পান্ডাস অনেকগুলি অন্তর্নির্মিত ভিজ্যুয়ালাইজেশন বৈশিষ্ট্যও প্রদান করে যা আমরা নীচে দেখতে যাচ্ছি৷
ইনস্টলেশন
পান্ডা ইনস্টল করতে, আপনার টার্মিনালে নিচের কমান্ডটি চালান -
pipinstall pandas
অরওয়ের কাছে অ্যানাকোন্ডা আছে, আপনি ব্যবহার করতে পারেন
condainstall pandas
পান্ডাস-ডেটাফ্রেম
যখন আমরা পান্ডাদের সাথে কাজ করি তখন ডেটা ফ্রেমই প্রধান টুল।
কোড −
import numpy as np import pandas as pd from numpy.random import randn np.random.seed(50) df = pd.DataFrame(randn(6,4), ['a','b','c','d','e','f'],['w','x','y','z']) df
আউটপুট
| ৷ | w | x | y | z |
|---|---|---|---|---|
| a | -1.560352 | -0.030978 | -0.620928 | -1.464580 |
| b | 1.411946 | -0.476732 | -0.780469 | 1.070268 |
| c | -1.282293 | -1.327479 | 0.126338 | 0.862194 |
| d | 0.696737 | -0.334565 | -0.997526 | 1.598908 |
| e | 3.314075 | 0.987770 | 0.123866 | 0.742785 |
| f | -0.393956 | 0.148116 | -0.412234 | -0.160715 |
পান্ডাস-অনুপস্থিত ডেটা
অনুপস্থিত ডেটা ইনপান্ডাস মোকাবেলা করার কিছু সুবিধাজনক উপায় দেখতে যাচ্ছি, যা স্বয়ংক্রিয়ভাবে শূন্য বা ন্যান দিয়ে পূর্ণ হয়ে যায়।
import numpy as np
import pandas as pd
from numpy.random import randn
d = {'A': [1,2,np.nan], 'B': [9, np.nan, np.nan], 'C': [1,4,9]}
df = pd.DataFrame(d)
df আউটপুট
| | A | B | C |
|---|---|---|---|
| 0 | 1.0 | 9.0 | 1 |
| 1 | 2.0 | NaN | 4 |
| 2 | NaN | NaN | 9 |
সুতরাং, উপরে আমাদের 3টি অনুপস্থিত মান রয়েছে।
df.dropna()
| | A | B | সি |
|---|---|---|---|
| 0 | 1.0 | 9.0 | 1 |
df.dropna(axis = 1)
| | সি |
|---|---|
| 0 | 1 |
| 1 | 4 |
| 2 | 9 |
df.dropna(thresh = 2)
| | A | B | সি |
|---|---|---|---|
| 0 | 1.0 | 9.0 | 1 |
| 1 | 2.0 | NaN | 4 |
df.fillna(value = df.mean())
| | A | B | সি |
|---|---|---|---|
| 0 | 1.0 | 9.0 | 1 |
| 1 | 2.0 | 9.0 | 4 |
| 2 | 1.5 | 9.0 | 9 |
পান্ডাস − ডেটা আমদানি করুন
আমরা csv ফাইলটি পড়তে যাচ্ছি যা হয় আমাদের স্থানীয় মেশিনে সংরক্ষিত (আমার ক্ষেত্রে) অথবা আমরা সরাসরি ওয়েব থেকে আনতে পারি।
#import pandas library
import pandas as pd
#Read csv file and assigned it to dataframe variable
df = pd.read_csv("SYB61_T03_Population Growth Rates in Urban areas and Capital cities.csv",encoding = "ISO-8859-1")
#Read first five element from the dataframe
df.head() থেকে প্রথম পাঁচটি উপাদান পড়ুন আউটপুট
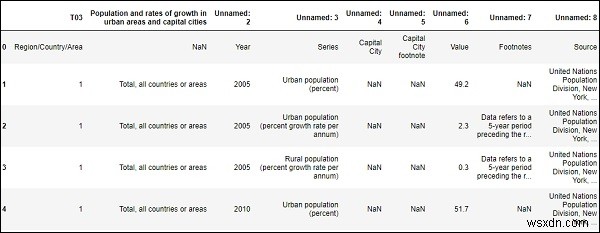
আমাদের ডেটাফ্রেম বা csv ফাইলে সারি এবং কলামের সংখ্যা পড়তে।
#Countthe number of rows and columns in our dataframe. df.shape
আউটপুট
(4166,9)
পান্ডাস − ডেটাফ্রেম ম্যাথ
পান্ডা ফরস্ট্যাটিস্টিক্সের বিভিন্ন টুল ব্যবহার করে অপারেশনস ডাটাফ্রেম করা যেতে পারে
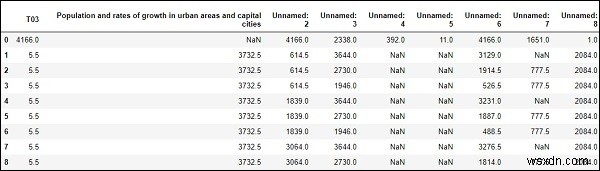
#To computes various summary statistics, excluding NaN values df.describe()
আউটপুট

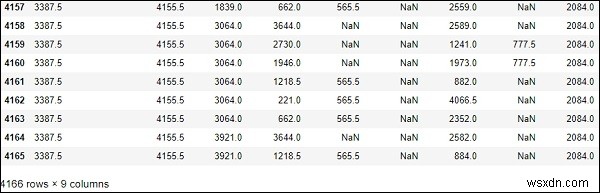
# computes numerical data ranks df.rank()
আউটপুট
.....
.....
পান্ডাস − প্লট গ্রাফ
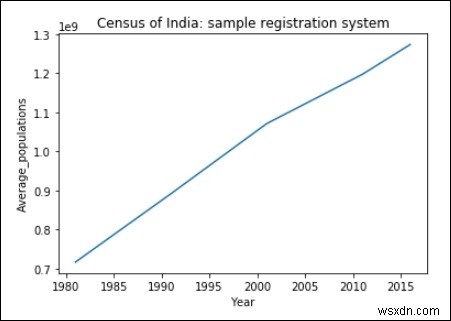
import matplotlib.pyplot as plt
years = [1981, 1991, 2001, 2011, 2016]
Average_populations = [716493000, 891910000, 1071374000, 1197658000, 1273986000]
plt.plot(years, Average_populations)
plt.title("Census of India: sample registration system")
plt.xlabel("Year")
plt.ylabel("Average_populations")
plt.show() আউটপুট
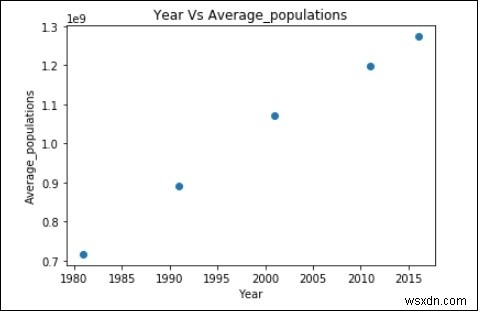
উপরের ডেটার স্ক্যাটার প্লট:
plt.scatter(years,Average_populations)
হিস্টোগ্রাম:
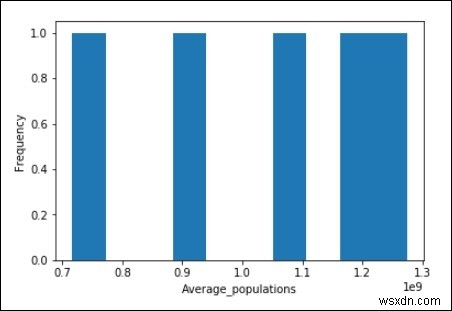
import matplotlib.pyplot as plt
Average_populations = [716493000, 891910000, 1071374000, 1197658000, 1273986000]
plt.hist(Average_populations, bins = 10)
plt.xlabel("Average_populations")
plt.ylabel("Frequency")
plt.show() আউটপুট