ডাটা সায়েন্স এবং অ্যানালিটিক্সের জন্য পান্ডাস হল সবচেয়ে জনপ্রিয় পাইথন লাইব্রেরি। পান্ডাস লাইব্রেরি ডেটা ম্যানিপুলেশন, বিশ্লেষণ এবং পরিষ্কারের জন্য ব্যবহৃত হয়। এটি নিম্ন-স্তরের NumPy-এর উপর একটি উচ্চ-স্তরের বিমূর্ততা যা সম্পূর্ণরূপে C তে লেখা। এই বিভাগে, আমরা কিছু গুরুত্বপূর্ণ (সবচেয়ে বেশি ব্যবহৃত) বিষয়গুলি কভার করব যা একজন বিশ্লেষক বা ডেটা বিজ্ঞানী হিসাবে আমাদের জানা দরকার৷
লাইব্রেরি ইনস্টল করা হচ্ছে
আমরা পিপ ব্যবহার করে প্রয়োজনীয় লাইব্রেরি ইনস্টল করতে পারি, আপনার কমান্ড টার্মিনালে নিচের কমান্ডটি চালান:
পিপ ইনটাল পান্ডা
ডেটাফ্রেম এবং সিরিজ
প্রথমে আমাদের পান্ডাগুলির দুটি প্রধান মৌলিক ডেটা কাঠামো বুঝতে হবে। ডেটাফ্রেম এবং সিরিজ। পান্ডাদের আয়ত্ত করার জন্য আমাদের এই দুটি ডেটা স্ট্রাকচারের দৃঢ় ধারণা থাকা দরকার।
সিরিজ
সিরিজ হল এমন একটি বস্তু যা পাইথন বিল্ট-ইন টাইপ তালিকার অনুরূপ কিন্তু এটি থেকে আলাদা কারণ এটি প্রতিটি উপাদান বা সূচকের সাথে লেবেল যুক্ত করেছে।
>>> pd হিসাবে পান্ডা আমদানি করুন>>> my_series =pd.Series([12, 24, 36, 48, 60, 72, 84])>>> my_series0 121 242 363 484 605 726 84dtype:প্রাক>উপরের আউটপুটে, 'সূচক' বাম দিকে এবং 'মান' ডানদিকে রয়েছে। এছাড়াও প্রতিটি সিরিজ অবজেক্টের ডেটা টাইপ(dtype), আমাদের ক্ষেত্রে এটি int64।
আমরা উপাদানগুলিকে তাদের সূচক নম্বর দ্বারা পুনরুদ্ধার করতে পারি:
>>> my_series[6]84সূচী (লেবেল) স্পষ্টতা প্রদান করতে, ব্যবহার করুন:
>>> my_series =pd.Series([12, 24, 36, 48, 60, 72, 84], index =['ind0', 'ind1', 'ind2', 'ind3', 'ind4' , 'ind5', 'ind6'])>>> my_seriesind0 12ind1 24ind2 36ind3 48ind4 60ind5 72ind6 84dtype:int64এছাড়াও তাদের সূচী দ্বারা বিভিন্ন উপাদান পুনরুদ্ধার করা বা গ্রুপ অ্যাসাইনমেন্ট করা খুব সহজ:
>>> my_series[['ind0', 'ind3', 'ind6']]ind0 12ind3 48ind6 84dtype:int64>>> my_series[['ind0', 'ind3', 'ind6']] =36>>> my_seriesind0 36ind1 24ind2 36ind3 36ind4 60ind5 72ind6 36dtype:int64ফিল্টারিং এবং গণিত অপারেশনগুলিও সহজ:
>>> my_series[my_series>24]ind0 36ind2 36ind3 36ind4 60ind5 72ind6 36dtype:int64>>> my_series[my_series <24] * 2Series([], dtype:int64ind20)>3ind3ind20)>3ind64 36dtype:int64>>>নীচে সিরিজের অন্যান্য সাধারণ ক্রিয়াকলাপ রয়েছে৷
৷>>> # অভিধান হিসেবে কাজ করুন>>> my_series1 =pd.Series({'a':9, 'b':18, 'c':27, 'd':36})>>> my_series1a 9b 18c 27d 36dtype:int64>>> #Label attributes>>> my_series1.name ='Numbers'>>> my_series1.index.name ='letters'>>>> my_series1lettersa 9b 18c 27d 36Name:Numbers, intpety>6>d #chaning Index>>> my_series1.index =['w', 'x', 'y', 'z']>>> my_series1w 9x 18y 27z 36Name:Numbers, dtype:int64>>>ডেটাফ্রেম
ডেটাফ্রেম একটি টেবিলের মতো কাজ করে কারণ এতে সারি এবং কলাম রয়েছে। ডেটাফ্রেমের প্রতিটি কলাম একটি সিরিজ অবজেক্ট এবং সারিগুলি সিরিজের ভিতরে উপাদান নিয়ে গঠিত।
বিল্ট-ইন পাইথন ডিক্টস ব্যবহার করে ডেটাফ্রেম তৈরি করা যেতে পারে:
>>> df =pd.DataFrame({ 'দেশ':['চীন', 'ভারত', 'ইন্দোনেশিয়া', 'পাকিস্তান'], 'জনসংখ্যা':[1420062022, 1368737513, 269536482, 2049, 425] এরিয়া ':[9388211, 2911570, 770880] 1811570, 770880]} dtype:object>>> df.columnsIndex(['Area', 'Country', 'Population'], dtype='object')>>> df.indexRangeIndex(start=0, stop=4, step=1)>>>এলিমেন্ট অ্যাক্সেস করা
স্পষ্টভাবে সারি সূচক প্রদান করার বিভিন্ন উপায় আছে।
>>> df =pd.DataFrame({ 'দেশ':['চীন', 'ভারত', 'ইন্দোনেশিয়া', 'পাকিস্তান'], 'জনসংখ্যা':[1420062022, 1368737513, 269536482, 2049, 425] ল্যান্ডরিয়ার ':[9388211, ২970880, 1811570, ২970880], সূচী =[' চা ',' ইন্ড ',' ইডো ',' পাক '])>>> DFCountry Landarea Pachinesiacha 9388211 1420062022 ভারত 2973190 1368737513IDo ইন্দোনেশিয়া 1811570 269536482 পাক 770880 204596442>>>> df.index =['CHI', 'IND', 'IDO', 'PAK']>>> df.index.name ='দেশের কোড'>>>> dfCountry Landarea PopulationCountry CodeCHI India 938182012020IND 2973190 1368737513IDO ইন্দোনেশিয়া 1811570 269536482PAK পাকিস্তান 770880 204596442>>> df['দেশ']দেশের কোডচি চিনাইন্ড ইন্ডিয়াআইডো ইন্দোনেশিয়া, পাকিস্তান অবজেক্ট:কান্ট্রিপ্রেডেনসূচী ব্যবহার করে সারি অ্যাক্সেস বিভিন্ন উপায়ে সঞ্চালিত হতে পারে
- .loc ব্যবহার করে এবং ইনডেক্স লেবেল প্রদান করে
- .iloc ব্যবহার করা এবং সূচক নম্বর প্রদান করা
>>> df.loc['IND']দেশ ইন্ডিয়াল্যান্ডেরিয়া 2973190জনসংখ্যা 1368737513নাম:IND, dtype:object>>> df.iloc[1]দেশ ইন্ডিয়াল্যান্ডেরিয়া 2973190জনসংখ্যা:1368737513>ডিপি>অবজেক্ট>5>ডিপি> .loc[['CHI', 'IND'], 'জনসংখ্যা']দেশের কোডচি 1420062022IND 1368737513 নাম:জনসংখ্যা, dtype:int64ফাইল পড়া এবং লেখা
পান্ডাস CSV, XML, HTML, Excel, SQL, JSON সহ অনেক জনপ্রিয় ফাইল ফরম্যাট সমর্থন করে। সাধারণত CSV ফাইল ফরম্যাট ব্যবহার করা হয়।
একটি csv ফাইল পড়তে, শুধু চালান:
>>> df =pd.read_csv('GDP.csv', sep =',')নামযুক্ত আর্গুমেন্ট sep CSV ফাইলে GDP.csv নামে একটি বিভাজক অক্ষর নির্দেশ করে।
একত্রীকরণ এবং গ্রুপিং
পান্ডায় ডেটা গ্রুপ করার জন্য আমরা .groupby পদ্ধতি ব্যবহার করতে পারি। আমি টাইটানিক ডেটাসেট ব্যবহার করেছি পান্ডাতে সমষ্টি এবং গোষ্ঠীকরণের ব্যবহার প্রদর্শন করতে, আপনি নীচের লিঙ্ক থেকে এটি খুঁজে পেতে পারেন:
https://yadi.sk/d/TfhJdE2k3EyALt
>>> titanic_df =pd.read_csv('titanic.csv')>>> print(titanic_df.head())যাত্রী আইডি নাম PClass বয়স \0 1 অ্যালেন, মিস এলিজাবেথ ওয়ালটন 1লা 29.001 2 অ্যালিসন, মিস হেলেন লোরেইন 1ম 2.002 3 অ্যালিসন, মিস্টার হাডসন জোশুয়া ক্রাইটন 1ম 30.003 4 অ্যালিসন, মিসেস হাডসন জেসি (বেসি ওয়াল্ডো ড্যানিয়েলস) 1ম 25.004 5 অ্যালিসন, মাস্টার হাডসন ট্রেভর 1ম 0.92 সেক্স সারভাইভড লিঙ্গ>>কতজন যাত্রী (নারী এবং পুরুষ) বেঁচেছিলেন এবং কতজন বাঁচেননি তা হিসাব করা যাক, আমরা .groupby
ব্যবহার করব।>>> print(titanic_df.groupby(['Sex', 'survived'])['PassengerID'].count())Sex Survivedfemale 0 154 1 308male 0 709 1 142Name:PassengerID, dtype:প্রাক>কেবিন ক্লাসের উপর ভিত্তি করে উপরের ডেটা:
>>> print(titanic_df.groupby(['PClass', 'survived'])['PassengerID'].count())PClass survived* 0 11st 0 129 1 1932nd 0 160 1 1193rd 0 51381ame:প্যাসেঞ্জারআইডি, dtype:int64পান্ডা ব্যবহার করে সময় সিরিজ বিশ্লেষণ
টাইম সিরিজ ডেটা বিশ্লেষণ করার জন্য পান্ডা তৈরি করা হয়েছিল। ব্যাখ্যা করার জন্য, আমি amazon 5 বছরের স্টকের দাম ব্যবহার করেছি। আপনি নীচের লিঙ্ক থেকে এটি ডাউনলোড করতে পারেন,
https://finance.yahoo.com/quote/AMZN/history?period1=1397413800&period2=1555180200&interval=1mo&filter=history&frequency=1mo
>>> pd হিসাবে পান্ডা আমদানি করুন>>>> amzn_df =pd.read_csv('AMZN.csv', index_col='Date', parse_dates=True)>>> amzn_df =amzn_df.sort_index()>>> প্রিন্ট( amzn_df.info())তারিখ সময়সূচী:62টি এন্ট্রি, 2014-04-01 থেকে 2019-04-12ডেটা কলাম (মোট 6টি কলাম):62টি নন-নাল অবজেক্ট উচ্চ 62টি খুলুন নাল অবজেক্টলো 62 নন-নাল অবজেক্টক্লোজ 62 নন-নাল অবজেক্টএডজে 62 নন-নাল অবজেক্ট ভলিউম 62 নন-নাল অবজেক্ট টাইপস:অবজেক্ট(6)মেমরি ব্যবহার:1.9+ KBNone উপরে আমরা তারিখ কলাম দ্বারা DatetimeIndex সহ একটি DataFRame তৈরি করেছি এবং তারপরে এটি সাজান৷
এবং গড় বন্ধ মূল্য হল,
>>> amzn_df.loc['2015-04', 'Close'].mean()421.779999ভিজ্যুয়ালাইজেশন
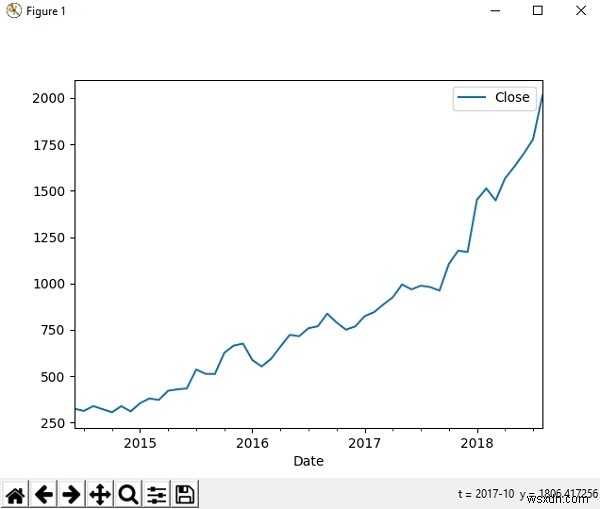
আমরা পান্ডা কল্পনা করতে matplotlib লাইব্রেরি ব্যবহার করতে পারি। আমাদের অ্যামাজন স্টক ঐতিহাসিক ডেটাসেট নেওয়া যাক এবং গ্রাফের উপর নির্দিষ্ট সময়কালের দামের গতিবিধি দেখুন।
>>> matplotlib.pyplot plt হিসাবে আমদানি করুন>>> df =pd.read_csv('AMZN.csv', index_col ='তারিখ' , parse_dates =True)>>> new_df =df.loc['2014-06 ':'2018-08', ['ক্লোজ']]>>> new_df=new_df.astype(float)>>>> new_df.plot()>>> plt। দেখান()