
ডেটা বিশ্লেষণের জন্য, অনুসন্ধানমূলক ডেটা বিশ্লেষণ (EDA) আপনার প্রথম পদক্ষেপ হতে হবে। অনুসন্ধানমূলক ডেটা বিশ্লেষণ আমাদের −
করতে সাহায্য করে-
একটি ডেটা সেটের অন্তর্দৃষ্টি দিতে।
-
অন্তর্নিহিত গঠন বুঝুন।
-
তাদের মধ্যে থাকা গুরুত্বপূর্ণ পরামিতি এবং সম্পর্কগুলি বের করুন৷
-
অন্তর্নিহিত অনুমান পরীক্ষা করুন।
নমুনা ডেটা সেট ব্যবহার করে EDA বোঝা
পাইথন ব্যবহার করে EDA বোঝার জন্য, আমরা সরাসরি যেকোনো ওয়েবসাইট বা আপনার স্থানীয় ডিস্ক থেকে নমুনা ডেটা নিতে পারি। আমি UCI মেশিন লার্নিং রিপোজিটরি থেকে নমুনা ডেটা নিচ্ছি যেটি ওয়াইন কোয়ালিটি ডেটা সেটের একটি লাল রূপের সর্বজনীনভাবে উপলব্ধ এবং EDA ব্যবহার করে ডেটা সেটের অনেক অন্তর্দৃষ্টি নেওয়ার চেষ্টা করি৷
pddf =pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")df.head() হিসেবে পান্ডা আমদানি করুন
জুপিটার নোটবুকে স্ক্রিপ্টের উপরে চালানো, নীচের মত কিছু আউটপুট দেবে −
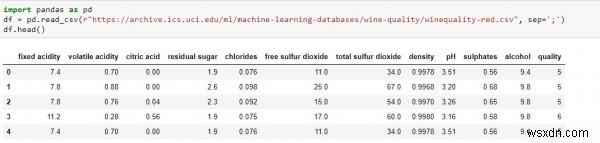
দিয়ে শুরু করতে,
-
প্রথমত, প্রয়োজনীয় লাইব্রেরি আমদানি করুন, ক্ষেত্রে পান্ডা।
-
পান্ডাস লাইব্রেরির read_csv() ফাংশন ব্যবহার করে csv ফাইলটি পড়ুন এবং প্রতিটি ডেটা ডিলিমিটার দ্বারা আলাদা করা হয়েছে “;” প্রদত্ত ডেটা সেটে৷
৷ -
পান্ডাস লাইব্রেরি দ্বারা প্রদত্ত “.head” ফাংশনের সাহায্যে ডেটা সেট থেকে প্রথম পাঁচটি পর্যবেক্ষণ ফেরত দিন। আমরা পান্ডাস লাইব্রেরির “.tail()” ফাংশন ব্যবহার করে একইভাবে শেষ পাঁচটি পর্যবেক্ষণ পেতে পারি।
আমরা নীচের মত “.shape” ব্যবহার করে ডেটা সেট থেকে সারি এবং কলামের মোট সংখ্যা পেতে পারি -
df.shape

ইনফো() ফাংশনের সাহায্যে এটির সমস্ত কলামে কী রয়েছে, কী ধরণের এবং এতে কোনও মান রয়েছে কিনা তা খুঁজে বের করতে।
df.info()
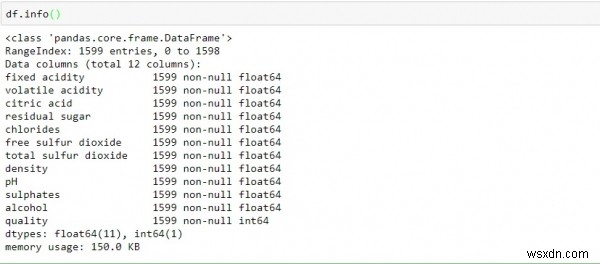
উপরোক্ত তথ্য পর্যবেক্ষণ করে, আমরা উপসংহারে আসতে পারি −
-
ডেটাতে শুধুমাত্র একটি ফ্লোট একটি পূর্ণসংখ্যার মান থাকে।
-
সমস্ত কলাম ভেরিয়েবল অ-নাল (কোন-খালি বা অনুপস্থিত মান)।
পান্ডাদের দ্বারা প্রদত্ত আরেকটি দরকারী ফাংশন হল describe() যা গণনা, গড়, মানক বিচ্যুতি, সর্বনিম্ন এবং সর্বোচ্চ মান এবং ডেটার পরিমাণ প্রদান করে।
df.describe()
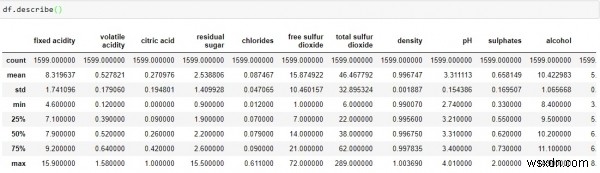
-
উপরের ডেটা থেকে, আমরা উপসংহারে আসতে পারি যে প্রতিটি কলামের গড় মান সূচক কলামের মধ্যম মানের (50%) থেকে কম৷
-
ভবিষ্যদ্বাণীকারী "অবশিষ্ট চিনি", "মুক্ত সালফার ডাই অক্সাইড" এবং "মোট সালফার ডাই অক্সাইড" এর 75% এবং সর্বোচ্চ মানের মধ্যে একটি বিশাল পার্থক্য রয়েছে৷
-
উপরে দুটি পর্যবেক্ষণ, একটি ইঙ্গিত দেয় যে চরম মান রয়েছে- আমাদের ডেটা সেটে বিচ্যুতি।
নির্ভরশীল ভেরিয়েবল থেকে আমরা যে কয়েকটি মূল অন্তর্দৃষ্টি পেতে পারি তা হল অনুসরণ −
df.quality.unique()

-
"গুণমান" স্কোর স্কেলে, 1 নিচের দিকে আসে। দরিদ্র এবং 10 শীর্ষে আসে। সেরা।
-
উপর থেকে আমরা উপসংহারে আসতে পারি, পর্যবেক্ষণ স্কোর 1(খারাপ), 2 এবং 9, 10(সেরা) স্কোরের কোনটিই নয়। সমস্ত স্কোর 3 থেকে 8 এর মধ্যে।
df.quality.value_counts()
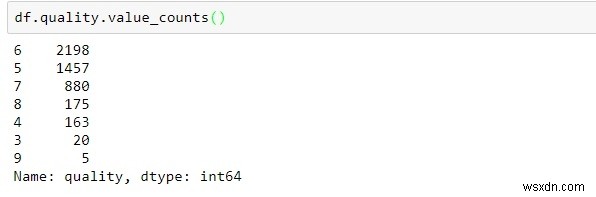
-
-
বেশিরভাগ গুণমান 5-7 এর মধ্যে।
-
সর্বনিম্ন পর্যবেক্ষণগুলি 3 এবং 6 বিভাগে পরিলক্ষিত হয়৷৷
ডেটা ভিজ্যুয়ালাইজেশন
অনুপস্থিত মান চেক করতে -
আমরা সমুদ্রের লাইব্রেরির সাহায্যে আমাদের সাদা-হুইস্কি csv ডেটা সেটে অনুপস্থিত মানগুলি পরীক্ষা করতে পারি। −
পূর্ণ করার কোডটি নিচে দেওয়া হলpdimport numpy হিসাবে npimport seaborn হিসাবে snsimport matplotlib.pyplot হিসাবে plt%matplotlib inlinesns.set()df =pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning- databases/wine-quality/winequality-white.csv", sep=";")sns.heatmap(df.isnull(), cbar=False, yticklabels=False, cmap='viridis') আউটপুট
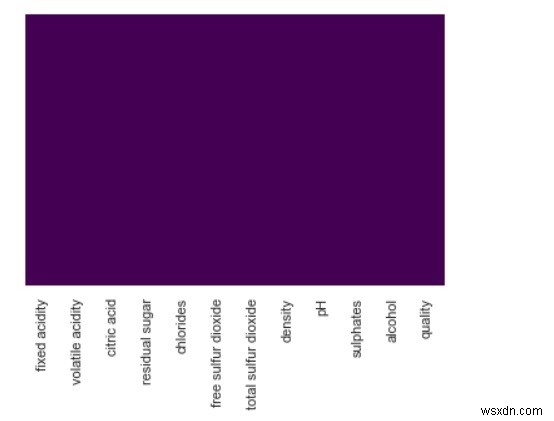
-
উপরে থেকে আমরা দেখতে পাচ্ছি ডেটাসেটে কোন অনুপস্থিত মান নেই। যদি কোনটি থাকে তবে আমরা বেগুনি পটভূমিতে বিভিন্ন রঙের ছায়া দ্বারা উপস্থাপিত চিত্র দেখতে পেতাম।
-
বিভিন্ন ডেটাসেটের সাথে যেখানে মান অনুপস্থিত রয়েছে এবং আপনি পার্থক্যটি লক্ষ্য করবেন।
পারস্পরিক সম্পর্ক পরীক্ষা করতে
ডেটাসেটের বিভিন্ন মানের মধ্যে পারস্পরিক সম্পর্ক পরীক্ষা করতে, আমাদের বিদ্যমান ডেটাসেটে নিচের কোডটি সন্নিবেশ করুন -
plt.figure(figsize=(8,4))sns.heatmap(df.corr(),cmap='Greens',annot=False)
আউটপুট
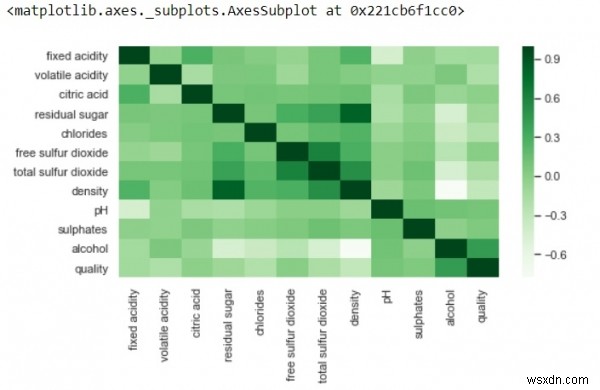
-
উপরে, ইতিবাচক পারস্পরিক সম্পর্ক গাঢ় ছায়া দ্বারা এবং নেতিবাচক সম্পর্ক হালকা ছায়া দ্বারা প্রতিনিধিত্ব করা হয়।
-
annot=True-এর মান পরিবর্তন করে, এবং আউটপুট আপনাকে সেই মানগুলি দেখাবে যার দ্বারা গ্রিড-কোষে বৈশিষ্ট্যগুলি একে অপরের সাথে সম্পর্কযুক্ত।
আমরা annot=True দিয়ে আরেকটি পারস্পরিক সম্পর্ক ম্যাট্রিক্স তৈরি করতে পারি। আমাদের বিদ্যমান কোড −
-এ কোডের নিচের লাইন যোগ করে আপনার কোড পরিবর্তন করুনk =12cols =df.corr().nlargest(k, 'quality')['quality'].indexcm =df[cols].corr()plt.figure(figsize=(8,6))sns .heatmap(cm, annot=True, cmap ='viridis')
আউটপুট
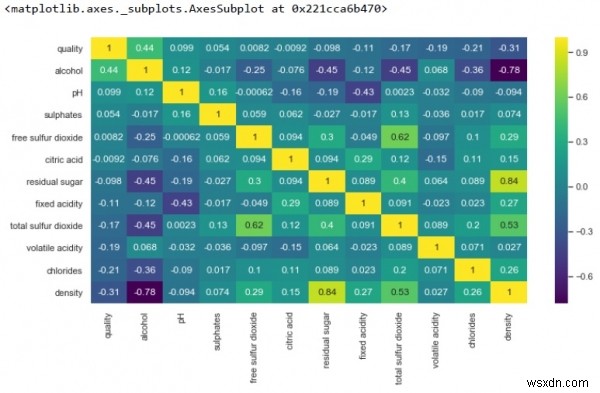
-
উপরে থেকে আমরা দেখতে পাচ্ছি, অবশিষ্ট চিনির সাথে ঘনত্বের একটি শক্তিশালী ইতিবাচক সম্পর্ক রয়েছে। যাইহোক, ঘনত্ব এবং অ্যালকোহলের একটি শক্তিশালী নেতিবাচক সম্পর্ক।
-
এছাড়াও, বিনামূল্যে সালফার ডাই অক্সাইড এবং গুণমানের মধ্যে কোন সম্পর্ক নেই।
