
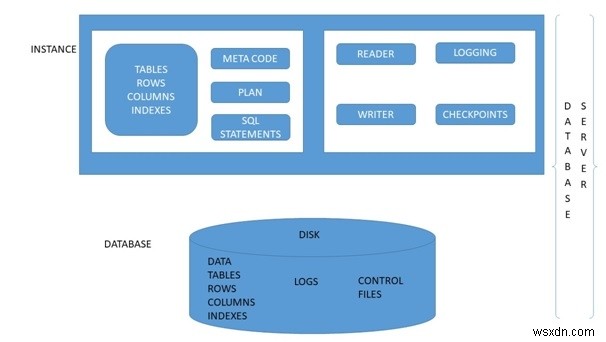
রিলেশনাল ডাটাবেস ডিজাইন (RDD) মডেলের তথ্য এবং ডেটা সারি এবং কলাম সহ টেবিলের একটি সেটে। একটি সম্পর্ক/সারণীর প্রতিটি সারি একটি রেকর্ড উপস্থাপন করে এবং প্রতিটি কলাম ডেটার একটি বৈশিষ্ট্য উপস্থাপন করে। স্ট্রাকচার্ড ক্যোয়ারী ল্যাঙ্গুয়েজ (SQL) রিলেশনাল ডাটাবেস ম্যানিপুলেট করতে ব্যবহৃত হয়। একটি রিলেশনাল ডাটাবেসের নকশা চারটি ধাপের সমন্বয়ে গঠিত, যেখানে ডেটা সম্পর্কিত টেবিলের একটি সেটে মডেল করা হয়। পর্যায়গুলি হল −
- সম্পর্ক/গুণাবলী সংজ্ঞায়িত করুন
- প্রাথমিক কী সংজ্ঞায়িত করুন
- সম্পর্ককে সংজ্ঞায়িত করুন
- স্বাভাবিককরণ
রিলেশনাল ডাটাবেসগুলি ডেটা সংগঠিত করতে এবং লেনদেন সম্পাদন করার পদ্ধতিতে অন্যান্য ডেটাবেস থেকে আলাদা। একটি RDD-তে, ডেটা টেবিলে সংগঠিত হয় এবং নিয়ন্ত্রিত লেনদেনের মাধ্যমে সমস্ত ধরনের ডেটা অ্যাক্সেস করা হয়। রিলেশনাল ডাটাবেস ডিজাইন একটি ডাটাবেস ডিজাইন থেকে প্রয়োজনীয় ACID (পরমাণু, সামঞ্জস্য, অখণ্ডতা এবং স্থায়িত্ব) বৈশিষ্ট্যগুলিকে সন্তুষ্ট করে। রিলেশনাল ডাটাবেস ডিজাইন ডেটা ম্যানেজমেন্ট সমস্যা মোকাবেলা করার জন্য অ্যাপ্লিকেশনগুলিতে একটি ডাটাবেস সার্ভারের ব্যবহার বাধ্যতামূলক করে৷
রিলেশনাল ডাটাবেস ডিজাইন প্রক্রিয়া
ডেটাবেস ডিজাইন বিজ্ঞানের চেয়ে বেশি শিল্প, কারণ আপনাকে অনেক সিদ্ধান্ত নিতে হবে। ডেটাবেস সাধারণত একটি নির্দিষ্ট অ্যাপ্লিকেশন অনুসারে কাস্টমাইজ করা হয়। কোন দুটি কাস্টমাইজড অ্যাপ্লিকেশন একই নয়, এবং তাই, কোন দুটি ডাটাবেস একই রকম নয়। এই ডিজাইনের সিদ্ধান্ত নেওয়ার ক্ষেত্রে নির্দেশিকা (সাধারণত কী করা উচিত নয় তার পরিপ্রেক্ষিতে) প্রদান করা হয়, তবে পছন্দগুলি শেষ পর্যন্ত ডিজাইনারের উপর নির্ভর করে।
ধাপ 1 - ডেটাবেসের উদ্দেশ্য নির্ধারণ করুন (প্রয়োজনীয় বিশ্লেষণ)
- প্রয়োজনীয়তা সংগ্রহ করুন এবং আপনার ডাটাবেসের উদ্দেশ্য নির্ধারণ করুন।
- নমুনা ইনপুট ফর্ম, প্রশ্ন এবং রিপোর্টের খসড়া তৈরি করা প্রায়ই সাহায্য করে।
ধাপ 2 - ডেটা সংগ্রহ করুন, টেবিলে সংগঠিত করুন এবং প্রাথমিক কীগুলি নির্দিষ্ট করুন
- আপনি একবার ডাটাবেসের উদ্দেশ্য সম্পর্কে সিদ্ধান্ত নেওয়ার পরে, ডাটাবেসে সংরক্ষণ করার জন্য প্রয়োজনীয় ডেটা সংগ্রহ করুন। বিষয়-ভিত্তিক টেবিলে ডেটা ভাগ করুন।
- তথাকথিত প্রাথমিক কী হিসাবে একটি কলাম (বা কয়েকটি কলাম) চয়ন করুন, যা প্রতিটি সারিকে স্বতন্ত্রভাবে সনাক্ত করে৷
ধাপ 3 - টেবিলের মধ্যে সম্পর্ক তৈরি করুন
স্বাধীন এবং অসংলগ্ন সারণী সমন্বিত একটি ডাটাবেস সামান্য উদ্দেশ্য পূরণ করে (আপনি পরিবর্তে একটি স্প্রেডশীট ব্যবহার করার কথা বিবেচনা করতে পারেন)। একটি রিলেশনাল ডাটাবেসের শক্তি সেই সম্পর্কের মধ্যে রয়েছে যা টেবিলের মধ্যে সংজ্ঞায়িত করা যেতে পারে। একটি রিলেশনাল ডাটাবেস ডিজাইন করার সবচেয়ে গুরুত্বপূর্ণ দিক হল টেবিলের মধ্যে সম্পর্ক চিহ্নিত করা। সম্পর্কের প্রকারের মধ্যে রয়েছে:
- এক থেকে বহু
- অনেক-থেকে-অনেক
- ওয়ান টু ওয়ান
এক থেকে বহু
একটি "ক্লাস রোস্টার" ডাটাবেসে, একজন শিক্ষক শূন্য বা তার বেশি ক্লাস শেখাতে পারেন, যখন একটি ক্লাস একজন (এবং শুধুমাত্র একজন) শিক্ষক দ্বারা শেখানো হয়। একটি "কোম্পানী" ডাটাবেসে, একজন ম্যানেজার শূন্য বা তার বেশি কর্মচারী পরিচালনা করেন, যখন একজন কর্মচারী একজন (এবং শুধুমাত্র একজন) ব্যবস্থাপক দ্বারা পরিচালিত হয়। একটি "পণ্য বিক্রয়" ডাটাবেসে, একজন গ্রাহক অনেক অর্ডার দিতে পারে; যখন একটি নির্দিষ্ট গ্রাহক দ্বারা একটি অর্ডার স্থাপন করা হয়. এই ধরনের সম্পর্ক এক-থেকে-অনেক হিসাবে পরিচিত।
এক-থেকে-অনেক সম্পর্ককে একক টেবিলে উপস্থাপন করা যায় না। উদাহরণস্বরূপ, একটি "ক্লাস রোস্টার" ডাটাবেসে, আমরা শিক্ষক নামক একটি টেবিল দিয়ে শুরু করতে পারি, যা শিক্ষকদের সম্পর্কে তথ্য সংরক্ষণ করে (যেমন নাম, অফিস, ফোন এবং ইমেল)। প্রতিটি শিক্ষকের শেখানো ক্লাসগুলি সংরক্ষণ করার জন্য, আমরা ক্লাস 1, ক্লাস 2, ক্লাস 3 কলাম তৈরি করতে পারি, কিন্তু কতগুলি কলাম তৈরি করতে হবে তা নিয়ে অবিলম্বে একটি সমস্যার সম্মুখীন হয়। অন্যদিকে, যদি আমরা ক্লাস নামক একটি টেবিল দিয়ে শুরু করি, যা একটি ক্লাস সম্পর্কে তথ্য সঞ্চয় করে, আমরা (এক) শিক্ষক (যেমন নাম, অফিস, ফোন এবং ইমেল) সম্পর্কে তথ্য সংরক্ষণ করার জন্য অতিরিক্ত কলাম তৈরি করতে পারি। যাইহোক, যেহেতু একজন শিক্ষক অনেক ক্লাস পড়াতে পারেন, তাই এর ডেটা টেবিল ক্লাসে অনেক সারিতে ডুপ্লিকেট করা হবে।
এক থেকে একাধিক সম্পর্ককে সমর্থন করার জন্য, আমাদের দুটি টেবিল ডিজাইন করতে হবে:যেমন প্রাথমিক কী হিসাবে classID সহ ক্লাস সম্পর্কে তথ্য সংরক্ষণ করার জন্য একটি টেবিল ক্লাস; এবং একটি টেবিল শিক্ষক প্রাথমিক কী হিসাবে শিক্ষক আইডি সহ শিক্ষকদের সম্পর্কে তথ্য সংরক্ষণ করতে। তারপরে আমরা টেবিলের ক্লাসে ("অনেক"-এন্ড বা চাইল্ড টেবিল), নীচের চিত্রিত হিসাবে।
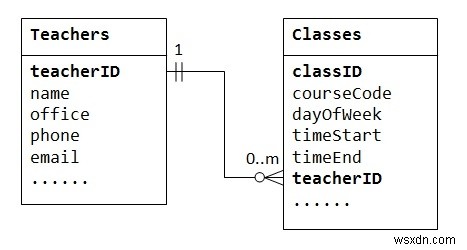 চাইল্ড টেবিল ক্লাসের কলাম টিচার আইডি বিদেশী কী নামে পরিচিত। একটি চাইল্ড টেবিলের একটি বিদেশী কী একটি প্যারেন্ট টেবিলের একটি প্রাথমিক কী, যা প্যারেন্ট টেবিলের উল্লেখ করতে ব্যবহৃত হয়।
চাইল্ড টেবিল ক্লাসের কলাম টিচার আইডি বিদেশী কী নামে পরিচিত। একটি চাইল্ড টেবিলের একটি বিদেশী কী একটি প্যারেন্ট টেবিলের একটি প্রাথমিক কী, যা প্যারেন্ট টেবিলের উল্লেখ করতে ব্যবহৃত হয়।
অনেক-থেকে-অনেক
একটি "পণ্য বিক্রয়" ডাটাবেসে, একজন গ্রাহকের অর্ডারে এক বা একাধিক পণ্য থাকতে পারে; এবং একটি পণ্য অনেক অর্ডার প্রদর্শিত হতে পারে. একটি "বইস্টোর" ডাটাবেসে, একটি বই এক বা একাধিক লেখক দ্বারা লিখিত হয়; যখন একজন লেখক শূন্য বা তার বেশি বই লিখতে পারেন। এই ধরনের সম্পর্ক বহু-থেকে-অনেক হিসাবে পরিচিত।
আসুন একটি "পণ্য বিক্রয়" ডাটাবেস দিয়ে চিত্রিত করি। আমরা দুটি টেবিল দিয়ে শুরু করি:পণ্য এবং অর্ডার। সারণী পণ্যগুলিতে প্রোডাক্ট আইডি এর প্রাথমিক কী হিসাবে পণ্যগুলির (যেমন নাম, বিবরণ এবং পরিমাণ ইনস্টক) সম্পর্কে তথ্য রয়েছে। টেবিলের অর্ডারগুলিতে গ্রাহকের অর্ডার থাকে (কাস্টমারআইডি, তারিখ অর্ডার করা, তারিখ প্রয়োজনীয় এবং স্থিতি)। আবার, আমরা অর্ডার টেবিলের ভিতরে অর্ডার করা আইটেমগুলি সংরক্ষণ করতে পারি না, কারণ আমরা জানি না আইটেমগুলির জন্য কতগুলি কলাম সংরক্ষণ করতে হবে। আমরা পণ্য টেবিলে অর্ডার তথ্য সংরক্ষণ করতে পারি না।
বহু-থেকে-অনেক সম্পর্ককে সমর্থন করার জন্য, আমাদের একটি তৃতীয় টেবিল (একটি জংশন টেবিল হিসাবে পরিচিত) তৈরি করতে হবে, বলুন OrderDetails (বা OrderLines), যেখানে প্রতিটি সারি একটি নির্দিষ্ট অর্ডারের একটি আইটেম উপস্থাপন করে। অর্ডার ডিটেইলস টেবিলের জন্য, প্রাথমিক কী দুটি কলাম নিয়ে গঠিত:অর্ডারআইডি এবং প্রোডাক্টআইডি, যা প্রতিটি সারিকে স্বতন্ত্রভাবে চিহ্নিত করে। অর্ডার ডিটেইলস টেবিলের কলাম অর্ডারআইডি এবং প্রোডাক্ট আইডি অর্ডার এবং প্রোডাক্ট টেবিলের রেফারেন্স করতে ব্যবহার করা হয়, তাই, অর্ডার ডিটেইলস টেবিলের বিদেশী কীও।
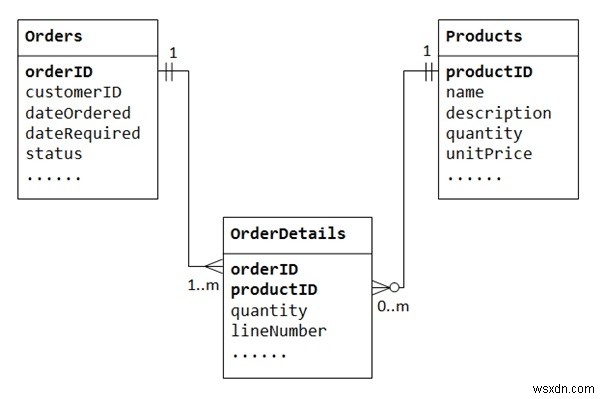
বহু-থেকে-অনেক সম্পর্ক, বাস্তবে, জংশন টেবিলের প্রবর্তনের সাথে দুটি এক-থেকে-অনেক সম্পর্ক হিসাবে বাস্তবায়িত হয়৷
একটি অর্ডারের অর্ডারের বিবরণে অনেক আইটেম থাকে। একটি অর্ডার ডিটেইলস আইটেম একটি নির্দিষ্ট অর্ডারের অন্তর্গত।
একটি পণ্য অনেক অর্ডারের বিবরণে প্রদর্শিত হতে পারে। প্রতিটি অর্ডার ডিটেইল আইটেম একটি পণ্য নির্দিষ্ট করে।
ওয়ান-টু-ওয়ান
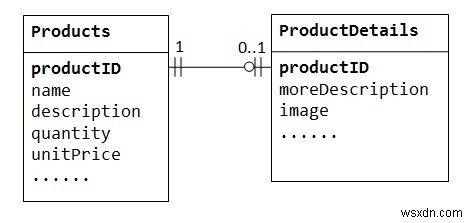
একটি "পণ্য বিক্রয়" ডাটাবেসে, একটি পণ্যের ঐচ্ছিক সম্পূরক তথ্য যেমন চিত্র, আরও বিবরণ এবং মন্তব্য থাকতে পারে। এগুলিকে পণ্য টেবিলের ভিতরে রাখার ফলে অনেকগুলি খালি জায়গা থাকে (এই ঐচ্ছিক ডেটা ছাড়াই সেই রেকর্ডগুলিতে)। উপরন্তু, এই বৃহৎ ডেটা ডাটাবেসের কর্মক্ষমতা হ্রাস করতে পারে।
পরিবর্তে, আমরা ঐচ্ছিক ডেটা সঞ্চয় করার জন্য অন্য একটি টেবিল (প্রোডাক্ট ডিটেল, প্রোডাক্টলাইন বা প্রোডাক্ট এক্সট্রাস বলুন) তৈরি করতে পারি। ঐচ্ছিক ডেটা সহ শুধুমাত্র সেই পণ্যগুলির জন্য একটি রেকর্ড তৈরি করা হবে৷ দুটি টেবিল, পণ্য এবং পণ্যের বিবরণ, এক-এক সম্পর্ক প্রদর্শন করে। অর্থাৎ, প্যারেন্ট টেবিলের প্রতিটি সারির জন্য, চাইল্ড টেবিলে সর্বাধিক একটি সারি (সম্ভবত শূন্য) থাকে। একই কলামের পণ্য ID উভয় টেবিলের জন্য প্রাথমিক কী হিসাবে ব্যবহার করা উচিত।
কিছু ডাটাবেস একটি টেবিলের ভিতরে তৈরি করা যেতে পারে এমন কলামের সংখ্যা সীমিত করে। ডেটা দুটি টেবিলে বিভক্ত করতে আপনি এক-এক সম্পর্ক ব্যবহার করতে পারেন। ওয়ান টু ওয়ান সম্পর্ক একটি সুরক্ষিত টেবিলে নির্দিষ্ট সংবেদনশীল ডেটা সংরক্ষণ করার জন্যও দরকারী, যখন অ-সংবেদনশীলগুলি মূল টেবিলে থাকে৷
কলাম ডেটা টাইপস
৷আপনাকে প্রতিটি কলামের জন্য একটি উপযুক্ত ডেটা টাইপ বেছে নিতে হবে। সাধারণত ডেটা প্রকারের মধ্যে পূর্ণসংখ্যা, ফ্লোটিং-পয়েন্ট সংখ্যা, স্ট্রিং (বা পাঠ্য), তারিখ/সময়, বাইনারি, সংগ্রহ (যেমন গণনা এবং সেট) অন্তর্ভুক্ত থাকে।
ধাপ 4 − ডিজাইনটিকে পরিমার্জিত ও স্বাভাবিক করুন
উদাহরণস্বরূপ,
- আরো কলাম যোগ করা হচ্ছে,
- ওয়ান-টু-ওয়ান সম্পর্ক ব্যবহার করে ঐচ্ছিক ডেটার জন্য একটি নতুন টেবিল তৈরি করুন,
- একটি বড় টেবিলকে দুটি ছোট টেবিলে ভাগ করুন,
- অন্যান্য পদ্ধতি।
সাধারণকরণ
আপনার ডাটাবেস কাঠামোগতভাবে সঠিক এবং সর্বোত্তম কিনা তা পরীক্ষা করতে তথাকথিত স্বাভাবিককরণের নিয়মগুলি প্রয়োগ করুন৷
প্রথম সাধারণ ফর্ম (1NF): একটি টেবিল 1NF হয় যদি প্রতিটি ঘরে একটি একক মান থাকে, মানের তালিকা নয়। এই সম্পত্তি পারমাণবিক হিসাবে পরিচিত. 1NF আইটেম1, আইটেম2, আইটেমএন-এর মতো কলামের পুনরাবৃত্তি করা গ্রুপকেও নিষিদ্ধ করে। পরিবর্তে, আপনাকে এক-থেকে-অনেক সম্পর্ক ব্যবহার করে অন্য টেবিল তৈরি করা উচিত।
দ্বিতীয় সাধারণ ফর্ম (2NF) - একটি টেবিল 2NF হয় যদি এটি 1NF হয় এবং প্রতিটি নন-কী কলাম প্রাথমিক কী-এর উপর সম্পূর্ণ নির্ভরশীল। তদ্ব্যতীত, যদি প্রাথমিক কীটি বেশ কয়েকটি কলাম দ্বারা গঠিত হয়, তবে প্রতিটি নন-কী কলাম সম্পূর্ণ সেটের উপর নির্ভর করবে এবং এর অংশ নয়।
উদাহরণস্বরূপ, অর্ডার আইডি এবং প্রোডাক্টআইডি সমন্বিত OrderDetails টেবিলের প্রাথমিক কী। ইউনিটপ্রাইস শুধুমাত্র প্রোডাক্ট আইডির উপর নির্ভরশীল হলে, এটি অর্ডার ডিটেইলস টেবিলে রাখা হবে না (কিন্তু প্রোডাক্ট টেবিলে)। অন্যদিকে, যদি ইউনিটের দাম পণ্যের পাশাপাশি নির্দিষ্ট অর্ডারের উপর নির্ভর করে, তাহলে তা অর্ডারের বিবরণ টেবিলে রাখা হবে।
তৃতীয় সাধারণ ফর্ম (3NF) - একটি টেবিল 3NF হয় যদি এটি 2NF হয় এবং নন-কী কলামগুলি একে অপরের থেকে স্বাধীন হয়। অন্য কথায়, নন-কী কলামগুলি প্রাথমিক কী-র উপর নির্ভরশীল, শুধুমাত্র প্রাথমিক কী-এর উপর এবং অন্য কিছু নয়। উদাহরণ স্বরূপ, ধরুন যে আমাদের কাছে কলাম প্রোডাক্ট আইডি (প্রাথমিক কী), নাম এবং ইউনিটপ্রাইস সহ একটি পণ্য টেবিল রয়েছে। কলাম ডিসকাউন্ট রেট পণ্য টেবিলের অন্তর্গত হবে না যদি এটি ইউনিটমূল্যের উপরও নির্ভর করে, যা প্রাথমিক কী-এর অংশ নয়৷
উচ্চতর সাধারণ ফর্ম:৷ 3NF এর অপর্যাপ্ততা রয়েছে, যা একটি উচ্চতর সাধারণ ফর্মের দিকে নিয়ে যায়, যেমন বয়েস/কড সাধারণ ফর্ম, চতুর্থ সাধারণ ফর্ম (4NF) এবং পঞ্চম সাধারণ ফর্ম (5NF), যা এই টিউটোরিয়ালের সুযোগের বাইরে৷
কখনও কখনও, আপনি কার্যক্ষমতার কারণে কিছু স্বাভাবিককরণের নিয়ম ভঙ্গ করার সিদ্ধান্ত নিতে পারেন (যেমন, অর্ডার টেবিলে টোটাল প্রাইস নামে একটি কলাম তৈরি করুন যা অর্ডারের বিবরণ রেকর্ড থেকে নেওয়া যেতে পারে); অথবা কারণ শেষ-ব্যবহারকারী এটির জন্য অনুরোধ করেছে। নিশ্চিত করুন যে আপনি এটি সম্পর্কে সম্পূর্ণ অবগত আছেন, এটি পরিচালনা করার জন্য প্রোগ্রামিং যুক্তি বিকাশ করুন এবং সিদ্ধান্তটি সঠিকভাবে নথিভুক্ত করুন৷
সততার নিয়ম
আপনার ডিজাইনের অখণ্ডতা পরীক্ষা করার জন্য আপনার সততা নিয়মও প্রয়োগ করা উচিত −
1. সত্তা অখণ্ডতার নিয়ম - প্রাথমিক কীতে NULL থাকতে পারে না। অন্যথায়, এটি সারিটিকে স্বতন্ত্রভাবে সনাক্ত করতে পারে না। বিভিন্ন কলামের সমন্বয়ে গঠিত যৌগিক কী-এর জন্য, কোনো কলামে NULL থাকতে পারে না। বেশিরভাগ RDBMS এই নিয়মটি পরীক্ষা করে এবং প্রয়োগ করে।
2. রেফারেন্সিয়াল ইন্টিগ্রিটি নিয়ম - প্রতিটি বিদেশী কী মান অবশ্যই রেফারেন্স করা সারণীতে একটি প্রাথমিক কী মানের সাথে মিলতে হবে (বা প্যারেন্ট টেবিল)।
আপনি চাইল্ড টেবিলে একটি বিদেশী কী দিয়ে একটি সারি সন্নিবেশ করতে পারেন শুধুমাত্র যদি প্যারেন্ট টেবিলে মানটি বিদ্যমান থাকে৷
যদি মূল সারণীতে কী-এর মান পরিবর্তন হয় (যেমন, সারিটি আপডেট করা বা মুছে ফেলা হয়েছে), চাইল্ড টেবিল(গুলি) এর এই বিদেশী কী সহ সমস্ত সারি অবশ্যই সেই অনুযায়ী পরিচালনা করতে হবে৷ আপনি হয় (ক) পরিবর্তনগুলিকে অস্বীকার করতে পারেন; (খ) সেই অনুযায়ী চাইল্ড টেবিলে পরিবর্তন ক্যাসকেড করুন (বা রেকর্ড মুছে দিন) (c) চাইল্ড টেবিলের মূল মানটি NULL এ সেট করুন।
অধিকাংশ RDBMS একটি নির্দিষ্ট পদ্ধতিতে চেক সম্পাদন এবং রেফারেন্সিয়াল অখণ্ডতা নিশ্চিত করার জন্য সেট আপ করা যেতে পারে।
3. ব্যবসায়িক যুক্তি সততা - উপরোক্ত দুটি সাধারণ অখণ্ডতা বিধি ছাড়াও, ব্যবসায়িক যুক্তির সাথে সম্পর্কিত অখণ্ডতা (বৈধতা) থাকতে পারে, যেমন, জিপ কোড একটি নির্দিষ্ট সীমার মধ্যে 5-সংখ্যার হবে, বিতরণের তারিখ এবং সময় ব্যবসায়িক সময়ের মধ্যে পড়বে; অর্ডারকৃত পরিমাণ স্টকের পরিমাণের সমান বা কম হতে হবে, ইত্যাদি। এগুলি অবৈধকরণের নিয়ম (নির্দিষ্ট কলামের জন্য) বা প্রোগ্রামিং লজিক বাহিত হতে পারে।
কলাম ইন্ডেক্সিং
আপনি ডেটা অনুসন্ধান এবং পুনরুদ্ধারের সুবিধার্থে নির্বাচিত কলাম(গুলি) তে একটি সূচক তৈরি করতে পারেন৷ একটি সূচী একটি স্ট্রাকচার্ড ফাইল যা SELECT এর জন্য ডেটা অ্যাক্সেসের গতি বাড়ায় কিন্তু INSERT, UPDATE এবং DELETE এর গতি কমিয়ে দিতে পারে। একটি সূচী কাঠামো ছাড়াই, একটি মানদণ্ডের সাথে একটি নির্বাচন প্রশ্ন প্রক্রিয়া করতে (যেমন, SELECT * FROM Customers WHERE name='Tan Ah Teck'), ডাটাবেস ইঞ্জিনকে টেবিলের প্রতিটি রেকর্ডের তুলনা করতে হবে। একটি বিশেষ সূচক (যেমন, BTREE কাঠামোতে) প্রতিটি রেকর্ডের তুলনা না করেই রেকর্ডে পৌঁছাতে পারে। যাইহোক, যখনই একটি রেকর্ড পরিবর্তন করা হয় তখনই সূচকটি পুনর্নির্মাণ করা প্রয়োজন, যার ফলে সূচী ব্যবহারের সাথে ওভারহেড যুক্ত হয়।
সূচীটি একটি একক কলামে, কলামের একটি সেট (কনক্যাটেনেটেড ইনডেক্স বলা হয়), বা একটি কলামের অংশে (যেমন, VARCHAR(100) এর প্রথম 10টি অক্ষর) (যাকে আংশিক সূচক বলা হয়) সংজ্ঞায়িত করা যেতে পারে . আপনি একটি টেবিলে একাধিক সূচক তৈরি করতে পারেন। উদাহরণস্বরূপ, যদি আপনি প্রায়ই গ্রাহকের নাম বা ফোন নম্বর ব্যবহার করে একজন গ্রাহকের জন্য অনুসন্ধান করেন, তাহলে আপনি কলাম গ্রাহকের নাম, সেইসাথে ফোন নম্বরে একটি সূচক তৈরি করে অনুসন্ধানের গতি বাড়াতে পারেন। বেশিরভাগ RDBMS প্রাথমিক কীতে স্বয়ংক্রিয়ভাবে একটি সূচক তৈরি করে।
