
এই পোস্টটি আমার মতে, বিশ্বের সবচেয়ে উত্তেজনাপূর্ণ দুটি জিনিস কী তা নিয়ে:সম্ভাব্য ডেটা স্ট্রাকচার এবং রেডিস মডিউল। আপনি যদি একটি বা অন্যটি সম্পর্কে শুনে থাকেন তবে আপনি অবশ্যই আমার উত্সাহের সাথে সম্পর্কিত হতে পারেন, তবে আপনি যদি পৃথিবীর সবচেয়ে দুর্দান্ত জিনিসগুলি পেতে চান তবে কেবল পড়া চালিয়ে যান।
আমি এই বিবৃতি দিয়ে শুরু করব:বৃহৎ আকারের নিম্ন-বিলম্বিত ডেটা প্রক্রিয়াকরণ চ্যালেঞ্জিং। জড়িত ডেটার ভলিউম এবং বেগ রিয়েল-টাইম বিশ্লেষণকে অত্যন্ত চাহিদাপূর্ণ করে তুলতে পারে। এর উচ্চ কর্মক্ষমতা এবং বহুমুখীতার কারণে, রেডিস সাধারণত এই ধরনের চ্যালেঞ্জগুলি সমাধান করতে ব্যবহৃত হয়। সাব-মিলিসেকেন্ড লেটেন্সিতে একাধিক ধরণের ডেটা সঞ্চয়, ম্যানিপুলেট এবং পরিবেশন করার ক্ষমতা এটিকে অনেক ক্ষেত্রে যেখানে অনলাইন গণনার প্রয়োজন হয় সেই ক্ষেত্রে এটিকে আদর্শ ডেটা ধারক করে তোলে৷
কিন্তু সবকিছুই আপেক্ষিক, এবং স্কেলগুলি এতটাই চরম যে তারা সঠিক রিয়েল-টাইম বিশ্লেষণকে ব্যবহারিক অসম্ভব করে তোলে। জটিল সমস্যাগুলি বড় হওয়ার সাথে সাথে আরও কঠিন হয়ে ওঠে, কিন্তু আমরা ভুলে যাই যে সাধারণ সমস্যাগুলি একই নিয়ম অনুসরণ করে। এমনকি যখন ডেটা খুব বড়, খুব দ্রুত বা যখন আমাদের কাছে এটি প্রক্রিয়া করার জন্য পর্যাপ্ত সংস্থান না থাকে তখন সংখ্যার যোগফলের মতো মৌলিক কিছু একটি গুরুত্বপূর্ণ কাজ হয়ে উঠতে পারে। এবং সম্পদগুলি সর্বদা সীমিত এবং ব্যয়বহুল হলেও, ডেটা ক্রমাগত কারও ব্যবসার মতো বাড়ছে।
কাউন্ট-মিন স্কেচ কি?
কাউন্ট-মিন স্কেচ (এছাড়াও সিএম স্কেচ বলা হয়) হল একটি সম্ভাব্য ডেটা স্ট্রাকচার যেটি কীভাবে কাজ করে এবং আরও গুরুত্বপূর্ণভাবে, এটি কীভাবে ব্যবহার করতে হয় তা উপলব্ধি করার পরে অত্যন্ত কার্যকর।
সৌভাগ্যবশত, সিএম স্কেচের সাধারণ বৈশিষ্ট্যগুলি নতুনদের জন্য তুলনামূলকভাবে সহজ করে বোঝায় (দেখা যাচ্ছে যে আমার অনেক বন্ধু এই টপ-কে ব্লগটি অনুসরণ করতে অক্ষম ছিল)।
CM স্কেচ বেশ কয়েক বছর ধরে একটি Redis মডিউল এবং সম্প্রতি RedisBloom মডিউল v2.0-এর অংশ হিসেবে পুনরায় লেখা হয়েছে। কিন্তু আমরা CM স্কেচে ডুব দেওয়ার আগে, আপনি কেন যেকোনও ব্যবহার করবেন তা বোঝা গুরুত্বপূর্ণ সম্ভাব্য তথ্য কাঠামো। গতি, স্থান এবং নির্ভুলতার ত্রিভুজে, সম্ভাব্য ডেটা স্ট্রাকচার স্থান অর্জনের জন্য কিছু নির্ভুলতাকে উৎসর্গ করে—সম্ভাব্য অনেক স্থান ! অ্যালগরিদম এবং সেট আকারের উপর ভিত্তি করে গতির উপর প্রভাব পরিবর্তিত হয়।
- নির্ভুলতা :সংজ্ঞা অনুসারে, আপনার ডেটার শুধুমাত্র অংশ রাখা এবং সঞ্চয়স্থানে সংঘর্ষের অনুমতি দেওয়া সঠিকতা হ্রাস করে। তবুও আপনি আপনার ব্যবহারের ক্ষেত্রের উপর ভিত্তি করে সর্বাধিক ত্রুটির হার সেট করতে পারেন।
- মেমরি স্পেস :বড় ডেটার বিশ্বে যেখানে বিলিয়ন ইভেন্ট রেকর্ড করা হয়, শুধুমাত্র আংশিক ডেটা সঞ্চয় করা স্টোরেজ স্পেস প্রয়োজনীয়তা এবং খরচ কমাতে পারে৷
- গতি :কিছু প্রথাগত ডেটা স্ট্রাকচার তুলনামূলকভাবে অদক্ষভাবে কাজ করে, প্রতিক্রিয়ার সময় ধীর করে। (উদাহরণস্বরূপ, একটি সাজানো সেট এটির সমস্ত উপাদানের ক্রম বজায় রাখে, তবে আপনি শুধুমাত্র শীর্ষ উপাদানগুলিতে আগ্রহী হতে পারেন৷ কারণ সম্ভাব্য অ্যালগরিদমগুলি শুধুমাত্র একটি আংশিক তালিকা বজায় রাখে, তারা আরও দক্ষ এবং প্রায়শই অনেক দ্রুত প্রশ্নের উত্তর দিতে পারে৷
সঠিক সম্ভাব্য ডেটা স্ট্রাকচার আপনাকে কম নির্ভুলতার বিনিময়ে আপনার ডেটাসেটে তথ্যের একটি অংশ রাখতে দেয়। অবশ্যই, অনেক ক্ষেত্রে (ব্যাংক অ্যাকাউন্ট, উদাহরণস্বরূপ), হ্রাস সঠিকতা অগ্রহণযোগ্য। কিন্তু ওয়েবসাইট ব্যবহারকারীদের কাছে সিনেমার সুপারিশ বা বিজ্ঞাপন দেখানোর জন্য, তুলনামূলকভাবে বিরল ভুলের খরচ কম এবং স্থান সঞ্চয় যথেষ্ট হতে পারে।
মূলত, CM স্কেচ আপনার ডেটাসেটের সমস্ত আইটেমের গণনাকে কয়েকটি কাউন্টার অ্যারেতে একত্রিত করে কাজ করে। একটি প্রশ্নে, এটি সমস্ত অ্যারের আইটেমের ন্যূনতম গণনা ফেরত দেয়, যা সংঘর্ষের ফলে সৃষ্ট কাউন্ট মুদ্রাস্ফীতি কমানোর প্রতিশ্রুতি দেয়। কম উপস্থিতির হার বা স্কোর ("মাউস ফ্লো") সহ আইটেমগুলির সংখ্যা ত্রুটির হারের নীচে রয়েছে , তাই আপনি তাদের প্রকৃত গণনা সম্পর্কে কোনো ডেটা হারাবেন এবং সেগুলি গোলমাল হিসাবে বিবেচিত হবে। একটি উচ্চ উপস্থিতি হার বা স্কোর সহ আইটেমগুলির জন্য ("হাতি প্রবাহ"), কেবল প্রাপ্ত গণনা ব্যবহার করুন। সিএম স্কেচের আকার ধ্রুবক এবং এটি অসীম সংখ্যক আইটেমের জন্য ব্যবহার করা যেতে পারে বিবেচনা করে, আপনি স্টোরেজ স্পেসে বিশাল সঞ্চয়ের সম্ভাবনা দেখতে পারেন৷
ব্যাকগ্রাউন্ডের জন্য, স্কেচ হল ডেটা স্ট্রাকচারের একটি শ্রেণী এবং তাদের সাথে থাকা অ্যালগরিদম। ধ্রুবক বা সাবলাইনার স্পেস ব্যবহার করার সময় এটি সম্পর্কে প্রশ্নের উত্তর দেওয়ার জন্য তারা আপনার ডেটার প্রকৃতি ক্যাপচার করে। 2005 সালের “ নামে একটি গবেষণাপত্রে গ্রাহাম কর্মোড এবং এস. মুথু মুথুকৃষ্ণান দ্বারা সিএম স্কেচ বর্ণনা করা হয়েছিল একটি উন্নত ডেটা স্ট্রীমের সারাংশ:কাউন্ট-মিন স্কেচ এবং এর প্রয়োগগুলি।"
কাউন্ট-মিন স্কেচ:কি এবং কিভাবে
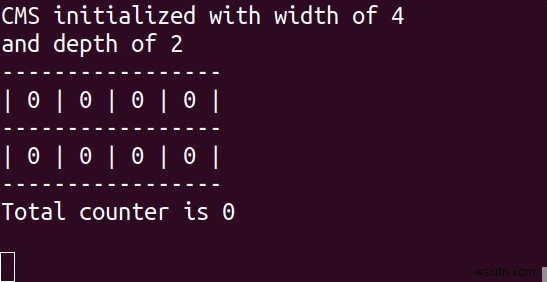
CM স্কেচ এর প্রাথমিক ব্যবহারের ক্ষেত্রে সমর্থন করার জন্য কাউন্টারের বিভিন্ন অ্যারে ব্যবহার করে। আসুন অ্যারের সংখ্যাকে "গভীরতা" এবং প্রতিটি অ্যারের কাউন্টারের সংখ্যাকে "প্রস্থ" বলি৷
যখনই আমরা একটি আইটেম পাই, আমরা একটি হ্যাশ ফাংশন ব্যবহার করি (যা একটি উপাদানকে পরিণত করে—একটি শব্দ, বাক্য, সংখ্যা, বা বাইনারি—এমন একটি সংখ্যায় যা সেট/অ্যারেতে অবস্থান হিসাবে বা ফিঙ্গারপ্রিন্ট হিসাবে ব্যবহার করা যেতে পারে) আইটেমের অবস্থান এবং প্রতিটি অ্যারের জন্য কাউন্টার বাড়ান। সংশ্লিষ্ট কাউন্টারগুলির প্রতিটি আইটেমের প্রকৃত মূল্যের সমান বা তার চেয়ে বেশি একটি মান রয়েছে৷ যখন আমরা একটি অনুসন্ধান করি, তখন আমরা একই হ্যাশ ফাংশন সহ সমস্ত অ্যারের মাধ্যমে যাই এবং আমাদের আইটেমের সাথে যুক্ত কাউন্টারটি নিয়ে আসি। তারপরে আমরা যে ন্যূনতম মানটির সম্মুখীন হয়েছি তা ফেরত দিই কারণ আমরা জানি আমাদের মানগুলি স্ফীত (বা সমান)।
যদিও আমরা জানি যে অনেকগুলি আইটেম বেশিরভাগ কাউন্টারে অবদান রাখে, প্রাকৃতিক সংঘর্ষের কারণে (যখন বিভিন্ন আইটেম একই অবস্থান পায়), আমরা 'শব্দ' গ্রহণ করি যতক্ষণ না এটি আমাদের কাঙ্ক্ষিত ত্রুটির হারের মধ্যে থাকে।
কাউন্ট-মিন স্কেচ উদাহরণ
গণিত নির্দেশ করে যে 10 এর গভীরতা এবং 2,000 এর প্রস্থের সাথে, ত্রুটি না হওয়ার সম্ভাবনা 99.9% এবং ত্রুটির হার 0.1%। (এটি মোট বৃদ্ধির শতাংশ, অনন্য আইটেম নয়)।
বাস্তব সংখ্যায়, এর মানে আপনি যদি 1 মিলিয়ন অনন্য আইটেম যোগ করেন, গড়ে প্রতিটি আইটেম 500 (1M/2K) এর মান পাবেন। যদিও এটি অসামঞ্জস্যপূর্ণ বলে মনে হয়, এটি আমাদের ত্রুটির হার 0.1% এর মধ্যে পড়ে, যা 1 মিলিয়ন আইটেমের জন্য 1,000।
একইভাবে, যদি 10টি হাতি প্রতিটি 10,000 বার দেখা যায়, তবে সমস্ত সেটে তাদের মান 10,000 বা তার বেশি হবে। ভবিষ্যতে যখনই আমরা তাদের গণনা করব, আমরা আমাদের সামনে একটি হাতি দেখতে পাব। অন্যান্য সমস্ত সংখ্যার জন্য (অর্থাৎ, সমস্ত ইঁদুর যাদের প্রকৃত সংখ্যা 1), তাদের সমস্ত সেটে একটি হাতির সাথে সংঘর্ষের সম্ভাবনা নেই (যেহেতু সিএম স্কেচ কেবলমাত্র সর্বনিম্ন গণনা বিবেচনা করে) কারণ এটি হওয়ার সম্ভাবনা কম এবং আরও হ্রাস পায় যদি আপনি আপনি CM স্কেচ শুরু করার সাথে সাথে গভীরতা বাড়ান।
কাউন্ট-মিন স্কেচ কিসের জন্য ভালো?
এখন আমরা সিএম স্কেচের আচরণ বুঝতে পেরেছি, এই ছোট্ট জানোয়ারের সাথে আমরা কী করতে পারি? এখানে কিছু সাধারণ ব্যবহারের ক্ষেত্রে রয়েছে:
- দুটি সংখ্যা জিজ্ঞাসা করুন এবং তাদের সংখ্যা তুলনা করুন।
- আগত আইটেমগুলির একটি শতাংশ সেট করুন, ধরা যাক 1%। যখনই একটি আইটেমের সর্বনিম্ন-গণনা মোট গণনার 1%-এর বেশি হয়, আমরা সত্যে ফিরে আসি। এটি একটি অনলাইন গেমের শীর্ষ প্লেয়ার নির্ধারণ করতে ব্যবহার করা যেতে পারে, উদাহরণস্বরূপ।
- CM স্কেচে একটি মিন-হিপ যোগ করুন এবং একটি Top-K ডেটা স্ট্রাকচার তৈরি করুন। যখনই আমরা একটি আইটেম বাড়াই, আমরা নতুন মিন-কাউন্ট হিপে ন্যূনতম থেকে বেশি কিনা তা পরীক্ষা করি এবং সেই অনুযায়ী আপডেট করি। RedisBloom-এর Top-K মডিউলের বিপরীতে, যা সময়ের সাথে ধীরে ধীরে ক্ষয়প্রাপ্ত হয়, CM স্কেচ কখনও ভুলে যায় না এবং তাই এর আচরণ HeavyKeeper থেকে কিছুটা আলাদা। -ভিত্তিক টপ-কে।
RedisBloom-এ, CM স্কেচের জন্য API সহজ এবং সহজ:
- একটি CM স্কেচ ডেটা স্ট্রাকচার শুরু করতে:INITBYDIM {কী } {প্রস্থ } {গভীরতা অথবা CMS.INITBYPROB {কী } {ত্রুটি } {সম্ভাব্যতা
- একটি আইটেমের কাউন্টার বাড়ানোর জন্য:CMS.INCRBY {কী } {আইটেম } {বৃদ্ধি
- আইটেমের কাউন্টারে পাওয়া ন্যূনতম গণনা পেতে:CMS.QUERY {কী } {আইটেম }
এই পোস্টের শীর্ষে অ্যানিমেটেড উদাহরণ তৈরি করতে নিম্নলিখিত কমান্ডগুলি ব্যবহার করা হয়েছিল:
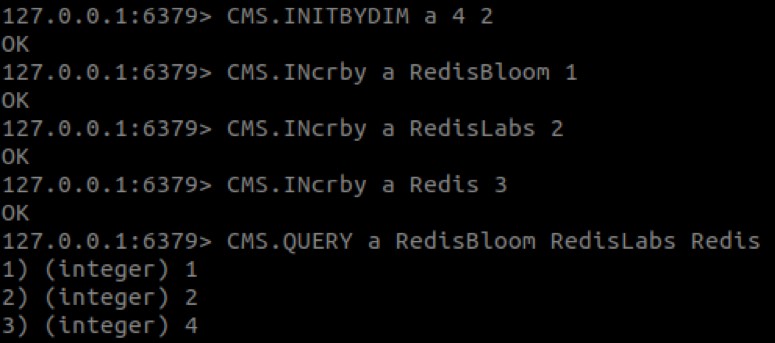
আপনি দেখতে পাচ্ছেন, 'Redis'-এর মান 3 এর পরিবর্তে 4। এই আচরণটি প্রত্যাশিত যেহেতু, CM স্কেচে, একটি আইটেমের গণনা স্ফীত হওয়ার সম্ভাবনা রয়েছে।
একটি স্কেচি ব্যবসা
সফ্টওয়্যার ইঞ্জিনিয়ারিং হল ট্রেড-অফ তৈরি করা এবং এই ধরনের চ্যালেঞ্জ মোকাবেলা করার জন্য একটি জনপ্রিয় পদ্ধতি হল দক্ষতার পক্ষে নির্ভুলতা ত্যাগ করা। এই পদ্ধতির উদাহরণ হল Redis-এর HyperLogLog-এর বাস্তবায়নের মাধ্যমে, একটি ডেটা স্ট্রাকচার যা সেট কার্ডিনালিটি সম্পর্কে প্রশ্নের উত্তর প্রদান করার জন্য ডিজাইন করা হয়েছে। HyperLogLog হল "স্কেচ" নামে পরিচিত ডেটা স্ট্রাকচারের একটি পরিবারের সদস্য যা, তাদের বাস্তব-বিশ্বের শৈল্পিক সমকক্ষদের মতোই, তাদের বিষয়ের আনুমানিকতার মাধ্যমে তথ্য প্রকাশ করে৷
বিস্তৃত স্ট্রোকে, স্কেচগুলি হল ডেটা স্ট্রাকচার (এবং তাদের সাথে থাকা অ্যালগরিদমগুলি) যা আপনার ডেটার প্রকৃতি ক্যাপচার করে — ডেটা সম্পর্কে আপনার প্রশ্নের উত্তর, আসলে ডেটা নিজেই সংরক্ষণ না করে। আনুষ্ঠানিকভাবে বলা হয়েছে, স্কেচগুলি দরকারী কারণ তাদের সাবলাইনার অ্যাসিম্পটোটিক কম্পিউটেশনাল জটিলতা রয়েছে, এইভাবে কম কম্পিউটিং শক্তি এবং/অথবা স্টোরেজ প্রয়োজন। কিন্তু কোন বিনামূল্যের মধ্যাহ্নভোজ নেই এবং দক্ষতা বৃদ্ধি উত্তরের নির্ভুলতার দ্বারা অফসেট করা হয়। অনেক ক্ষেত্রে, যদিও, ত্রুটিগুলি গ্রহণযোগ্য হয় যতক্ষণ না সেগুলিকে একটি থ্রেশহোল্ডের মধ্যে রাখা যায়। একটি ভাল ডেটা স্কেচ হল এমন একটি যা সহজেই তার ত্রুটিগুলি স্বীকার করে এবং প্রকৃতপক্ষে, অনেক স্কেচ তাদের ত্রুটিগুলি (বা বলা ত্রুটির সম্ভাবনা) প্যারামিটারাইজ করে যাতে ব্যবহারকারীর দ্বারা সংজ্ঞায়িত করা যায়৷
ভাল স্কেচগুলি দক্ষ এবং ত্রুটির আবদ্ধ সম্ভাবনা থাকে, তবে চমৎকার স্কেচগুলি সেইগুলি যা সমান্তরালভাবে গণনা করা যায়। একটি সমান্তরাল স্কেচ এমন একটি যা ডেটার অংশগুলিতে স্বাধীনভাবে প্রস্তুত করা যেতে পারে এবং এটি এর অংশগুলিকে একটি অর্থপূর্ণ এবং সামঞ্জস্যপূর্ণ সমষ্টিতে একত্রিত করার অনুমতি দেয়। যেহেতু একটি চমৎকার স্কেচের প্রতিটি অংশ একটি ভিন্ন অবস্থান এবং/অথবা সময়ে গণনা করা যেতে পারে, সমান্তরালতা স্কেলিং চ্যালেঞ্জগুলি সমাধানের জন্য একটি সরল বিভাজন-এবং-জয় পদ্ধতি প্রয়োগ করা সম্ভব করে।
একটি ঘন ঘন সমস্যা
উপরে উল্লিখিত HyperLogLog একটি চমৎকার স্কেচ কিন্তু এটি শুধুমাত্র একটি নির্দিষ্ট ধরনের প্রশ্নের উত্তর দেওয়ার জন্য উপযুক্ত। আরেকটি অমূল্য হাতিয়ার হল Count Min Sketch (CMS), যেমনটি G. Cormode এবং S. Muthukrishnan দ্বারা “An Improved Data Stream Summary:The Count-min Sketch and Its Applications”-এ বর্ণনা করা হয়েছে। নমুনার ফ্রিকোয়েন্সি সম্পর্কে উত্তর দেওয়ার জন্য এই বুদ্ধিমান কনট্রাপশনটি তৈরি করা হয়েছিল, যা বিশ্লেষণাত্মক প্রক্রিয়াগুলির একটি বড় শতাংশে একটি সাধারণ বিল্ডিং ব্লক।
পর্যাপ্ত সময় এবং সংস্থান দেওয়া, নমুনার ফ্রিকোয়েন্সি গণনা করা একটি সহজ প্রক্রিয়া - প্রতিটি নমুনার (যে জিনিসটি দেখা হয়েছে) জন্য শুধুমাত্র পর্যবেক্ষণের একটি গণনা (বার দেখা হয়েছে) রাখুন এবং তারপর সেই নমুনার ফ্রিকোয়েন্সি পেতে মোট পর্যবেক্ষণের সংখ্যা দিয়ে ভাগ করুন। যাইহোক, উচ্চ-স্কেল লো-লেটেন্সি ডেটা প্রক্রিয়াকরণের প্রেক্ষাপটে, পর্যাপ্ত সময় বা সংস্থান নেই। স্কেল নির্বিশেষে ডেটা স্ট্রিম করার সাথে সাথে উত্তরগুলি তাৎক্ষণিকভাবে সরবরাহ করা হয় এবং নমুনা স্থানের নিছক আকার প্রতিটি নমুনার জন্য একটি কাউন্টার রাখা অসম্ভব করে তোলে৷
তাই প্রতিটি নমুনার সঠিকভাবে ট্র্যাক রাখার পরিবর্তে, আমরা ফ্রিকোয়েন্সি অনুমান করার চেষ্টা করতে পারি। এটি সম্পর্কে যাওয়ার একটি উপায় হ'ল এলোমেলোভাবে পর্যবেক্ষণগুলিকে নমুনা করা এবং আশা করি যে নমুনাটি সাধারণত পুরো বৈশিষ্ট্যগুলিকে প্রতিফলিত করে। এই পদ্ধতির সমস্যা হল যে সত্যিকারের এলোমেলোতা নিশ্চিত করা একটি কঠিন কাজ, তাই র্যান্ডম স্যাম্পলিংয়ের সাফল্য আমাদের নির্বাচন প্রক্রিয়া এবং/অথবা ডেটার নিজস্ব বৈশিষ্ট্য দ্বারা সীমিত হতে পারে। সেখানেই CMS এমন একটি পদ্ধতির সাথে আসে যা এতটাই ভিন্ন, যে প্রথমে এটি একটি চমৎকার স্কেচের বিপরীত বলে মনে হতে পারে:CMS শুধুমাত্র প্রতিটি পর্যবেক্ষণই রেকর্ড করে না, প্রতিটি একাধিক কাউন্টারে রেকর্ড করা হয়!
অবশ্যই, একটি মোচড় আছে, এবং এটি সহজ হিসাবে চতুর। আসল কাগজটি (এবং এর হালকা সংস্করণ "কাউন্ট-মিন ডেটা স্ট্রাকচারের সাথে আনুমানিক ডেটা" নামে পরিচিত) এটি ব্যাখ্যা করার জন্য একটি দুর্দান্ত কাজ করে, তবে আমি যাইহোক এটিকে সংক্ষিপ্ত করার চেষ্টা করব। CMS এর চতুরতা হল যেভাবে এটি নমুনা সংরক্ষণ করে:প্রতিটি অনন্য নমুনা স্বাধীনভাবে ট্র্যাক করার পরিবর্তে, এটি তার হ্যাশ মান ব্যবহার করে। একটি নমুনার হ্যাশ মান কাউন্টারগুলির একটি ধ্রুবক আকারের (কাগজে d হিসাবে প্যারামিটারাইজড) সূচক হিসাবে ব্যবহৃত হয়। বেশ কয়েকটি (প্যারামিটার w) বিভিন্ন হ্যাশ ফাংশন এবং তাদের নিজ নিজ অ্যারে নিয়োগ করে, স্কেচটি নমুনার জন্য সমস্ত প্রাসঙ্গিক কাউন্টার থেকে ন্যূনতম মান বাছাই করে কাঠামোটি জিজ্ঞাসা করার সময় পাওয়া হ্যাশ সংঘর্ষগুলি পরিচালনা করে৷
একটি উদাহরণের জন্য বলা হয়েছে, তাই আসুন ডেটা কাঠামোর অভ্যন্তরীণ কাজগুলিকে চিত্রিত করার জন্য একটি সাধারণ স্কেচ তৈরি করি। স্কেচ সহজ রাখতে, আমরা ছোট প্যারামিটার মান ব্যবহার করব। আমরা w সেট করব 3, অর্থাৎ আমরা তিনটি হ্যাশ ফাংশন ব্যবহার করব - যথাক্রমে h1, h2 এবং h3 এবং d থেকে 4। স্কেচের কাউন্টারগুলি সংরক্ষণ করতে আমরা মোট 12 সহ একটি 3×4 অ্যারে ব্যবহার করব। উপাদানগুলি 0-তে আরম্ভ করা হয়েছে।
এখন আমরা পরীক্ষা করতে পারি যখন স্কেচে নমুনা যোগ করা হয় তখন কী ঘটে। ধরা যাক একের পর এক নমুনা আসে এবং প্রথম নমুনার হ্যাশগুলি, s1 হিসাবে চিহ্নিত, হল:h1(s1) =1, h2(s1) =2 এবং h3(s1) =3। স্কেচে s1 রেকর্ড করতে আমরা প্রাসঙ্গিক সূচকে প্রতিটি হ্যাশ ফাংশনের কাউন্টারকে 1 দ্বারা বৃদ্ধি করবে। নিম্নলিখিত টেবিলটি অ্যারের প্রাথমিক এবং বর্তমান অবস্থা দেখায়:

যদিও স্কেচে শুধুমাত্র একটি নমুনা আছে, আমরা ইতিমধ্যে এটি কার্যকরভাবে অনুসন্ধান করতে পারি। মনে রাখবেন যে একটি নমুনার জন্য পর্যবেক্ষণের সংখ্যা হল তার সমস্ত কাউন্টারের সর্বনিম্ন, তাই s1 এর জন্য এটি প্রাপ্ত হয়:
min(array[1][h1(s1)], array[2][h2(s1)], array[3][h3(s1)]) = স্কেচটি এখনও যোগ করা হয়নি এমন নমুনাগুলি সম্পর্কে প্রশ্নের উত্তর দেয়। ধরে নেওয়া হচ্ছে h1 (s2 ) =4, h2 (s2 ) =4, h3 (s2 ) =4, মনে রাখবেন যে s2-এর জন্য প্রশ্ন করা হচ্ছে ফলাফল 0 প্রদান করবে। আসুন s2 যোগ করা চালিয়ে যাই এবং s3 (h1 (s3 ) =1, h2 (s3 ) =1, h3 (s3 ) =1) স্কেচ করতে, নিম্নলিখিতগুলি প্রদান করে:
min(array[1][1], array[2][2], array[3][3]) =
min(1,1,1) = 1

আমাদের কল্পিত উদাহরণে, প্রায় সমস্ত নমুনার হ্যাশগুলি অনন্য কাউন্টারে ম্যাপ করে, একটি ব্যতিক্রম হল h1(s1) এবং h1(s3) এর সংঘর্ষ। যেহেতু উভয় হ্যাশ একই, h1 এর 1ম কাউন্টারে এখন 2 মান রয়েছে। যেহেতু স্কেচটি সমস্ত কাউন্টারের ন্যূনতম বাছাই করে, তাই s1 এবং s3-এর জন্য প্রশ্নগুলি এখনও 1-এর সঠিক ফলাফল প্রদান করে। অবশেষে, যাইহোক, একবার পর্যাপ্ত সংঘর্ষ হলে ঘটেছে, প্রশ্নের ফলাফল কম নির্ভুল হবে।
CMS-এর দুটি প্যারামিটার - w এবং d - এর স্থান/সময়ের প্রয়োজনীয়তার পাশাপাশি এর ত্রুটির সম্ভাব্যতা এবং সর্বাধিক মান নির্ধারণ করে। স্কেচ আরম্ভ করার একটি আরও স্বজ্ঞাত উপায় হল ত্রুটির সম্ভাব্যতা এবং ক্যাপ প্রদান করা, এটি তারপর w এবং d-এর জন্য প্রয়োজনীয় মানগুলি বের করার অনুমতি দেয়। সমান্তরালকরণ সম্ভব কারণ যেকোন সংখ্যক সাব-স্কেচ তুচ্ছভাবে অ্যারের সমষ্টি হিসাবে একত্রিত করা যেতে পারে, যতক্ষণ না একই পরামিতি এবং হ্যাশ ফাংশনগুলি তৈরিতে ব্যবহার করা হয়।
কাউন্ট-মিন স্কেচ সম্পর্কে কিছু পর্যবেক্ষণ
কাউন্ট মিন স্কেচ এর প্রয়োজনীয়তা পর্যালোচনা করে এর দক্ষতা প্রদর্শন করা যেতে পারে। CMS-এর স্থান জটিলতা হল w, d, এবং এটি যে কাউন্টার ব্যবহার করে তার প্রস্থের গুণফল। উদাহরণস্বরূপ, 0.01% সম্ভাব্যতার সাথে 0.01% ত্রুটির হার সহ একটি স্কেচ 10 হ্যাশ ফাংশন এবং 2000-কাউন্টার অ্যারে ব্যবহার করে তৈরি করা হয়। 16-বিট কাউন্টারগুলির ব্যবহার অনুমান করে, ফলাফল স্কেচের ডেটা স্ট্রাকচার ঘড়ির সামগ্রিক মেমরির প্রয়োজনীয়তা 40KB-তে (মোট পর্যবেক্ষণের সংখ্যা এবং কয়েকটি পয়েন্টার সংরক্ষণের জন্য কয়েকটি অতিরিক্ত বাইট প্রয়োজন)। স্কেচের অন্যান্য কম্পিউটেশনাল দিকটি একইভাবে আনন্দদায়ক—কারণ হ্যাশ ফাংশনগুলি উত্পাদন এবং গণনা করার জন্য সস্তা, ডেটা স্ট্রাকচার অ্যাক্সেস করা, পড়া বা লেখার জন্য, এটিও স্থির সময়ে সঞ্চালিত হয়৷
CMS এর আরও অনেক কিছু আছে; স্কেচের লেখকরাও দেখিয়েছেন কীভাবে এটি অন্যান্য অনুরূপ প্রশ্নের উত্তর দেওয়ার জন্য ব্যবহার করা যেতে পারে। এর মধ্যে রয়েছে শতকরা অনুমান করা এবং ভারী হিটার (ঘন ঘন আইটেম) সনাক্ত করা কিন্তু এই পোস্টের সুযোগের বাইরে।
সিএমএস অবশ্যই একটি চমৎকার স্কেচ, তবে কমপক্ষে দুটি জিনিস রয়েছে যা এটিকে পরিপূর্ণতা অর্জনে বাধা দেয়। CMS সম্পর্কে আমার প্রথম রিজার্ভেশন হল এটি পক্ষপাতদুষ্ট হতে পারে, এবং এইভাবে অল্প সংখ্যক পর্যবেক্ষণের সাথে নমুনার ফ্রিকোয়েন্সিকে অত্যধিক মূল্যায়ন করতে পারে। CMS এর পক্ষপাত সুপরিচিত এবং বেশ কিছু উন্নতির পরামর্শ দেওয়া হয়েছে। সবচেয়ে সাম্প্রতিকটি হল কাউন্ট মিন লগ স্কেচ (জি. পিটেল এবং জি. ফুকুইয়ের থেকে "আনুমানিক কাউন্টারগুলির সাথে প্রায় গণনা"), যা মূলত আপেক্ষিক ত্রুটি কমাতে এবং প্রস্থ না বাড়িয়ে উচ্চ গণনার অনুমতি দেওয়ার জন্য লগারিদমিক রেজিস্টারগুলিকে লগারিদমিক দিয়ে প্রতিস্থাপন করে। কাউন্টার রেজিস্টারের।
যদিও উপরের রিজার্ভেশনটি প্রত্যেকের দ্বারা ভাগ করা হয়েছে (যদিও শুধুমাত্র যারা ডেটা স্ট্রাকচার গ্রোক করে), আমার দ্বিতীয় রিজার্ভেশনটি রেডিস সম্প্রদায়ের জন্য একচেটিয়া। ব্যাখ্যা করার জন্য, আমাকে রেডিস মডিউল প্রবর্তন করতে হবে।
একটি রেডিস মডিউল
রেডিস মডিউলগুলি এই বছরের শুরুতে রেডিসকনফে এন্টিরেজ দ্বারা উন্মোচন করা হয়েছিল এবং আক্ষরিক অর্থে আমাদের বিশ্বকে উল্টে দিয়েছে। সার্ভার-লোডযোগ্য ডায়নামিক লাইব্রেরির চেয়ে কম বা কম কিছুই নয়, মডিউলগুলি রেডিস ব্যবহারকারীদের রেডিসের চেয়ে দ্রুত গতিতে যেতে দেয় এবং এমন জায়গায় যেতে দেয় যা আগে কখনও স্বপ্নেও ভাবিনি। এবং যদিও এই পোস্টটি মডিউলগুলি কী বা কীভাবে সেগুলি তৈরি করতে হয় তার একটি ভূমিকা নয়, এটি একটি (পাশাপাশি এই পোস্টটি এবং এই ওয়েবিনার)৷
আমি কাউন্ট মিন স্কেচ রেডিস মডিউলটি লিখতে চেয়েছিলাম, এর চরম উপযোগিতা ছাড়াও বেশ কয়েকটি কারণ রয়েছে। এটির একটি অংশ ছিল একটি শেখার অভিজ্ঞতা এবং এটির একটি অংশ ছিল মডিউল API-এর একটি মূল্যায়ন, কিন্তু বেশিরভাগ ক্ষেত্রে এটি Redis-এ একটি নতুন ডেটা স্ট্রাকচার মডেল করার জন্য একটি সম্পূর্ণ মজা ছিল। মডিউলটি স্কেচে পর্যবেক্ষণ যোগ করার জন্য, এটিকে জিজ্ঞাসা করার জন্য এবং একাধিক স্কেচকে একটিতে মার্জ করার জন্য একটি Redis ইন্টারফেস প্রদান করে৷
মডিউলটি একটি রেডিস স্ট্রিং-এ স্কেচের ডেটা সঞ্চয় করে এবং এর অভ্যন্তরীণ ডেটা কাঠামোতে কী-এর বিষয়বস্তু ম্যাপ করার জন্য সরাসরি মেমরি অ্যাক্সেস (DMA) ব্যবহার করে। আমি এখনও এটিতে সম্পূর্ণ পারফরম্যান্স বেঞ্চমার্কগুলি পরিচালনা করতে পারিনি, তবে স্থানীয়ভাবে এটি পরীক্ষা করে আমার প্রাথমিক ধারণা হল যে এটি মূল রেডিস কমান্ডগুলির মতোই কার্যকরী। আমাদের অন্যান্য মডিউলের মতো, কাউন্টমিনস্কেচ ওপেন সোর্স এবং আমি আপনাকে এটি ব্যবহার করে হ্যাক করার জন্য উত্সাহিত করি৷
সাইন অফ করার আগে, আমি আমার প্রতিশ্রুতি রাখতে চাই এবং CMS সম্পর্কে আমার Redis-নির্দিষ্ট রিজার্ভেশন শেয়ার করতে চাই। সমস্যা, যা অন্যান্য স্কেচ এবং ডেটা স্ট্রাকচারের ক্ষেত্রেও প্রযোজ্য, সেটি হল CMS-এর জন্য আপনাকে এটি সেট আপ/ইনিশিয়ালাইজ করতে/এটি ব্যবহারের আগে তৈরি করতে হবে। বাধ্যতামূলক প্রাথমিক পর্যায়ের প্রয়োজন, যেমন CMS প্যারামিটার সেটআপ, Redis-এর মৌলিক প্যাটার্নগুলির মধ্যে একটিকে ভেঙে দেয় — ডেটা স্ট্রাকচারগুলি ব্যবহারের আগে স্পষ্টভাবে ঘোষণা করার প্রয়োজন নেই কারণ সেগুলি চাহিদা অনুযায়ী তৈরি করা যেতে পারে। মডিউলটিকে আরও রেডিস-ইশ মনে করতে এবং সেই অ্যান্টি-প্যাটার্নের চারপাশে কাজ করতে, যখন একটি নতুন স্কেচ অন্তর্নিহিতভাবে উহ্য থাকে তখন মডিউলটি ডিফল্ট প্যারামিটার মান ব্যবহার করে (যেমন একটি অ-বিদ্যমান কী-তে CMS.ADD কমান্ড ব্যবহার করে) কিন্তু নতুন তৈরি করার অনুমতি দেয় প্রদত্ত পরামিতি সহ খালি স্কেচ।
সম্ভাব্য ডেটা স্ট্রাকচার, বা স্কেচগুলি হল আশ্চর্যজনক সরঞ্জাম যা আমাদেরকে একটি দক্ষ এবং যথেষ্ট সঠিক উপায়ে বড় ডেটার বৃদ্ধি এবং লেটেন্সি বাজেটের সংকোচনের সাথে তাল মিলিয়ে চলতে দেয়৷ এই পোস্টে উল্লিখিত দুটি স্কেচ, এবং অন্যান্য যেমন ব্লুম ফিল্টার এবং টি-ডাইজেস্ট, আধুনিক ডেটা মঞ্জারের অস্ত্রাগারে দ্রুত অপরিহার্য সরঞ্জাম হয়ে উঠছে। মডিউলগুলি আপনাকে কাস্টম ডেটা প্রকার এবং কমান্ড সহ Redis প্রসারিত করতে দেয় যা স্থানীয় গতিতে কাজ করে এবং ডেটাতে স্থানীয় অ্যাক্সেস থাকে। সম্ভাবনা অন্তহীন এবং কিছুই অসম্ভব নয়।
Redis মডিউল সম্পর্কে আরও জানতে চান এবং কীভাবে তাদের বিকাশ করবেন? কোন ডেটা স্ট্রাকচার আছে, সম্ভাব্যতা বা না হোক, যেটি আপনি রেডিসে আলোচনা করতে বা যোগ করতে চান? আমার টুইটার অ্যাকাউন্টে বা ইমেলের মাধ্যমে যেকোনো কিছুর জন্য নির্দ্বিধায় আমার সাথে যোগাযোগ করুন – আমি অত্যন্ত উপলব্ধ 🙂
