
প্রতিটি ব্যবসা গ্রাহকের আনুগত্য উপর নির্ভর করে. গ্রাহকের কাছ থেকে পুনরাবৃত্ত ব্যবসা ব্যবসার লাভজনকতার অন্যতম ভিত্তি। তাই গ্রাহকদের ব্যবসা ছেড়ে দেওয়ার কারণ জানা গুরুত্বপূর্ণ। গ্রাহক চলে যাওয়াকে গ্রাহক মন্থন বলা হয়। অতীতের প্রবণতাগুলি দেখে আমরা বিচার করতে পারি যে কোন বিষয়গুলি গ্রাহক মন্থনকে প্রভাবিত করে এবং কীভাবে ভবিষ্যদ্বাণী করা যায় যে কোনও নির্দিষ্ট গ্রাহক ব্যবসা থেকে দূরে চলে যাবে। এই নিবন্ধে আমরা গ্রাহক মন্থনের অতীত প্রবণতাগুলি অধ্যয়ন করতে ML অ্যালগরিদম ব্যবহার করব এবং তারপর বিচার করব কোন গ্রাহকরা মন্থন করতে পারে৷
ডেটা প্রস্তুতি
উদাহরণ হিসেবে এই নিবন্ধটির জন্য টেলিকম গ্রাহক মন্থন বিবেচনা করা হবে। উৎস তথ্য kaggel এ উপলব্ধ. ডেটা ডাউনলোড করার URL নীচের প্রোগ্রামে উল্লেখ করা হয়েছে। আমরা পাইথন প্রোগ্রামে csv ফাইল লোড করতে এবং কিছু নমুনা সারি দেখতে পান্ডাস লাইব্রেরি ব্যবহার করি।
উদাহরণ
pd হিসেবে পান্ডা আমদানি করুন#Telco-Customer-Churn.csv ডেটাসেট লোড হচ্ছে#https://www.kaggle.com/blastchar/telco-customer-churndatainput =pd.read_csv('E:\\Telecom_customers.csv' )প্রিন্ট("প্রদত্ত ইনপুট ডেটা :\n",ডেটাইনপুট) আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
<প্রে>প্রদত্ত ইনপুট ডেটা:কাস্টমারআইডি লিঙ্গ সিনিয়র সিটিজেন... মাসিক চার্জ মোট চার্জ Churn0 7590-VHVEG মহিলা 0 ... 29.85 29.85 নং 5575-GNVDE পুরুষ 0 ... 56.95 1889.5 1889.5 Male... 56.95 1889.5 Male 53578.5389.5375858589. -CFOCW পুরুষ 0 ... 42.30 1840.75 No4 9237-HQITU মহিলা 0 ... 70.70 151.65 হ্যাঁ... ... ... ... ... ... ... ... 7038 6840-RESVB পুরুষ 0 ... 84.80 1990.5 No7039 2234-XADUH মহিলা 0 ... 103.20 7362.9 No7040 4801-JZAZL মহিলা 0 ... 29.60 346.45 নম্বর 7041 8361-LTMKD পুরুষ 1 ... 74.40 306.6 হ্যাঁ7042 3186-AJIEK পুরুষ 0 ... 105.65 6844.5 না[7043 সারি x 21 কলাম]বিদ্যমান প্যাটার্ন অধ্যয়ন করুন
পরবর্তীতে আমরা চেইনটি কখন ঘটে তার বিদ্যমান নিদর্শনগুলি খুঁজে পেতে ডেটা সেটটি অধ্যয়ন করি। আমরা ডেটা ফ্রেন্ড থেকে কিছু কলাম ড্রপ করি যা শর্তকে প্রভাবিত করে না। উদাহরণস্বরূপ, গ্রাহক আইডি কলামটি গ্রাহকের পাতা না হয় কিনা তার উপর প্রভাব ফেলবে না তাই আমরা ড্রপ অল পপ পদ্ধতি ব্যবহার করে এই জাতীয় কলাম ড্রপ করি। তারপরে আমরা প্রদত্ত ডেটা সেটে সুযোগের শতাংশ দেখানো একটি চার্ট তৈরি করি।
উদাহরণ 2
pdimport matplotlib.pyplot হিসাবে pandas আমদানি করুন E:\\Telecom_customers.csv')প্রিন্ট("প্রদত্ত ইনপুট ডেটা :\n",ডেটাইনপুট)#ড্রপিং columnsdatainput.drop(['customerID'], axis=1, inplace=True)datainput.pop('টোটাল চার্জ') datainput['OnlineBackup'].unique()data =datainput['churn'].value_counts(sort =True)chroma =["#BDFCC9","#FFDEAD"]rcParams['figure.figsize'] =9,9 explode =[0.2,0.2]plt.pie(data, explode=explode, colors=chroma, autopct='%1.1f%%', shadow=True, startangle=180,)plt.title('প্রদত্ত মন্থনের শতাংশ ডেটা')plt.show() আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
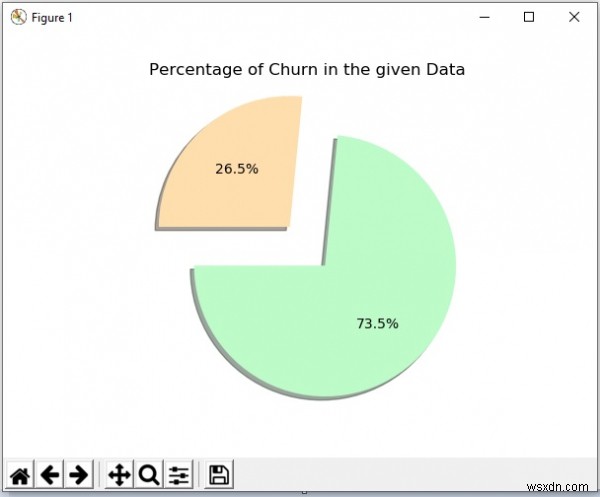
ডেটা প্রিপ্রসেসিং
ML অ্যালগরিদম ব্যবহার করার জন্য ডেটা প্রস্তুত করতে, আমরা সমস্ত ক্ষেত্র লেবেল করি। আমরা পাঠ্য মানগুলিকে সংখ্যাসূচক পতাকায় রূপান্তর করি। উদাহরণস্বরূপ, লিঙ্গ কলামের মানগুলি পুরুষ এবং মহিলার পরিবর্তে 0 এবং 1 এ পরিবর্তিত হয়৷ এটি গণনা এবং অ্যালগরিদমগুলিতে সেই ক্ষেত্রগুলি ব্যবহার করতে সহায়তা করে যা মন্থন মানের উপর এই ক্ষেত্রগুলির প্রভাব মূল্যায়ন করবে। আমরা sklearn থেকে LabelEncoder পদ্ধতি ব্যবহার করি।
উদাহরণ 3
sklearn import preprocessinglabel_encoder =preprocessing.LabelEncoder()datainput['gender'] =label_encoder.fit_transform(datainput['gender'])datainput['Partner'] =label_encoder.fit_transform'[Partner'] ])datainput['Dependents'] =label_encoder.fit_transform(datainput['Dependents'])datainput['PhoneService'] =label_encoder.fit_transform(datainput['PhoneService'])datainput['MultipleLines'] =label_encoder('MultipleLines'] =label_encoder ['MultipleLines'])datainput['InternetService'] =label_encoder.fit_transform(datainput['InternetService'])datainput['OnlineSecurity'] =label_encoder.fit_transform(datainput['OnlineSecurity'])ডাটাইনপুট .fit_transform(datainput['OnlineBackup'])datainput['DeviceProtection'] =label_encoder.fit_transform(datainput['DeviceProtection'])datainput['TechSupport'] =label_encoder.fit_transform(datainput['Techdatainput']Streaming']TVSport '] =label_encoder.fit_transform(datainput['StreamingTV'])datainp ut['StreamingMovies'] =label_encoder.fit_transform(datainput['StreamingMovies'])datainput['Contract'] =label_encoder.fit_transform(datainput['Contract'])datainput['PaperlessBilling'] =label_encoder(fit_transform' PaperlessBilling'])datainput['PaymentMethod'] =label_encoder.fit_transform(datainput['PaymentMethod'])datainput['Churn'] =label_encoder.fit_transform(datainput['Churn'])প্রিন্ট("লেবেল এনকোডারের পরে ইনপুট ডেটা :\ n",datainput)#বিচ্ছিন্ন বৈশিষ্ট্য(X) এবং লেবেল(y)datainput["Churn"] =datainput["Churn"].astype(int)y =datainput["Churn"].valuesX =datainput.drop(লেবেল =["মন্থন"],অক্ষ =1)মুদ্রণ("\nX এবং y :")মুদ্রণ("y -",y)মুদ্রণ("X -",X)আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
লেবেল এনকোডার কাস্টমারআইডি লিঙ্গ সিনিয়র সিটিজেনের পরে ডেটা ইনপুট করুন... মাসিক চার্জ মোট চার্জ Churn0 7590-VHVEG 0 0 ... 29.85 29.85 01 5575-GNVDE 1 0 ... 56.95 18289.51818535350. 7795-CFOCW 1 0 ... 42.30 1840.75 04 9237-HQITU 0 0 ... 70.70 151.65 1... ... ... ... ... ... ... ... 7038 6840-RESVB 1 0 ... 84.80 1990.5 07039 2234-XADUH 0 0 ... 103.20 7362.9 07040 4801-JZAZL 0 0 ... 29.60 346.45 07041 83761836104507041.376145.45 টিএম6844.5 0[7043 সারি x 21 কলাম] পৃথক করা X এবং y :y - [0 0 1 ... 0 1 0]X - কাস্টমারআইডি লিঙ্গ ... মাসিক চার্জ মোট চার্জ0 7590-VHVEG 0 ... 29.85 29.85G-29.8511 .. 56.95 1889.52 3668-QPYBK 1 ... 53.85 108.153 7795-CFOCW 1 ... 42.30 1840.754 9237-HQITU 0 ... 70.70 ... 1531 ... ... 70.70 ... 1531 ... ... 6840-রেসভিবি 1 ... 84.80 1990.57039 2234-Xaduh 0 ... 103.20 7362.97040 4801-জজাজল 0 ... ২9.60 346.457041 8361-এলটিএমএইচডি 1 ... 74.40 30667042 3186-Ajiek 1 ... 105.65 6844.5 [7043 সারি x 20 কলাম]
ডেটা প্রশিক্ষণ এবং পরীক্ষা করা
এখন আমরা ডেটা সেট দুটি ভাগে বিভক্ত করি। একটি প্রশিক্ষণের জন্য এবং অন্যটি পরীক্ষার জন্য। শুধুমাত্র পরীক্ষার জন্য কত শতাংশ ডেটা সেট ব্যবহার করা হবে তা নির্ধারণ করতে test_size প্যারামিটার ব্যবহার করা হয়। এই অনুশীলনটি আমাদের তৈরি করা মডেলের উপর আস্থা অর্জন করতে সাহায্য করবে। তারপরে আমরা লজিস্টিক রিগ্রেশন অ্যালগরিদম প্রয়োগ করি এবং পূর্বাভাসিত মানগুলি খুঁজে বের করি।
উদাহরণ
sklearn.linear_model import LogisticRegression থেকে pdimport warningswarnings.filterwarnings("ignore") হিসাবেপান্ডা আমদানি করুন#pandasdatainput =pd.read_csv('E:\\'merdacs_com) সহ Telco-Customer-Churn.csv ডেটাসেট লোড করা হচ্ছে। .drop(['customerID'], axis=1, inplace=True)datainput.pop('TotalCharges')datainput['OnlineBackup'].unique()#LabelEncoder() from sklearn import preprocessinglabel_encoder =প্রিপ্রসেসিং (LabelEncoder) ['gender'] =label_encoder.fit_transform(datainput['gender'])datainput['Partner'] =label_encoder.fit_transform(datainput['Partner'])datainput['Dependents'] =label_encoder.fit_transform(datainput['Dependents') '])datainput['PhoneService'] =label_encoder.fit_transform(datainput['PhoneService'])datainput['MultipleLines'] =label_encoder.fit_transform(datainput['MultipleLines'])datainput['InternetService'] =label_transform datainput['InternetService'])datainput['OnlineSecurity'] =label_encoder.fit_transform(datainput['OnlineSecurity'])d atainput['OnlineBackup'] =label_encoder.fit_transform(datainput['OnlineBackup'])datainput['DeviceProtection'] =label_encoder.fit_transform(datainput['DeviceProtection'])datainput['TechSupport'] =label_transform TechSupport'])datainput['StreamingTV'] =label_encoder.fit_transform(datainput['StreamingTV'])datainput['StreamingMovies'] =label_encoder.fit_transform(datainput['StreamingMovies'])datainput['Contract'] =label_transform. (datainput['Contract'])datainput['PaperlessBilling'] =label_encoder.fit_transform(datainput['PaperlessBilling'])datainput['PaymentMethod'] =label_encoder.fit_transform(datainput['PaperlessBilling']]datain' =label_encoder.fit_transform(datainput['Churn'])#print("লেবেল এনকোডারের পরে ইনপুট ডেটা :\n",datainput)#বিভাজন বৈশিষ্ট্য(X) এবং লেবেল(y)datainput["Churn"] =datainput["Churn "].astype(int)Y =datainput["Churn"].valuesX =datainput.drop(লেবেল =["Churn"],axis =1) sklearn.model_selec থেকে #train_test_split পদ্ধতি tion import train_test_splitX_train, X_test, Y_train, Y_test =train_test_split(X, Y, test_size=0.2)#LogisticRegressionclassifier=LogisticRegression()classifier.fit(X_train,Y_train)Y_pred=classifier(x_pred=classifier) n"Y_pred) আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
ভবিষ্যদ্বাণীকৃত মান :[0 0 1 ... 0 1 0]
মূল্যায়ন পরামিতি খোঁজা
উপরের ধাপে নির্ভুলতার মাত্রা গ্রহণযোগ্য হলে আমরা বিভিন্ন পরামিতি খুঁজে বের করে মডেলটির আরও মূল্যায়ন করি। এই মডেলটি কতটা সঠিকভাবে আচরণ করছে তা বিচার করতে আমরা আমাদের প্যারামিটার হিসাবে যথার্থতা এবং বিভ্রান্তি ম্যাট্রিক্স ব্যবহার করি। নির্ভুলতার মানের একটি উচ্চ শতাংশ মডেলটিকে একটি ভাল ফিট হিসাবে প্রস্তাব করে৷ একইভাবে বিভ্রান্তি ম্যাট্রিক্স সত্য ইতিবাচক, সত্য নেতিবাচক, মিথ্যা ধনাত্মক এবং মিথ্যা নেতিবাচকগুলির একটি ম্যাট্রিক্স দেখায়। মিথ্যা মানগুলির তুলনায় সত্য মানগুলির একটি উচ্চ শতাংশ হল আরও ভাল মডেলের ইঙ্গিত৷
৷উদাহরণ
sklearn.linear_model থেকে pdimport warningswarnings.filterwarnings("ignore") হিসাবে পান্ডা আমদানি করুন \\Telecom_customers.csv')datainput.drop(['customerID'], axis=1, inplace=True)datainput.pop('TotalCharges')datainput['OnlineBackup'].unique()#LabelEncoder()sklearn আমদানি থেকে preprocessinglabel_encoder =preprocessing.LabelEncoder()datainput['gender'] =label_encoder.fit_transform(datainput['gender'])datainput['Partner'] =label_encoder.fit_transform(datainput['Partner'])datainput' ='Depend label_encoder.fit_transform(datainput['Dependents'])datainput['PhoneService'] =label_encoder.fit_transform(datainput['PhoneService'])datainput['MultipleLines'] =label_encoder.fit_transform(datainput['Multiple']Datainput['Multiple'da] InternetService'] =label_encoder.fit_transform(datainput['InternetService'])datainput['Onlin eSecurity'] =label_encoder.fit_transform(datainput['OnlineSecurity'])datainput['OnlineBackup'] =label_encoder.fit_transform(datainput['OnlineBackup'])datainput['DeviceProtection'] =label_encoder'[DeviceProtection']e )datainput['TechSupport'] =label_encoder.fit_transform(datainput['TechSupport'])datainput['StreamingTV'] =label_encoder.fit_transform(datainput['StreamingTV'])datainput['StreamingMovies'] =label_encoder 'স্ট্রিমিংমুভিজ'])datainput['Contract'] =label_encoder.fit_transform(datainput['Contract'])datainput['PaperlessBilling'] =label_encoder.fit_transform(datainput['PaperlessBilling'])datainput['PaperlessBilling'])label_encoder. fit_transform(datainput['PaymentMethod'])datainput['Churn'] =label_encoder.fit_transform(datainput['Churn'])#print("লেবেল এনকোডারের পরে ইনপুট ডেটা :\n",datainput)#বিচ্ছিন্ন বৈশিষ্ট্য(X) এবং label(y)datainput["Churn"] =datainput["Churn"].astype(int)Y =datainput["Churn"].valuesX =datainput.drop(লেবেল) s =["মথুন"],অক্ষ =1) #train_test_split পদ্ধতি থেকে sklearn.model_selection import train_test_splitX_train, X_test, Y_train, Y_test =train_test_split(X, Y, test_size=0.2)#Logisticifression_classion(YRegistic_Regassion) )Y_pred=classifier.predict(X_test)#AccuracyLR =metrics.accuracy_score(Y_test, Y_pred) * 100print("\nLR ব্যবহার করে নির্ভুলতা স্কোর হল -> ",LR)#confusion matrixcm=confusion_matrix,Ypred_matrix(Y_dprint) "\nবিভ্রান্তি ম্যাট্রিক্স :\n",সেমি)আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
LR ব্যবহার করে নির্ভুলতা স্কোর হল -> 80.8374733853797 কনফিউশন ম্যাট্রিক্স :[[928 109] [161 211]]
ভেরিয়েবলের ওজন
এরপরে আমরা বিচার করি কিভাবে প্রতিটি ক্ষেত্র বা পরিবর্তনশীল মন্থন মানকে প্রভাবিত করে। এটি আমাদের নির্দিষ্ট ভেরিয়েবলগুলিকে লক্ষ্য করতে সাহায্য করবে যেগুলি মন্থনের উপর বেশি প্রভাব ফেলবে এবং গ্রাহক মন্থন প্রতিরোধে সেই ভেরিয়েবলগুলি পরিচালনা করার চেষ্টা করবে৷ এর জন্য আমরা আমাদের শ্রেণীবিভাগের সহগগুলিকে শূন্যে সেট করি এবং প্রতিটি ভেরিয়েবলের ওজন পেতে পারি৷
উদাহরণ
sklearn.linear_model import LogisticRegression থেকে pdimport warningswarnings.filterwarnings("ignore") হিসাবেপান্ডা আমদানি করুন#pandasdatainput =pd.read_csv('E:\\Telecom_customers.csv')dataintomer'[IDtomer'[ID] ], axis=1, inplace=True)datainput.pop('TotalCharges')datainput['OnlineBackup'].unique()#LabelEncoder()from sklearn import preprocessinglabel_encoder =preprocessing.LabelEncoder()der'_belenput]labelencoder =.fit_transform(datainput['gender'])datainput['Partner'] =label_encoder.fit_transform(datainput['Partner'])datainput['Dependents'] =label_encoder.fit_transform(datainput['Dependents'])datainput['PhoneService '] =label_encoder.fit_transform(datainput['PhoneService'])datainput['MultipleLines'] =label_encoder.fit_transform(datainput['MultipleLines'])datainput['InternetService'] =label_encoder.fit_transform']net(datainput['MultipleLines']) datainput['OnlineSecurity'] =label_encoder.fit_transform(datainput['OnlineSecurity'])datainput['OnlineBackup'] =label_encoder.fit_transform(datainput['OnlineBackup'])datainput['DeviceProtection'] =label_encoder.fit_transform(datainput['DeviceProtection'])datainput['TechSupport'] =label_encoder.fit_transform(datainput'[echdatain'] 'স্ট্রিমিংটিভি'] =label_encoder.fit_transform(datainput['StreamingTV'])datainput['StreamingMovies'] =label_encoder.fit_transform(datainput['StreamingMovies'])datainput['Contract'] =label_encoder.fit_transform'(datainput' ])datainput['PaperlessBilling'] =label_encoder.fit_transform(datainput['PaperlessBilling'])datainput['PaymentMethod'] =label_encoder.fit_transform(datainput['PaymentMethod'])datainput['churn'](datainput['Churn')] =datainput ['চুর্ন'])#প্রিন্ট("লেবেল এনকোডারের পরে ইনপুট ডেটা :\n",ডেটাইনপুট)#বিচ্ছিন্ন বৈশিষ্ট্য(এক্স) এবং লেবেল(y)ডেটাইনপুট["চুর্ন"] =ডেটাইনপুট["চুর্ন"]।astype(int )Y =datainput["Churn"].valuesX =datainput.drop(লেবেল =["Churn"],axis =1)##train_test_split পদ্ধতি থেকে sklearn.model_selection import train_test_s plitX_train, X_test, Y_train, Y_test =train_test_split(X, Y, test_size=0.2)##LogisticRegressionclassifier=LogisticRegression()classifier.fit(X_train,Y_train)Y_pred=classifier.Predict=wdwt=wwt_west. সিরিজ(classifier.coef_[0], index=X.columns.values)মুদ্রণ("\nসমস্ত ভেরিয়েবলের ওজন :")প্রিন্ট(wt.sort_values(ascending=False)) আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
সমস্ত ভেরিয়েবল ওজন:PaperlessBilling 0.389379SeniorCitizen 0.246504InternetService 0.209283Partner 0.067855StreamingMovies 0.054309MultipleLines 0.042330PaymentMethod 0.039134MonthlyCharges 0.027180StreamingTV -0.008606gender -0.029547tenure -0.034668DeviceProtection -0.052690OnlineBackup -0.143625Dependents -0.209667OnlineSecurity -0.245952TechSupport -0.254740Contract -0.729557ফোনসার্ভিস -0.950555dtype:float64
