আদমশুমারি হল প্রদত্ত জনসংখ্যা সম্পর্কে একটি নিয়মতান্ত্রিক পদ্ধতিতে তথ্য রেকর্ড করা। ক্যাপচার করা ডেটাতে বিভিন্ন ধরণের তথ্য রয়েছে যেমন – জনসংখ্যা, অর্থনৈতিক, বাসস্থানের বিবরণ ইত্যাদি। এটি শেষ পর্যন্ত সরকারকে বর্তমান পরিস্থিতি বোঝার পাশাপাশি ভবিষ্যতের জন্য পরিকল্পনা করতে সহায়তা করে। এই প্রবন্ধে আমরা দেখতে পাব কীভাবে ভারতীয় জনসংখ্যার জন্য আদমশুমারির তথ্য বিশ্লেষণ করতে পাইথন ব্যবহার করা যায়। আমরা বিভিন্ন জনসংখ্যাগত এবং অর্থনৈতিক দিক দেখব। তারপর প্লট চার্জ যা গ্রাফিক্যাল পদ্ধতিতে বিশ্লেষণকে প্রজেক্ট করবে। কাগল থেকে যে উৎস সংগ্রহ করা হয়। এটি এখানে অবস্থিত।
ডেটা সংগঠিত করা
নীচের প্রোগ্রামে প্রথমে আমরা একটি ছোট পাইথন প্রোগ্রাম ব্যবহার করে ডেটা অর্জন করি। এটি আরও বিশ্লেষণের জন্য পান্ডাস ডেটাফ্রেমে ডেটা লোড করে। আউটপুট সহজ উপস্থাপনার জন্য কিছু ক্ষেত্র দেখায়।
উদাহরণ
পান্ডা আমদানি করুন -2011.csvprint(datainput)
আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
জেলা কোড... Total_Power_Parity0 1 ... 11191 2 ... 10662 3 ... 2423 4 ... 2144 5 ... 629.. ... ... ... ... 635 636 ... 10027636 637 ... 4890637 638 ... 3151638 639 ... 3151639 640 ... 5782[640 সারি x 118 কলাম]
দুটি রাজ্যের মধ্যে মিল বিশ্লেষণ করা
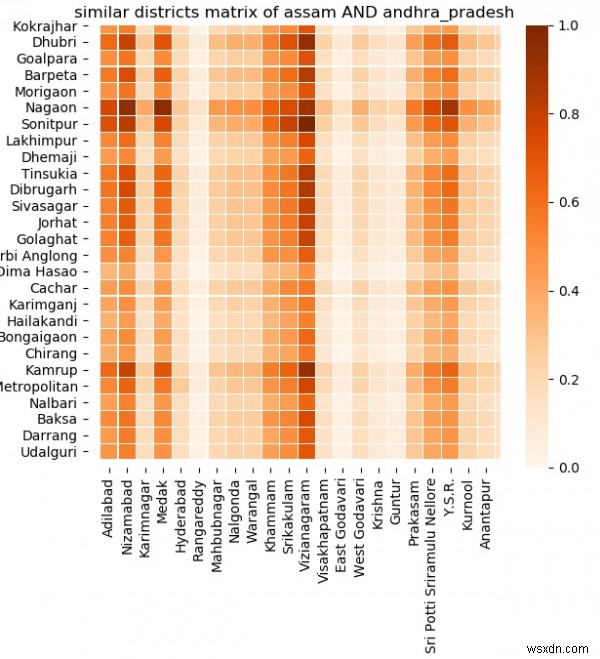
এখন যেহেতু আমরা ডেটা সংগ্রহ করেছি আমরা দুটি রাজ্যের মধ্যে বিভিন্ন ফ্রন্টে মিল বিশ্লেষণ করতে এগিয়ে যেতে পারি। মিলগুলি বয়স গোষ্ঠী, কম্পিউটারের মালিকানা, আবাসনের প্রাপ্যতা, শিক্ষার স্তর ইত্যাদির ভিত্তিতে হতে পারে৷ নীচের উদাহরণে আমরা আসাম এবং অন্ধ্র প্রদেশ নামক দুটি রাজ্যকে নিই৷ তারপর আমরা মিল_ম্যাট্রিক্স ব্যবহার করে দুটি অবস্থার তুলনা করি। উভয় রাজ্যের প্রতিটি সম্ভাব্য জোড়া জেলার জন্য সমস্ত ডেটা ক্ষেত্র তুলনা করা হয়। ফলাফল হিটম্যাপ নির্দেশ করে যে এই দুটি কতটা ঘনিষ্ঠভাবে সম্পর্কিত। ছায়া যত গাঢ় হবে ততই তারা সম্পর্কিত।
উদাহরণ
matplotlib.colors থেকে pdimport matplotlib.pyplot হিসাবে pandas আমদানি করুন 'রাজ্যের নাম'] =='আসাম']df_ANDHRA_PRADESH =datainput.loc[datainput['State name'] =='ANDHRA PRADESH']def সেগমেন্ট(x1, x2):# উভয় ডেটা ফ্রেমের জন্য সূচক সেট করুন x1.set_index ('জেলা কোড') x2.set_index('ডিস্ট্রিক্ট কোড') # লেন(x1) X len(x2) মিলের ম্যাট্রিক্সের সাদৃশ্য ম্যাট্রিক্স =[] # x1.iterrows() এ r1 এর জন্য df1 এর সারিগুলির মাধ্যমে পুনরাবৃত্তি করুন:# x2 y =[] এর অন্যান্য সারির সাথে সারি 1 এর সাদৃশ্য স্কোর রাখার জন্য তালিকা তৈরি করুন # x2.iterrows(এ r2 এর জন্য x2 এর সারিগুলির মাধ্যমে পুনরাবৃত্তি করুন):# তালিকায় (ডেটাইনপুট) c এর জন্য n =0 বর্গক্ষেত্রের পার্থক্যের যোগফল গণনা করুন। :]:সর্বোচ্চ_c =সর্বোচ্চ(ডেটাইনপুট[c]) ন্যূনতম_c =মিনিট(ডেটাইনপুট[c]) n +=pow((r1[1][c] - r2[1][c]) / (সর্বোচ্চ_c - সর্বনিম্ন_c), 2) # sqrt নিন এবং ফলাফলটি y.append(1 / math.sqrt(n)) # যোগ করুন মিলের স্কোরের মিল যোগ করুন. n রেঞ্জের জন্য(len(smilarity_matrix[m])):if (similarity_matrix[m][n]> p):p =similarity_matrix[m][n] q =m r =n print("%s ASSAM থেকে এবং % অন্ধ্রপ্রদেশ থেকে s সবচেয়ে বেশি একই রকম" % (x1['জেলার নাম'].iloc[q],x2['জেলার নাম'].iloc[r])) সাদৃশ্য_matrixm =সেগমেন্ট(df_ASSAM, df_ANDHRA_PRADESH)সাধারণকরণ=স্বাভাবিককরণ( )s =plot.axes()sns.heatmap(normalization(m), xticklabels=df_ANDHRA_PRADESH['জেলার নাম'],yticklabels=df_ASSAM['জেলার নাম'],linewidths=0.05,cmap='Oranges').set_title( "আসাম এবং অন্ধ্র_প্রদেশের অনুরূপ জেলা ম্যাট্রিক্স")plot.rcParams['figure.figsize'] =(20,20)plot.show()আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
নির্দিষ্ট পরামিতি তুলনা
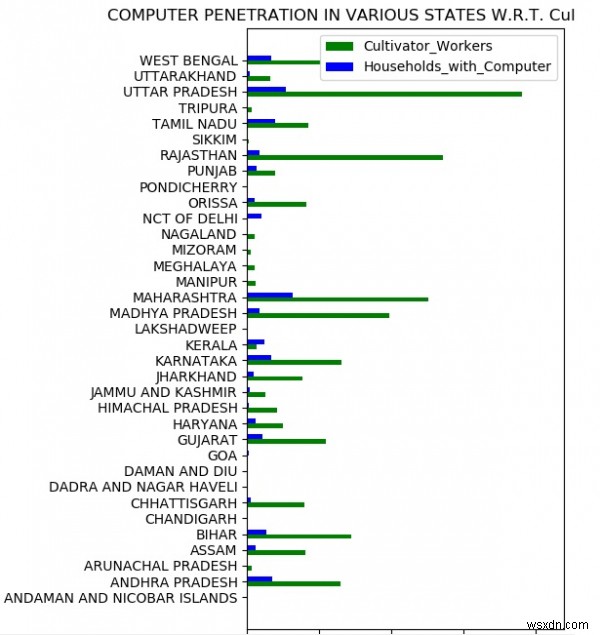
এখন আমরা নির্দিষ্ট পরামিতি সাপেক্ষে স্থানগুলি তুলনা করতে পারি। নীচের উদাহরণে আমরা চাষি শ্রমিকদের জন্য উপলব্ধ পরিবারের কম্পিউটারের প্রাপ্যতার তুলনা করি। আমরা গ্রাফ তৈরি করি যা প্রতিটি রাজ্যের জন্য এই দুটি পরামিতির মধ্যে তুলনা দেখায়।
উদাহরণ
numpy আমদানি থেকে pdimport matplotlib.pyplot হিসাবে pandas আমদানি করুন *datainput =pd.read_csv('E:\\india-districts-sensus-2011.csv')z =datainput.groupby(by="State name") m =[]w =[] k-এর জন্য, z-এ g:t =0 t1 =0 r-এর জন্য g.iterrows():t +=r[1][36] t1 +=r[1][21] m.append((k, t)) w.append((k, t1))mp=pd.DataFrame({ 'state':[x[0] for x m in], 'households_with_computer':[x[1] ] এর জন্য m in x], 'Cultivator_Workers':[x[1] এর জন্য x in w]})d =arange(35)wi =0.3fig, f =plot.subplots()plot.xlim(0, 22000000)r1 =f.barh(d, mp['Cultivator_Workers'], wi, color='g', align='center')r2 =f.barh(d + wi, mp['households_with_computer'], wi, color=' b', align='center')f.set_xlabel('জনসংখ্যা')f.set_title('বিভিন্ন রাজ্যে কম্পিউটারের প্রবেশ mp['state']))f.legend((r1[0], r2[0]), ('Cultivator_Workers', 'households_with_computer'))plot.rcParams.update({'font.size':15}) plot.rcParams['figure.figsize' ] =(15, 15)plot.show() আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -