ml এবং AI শেখার জন্য পরিসংখ্যান মৌলিক। যেহেতু পাইথন এই প্রযুক্তিগুলির জন্য পছন্দের ভাষা, তাই আমরা দেখব কিভাবে পাইথন প্রোগ্রাম লিখতে হয় যা পরিসংখ্যানগত বিশ্লেষণকে অন্তর্ভুক্ত করে। এই প্রবন্ধে আমরা দেখব কিভাবে বিভিন্ন পাইথন মডিউল ব্যবহার করে গ্রাফ এবং চার্ট তৈরি করা যায়। এই বৈচিত্র্যময় চার্টগুলি আমাদেরকে দ্রুত ডেটা বিশ্লেষণ করতে সাহায্য করে এবং গ্রাফিকভাবে উপসংহারের ভিতরের তথ্য বের করতে সাহায্য করে৷
ডেটা প্রস্তুতি
আমরা বিভিন্ন বীজ সম্পর্কে তথ্য ধারণকারী ডেটা সেট গ্রহণ করি। এই ডেটা সেটটি নীচের প্রোগ্রামে দেখানো লিঙ্কে ক্যাগল এ উপলব্ধ। এটিতে আটটি কলাম রয়েছে যা বিভিন্ন বীজের বৈশিষ্ট্য তুলনা করার জন্য বিভিন্ন ধরণের চার্ট তৈরি করতে ব্যবহৃত হবে। নীচের প্রোগ্রামটি স্থানীয় পরিবেশ থেকে ডেটা সেট লোড করে এবং সারিগুলির একটি নমুনা প্রদর্শন করে৷
উদাহরণ
pdimport warningswarnings.filterwarnings("ignore")datainput =pd.read_csv('E:\\seeds.csv')#https://www.kaggle.com/jmcaro/wheat-seedsuciprint(datainput) হিসাবে পান্ডা আমদানি করুন আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
এরিয়া পেরিমিটার কম্প্যাক্টেশন ... Asymmetretry.coff Kernel.groove Tryp0 15.26 14.84 0.8710 ... 2.221 5.220 11 14.88 14.57 0.8811 ... 1.018 4.956 12 14.29 14.09 0.9050 ... 2.699 4.825 13 13.84 13.94 0.8955 ... 2.259 4.805 14 16.14 14.99 0.9034 ... 1.355 5.175 1.. ... ... ... ... ... ... ... 194 12.19 13.20 0.8783 ... 3.631 4.870 3195 11.318 ... ... ... ... ... ... ... ... ... 4.325 5.003 3196 13.20 13.66 0.8883 ... 8.315 5.05 6 3197 11.84 13.21 0.8521 ... 3.598 5.044 3198 12.30 13.34 0.8684 ... 5.637 5.063 3[199 সারি x 8 কলাম]
হিস্টোগ্রাম তৈরি করা হচ্ছে
একটি হিস্টোগ্রাম তৈরি করতে আমরা csv ফাইল থেকে হেডার সারিটি সরিয়ে ফেলি এবং ফাইলটিকে নম্পি অ্যারে হিসাবে পড়ি। তারপরে আমরা ফাইলটি পড়ার জন্য genfromtxt মডিউল ব্যবহার করি। ফাইল করা কার্নেলের দৈর্ঘ্য অ্যারেতে কলাম সূচক 3 হিসাবে অবস্থিত। অবশেষে আমরা numpy দ্বারা তৈরি ডেটা সেট ব্যবহার করে হিস্টোগ্রাম প্লট করতে matplotlib ব্যবহার করি এবং প্রয়োজনীয় লেবেলগুলিও প্রয়োগ করি৷
উদাহরণ
matplotlib.pyplot আমদানি করুন plotimport numpy হিসাবে npfrom numpy আমদানি করুন genfromtxtseed_data =genfromtxt('E:\\seeds.csv', delimiter=',')Kernel_Length =seed_data[:, [Llenng] y =np.sqrt(x)y =int(y)z =plot.hist(Kernel_Length, bins=y, color='#FF4040')z =plot.xlabel('Kernel_Length')z =plot.ylabel(' values')plot.show() আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
<প্রে>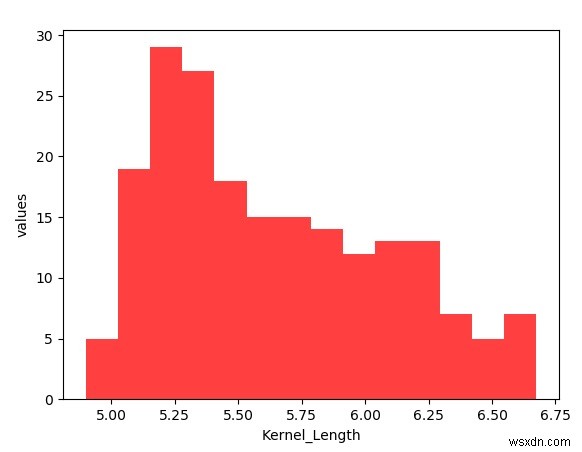
অভিজ্ঞতামূলক ক্রমবর্ধমান বিতরণ ফাংশন
এই চার্টটি ডেটা সেট জুড়ে বিতরণ করা কার্নেল খাঁজের আকারের প্লট দেখায়। এটি সর্বনিম্ন থেকে সর্বোচ্চ মান পর্যন্ত সাজানো হয় এবং এটি একটি বিতরণ হিসাবে দেখানো হয়।
উদাহরণ
matplotlib.pyplot আমদানি করুন plotimport numpy হিসাবে npfrom numpy আমদানি করুন genfromtxtseed_data =genfromtxt('E:\\seeds.csv', delimiter=',')Kernel_groove =seed_deta[f:, CDFSEED] ক্রমবর্ধমান বন্টন ফাংশন i =len(seed_data) m =np.sort(seed_data) n =np.arange(1, i + 1) / i রিটার্ন m, nm, n =ECDF(Kernel_groove)plot.plot(m, n, marker='.', linestyle='none')plot.xlabel('Kernel_Groove')plot.ylabel('Empirical cumulative distribution functions')plot.show() আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
<প্রে>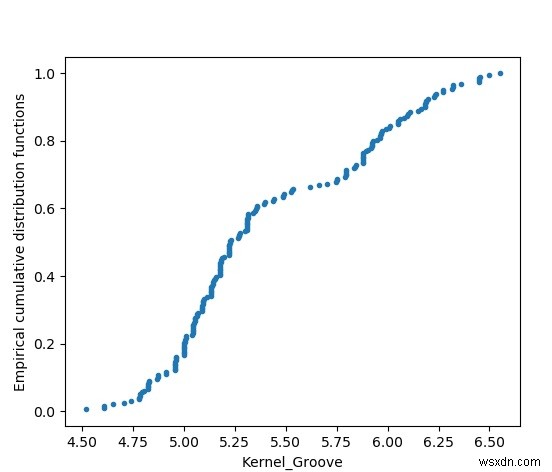
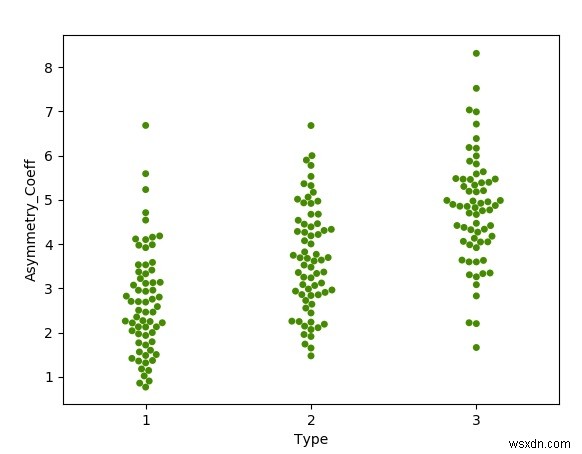
মৌমাছির ঝাঁক প্লট
একটি মৌমাছির প্লট প্রতিটি পৃথক ডেটা পয়েন্টকে দৃশ্যত ক্লাস্টার করে ডেটা পয়েন্টগুলির একটি গ্রুপের আকার দেখায়। আমরা এই গ্রাফ তৈরি করতে সমুদ্রের লাইব্রেরি ব্যবহার করি। আমরা একই ধরনের বীজ একসাথে গুচ্ছ করতে ডেটা সেট থেকে টাইপ কলাম ব্যবহার করি।
উদাহরণ
পান্ডা আমদানি করুন pdimport matplotlib.pyplot হিসাবে plotimport seaborn হিসাবে snsdatainput =pd.read_csv('E:\\seeds.csv')sns.swarmplot(x='Type', y='Asymmetry.Coeff',data=datainput, color='#458B00')#bee swarm plotplot.xlabel('Type')plot.ylabel('Asymmetry_Coeff')plot.show() আউটপুট
উপরের কোডটি চালানো আমাদের নিম্নলিখিত ফলাফল দেয় -
<প্রে>