
মেশিন লার্নিং-এ অনেক ধরনের ক্লাস্টারিং অ্যালগরিদম রয়েছে৷ এই অ্যালগরিদমগুলি পাইথনে প্রয়োগ করা যেতে পারে। এই নিবন্ধে, আসুন আমরা পাইথন ব্যবহার করে 'Mean−Shift' অ্যালগরিদম নিয়ে আলোচনা করি এবং বাস্তবায়ন করি। এটি একটি ক্লাস্টারিং অ্যালগরিদম যা একটি তত্ত্বাবধানহীন শেখার পদ্ধতি হিসাবে ব্যবহৃত হয়৷
এই অ্যালগরিদমে, কোন অনুমান করা হয় না। এটি বোঝায় যে এটি একটি নন-প্যারামেট্রিক অ্যালগরিদম। এই অ্যালগরিদম নির্দিষ্ট ক্লাস্টারে ডেটা পয়েন্টগুলিকে পুনরাবৃত্তভাবে বরাদ্দ করে, যা এই ডেটা পয়েন্টগুলিকে ডেটা পয়েন্টের সর্বোচ্চ ঘনত্বের দিকে স্থানান্তর করার মাধ্যমে করা হয়৷
ডেটা পয়েন্টের এই উচ্চ ঘনত্বকে ক্লাস্টারের সেন্ট্রোয়েড বলা হয়। গড় শিফট অ্যালগরিদম এবং K মানে ক্লাস্টারিংয়ের মধ্যে পার্থক্য হল যে পূর্বে (K−মানে) ক্লাস্টারের সংখ্যা আগে থেকেই নির্দিষ্ট করা প্রয়োজন৷
এর কারণ হল K এর সাহায্যে ক্লাস্টারের সংখ্যা পাওয়া যায় মানে উপস্থিত ডেটার উপর ভিত্তি করে অ্যালগরিদম।
আসুন আমরা মিন-শিফ্ট অ্যালগরিদমের ধাপগুলি বুঝতে পারি -
-
ডেটা পয়েন্টগুলি নিজস্ব একটি ক্লাস্টারে বরাদ্দ করা হয়৷
৷ -
তারপর, এই ক্লাস্টারগুলির সেন্ট্রোয়েডগুলি নির্ধারণ করা হয়।
-
এই সেন্ট্রোয়েডগুলির অবস্থান পুনরাবৃত্তভাবে আপডেট করা হয়।
-
এরপরে, প্রক্রিয়াটি উচ্চ ঘনত্বের অঞ্চলে চলে যায়।
-
একবার সেন্ট্রোয়েডগুলি এমন একটি অবস্থানে পৌঁছালে যেখানে তারা আর অগ্রসর হতে পারে না, প্রক্রিয়াটি বন্ধ হয়ে যায়।
আসুন আমরা বুঝতে পারি যে কিভাবে এটি sikit−learn −
ব্যবহার করে পাইথনে প্রয়োগ করা যেতে পারেউদাহরণ
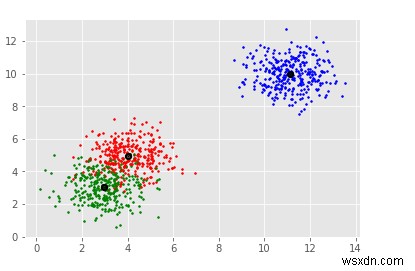
sklearn.datasets.samples_generator থেকে sklearn.datasets.samples_generator import make_blobscenters, =[[3,] 1 5],[11,10,10]]X, _ =make_blobs(n_samples =950, centers =centers, cluster_std =0.89)plt.title("Man-Shift অ্যালগরিদমের বাস্তবায়ন")plt.xlabel("X-axis) ")plt.ylabel("Y-axis")plt.scatter(X[:,0],X[:,1])plt.show()ms =MeanShift()ms.fit(X)লেবেল =ms. labels_clusterCent =ms.cluster_centers_print(clusterCent)numCluster =len(np.unique(লেবেল))মুদ্রণ("আনুমানিক ক্লাস্টার:", numCluster)রং =10*['r.','g.','b.',' c.','k.','y.','m.']এর জন্য i রেঞ্জে(len(X)):plt.plot(X[i][0], X[i][1], রং[লেবেল[i]], মার্কারসাইজ =3)plt.scatter(clusterCent[:,0],clusterCent[:,1], marker=".",color='k', s=20, লাইনউইথ =5, zorder=10)plt.show()আউটপুট
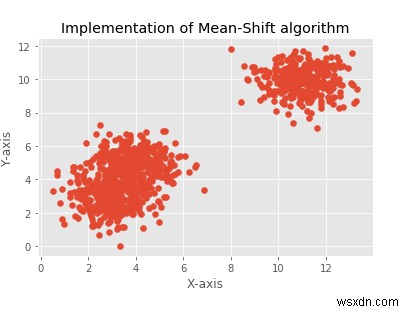
[[ 3.05250924 3.03734994 1.06159541][ 3.92913017 4.99956874 4.86668482][10.99127523 10.02361123 10.02361123 পূর্বে
ব্যাখ্যা
-
প্রয়োজনীয় প্যাকেজগুলি আমদানি করা হয় এবং এটির উপনাম ব্যবহার সহজ করার জন্য সংজ্ঞায়িত করা হয়৷
-
'স্টাইল' ক্লাসে উপস্থিত 'ব্যবহার' ফাংশনের জন্য 'ggplot' নির্দিষ্ট করা হয়েছে।
-
'make_blobs' ফাংশনটি ডেটার ক্লাস্টার তৈরি করতে ব্যবহৃত হয়।
-
set_xlabel, set_ylabel এবং set_title ফাংশনগুলি 'X' অক্ষ, 'Y' অক্ষ এবং শিরোনামের জন্য লেবেল প্রদান করতে ব্যবহৃত হয়।
-
'MeanShift' ফাংশন বলা হয়, এবং একটি ভেরিয়েবলকে বরাদ্দ করা হয়।
-
ডেটা মডেলের সাথে মানানসই৷
৷ -
লেবেল এবং ক্লাস্টার সংখ্যা সংজ্ঞায়িত করা হয়।
-
এই ডেটা প্লট করা হয়, এবং মডেলের সাথে মানানসই ডেটার জন্য স্ক্যাটার প্লটও প্রদর্শিত হয়৷
-
এটি 'শো' ফাংশন ব্যবহার করে কনসোলে দেখানো হয়।
