সিবোর্নের স্যাক্টারপ্লটটি বেশ কয়েকটি শব্দার্থিক গ্রুপিংয়ের সম্ভাবনা সহ একটি বিক্ষিপ্ত প্লট আঁকতে ব্যবহৃত হয়। এর জন্য seaborn.scatterplot() ব্যবহার করা হয়।
ধরা যাক নিম্নলিখিতটি একটি CSV ফাইলের আকারে আমাদের ডেটাসেট - Cricketers.csv
প্রথমে, প্রয়োজনীয় 3টি লাইব্রেরি আমদানি করুন -
import seaborn as sb import pandas as pd import matplotlib.pyplot as plt
একটি পান্ডাস ডেটাফ্রেম -
-এ একটি CSV ফাইল থেকে ডেটা লোড করুনdataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\Cricketers.csv")
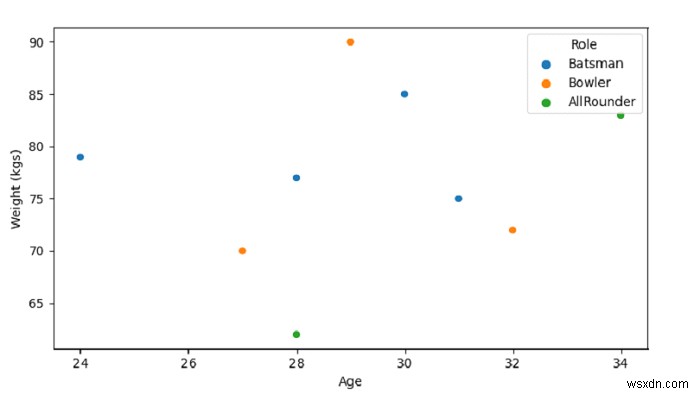
বয়স এবং ওজন (কেজি) সহ স্ক্যাটারপ্লট প্লট করা। হিউ প্যারামিটার "ভূমিকা" −
হিসাবে সেট করা হয়েছেsb.scatterplot(dataFrame['Age'],dataFrame['Weight'], hue=dataFrame['Role'])
উদাহরণ
নিম্নলিখিত কোড -
pdimport matplotlib.pyplot হিসাবে sbimport পান্ডা হিসাবেimport seaborn as sb
import pandas as pd
import matplotlib.pyplot as plt
# Load data from a CSV file into a Pandas DataFrame:
dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\Cricketers.csv")
# plotting scatterplot with Age and Weight (kgs)
# hue parameter set as "Role"
sb.scatterplot(dataFrame['Age'],dataFrame['Weight'], hue=dataFrame['Role'])
plt.ylabel("Weight (kgs)")
plt.show() আউটপুট
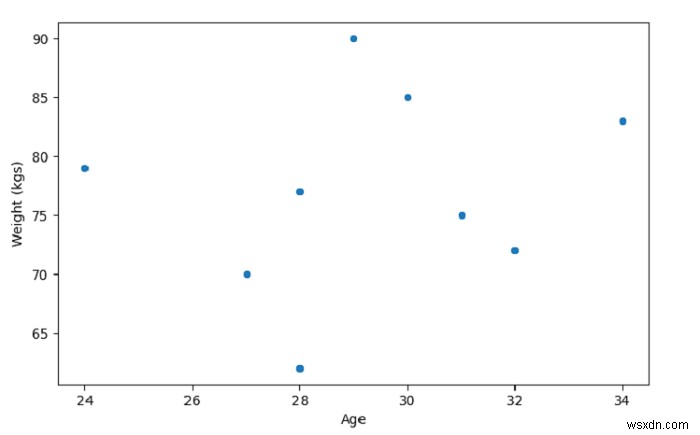
এটি নিম্নলিখিত উদাহরণ তৈরি করবে -
উদাহরণ
আসুন আমরা আরেকটি উদাহরণ দেখি, যেখানে আমরা হিউ প্যারামিটার সেট করিনি। নিম্নলিখিত কোড -
pdimport matplotlib.pyplot হিসাবে sbimport পান্ডা হিসাবেimport seaborn as sb
import pandas as pd
import matplotlib.pyplot as plt
# Load data from a CSV file into a Pandas DataFrame:
dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\Cricketers.csv")
# plotting scatterplot with Age and Weight
# weight in kgs
sb.scatterplot(dataFrame['Age'],dataFrame['Weight'])
plt.ylabel("Weight (kgs)")
plt.show() এ বয়স এবং ওজন সহ # প্লটিং স্ক্যাটারপ্লট আউটপুট
এটি নিম্নলিখিত আউটপুট −
তৈরি করবে