
আমার এখনও বাচ্চা নেই, কিন্তু যখন আমি করি, আমি চাই তারা দুটি জিনিস শিখুক:
- ব্যক্তিগত অর্থ
- মেশিন লার্নিং
আপনি বিশ্বাস করুন বা না করুন যে সিঙ্গুলারিটি কাছাকাছি, এটি অস্বীকার করার কিছু নেই যে বিশ্ব ডেটার উপর চলে। সেই ডেটা কীভাবে জ্ঞানে রূপান্তরিত হয় তা বোঝা আজকাল বয়সে আসা যে কারও জন্য গুরুত্বপূর্ণ - এবং আরও বেশি ডেভেলপারদের জন্য।
এটি একটি সিরিজের প্রথম নিবন্ধ যা সম্পূর্ণ-স্ট্যাক রুবি বিকাশকারীদের কাছে মেশিন লার্নিং (এমএল) অ্যাক্সেসযোগ্য করার চেষ্টা করবে। আপনার নিষ্পত্তিতে ML সরঞ্জামগুলি বোঝার মাধ্যমে, আপনি আপনার স্টেকহোল্ডারদের আরও ভাল সিদ্ধান্ত নিতে সাহায্য করতে সক্ষম হবেন। ভবিষ্যত নিবন্ধগুলি পৃথক কৌশল এবং ব্যবহারিক উদাহরণগুলিতে ফোকাস করবে, তবে এই একটিতে, আমরা স্টেজ সেট করছি – আপনাকে একটি মানচিত্র দেখাচ্ছি এবং একটি পিন রাখছি যা বলে "আপনি এখানে আছেন।"
নম্র শুরু

কৃত্রিম বুদ্ধিমত্তা (AI) এবং মেশিন লার্নিং নতুন কিছু নয়। 1950 এর দশকে, আর্থার স্যামুয়েল একটি কম্পিউটার প্রোগ্রাম তৈরি করেছিলেন যা চেকার খেলতে পারে। তিনি "আলফা-বিটা ছাঁটাই" ব্যবহার করেছিলেন - একটি সাধারণ অনুসন্ধান অ্যালগরিদম।
1960-এর দশকে বহু-স্তরযুক্ত নিউরাল নেটওয়ার্ক এবং নিকটতম-প্রতিবেশী অ্যালগরিদমের আবির্ভাব ঘটে, যা গুদামগুলিতে সর্বোত্তম পথ খুঁজে পেতে ব্যবহৃত হয়৷
তাই যদি AI এত পুরানো হয়, তাহলে AI স্টার্টআপগুলি এত ট্রেন্ডি কেন? আমার মতে, এর দুটি কারণ রয়েছে:
- কম্পিউটিং ক্ষমতা (মুরের আইন দেখুন)
- প্রতিদিন ইন্টারনেটে যে পরিমাণ ডেটা যোগ করা হচ্ছে
দৈনিক ভিত্তিতে তৈরি হওয়া ডেটার পরিমাণের সাথে সম্পর্কিত দুটি পরিসংখ্যান রয়েছে যেগুলি সম্পর্কে যখনই আমি চিন্তা করি তখনই আমার মন উড়িয়ে দেয়:
- 2018 সালের হিসাবে, আমরা প্রতিদিন 2.5 কুইন্টিলিয়ন বাইট ডেটা তৈরি করছি। ফোর্বসের এই নিবন্ধটি প্রকাশিত হওয়ার পর থেকে এই সংখ্যাটি বেড়েছে তাতে সন্দেহ নেই।
- শুধুমাত্র গত দুই বছরে, বিশ্বের 90% ডেটা তৈরি হয়েছে।
একসাথে, এর অর্থ হল (1) ডেটা সঞ্চয় করার জন্য এবং অ্যালগরিদমগুলি চালানোর জন্য প্রয়োজনীয় হার্ডওয়্যারগুলি আরও সাশ্রয়ী হতে চলেছে এবং (2) ML মডেলগুলিকে প্রশিক্ষণ দেওয়ার জন্য উপলব্ধ ডেটার পরিমাণ একটি পাগল-দ্রুত গতিতে বাড়ছে৷
প্রতিদিন আমরা কৃত্রিম বুদ্ধিমত্তা এবং মেশিন লার্নিংয়ের জগতের সাথে যোগাযোগ করছি, প্রভাবিত হচ্ছি এবং অবদান রাখছি। উদাহরণস্বরূপ, আপনি নিম্নলিখিতগুলির জন্য অ্যালগরিদমকে ধন্যবাদ (বা দোষারোপ) করতে পারেন:
- আপনার ক্রেডিট লাইন
- অসুখ নির্ণয়ে সাহায্য করা
- এমনও হতে পারে যে আপনি চাকরি পেয়েছেন বা না পেয়েছেন
- বর্তমান ট্রাফিক অবস্থার প্রেক্ষিতে সবচেয়ে কার্যকরী রুট খুঁজে পেতে সাহায্য করে
- অ্যালেক্সা বুঝতে পারছেন আপনি ঠিক কি বলতে চাচ্ছেন যখন আপনি তাকে বলবেন আপনি এইমাত্র হাঁচি দিয়েছেন
- Spotify আপনাকে আপনার নতুন প্রিয় গানের সাথে পরিচয় করিয়ে দিচ্ছে
আমার কাল্পনিক ভবিষ্যৎ বাচ্চাদের প্রতিপালনের কারণ হল:আমি তাদের বুঝতে চাই যে কীভাবে তাদের ডিজিটাল জীবন তাদের "বাস্তব" জীবনকে প্রভাবিত করে, তাদের ডেটা গোপনীয়তার সিদ্ধান্তের প্রভাব, এবং কখন তাদের মেশিনে বিশ্বাস করা উচিত সে সম্পর্কে তাদের নিজস্ব মতামত কীভাবে তৈরি করা যায়। বনাম যখন তাদের উচিত নয়।
এই পোস্টের বাকি অংশে, আমি যে তিন ধরনের মেশিন লার্নিং নিয়ে অধ্যয়ন করেছি তার একটি সংক্ষিপ্ত বিবরণ দিতে চাই:তত্ত্বাবধানে শিক্ষা, তত্ত্বাবধানহীন লার্নিং এবং রিইনফোর্সমেন্ট লার্নিং। প্রতিটি পদ্ধতিকে কী অনন্য করে তোলে এবং প্রতিটি সমস্যা সমাধানে বিশেষভাবে ভালো হয় সে বিষয়ে আমরা কথা বলব।
তত্ত্বাবধান করা শিক্ষা
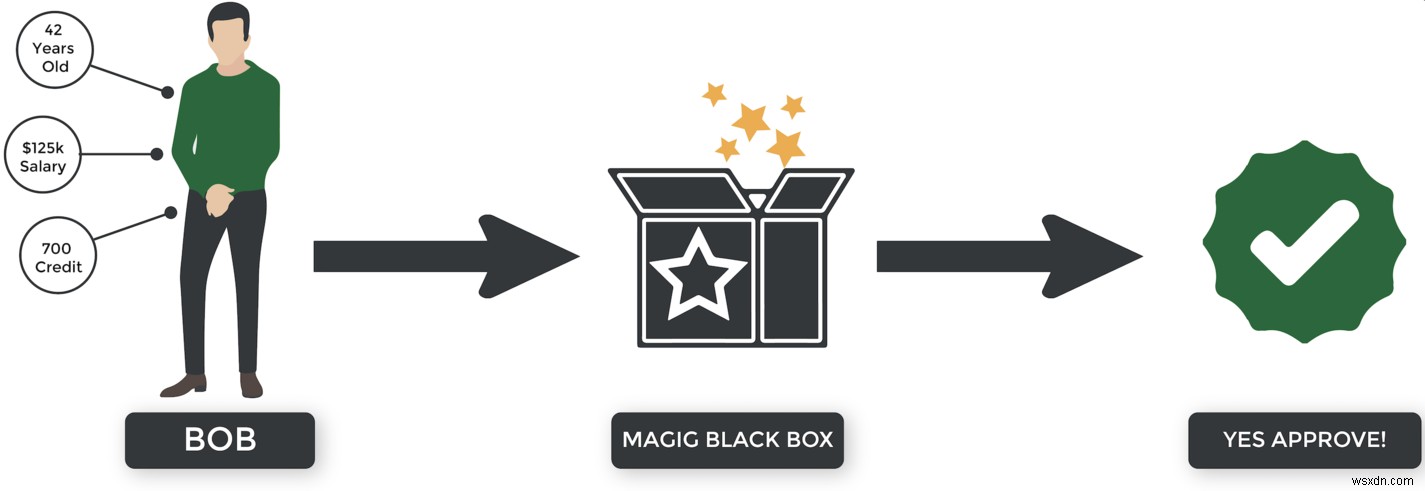
তত্ত্বাবধানে শিক্ষা... ভাল, মানুষের তত্ত্বাবধানে। :) কল্পনা করুন যে আমরা একটি তত্ত্বাবধানে শিক্ষাব্যবস্থা তৈরি করছি যাতে সিদ্ধান্ত নেওয়া যায় যে কে একটি বন্ধকের জন্য অনুমোদিত হবে। এটি কীভাবে কাজ করতে পারে তা এখানে:
- ব্যাঙ্ক একটি ডেটাসেট সংকলন করে যা গ্রাহকের গুণাবলী (বয়স, বেতন, ইত্যাদি) ফলাফলের (ঋণ পরিশোধ, ডিফল্ট, ইত্যাদি) ম্যাপ করে।
- আমরা ডেটা ব্যবহার করে আমাদের সিস্টেমকে প্রশিক্ষণ দিই।
- একজন আবেদনকারীর বৈশিষ্ট্যের উপর ভিত্তি করে ভবিষ্যৎ ফলাফল অনুমান করতে সিস্টেমটি যা শিখে তা ব্যবহার করে।
- যদি অ্যালগরিদম সঠিকভাবে অনুমান করে, আমরা এটিকে বলি, "দারুণ কাজ! আপনি ঠিক বলেছেন।" কিন্তু যদি এটি ভুল হয়, আমরা এটিকে বলি, "না, আপনি ভুল। অনুগ্রহ করে উন্নতি করুন এবং আবার চেষ্টা করুন।"
এই উদাহরণটিকে একটি "শ্রেণীবিন্যাস" সমস্যা হিসাবে বিবেচনা করা হয় কারণ অ্যালগরিদমের আউটপুট একটি বিভাগ - এই ক্ষেত্রে, অনুমোদিত বা অনুমোদিত নয়৷ শ্রেণীবিন্যাস সমস্যার অন্যান্য উদাহরণের মধ্যে রয়েছে কিনা তা নির্ধারণ করা:
- একজন ব্যক্তির একটি অসুস্থতা আছে
- এক্স-রেতে একটি হাড় ভাঙা আছে
- একটি ই-মেইল স্প্যাম
আপনি যদি ML শ্রেণীবিভাগের অ্যালগরিদমগুলির পিছনের গণিত সম্পর্কে আরও জানতে আগ্রহী হন, Google এর যেকোনও একটি করুন:নিষ্পাপ বেইস ক্লাসিফায়ার, সমর্থন ভেক্টর মেশিন, লজিস্টিক রিগ্রেশন, নিউরাল নেটওয়ার্ক, এলোমেলো বন।
শ্রেণীবিভাগের সমস্যাগুলি যা "হ্যাঁ/না" ফলাফল প্রদান করে, তত্ত্বাবধানে থাকা শিক্ষাকে রিগ্রেশন সমস্যা সমাধানের জন্যও ব্যবহার করা যেতে পারে - এখানে, আমরা একটি ধারাবাহিক স্কেলে একটি ভবিষ্যদ্বাণী করি, উদাহরণস্বরূপ:
- একটি স্টকের ভবিষ্যৎ মূল্য
- নিউ ইংল্যান্ড প্যাট্রিয়টস সুপার বোল জেতার সম্ভাবনা
- গড় বেতন একটি কোম্পানি তাদের গ্রহণ করার জন্য একটি প্রার্থীর প্রস্তাব করতে হবে
তত্ত্বাবধানে থাকা রিগ্রেশন সমস্যার জন্য ব্যবহৃত অ্যালগরিদমের উদাহরণগুলির মধ্যে রয়েছে রৈখিক রিগ্রেশন, নন-লিনিয়ার রিগ্রেশন এবং বায়েসিয়ান লিনিয়ার রিগ্রেশন।
আনসুপারভাইসড লার্নিং
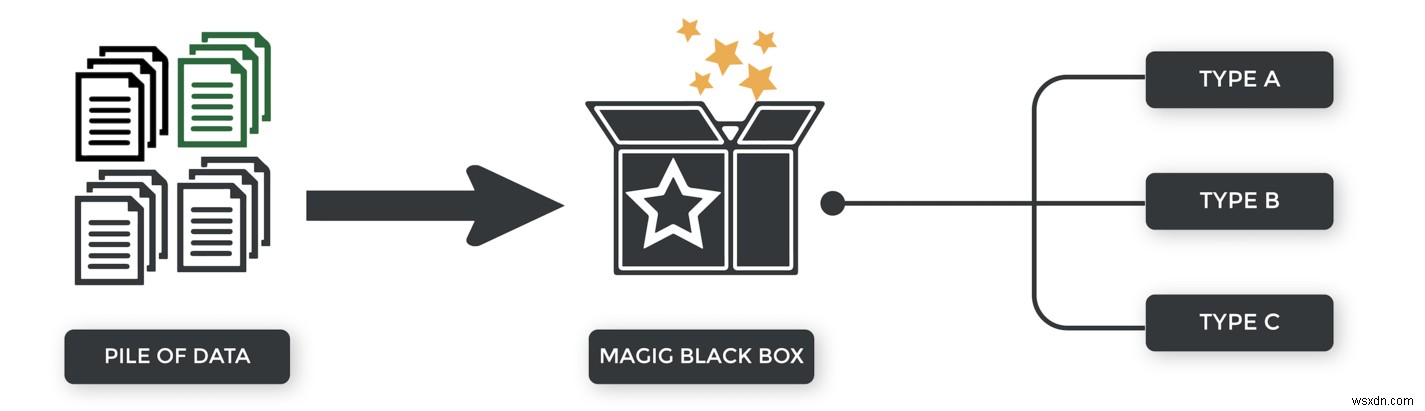
আমাদের তত্ত্বাবধানে শেখার উদাহরণ সহ, আমরা শ্রেণীবিভাগের বিভাগগুলি পূর্বনির্ধারিত করেছি। বন্ধকী আবেদনকারী হয় অনুমোদিত বা অস্বীকার করা হয়েছে.
তত্ত্বাবধানহীন শিক্ষার সাথে, আমরা বিভাগগুলি প্রদান করি না। তারা আমাদের কাছে উপলব্ধ নয়। অ্যালগরিদমকে অবশ্যই তার নিজস্ব সিদ্ধান্তে আসতে হবে।
কেন আমরা একটি unsupervised পদ্ধতি ব্যবহার করতে চাই?
1) কখনও কখনও আমরা আগে থেকে বিভাগ জানি না. ইন্টারনেটের চারপাশে ভাসমান বেশিরভাগ ডেটা অসংগঠিত - যেমন, লেবেলের অভাব৷
2) অন্য সময়, আমরা জানি না আমরা কী খুঁজছি, তাই আমরা অ্যালগরিদমকে এমন প্যাটার্ন/বৈশিষ্ট্য খুঁজে পেতে বলতে পারি যা শ্রেণীকরণের জন্য উপযোগী হতে পারে।
মেশিন লার্নিং দিয়ে অসংগঠিত ডেটা পরিচালনা করার আরেকটি উপায় হ'ল মানুষকে এটি দেখতে এবং ম্যানুয়ালি লেবেল করা। অনেক কোম্পানি আছে যারা ম্যানুয়ালি ডেটা শ্রেণীবদ্ধ করার জন্য কর্মী নিয়োগ করে:লেবেল ডেটা।
নিরীক্ষণহীন শিক্ষার পদ্ধতি
দুটি কৌশল যা সাধারণত তত্ত্বাবধানহীন শিক্ষায় ব্যবহৃত হয় তা হল অ্যাসোসিয়েশন এবং ক্লাস্টারিং .
অ্যাসোসিয়েশন: কল্পনা করুন যে আপনি আমাজন। আপনার কাছে প্রচুর গ্রাহকের ডেটা, কেনাকাটার ইতিহাস ইত্যাদি রয়েছে৷ তত্ত্বাবধানহীন শিক্ষা ব্যবহার করে, আপনি গ্রাহকদেরকে "ক্রেতাদের প্রকার"-এ বিভক্ত করতে পারেন - হয়ত বুঝতে পেরেছেন যে যারা গোলাপী ছাতা কেনেন তাদের ম্যাচা চা কেনার সম্ভাবনা বেশি৷
ক্লস্টারিং: ক্লাস্টারিং আপনার ডেটা দেখে এবং একটি নির্দিষ্ট সংখ্যক গ্রুপ বা ক্লাস্টারে বিভাজন করে। উদাহরণস্বরূপ, হতে পারে আপনার কাছে একগুচ্ছ আবাসন ডেটা রয়েছে এবং আপনি দেখতে চান এমন কোনও বৈশিষ্ট্য (সম্ভবত অপরাধের ডেটা?) আছে কিনা যা বাড়িটি কোন আশেপাশে রয়েছে তা অনুমান করতে পারে। যেমন, এই নিবন্ধটি কি টেনিস, রান্না বা স্থান সম্পর্কে?)
আপনি যদি সুনির্দিষ্ট তত্ত্বাবধানহীন শেখার কৌশলগুলি সম্পর্কে আরও জানতে আগ্রহী হন, Google অনুসন্ধান k- মানে ক্লাস্টারিং, কোসাইন সাদৃশ্য, শ্রেণীবিন্যাস ক্লাস্টারিং, এবং k- নিকটবর্তী-প্রতিবেশী ক্লাস্টারিং।
রিইনফোর্সমেন্ট লার্নিং

মেশিন লার্নিংয়ের এই উপসেটটি সাধারণত গেমগুলিতে ব্যবহৃত হয় কারণ এটি লক্ষ্য-ভিত্তিক অ্যালগরিদম ব্যবহার করে। তত্ত্বাবধানে শিক্ষার বিপরীতে, প্রতিটি সিদ্ধান্ত স্বাধীন নয় - একটি বর্তমান ইনপুট দেওয়া হলে, অ্যালগরিদম একটি সিদ্ধান্ত নেয় এবং পরবর্তী ইনপুট এই সিদ্ধান্তের উপর নির্ভর করে .
ঠিক যেমন আমি আমার কুকুরের মাথায় একটা থাপ্পড় দিই যখন সে অবিরাম ঘেউ ঘেউ করা বন্ধ করে দেয় যখন দরজার বেল বাজে বা যখন সে বন্ধ না করে তখন তাকে তার ক্যানেলে রেখে দেই, লক্ষ্য-অনুকূল করার সিদ্ধান্ত নেওয়ার সময় শক্তিবৃদ্ধি অ্যালগরিদমগুলিকে পুরস্কৃত করা হয় (যেমন, স্কোর করা পয়েন্টের সর্বোচ্চ সংখ্যক) এবং একটি দরিদ্র করার সময় জরিমানা করা হয়।
শক্তিবৃদ্ধি শেখার অ্যালগরিদমগুলির জন্য সুস্পষ্ট অ্যাপ্লিকেশনগুলির মধ্যে রয়েছে:
- চেস এবং গো-এর মতো গেম (আমি নেটফ্লিক্সে আলফাগো ডকুমেন্টারির সুপারিশ করছি, যদি আপনি এটি ইতিমধ্যেই না দেখে থাকেন।)
- রোবোটিক্স (কাঙ্খিত কাজগুলি সম্পূর্ণ করতে বট শেখানো)
- স্বায়ত্তশাসিত যানবাহন
- রোবো-উপদেষ্টা যারা স্টক মার্কেটকে হারাতে প্রশিক্ষিত
আপনি যদি রিইনফোর্সমেন্ট লার্নিং, গুগল সার্চ Q-লার্নিং, স্টেট-অ্যাকশন-রিওয়ার্ড-স্টেট-অ্যাকশন (SARSA), DQN, এবং অ্যাসিঙ্ক্রোনাস সুবিধা অভিনেতা সমালোচকের পিছনে অ্যালগরিদম সম্পর্কে আরও জানতে আগ্রহী হন।
উপসংহার
আমি আশা করি যে এই উদাহরণগুলি আপনাকে মেশিন লার্নিং কৌশলগুলি বুঝতে সাহায্য করেছে এবং আমরা যে আজকে বাস করছি সেই পাগল বিশ্বকে প্রভাবিত করতে কীভাবে প্রতিটি ব্যবহার করা হয়। যদিও আমি মাঝে মাঝে নিজেকে শেখার মতো সমস্ত কিছু নিয়ে অভিভূত দেখতে পাই, কোথাও শুরু করা কিছুই না করার চেয়ে ভাল, এবং মনে রাখবেন যে এর অনেক কিছুই আসলে একেবারেই নতুন নয় - আমরা কেবল এটি সম্পর্কে আরও শুনছি কারণ ডেটা আরও উপলব্ধ এবং প্রক্রিয়াকরণ হচ্ছে শক্তি সস্তা।
