
পুনরুদ্ধার-বর্ধিত প্রজন্ম বাহ্যিক জ্ঞানের সাথে বৃহৎ ভাষার মডেলগুলিকে বৃদ্ধি করার কথা। এটি ডেমোতে সুন্দরভাবে কাজ করতে পারে:একটি ছোট কিউরেটেড ডেটাসেট, পরিষ্কার ক্যোয়ারী এবং একটি সীমাবদ্ধ লেটেন্সি বাজেট জ্ঞানী, গ্রাউন্ডেড উত্তর দেয় যা ব্যবহারকারীরা সঠিক বলে মনে করেন। যাইহোক, অনেক দল দেখতে পায় যে একবার তারা ব্যবহারকারীদের কাছে তাদের RAG অ্যাপ্লিকেশন স্থাপন করলে, কর্মক্ষমতা ধসে পড়ে। প্রশ্নগুলি অস্পষ্ট হয়ে যায়, কর্পাস প্রসারিত হয়, পুনরুদ্ধারের গুণমান হ্রাস পায়, লেটেন্সি বেলুন এবং সিস্টেমটি নিঃশব্দে নির্ভুলভাবে বিবর্ণ হতে শুরু করে। আরও খারাপ, দুর্বল মূল্যায়ন কৌশলগুলি লুকিয়ে রাখে যেখানে ব্যবহারকারীরা অভিযোগ না করা পর্যন্ত সিস্টেমটি আসলে ব্যর্থ হতে শুরু করে। এই নিবন্ধটি কারণ অনুসন্ধান করে কেন অনেক RAG সিস্টেম উৎপাদনে ব্যর্থ হয়। আমরা সাম্প্রতিক গবেষণা এবং শিল্প নির্দেশিকা থেকে আঁকা. আমরা ব্যর্থতার মোডের একটি শৃঙ্খলে লিঙ্ক হিসাবে পুনরুদ্ধারের গুণমান, লেটেন্সি ট্রেড-অফ, এম্বেডিং ড্রিফ্ট এবং মূল্যায়নের ফাঁকগুলির চারপাশে সমস্যাগুলি ফ্রেম করি। এই চেইনের প্রতিটি লিঙ্ককে অবশ্যই একটি শক্তিশালী উৎপাদন RAG সিস্টেম তৈরি করতে হবে।
প্রধান টেকওয়ে
- অধিকাংশ RAG ব্যর্থতা পুনরুদ্ধারে শুরু হয়, প্রজন্ম নয়। যখন সিস্টেমটি অসম্পূর্ণ, অপ্রাসঙ্গিক, বা খারাপভাবে র্যাঙ্ক করা প্রমাণ পুনরুদ্ধার করে, এমনকি একটি শক্তিশালী LLM দুর্বল উত্তর তৈরি করবে৷
- ভাল পুনরুদ্ধারের জন্য আরও ভালো ইঞ্জিনিয়ারিং পছন্দ প্রয়োজন৷৷ প্রাসঙ্গিকতা উন্নত করতে এবং নীরব পুনরুদ্ধার ব্যর্থতা কমাতে মূল কৌশল হিসেবে ডোমেন-সচেতন চাঙ্কিং, হাইব্রিড পুনরুদ্ধার এবং পুনঃর্যাঙ্কিং উপস্থাপন করা হয়৷
- লেটেন্সি দ্রুত উৎপাদনে বাধা হয়ে দাঁড়ায়৷৷ বৃহত্তর top_k, rerankers, দীর্ঘ প্রসঙ্গ, এবং অতিরিক্ত পুনরুদ্ধারের পদক্ষেপগুলি যোগ করার ফলে প্রত্যাহারের উন্নতি হতে পারে, তবে এটি প্রকৃত ব্যবহারকারীদের জন্য সিস্টেমটিকে খুব ধীর করে দিতে পারে।
- এম্বেডিং ড্রিফ্ট নিঃশব্দে সময়ের সাথে কর্মক্ষমতা হ্রাস করে৷৷ এমবেডিং মডেল, নথি সংগ্রহ এবং ব্যবহারকারীর শব্দভান্ডারের পরিবর্তনগুলি পুনরুদ্ধারের আচরণকে পরিবর্তন করতে পারে, তাই সংস্করণ এবং পর্যবেক্ষণযোগ্যতা প্রয়োজন৷
- একা চূড়ান্ত-উত্তরের গুণমান মূল্যায়নের জন্য যথেষ্ট নয়। দলগুলির পৃথক পুনরুদ্ধার এবং প্রজন্মের মেট্রিক্স, বাস্তবসম্মত পরীক্ষার সেট, চলমান পর্যবেক্ষণ, এবং প্রমাণ দুর্বল বা অনুপস্থিত হলে সিস্টেমের জন্য বিরত থাকার ক্ষমতা প্রয়োজন৷
দরিদ্র পুনরুদ্ধারের গুণমানের কারণে ব্যর্থতা
কম পুনরুদ্ধারের গুণমান হল উৎপাদনে মোতায়েন করার সময় RAG সিস্টেমের ব্যর্থতার সবচেয়ে ঘন ঘন কারণগুলির মধ্যে একটি। ডেভেলপাররা প্রায়ই ভুল/খারাপ উত্তরের জন্য এলএলএমকে দায়ী করে; যাইহোক, দোষটি সাধারণত পাইপলাইনের আগে থাকে। যদি সিস্টেমটি সম্পূর্ণ বা প্রাসঙ্গিক প্রমাণ পুনরুদ্ধার করতে না পারে, বা প্রমাণকে খারাপভাবে স্থান দেয়, এমনকি সেরা মডেলটিও একটি বিশ্বস্ত প্রতিক্রিয়া তৈরি করার সম্ভাবনা কম। পুনরুদ্ধারের গুণমানকে একটি পটভূমি পদক্ষেপের পরিবর্তে একটি প্রথম-শ্রেণীর ইঞ্জিনিয়ারিং উদ্বেগ হিসাবে বিবেচনা করা উচিত৷
এলএলএম একটি প্রশ্ন দেখার আগে বেশিরভাগ ব্যর্থতা ঘটে
স্ট্যান্ডার্ড পাইপলাইন ব্যবহারকারীর ক্যোয়ারী এম্বেড করে, একটি ভেক্টর স্টোর থেকে টপ-কে ডকুমেন্ট পুনরুদ্ধার করে এবং একটি LLM-এ পাঠায়। সেই পাইপলাইনের প্রতিটি তীর ব্যর্থতার সম্ভাব্য বিন্দু।
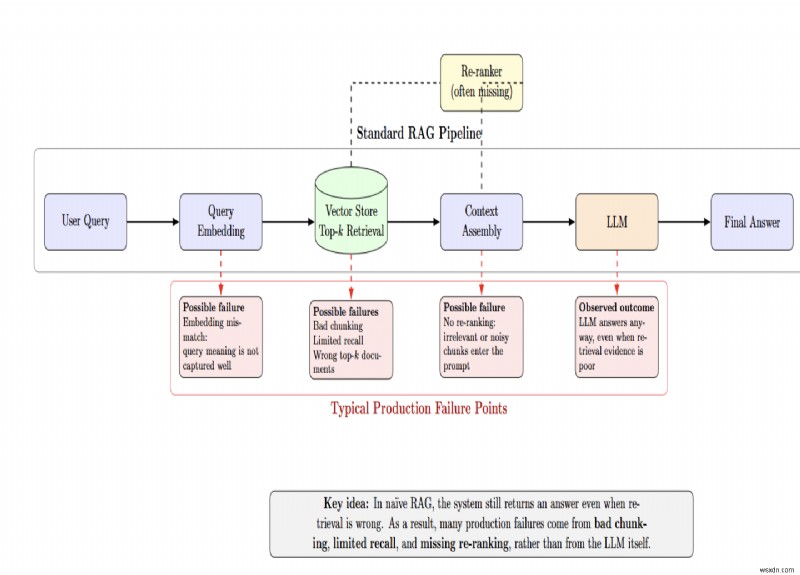
নিষ্পাপ RAG এই ব্যর্থতাগুলিকে অস্পষ্ট করে যেহেতু সিস্টেমটি একটি উত্তর প্রদান করে তা নির্বিশেষে পুনরুদ্ধারটি ভুল ছিল কিনা। অনেক উৎপাদন সমস্যা এলএলএম-এর ঘাটতিগুলির পরিবর্তে খারাপ চঙ্কিং কৌশল, সীমিত প্রত্যাহার এবং অনুপস্থিত পুনর্বিন্যাস থেকে উদ্ভূত হয়৷
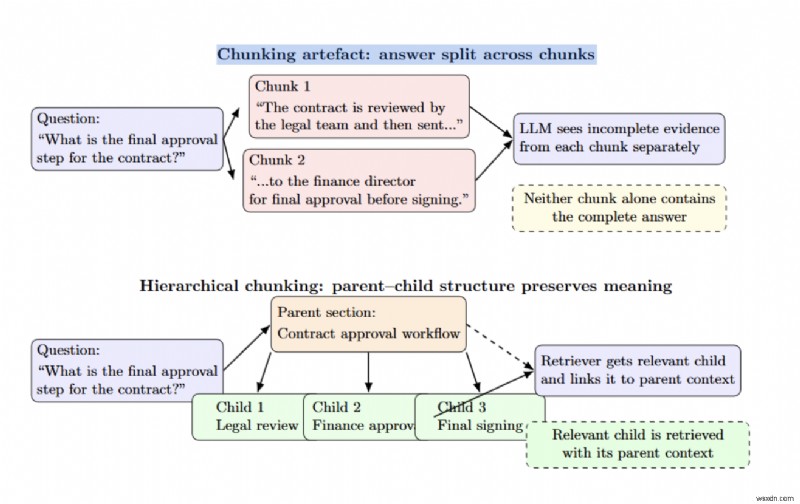
চঙ্কিং ভুলগুলি নীরব ব্যর্থতা তৈরি করে
খণ্ডের আকার নির্ভুলতা/প্রত্যাহারকে প্রভাবিত করে — বড় খণ্ডগুলি কম প্রাসঙ্গিকতার সাথে আরও প্রসঙ্গ সরবরাহ করে, যখন ছোট খণ্ডগুলি উচ্চ নির্ভুলতা প্রদান করে কিন্তু আশেপাশের তথ্য হারায়। হায়ারার্কিক্যাল (পিতা-মাতা-সন্তান) অংশগুলি সম্পূর্ণ অংশগুলিকে অভিভাবক খণ্ড হিসাবে সংরক্ষণ করে এবং শুধুমাত্র ছোট প্রাসঙ্গিক শিশু খণ্ডটি পুনরুদ্ধার করে এই ট্রেড-অফের সমাধান করে৷
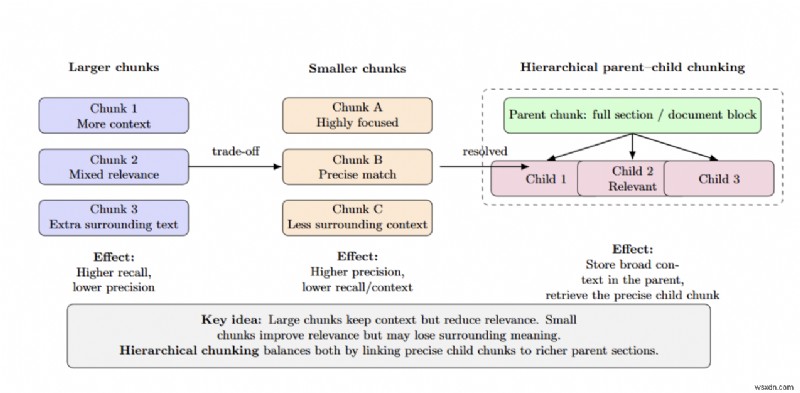
ইউনিভার্সিটি প্রেজেন্টেশন ডেকের উপর NVIDIA-এর অভ্যন্তরীণ পরীক্ষায় দেখা গেছে যে হায়ারার্কিক্যাল চাঙ্কিং উত্তরের নির্ভুলতাকে 61% থেকে স্থির-আকারের অংশগুলির সাথে 89%-এ উন্নতি করে। কাঠামোগত সীমানাকে সম্মান করার সময় এবং যেখানে সম্ভব ডোমেন-সচেতন বিভাজন প্রয়োগ করার সময় একটি উপযুক্ত খণ্ডের আকার বেছে নেওয়া গুরুত্বপূর্ণ।
হাইব্রিড পুনরুদ্ধার এবং পুনরায় র্যাঙ্কিং
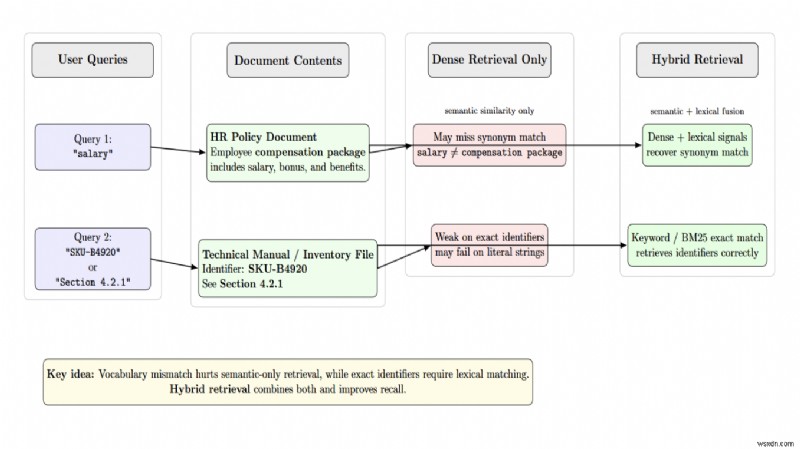
বিশুদ্ধ ঘন পুনরুদ্ধার শব্দার্থিক সাদৃশ্যে ভাল কিন্তু সঠিক শনাক্তকারী মিস করে। বিশুদ্ধ কীওয়ার্ড অনুসন্ধান সঠিক পদগুলির জন্য সংবেদনশীল, কিন্তু শব্দার্থিক প্যারাফ্রেজগুলিতে ব্যর্থ হয়। হাইব্রিড পুনরুদ্ধার সিস্টেমগুলি একই সাথে ঘন (ভেক্টর) পুনরুদ্ধার এবং স্পার্স (BM25/কীওয়ার্ড) পুনরুদ্ধার চালায়, তারপর তাদের ফলাফলগুলিকে পারস্পরিক র্যাঙ্ক ফিউশনের সাথে ফিউজ করে।
হাইব্রিড পুনরুদ্ধার ব্যবস্থা আভিধানিক মিল সংকেতগুলির সাথে শব্দার্থিক মিল সংকেতগুলিকে একত্রিত করে শব্দভান্ডারের অমিল সমাধান করে। ফিউশনের পরে রি-রেঙ্কার (ক্রস-এনকোডার) দিয়ে প্রার্থীর জোড়াকে পুনরুদ্ধার করা হলে তা স্মরণে উন্নতি করে। মূলত, পুনরুদ্ধার করা নথিগুলিকে পুনঃবিন্যাস করে যাতে কেবলমাত্র সবচেয়ে প্রাসঙ্গিক নথিগুলিই এটিকে সেই প্রসঙ্গে তৈরি করে যা LLM পর্যালোচনা করে। এটি টোকেন সীমা সংরক্ষণ করে এবং LLM প্রত্যাহার উন্নত করার সময় প্রসঙ্গ স্টাফিং এড়ায়৷
পুনরুদ্ধার মেট্রিক্স আলাদাভাবে পর্যবেক্ষণ করা আবশ্যক
দলগুলি শুধুমাত্র শেষ থেকে শেষ উত্তরের গুণমান পরিমাপ করে। পুনরুদ্ধারের নিজেই মেট্রিক রয়েছে যা আপনি ব্যবহার করতে পারেন:precision@k (পুনরুদ্ধার করা অংশগুলির কোন ভগ্নাংশ প্রাসঙ্গিক? ), recall@k (প্রাসঙ্গিক অংশগুলির কোন ভগ্নাংশ আপনি পুনরুদ্ধার করেছেন? ), মানে পারস্পরিক র্যাঙ্ক (প্রথম প্রাসঙ্গিক অংশটি কতটা উচ্চ ছিল?), এবং আপনার সমস্ত লাভ স্বাভাবিক করা হয়েছে র্যাঙ্কিং?)।

আপনি যদি এইগুলি পরিমাপ না করেন তবে আপনি জানতে পারবেন না যে ব্যর্থতাগুলি একটি খারাপ পুনরুদ্ধার বা খারাপ জেনারেটর থেকে। পরীক্ষার প্রশ্ন এবং গোল্ডেন ডেটাসেট আপনাকে অফলাইনে মূল্যায়ন করতে দেবে। আপনি যদি এই মেট্রিক্সগুলিকে বাস্তব প্রশ্নে ট্র্যাক করেন, আপনি উত্পাদন রিগ্রেশনগুলিকে পৃষ্ঠ করতে পারেন৷
উদাহরণ সহ পুনরুদ্ধার ব্যর্থতা নির্ণয়
অস্পষ্ট প্রশ্ন এবং শব্দভান্ডারের অমিল প্রায়শই ভুল পুনরুদ্ধার ঘটায়। একজন ব্যবহারকারী "বেতন" অনুসন্ধান করতে পারেন যখন নথিটি "ক্ষতিপূরণ প্যাকেজ" উল্লেখ করে। ঘন এম্বেডিং প্রতিশব্দ চিনতে ব্যর্থ হতে পারে, যখন হাইব্রিড পুনরুদ্ধার এটি সংশোধন করে। আরেকটি ক্ষেত্রে সঠিক মিলের জন্য, যেমন শনাক্তকারী। "SKU‑B4920" বা "বিভাগ 4.2.1"-এর জন্য একটি প্রশ্নের সঠিক আভিধানিক মিল প্রয়োজন৷
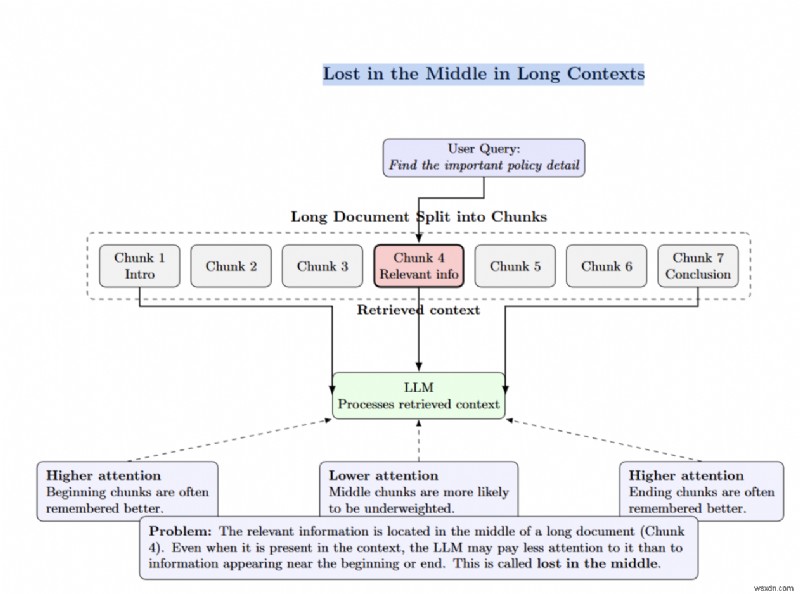
"মাঝখানে হারিয়ে যাওয়া" ঘটে যখন প্রাসঙ্গিক তথ্য একটি দীর্ঘ নথিতে গভীরভাবে সমাহিত হয়। LLM মধ্যম অংশে কম ওজনের টোকেন হবে।
একটি উত্তর দুটি খণ্ডে বিভক্ত হলে খণ্ডিত প্রত্নবস্তু তৈরি হয়, তাই কোনো খণ্ডে সম্পূর্ণ উত্তর থাকে না। হায়ারার্কিক্যাল চঙ্কিং পিতামাতা এবং শিশু নোডগুলিকে সংযুক্ত করে এটিকে প্রশমিত করতে সহায়তা করে৷
বিফলতার কারণে প্রকৃত সিস্টেমে বিস্ফোরিত হয়
লেটেন্সি হল একটি RAG সিস্টেম যা ডেমোতে কাজ করে প্রোডাকশনে লড়াই করার অন্যতম প্রধান কারণ। পুনরুদ্ধারের পাইপলাইনগুলি আরও পরিশীলিত হয়ে উঠলে, প্রতিক্রিয়ার সময়গুলি দ্রুত বাড়তে পারে এবং টিমগুলিকে ব্যবহারযোগ্যতার বিপরীতে উত্তরের গুণমান বাণিজ্য করতে বাধ্য করতে পারে৷
পুনরুদ্ধার–লেটেন্সি ট্রেড-অফ৷
উত্পাদন দলগুলিকে প্রায়শই পুনরুদ্ধারের গুণমান এবং তাদের বিলম্বিত বাজেটের ভারসাম্য বজায় রাখতে হবে। প্রতিক্রিয়া সময় বাড়ায় (top_k এর সাথে বড় হওয়া, হাইব্রিড পুনরুদ্ধার যোগ করা, পুনরায় র্যাঙ্কিং করা, বা দীর্ঘ-প্রসঙ্গ মডেল চালানো) সেই বাজেটগুলিতে কাটছাঁট করে। ট্রেড-অফ বিশেষত কঠিন কারণ ব্যবহারকারীরা প্রতিক্রিয়াশীল উত্তর আশা করে, এবং এন্টারপ্রাইজ ইন্টিগ্রেশন কঠোর লেটেন্সি বাজেটের সাথে আসে। যাইহোক, কর্নেল এবং NVIDIA-এর সাম্প্রতিক কাজ দেখায়, RAG-এর উপর উল্লেখযোগ্য লেটেন্সি হয়। খুব ঘন ঘন পুনরুদ্ধার চালানো নির্ভুলতা বাড়াতে পারে, কিন্তু শেষ থেকে শেষ লেটেন্সি প্রায় 30 সেকেন্ডে বৃদ্ধি করতে পারে—উৎপাদন ব্যবহারের জন্য খুব বেশি।
প্রজন্ম সাধারণত আধিপত্য বিস্তার করে, তবে পুনরুদ্ধারের বিষয়গুলি
RAGPerf এর সাথে বেঞ্চমার্কিং দেখায় যে প্রজন্ম প্রায়শই পাঠ্য-শুধু RAG পাইপলাইনের প্রভাবশালী অংশ . যদি পুনরুদ্ধারের গুণমান বজায় রাখা হয় তবে একটি ছোট এলএলএম বেছে নেওয়া উত্তরের গুণমানকে ত্যাগ না করেই বিলম্বকে মারাত্মকভাবে হ্রাস করতে পারে। মাল্টিমোডাল পাইপলাইনগুলির (পিডিএফ এবং চিত্র পুনরুদ্ধার) পুনঃর্যাঙ্কিং এবং সংশ্লিষ্ট ক্রস-মোডাল মডেলগুলির কারণে আংশিকভাবে বড় গণনা চাহিদা রয়েছে। ভেক্টর ডাটাবেসগুলি ধীর হলে বা একযোগে লুকআপের অনুমতি না দিলে পুনরুদ্ধারের বিলম্ব বাড়তে পারে। যাইহোক, এমনকি দ্রুত লুকআপের সাথেও, পুনঃর্যাঙ্কিং অনেক RAG কাজের চাপের জন্য মোট লেটেন্সিকে প্রাধান্য দিতে পারে।
লেটেন্সি, খরচ, এবং প্রসঙ্গ উইন্ডো
কিছু দল LLM এর প্রসঙ্গে top_k বাড়িয়ে বা আরও নথি ক্র্যাম করে প্রত্যাহার সমাধান করার চেষ্টা করে। স্টাডিজ দেখায় যে এর বিপরীত প্রভাব রয়েছে। আপনি প্রম্পটে যত বেশি নথি যোগ করবেন, LLM সঠিক তথ্য স্মরণ করতে তত কম সক্ষম হবে। পুনরুদ্ধার পুনঃর্যাঙ্কিং অনেক নথি পুনরুদ্ধার করে, তারপরে শুধুমাত্র এলএলএম-এর জন্য সেরাগুলি নির্বাচন করে এটি সমাধান করে। দীর্ঘ প্রসঙ্গ উইন্ডোগুলি "মাঝখানে হারিয়ে যাওয়া" এবং জ্যোতির্বিদ্যা সংক্রান্ত গণনামূলক খরচের কারণ।
অপ্টিমাইজিং লেটেন্সি৷
RAG সিস্টেমে লেটেন্সি অ্যাড্রেস করার জন্য সমগ্র পাইপলাইন জুড়ে ইচ্ছাকৃত অর্কেস্ট্রেশন প্রয়োজন:
এম্বেডিং ড্রিফ্ট এবং জ্ঞান পরিবর্তনের কারণে ব্যর্থতা
এম্বেডিংগুলি একে অপরের কাছাকাছি একই অর্থ সহ উচ্চ-মাত্রিক ভেক্টর হিসাবে পাঠ্যকে উপস্থাপন করে। দলগুলি প্রায়শই তাদের নথিগুলিকে একটি ভিন্ন এমবেডিং মডেলের সাথে পুনরায় এম্বেড করে বা তাদের সূচীকে সঠিকভাবে সংস্করণ না করে বা প্রাসঙ্গিকতা পরিবর্তনের বেঞ্চমার্ক না করে ক্যোয়ারী এনকোডারগুলিকে অদলবদল করে। নতুন মডেলটি উদ্দেশ্যমূলকভাবে শক্তিশালী হতে পারে, তবে এটি অপ্রত্যাশিত উপায়ে আশেপাশের কাঠামো পরিবর্তন করতে পারে যা র্যাঙ্কিং, প্রত্যাহার বা এমনকি ডোমেন-নির্দিষ্ট ভাষাকে প্রভাবিত করে। একটি মডেল যা সাধারণীকৃত বেঞ্চমার্কে শ্রেষ্ঠত্ব অর্জন করে তা আপনার বাস্তব-বিশ্বের এন্টারপ্রাইজ লিঙ্গো দিয়ে ভয়ঙ্করভাবে পারফর্ম করতে পারে।
প্রবাহের তিনটি কারণ
- মডেল ড্রিফ্ট৷৷ এমবেডিং মডেল ক্রমাগত আপডেট করা হয়. আপনি যখন এম্বেডিং মডেলের একটি সংস্করণ ব্যবহার করে নথিগুলিকে সূচী করেন, তখন আপনি অন্য মডেল থেকে এম্বেডিংয়ের মাধ্যমে সেগুলি অনুসন্ধান করতে পারবেন না। কর্পাস পুনঃসূচীকরণ না করে এম্বেডিং মডেল পরিবর্তন করা আপনার পুনরুদ্ধারকে প্রভাবিত করবে৷
- কর্পাস ড্রিফ্ট৷৷ আপনি যখন সূচীতে নতুন নথি যোগ করেন, বিশেষ করে নতুন ধরনের নথি, ভেক্টর স্থান পরিবর্তিত হয়। ঘন ভেক্টরের নতুন ক্লাস্টার উপস্থিত হয়। এই ঘন ক্লাস্টারগুলি প্রশ্নগুলি টানতে শুরু করে যা অন্যান্য নথির সাথে মিলে যাওয়া উচিত। ব্যবহারকারী-উত্পাদিত বা কোলাহলপূর্ণ বিষয়বস্তু যোগ করা সময়ের সাথে সাথে পুনরুদ্ধারের গুণমানকে হ্রাস করবে, এমনকি আপনি এমবেডিং মডেল পরিবর্তন না করলেও।
- কোয়েরি প্রবাহ। সময়ের সাথে সাথে ব্যবহারকারীদের শব্দভান্ডার প্রসারিত হয় এবং পরিবর্তন হয়। নতুন পরিভাষা ব্যবহারে আসে ("রিমোট ওয়ার্ক," "স্টেবলকয়েন," "প্রম্পট ইঞ্জিনিয়ারিং") এবং পুরানো পরিভাষা বিবর্ণ হয়ে যায়। প্রাক-বিদ্যমান এম্বেডিংগুলি এমন শব্দগুলির সাথে মেলে না যেগুলি প্রশিক্ষিত হওয়ার সময় বিদ্যমান ছিল না৷ যদি একটি কোম্পানি তার পণ্যগুলির একটির নাম পরিবর্তন করে, নতুন নামের অনুসন্ধান ব্যর্থ হয় কারণ এমবেডিংগুলি এখনও পুরানো নামকে প্রতিফলিত করে৷
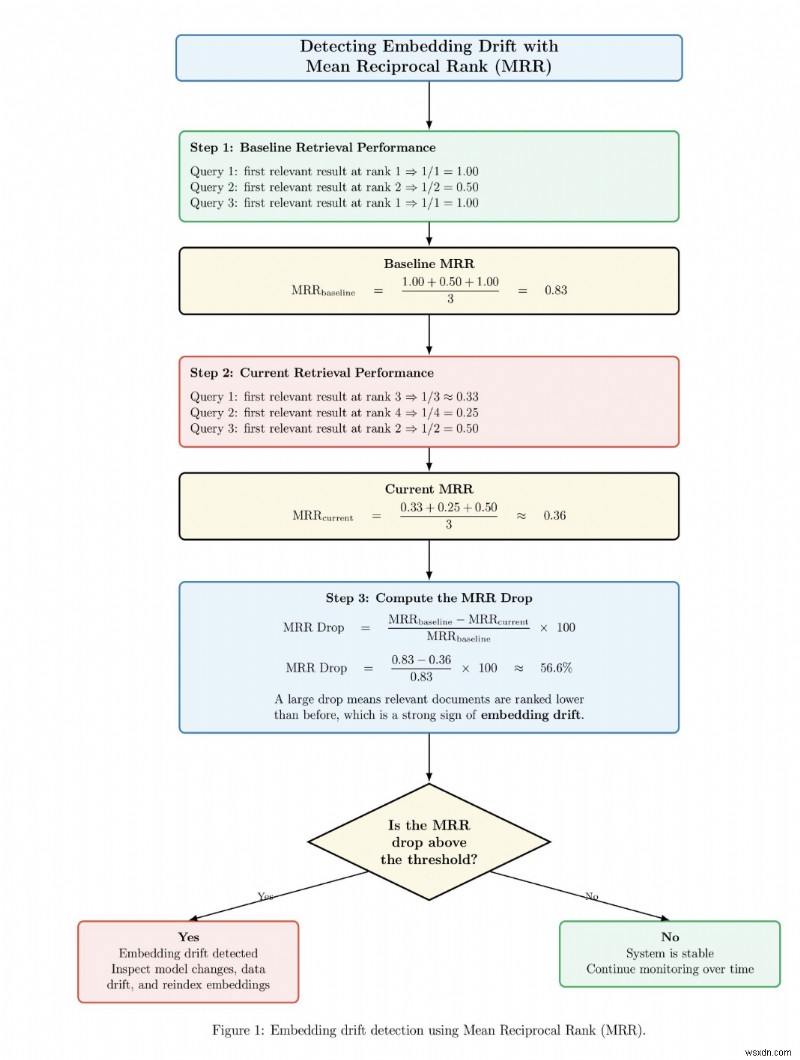
গড় পারস্পরিক র্যাঙ্ক সহ এমবেডিং ড্রিফ্ট সনাক্ত করা
সিস্টেম পরিবর্তনের আগে এবং পরে, বা সময়ের সাথে সাথে পুনরুদ্ধার কার্যক্ষমতার পরিবর্তনগুলি পর্যবেক্ষণ করে কীভাবে এমবেডিং ড্রিফ্ট সনাক্ত করা হয় তা নীচে একটি উদাহরণ চিত্র। ডায়াগ্রামটি প্রথমে একটি বেসলাইন এমআরআর স্কোর গণনা করে যেখানে প্রাসঙ্গিক নথিগুলি র্যাঙ্কিংয়ের শীর্ষের কাছে উপস্থিত হয়। তারপরে এটি একটি বর্তমান MRR স্কোর গণনা করে যেখানে প্রাসঙ্গিক নথিগুলিকে র্যাঙ্কিংয়ের আরও নীচে স্থান দেওয়া হয়। সিস্টেম তারপর বেসলাইন MRR এবং বর্তমান MRR এর মধ্যে শতাংশ ড্রপ গণনা করে। যদি MRR ড্রপ পূর্বনির্বাচিত থ্রেশহোল্ডের উপরে হয়, তাহলে সিস্টেম এমবেডিং ড্রিফটের জন্য একটি সতর্কতা জারি করে এবং এমবেডিং মডেল, ডেটা বিতরণ এবং সূচক পর্যালোচনা করার পরামর্শ দেয়। অন্যথায়, যদি ড্রপ থ্রেশহোল্ডের নীচে থাকে, তাহলে সিস্টেমটি নির্ধারণ করে যে পুনরুদ্ধার ব্যবস্থা স্থিতিশীল এবং পর্যবেক্ষণ অব্যাহত রাখে৷
এই কারণে, উত্পাদন RAG সিস্টেমগুলি স্পষ্টভাবে সংস্করণ এবং পর্যবেক্ষণযোগ্য হতে হবে। এমবেডিং সংস্করণ করা উচিত. সূচক বিল্ড ট্রেসযোগ্য হতে হবে. চাঙ্কিং নীতিটি নথিভুক্ত এবং পুনরুত্পাদনযোগ্য হওয়া উচিত। যদি গুণমান অবনমিত হতে শুরু করে, আপনি অবশ্যই প্রশ্নের উত্তর দিতে সক্ষম হবেন যেমন:কোন এমবেডিং মডেল এই সূচকটি তৈরি করেছে? কি খণ্ডিত নিয়ম বিষয়বস্তু এই খণ্ড তৈরি? এই দস্তাবেজটি শেষ কবে সিস্টেমে পুনরায় প্রবেশ করানো হয়েছিল? কোন পুনরুদ্ধারকারী এবং পুনঃরাঙ্কার এই অনুরোধটি পূরণ করেছে?
যদি আপনার পাইপলাইনে দৃশ্যমানতা না থাকে, তাহলে ড্রিফট এলোমেলো বলে মনে হবে। এটি দিয়ে, এটি নির্ণয়যোগ্য হয়ে ওঠে।
মূল্যায়ন ফাঁকের কারণে ব্যর্থতা:আসল বাধা লুকিয়ে রাখে
দুর্বল মূল্যায়ন হল চতুর্থ সবচেয়ে সাধারণ কারণ টিম উৎপাদনে RAG সিস্টেম স্থাপন করতে ব্যর্থ হয়। আমরা শুধুমাত্র চূড়ান্ত উত্তর মূল্যায়ন ঝোঁক. এটা যথেষ্ট নয়।
উৎপাদন-গ্রেড RAG একটি পাইপলাইন। যেকোন সংখ্যক স্তরে, দুর্বল ইনপুট খারাপ চূড়ান্ত আউটপুট সৃষ্টি করতে পারে। পুনরুদ্ধারকারী সঠিক নথি পুনরুদ্ধার করতে ব্যর্থ হতে পারে। র্যাঙ্কার সেরা প্রমাণকে খুব কম র্যাঙ্ক করেছেন। কনটেক্সট অ্যাসেম্বলার খুব বেশি শব্দ অন্তর্ভুক্ত করতে পারে। জেনারেটর সবচেয়ে শক্তিশালী উত্তরণ উপর চকচকে থাকতে পারে. উত্তরটি বিস্তৃত স্তরে সঠিক হতে পারে যদিও এখনও পুনরুদ্ধার করা প্রমাণের প্রতি সম্পূর্ণ অবিশ্বস্ত। আপনি যদি শুধুমাত্র চূড়ান্ত আউটপুট পাঠ্য স্কোর করেন তবে আপনি দুর্বল পর্যায়গুলি সনাক্ত করতে পারবেন না।
পুনরুদ্ধার মেট্রিক্স আলাদাভাবে মূল্যায়ন করা উচিত
এই কারণে, RAG মূল্যায়নে প্রজন্মের মেট্রিক্স থেকে পৃথক পুনরুদ্ধার মেট্রিক্স অন্তর্ভুক্ত করা উচিত। পুনরুদ্ধার মেট্রিক্সে প্রসঙ্গ নির্ভুলতা এবং প্রসঙ্গ স্মরণ অন্তর্ভুক্ত করা উচিত।
- প্রসঙ্গ স্মরণ :কনটেক্সট রিকল চেক করে যে পুনরুদ্ধার করা প্যাসেজে প্রশ্নের উত্তর দেওয়ার জন্য প্রয়োজনীয় তথ্য আছে কিনা।
- প্রসঙ্গ স্পষ্টতা :প্রসঙ্গ সূক্ষ্মতা পরিমাপ করে যে পুনরুদ্ধার করা সেটটি বেশিরভাগ প্রাসঙ্গিক নাকি শব্দ দ্বারা দূষিত৷
- র্যাঙ্কিং গুণমান: র্যাঙ্কিংয়ের গুণমানও গুরুত্বপূর্ণ, যেহেতু র্যাঙ্ক 1 এ প্রাসঙ্গিক প্যাসেজ 10 নম্বরে একই প্রাসঙ্গিক প্যাসেজের চেয়ে বেশি কার্যকর।
জেনারেশন মেট্রিক্স যতটা গুরুত্বপূর্ণ
একবার পুনরুদ্ধার পরিমাপ করা হলে, প্রজন্মের স্তরটিকে তার নিজের শর্তে মূল্যায়ন করতে হবে। দুটি মূল মেট্রিক হল ভিত্তি এবং বিশ্বস্ততা।
- গ্রাউন্ডেডনেস: গ্রাউন্ডেডনেস প্রশ্ন করে যে উত্তরটি পুনরুদ্ধার করা প্রসঙ্গে প্রদত্ত তথ্য প্রতিফলিত করে।
- বিশ্বস্ততা: বিশ্বস্ততা জিজ্ঞাসা করে যে মডেলটি সেই প্রসঙ্গটি সঠিকভাবে উপস্থাপন করে কিনা। এই মেট্রিকটি গুরুত্বপূর্ণ কারণ একটি সিস্টেম এখনও উত্স উপাদানকে ভুলভাবে উপস্থাপন করার সময় বিশ্বাসযোগ্য শোনাতে পারে৷
অবাস্তব পরীক্ষার ডেটা বাস্তব ব্যর্থতা লুকায়
অবাস্তব পরীক্ষার তথ্য আরেকটি প্রধান সমস্যা। অনেক দল পরিষ্কার, সিন্থেটিক প্রশ্ন বা অভ্যন্তরীণ দল দ্বারা সাবধানে কিউরেট করা প্রম্পটের উপর মূল্যায়ন করে। এটি মৌলিকভাবে প্রকৃত ব্যর্থতার পৃষ্ঠকে লুকিয়ে রাখে। উৎপাদনের মূল্যায়নের শর্তে অস্পষ্ট প্রশ্ন, পরস্পরবিরোধী নথি, আংশিক ব্যবহারকারীর ইনপুট, বাসি বিষয়বস্তু এবং এমন পরিস্থিতি অন্তর্ভুক্ত করা উচিত যেখানে সঠিক উত্তরটি একেবারেই উত্তর না দেওয়া। যদি ডেটাসেট প্রকৃত ব্যবহারকারীর আচরণকে প্রতিফলিত না করে, তাহলে মূল্যায়ন একটি ডায়াগনস্টিক টুলের পরিবর্তে একটি স্বাচ্ছন্দ্য ব্যবস্থায় পরিণত হয়৷
নিয়োজনের পরে মূল্যায়ন চালিয়ে যেতে হবে
আপনি প্রাথমিক রান সম্পূর্ণ করার পরে মূল্যায়ন বন্ধ করা উচিত নয়। উত্পাদন RAGs পরিবর্তন. নথি পরিবর্তন। এমবেডিং অদলবদল করা হয়. র্যাঙ্কিং যুক্তি বিকশিত হয়। প্রম্পট টেমপ্লেট স্থানান্তর. আপনার CI/CD এবং প্রোডাকশন ট্রেসিং পোস্ট-ডিপ্লয়মেন্টের অংশ হিসাবে মূল্যায়ন ছাড়াই, আপনি তাদের নিজস্ব পর্যবেক্ষণের পরিবর্তে অসুখী ব্যবহারকারীদের কাছ থেকে রিগ্রেশন সম্পর্কে শিখবেন।
কেন উৎপাদন RAG ব্যর্থ হয় এমনকি যখন বেঞ্চমার্ক ভালো দেখায়
এখানেই অনেক দল বিভ্রান্ত হয়ে পড়ে। মানদণ্ড উন্নত, তবুও লাইভ সিস্টেম এখনও হতাশ।
উৎপাদন ব্যর্থতা সাধারণত প্রণোদনা মিসলাইনমেন্ট দ্বারা সৃষ্ট হয়. দলগুলি লেটেন্সি বাজেটে ফ্যাক্টরিং ছাড়াই পুনরুদ্ধার প্রত্যাহারের জন্য অপ্টিমাইজ করার চেষ্টা করে বা পুনরুদ্ধারের নির্ভুলতা ট্র্যাক না করে উচ্চতর এলএলএম স্কোরগুলির জন্য অপ্টিমাইজ করার চেষ্টা করে। প্রজন্মের মানের খরচে পুনরুদ্ধার ওভার-টিউন হতে পারে, গোলমালের পরিচয় দেয়। পুনরুদ্ধারের উন্নতি বিবেচনা না করেই প্রজন্মকে ওভার-টিউন করা যেতে পারে। পুনরুদ্ধার এবং প্রজন্মের নির্ভুলতার মধ্যে উপযুক্ত অনুপাত প্রয়োগের উপর নির্ভর করে। সম্মতি, আইনি, এবং অন্যান্য উচ্চ-স্টেকের ব্যবহারের ক্ষেত্রে যতটা সম্ভব বিশ্বস্ততা এবং প্রসঙ্গ নির্ভুলতা প্রয়োজন। সৃজনশীল ব্যবহারের ক্ষেত্রে গতির বিনিময়ে শব্দের অনুমতি দিতে পারে।
উত্পাদন একটি একক মেট্রিক অপ্টিমাইজ করা হয় না. পুনরুদ্ধারের গুণমান, বিলম্বতা, সতেজতা, গ্রাউন্ডেডনেস এবং অপারেশনাল সরলতার মধ্যে ট্রেডঅফ রয়েছে। এজন্য ডেমো সাফল্য এত বিভ্রান্তিকর হতে পারে। ডেমো পুরস্কার সিস্টেম যে "সঠিক শব্দ"। উৎপাদন নির্ভরযোগ্যতা পুরস্কৃত করে।
উৎপাদন RAG সিস্টেমগুলি কীভাবে ঠিক করবেন
এগিয়ে যাওয়ার পথটি আরএজি পরিত্যাগ করা নয়। এটিকে একটি সুশৃঙ্খল পুনরুদ্ধার ব্যবস্থা হিসাবে বিবেচনা করা হয়।
প্রায়শই জিজ্ঞাসিত প্রশ্ন বিভাগ
আপনি কিভাবে RAG এ পুনরুদ্ধারের গুণমান পরিমাপ করবেন?
আমরা পুনরুদ্ধারের মেট্রিকগুলি ব্যবহার করি যেমন প্রসঙ্গ নির্ভুলতা, প্রসঙ্গ স্মরণ এবং র্যাঙ্কিং গুণমান, এবং পুনরুদ্ধার করা প্রমাণগুলি আসলে উত্তর তৈরিকে সমর্থন করে কিনা তাও পরীক্ষা করি৷
আরএজি সিস্টেমগুলি উৎপাদনে ব্যর্থ হওয়ার কারণ কী?
উত্পাদন ব্যর্থতাগুলি সাধারণত পুনরুদ্ধারের গুণমানে অবনতি, লেটেন্সি ক্রীপ, এম্বেডিং/কর্পাস ড্রিফট এবং খারাপ মূল্যায়ন অনুশীলনের কারণে ঘটে যা সমস্যাগুলি যেখানে শুরু হয় তা লুকিয়ে রাখে৷
একটি RAG পাইপলাইনে এমবেডিং ড্রিফ্ট কি?
এমবেডিং ড্রিফ্ট ঘটে যখন এমবেডিং মডেল, কর্পোরা, বা লাইভ ক্যোয়ারী আচরণের আপডেটগুলি ধীরে ধীরে পুনরুদ্ধারের আচরণ (অনগ্রহের প্রাসঙ্গিকতা) পরিবর্তন করে, কোনও স্পষ্টভাবে ভেঙে যাওয়া সিস্টেম আচরণের কারণ না করে।
কেন RAG লেটেন্সি স্কেলে বৃদ্ধি পায়?
লেটেন্সি বেড়ে যায় কারণ প্রোডাকশন সিস্টেম প্রায়ই ক্যোয়ারী রিরাইটিং, একাধিক পুনরুদ্ধার পাস, পুনঃর্যাঙ্কিং, অতিরিক্ত মডেল কল এবং বৃহত্তর কর্পোরা যোগ করে, যা সব প্রক্রিয়াকরণের সময় এবং অপারেশনাল জটিলতা বাড়ায়।
আপনি কীভাবে RAG-তে ভিত্তি এবং বিশ্বস্ততাকে মূল্যায়ন করেন?
আপনি পুনরুদ্ধার করা প্রমাণের সাথে উত্পাদিত উত্তরের তুলনা করুন, দাবিগুলি উত্স দ্বারা সমর্থিত কিনা এবং শব্দগুলি উদ্ভাবন বা বিকৃতি ছাড়াই সেই উত্সগুলিকে সঠিকভাবে প্রতিফলিত করে কিনা তা পরীক্ষা করে দেখুন৷
উপসংহার
বেশিরভাগ RAG সিস্টেমে উত্পাদন ব্যর্থতা ব্যর্থতার একক বিন্দুর ফলাফল নয়। পরিবর্তে, দায়ী প্রকৌশলীরা লক্ষ্য করবেন যে বেশিরভাগ ব্রেকডাউন একটি সংযুক্ত চেইনের একটি দুর্বল লিঙ্ক দিয়ে শুরু হয়। পুনরুদ্ধারের গুণমান প্রায় সর্বদাই প্রথম ব্যর্থ হয়। প্রকৌশলীরা আরও পুনরুদ্ধার, আরও প্রসঙ্গ এবং আরও অর্কেস্ট্রেশন স্তরগুলি ব্যবহার করে এই সমস্যার "সমাধান" করেন৷ এটি করা লেটেন্সি বাড়ানোর জন্য কাজ করে। এম্বেডিং, কর্পোরা, এবং ব্যবহারকারীর আচরণ সব সময়ের সাথে প্রবাহিত হওয়ার কারণে, দুর্বল মূল্যায়ন মেট্রিকগুলি লুকিয়ে রাখে যেখানে সিস্টেমটি সত্যিই ব্যর্থ হচ্ছে। পরিচালকরা বুঝতে পারার আগে ব্যবহারকারীরা লক্ষ্য করতে শুরু করে এবং বিশ্বাস হারাতে শুরু করে একটি সমস্যা। ততক্ষণে, প্যাটার্নের ভাঙ্গন রহস্যময় মনে হয়। যাইহোক, সমস্যাগুলি শুরু থেকেই পরিষ্কার ছিল৷
৷RAG স্কেলে ব্যর্থ হয় কারণ প্যাটার্নটি ভুল নয়, কিন্তু কারণ উৎপাদন RAG সিস্টেম তৈরির জন্য শক্তিশালী পুনরুদ্ধার প্রকৌশল, লেটেন্সি ম্যানেজমেন্ট, ড্রিফট প্রশমন এবং ক্রমাগত মূল্যায়ন প্রয়োজন। তারা উন্নত র্যাঙ্কিং, উন্নত খণ্ডন, ভালো পর্যবেক্ষণযোগ্যতা এবং ভিত্তি ও বিশ্বস্ততার পরিমাপ দাবি করে। সবচেয়ে গুরুত্বপূর্ণভাবে, দলগুলিকে সেট-ইট-এন্ড-ফোরগেট-ইট ডেমো আর্কিটেকচারের পরিবর্তে একটি জীবন্ত ব্যবস্থা হিসাবে RAG-এর সাথে যোগাযোগ করতে হবে।
রেফারেন্স
- উৎপাদনে RAG সিস্টেম:কেন এটি ব্যর্থ হয় এবং কীভাবে এটি ঠিক করা যায়
- 2026 সালে RAG (এবং LLM) এর জন্য সেরা চঙ্কিং কৌশলগুলি
- আরএজি মূল্যায়ন কি? পুনরুদ্ধারের গুণমান এবং উত্তরের ভিত্তি পরিমাপ করা
- পুনরুদ্ধার-অগমেন্টেড জেনারেশন মডেল ইনফারেন্সে সিস্টেম ট্রেড-অফ বোঝার দিকে
- RAGPerf:পুনরুদ্ধার-অগমেন্টেড জেনারেশন সিস্টেমের জন্য একটি এন্ড-টু-এন্ড বেঞ্চমার্কিং ফ্রেমওয়ার্ক
- Rerankers এবং দুই-পর্যায়ের পুনরুদ্ধার
- RAG থেকে প্রসঙ্গ পর্যন্ত - RAG-এর একটি 2025 বছরের শেষ পর্যালোচনা
 এই ক্রিয়েটিভ লাইসেন্সের অধীনে কাজ করে" অ্যাট্রিবিউশন-অবাণিজ্যিক- শেয়ারঅ্যালাইক 4.0 আন্তর্জাতিক লাইসেন্স।
এই ক্রিয়েটিভ লাইসেন্সের অধীনে কাজ করে" অ্যাট্রিবিউশন-অবাণিজ্যিক- শেয়ারঅ্যালাইক 4.0 আন্তর্জাতিক লাইসেন্স।
