
মূলত Tricore দ্বারা প্রকাশিত:11 জুলাই, 2017
Apache™ Hadoop®-এর এই দুই-খণ্ডের সিরিজের পার্ট 1-এ, আমরা Hadoopecosystem এবং Hadoop ফ্রেমওয়ার্ক প্রবর্তন করেছি। পার্ট 2-এ, আমরা হ্যাডুপ ফ্রেমওয়ার্কের আরও মূল উপাদানগুলি কভার করি, যার মধ্যে রয়েছে অনুসন্ধান, বাহ্যিক একীকরণ, ডেটা বিনিময়, সমন্বয় এবং পরিচালনার জন্য। আমরা একটি মডিউলও প্রবর্তন করি যা মনিটর হ্যাডুপ ক্লাস্টার।
কোয়েরি করা হচ্ছে
এই সিরিজের পার্ট 1 Apache Pig™ কে একটি স্ক্রিপ্টিং টুল হিসাবে প্রবর্তন করেছে। পিগ ল্যাটিন ভাষায় লেখা, পিগকে এক্সিকিউটেবল ম্যাপরিডুস চাকরিতে অনুবাদ করা হয়েছে। এটি বেশ কিছু সুবিধা অফার করে যা আপনি পার্ট 1 এ আরও জানতে পারবেন।
যাইহোক, কিছু বিকাশকারী এখনও SQL পছন্দ করে। যদি আপনি যা জানেন তার সাথে যেতে চান, আপনি পরিবর্তে Hadoop-এর সাথে SQL ব্যবহার করতে পারেন।
হাইভ
Apache Hive™ একটি বিতরণ করা ডেটা গুদাম যা প্রচুর পরিমাণে ডেটা পরিচালনা এবং সংগঠিত করে। এই গুদামটি HadoopDistributed File System (HDFS™) এর উপরে নির্মিত। Hive ক্যোয়ারী ভাষা, HiveQL, SQL শব্দার্থবিদ্যার উপর ভিত্তি করে। রানটাইম ইঞ্জিন HiveQL কে MapReduce জবসে রূপান্তর করে যা ডেটা জিজ্ঞাসা করে।
হাইভ নিম্নলিখিত ক্ষমতাগুলি অফার করে:
-
প্রচুর পরিমাণে কাঁচা ডেটা রাখার জন্য একটি পরিকল্পিত ডেটা স্টোর।
-
এইচডিএফএস-এ অপরিশোধিত ডেটার উপর বিশ্লেষণ এবং অনুসন্ধান চালানোর জন্য একটি SQL-এর মতো পরিবেশ।
-
বাইরের রিলেশনাল ডাটাবেস ম্যানেজমেন্ট সিস্টেম (RDBMS) অ্যাপ্লিকেশনের সাথে ইন্টিগ্রেশন।
নিম্নলিখিত চিত্রটি হ্যাডুপ ইকোসিস্টেমের স্থাপত্যকে কল্পনা করে:
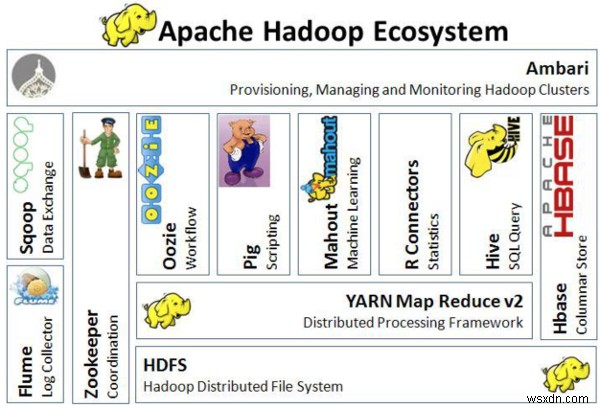 হাডুপ ইকোসিস্টেমের আর্কিটেকচার
হাডুপ ইকোসিস্টেমের আর্কিটেকচার বহিরাগত ইন্টিগ্রেশন
Apache Flume™ হল একটি বিতরণ করা, নির্ভরযোগ্য এবং উপলব্ধ পরিষেবা যা দক্ষতার সাথে সংগ্রহ করা, একত্রিত করা এবং প্রচুর পরিমাণে লগ ডেটা HDFS-এ স্থানান্তর করা৷ ফ্লুম একটি স্ট্রিমিং ডেটাফ্লো আর্কিটেকচার ব্যবহার করে প্রচুর পরিমাণে ইভেন্ট ডেটা পরিবহন করে যা ত্রুটি সহনশীল এবং ব্যর্থতা পুনরুদ্ধারের জন্য প্রস্তুত৷
Flume এছাড়াও নিম্নলিখিত ক্ষমতা প্রদান করে:
-
নেটওয়ার্ক ট্র্যাফিক, লগ, এবং ইমেল বার্তার মতো প্রচুর পরিমাণে ইভেন্ট ডেটা পরিবহন করে।
-
HDFS-এ একাধিক উৎস থেকে ডেটা স্ট্রিম করে।
-
Hadoop অ্যাপ্লিকেশনগুলিতে নির্ভরযোগ্য, রিয়েল-টাইম ডেটা স্ট্রিমিংয়ের গ্যারান্টি দেয়।
ডেটা বিনিময়
Apache Sqoop™ হ্যাডোপ এবং বাহ্যিক ডেটা স্টোর যেমন রিলেশনাল ডেটাবেস এবং এন্টারপ্রাইজডেটা গুদামগুলির মধ্যে বাল্ক ডেটা দক্ষতার সাথে স্থানান্তর করার জন্য ডিজাইন করা হয়েছে। Sqoop রিলেশনাল ডাটাবেসের সাথে কাজ করে যেমন TeradataDatabase, IBM® Netezza, Oracle® Database, MySQL™, এবং PostgreSQL®। Sqoop বেশিরভাগ কোম্পানিতে ব্যাপকভাবে ব্যবহৃত হয় যারা বড় তথ্য সংগ্রহ করে।
Sqoop নিম্নলিখিত কার্যকারিতা অফার করে:
-
ডাটাবেসের উপর নির্ভর করে, এটি আমদানি করা ডেটার জন্য স্কিমা বর্ণনা করার বেশিরভাগ প্রক্রিয়াকে স্বয়ংক্রিয় করতে পারে।
-
এটি ডেটা আমদানি এবং রপ্তানি করতে MapReduce ফ্রেমওয়ার্ক ব্যবহার করে। এটি Sqoop কে একটি সমান্তরাল প্রক্রিয়া এবং ত্রুটি সহনশীলতা প্রদান করতে সক্ষম করে।
-
এটি সমস্ত প্রধান RDBMS ডাটাবেসের জন্য সংযোগকারী প্রদান করে।
-
এটি সম্পূর্ণ এবং ক্রমবর্ধমান লোড, সমান্তরাল রপ্তানি এবং ডেটা আমদানি এবং ডেটা কম্প্রেশন সমর্থন করে৷
-
এটি Kerberos নিরাপত্তা ইন্টিগ্রেশন সমর্থন করে।
সমন্বয়
Apache Zookeeper™ বিতরণ করা অ্যাপ্লিকেশনগুলির জন্য একটি সমন্বয় পরিষেবা যা একটি ক্লাস্টার জুড়ে সিঙ্ক্রোনাইজেশন সক্ষম করে৷ এটি একটি সেন্ট্রালাইজড রিপোজিটরি প্রদান করে যেখানে বিতরণ করা অ্যাপ্লিকেশনগুলি ডেটা সংরক্ষণ এবং পুনরুদ্ধার করতে পারে৷
Zookeeper হল একটি প্রশাসনিক Hadoop টুল যা ক্লাস্টারে কাজগুলি পরিচালনা করতে ব্যবহৃত হয়। কিছু বিকাশকারী এই টুলটিকে "ওয়াচ গার্ড" হিসাবে উল্লেখ করে কারণ একটি নোডের ডেটাতে যে কোনও পরিবর্তন অন্য নোডগুলিতে যোগাযোগ করা হয়৷
হাদুপ ক্লাস্টারগুলির বিধান, পরিচালনা এবং পর্যবেক্ষণ
Apache Ambari™ হল Apache Hadoop ক্লাস্টারের ব্যবস্থা, পরিচালনা এবং নিরীক্ষণের জন্য একটি ওয়েব-ভিত্তিক টুল। সরঞ্জামগুলি ইনস্টল করার এবং পরিচালনা, কনফিগারেশন এবং নিরীক্ষণের কাজগুলি সম্পাদন করার জন্য এটিতে একটি খুব সহজ তবে অত্যন্ত ইন্টারেক্টিভ ইউজার ইন্টারফেস রয়েছে। Ambari একটি ড্যাশবোর্ড প্রদান করে তথ্য দেখার জন্য ক্লাস্টার স্বাস্থ্য, যেমন তাপ মানচিত্র। এটি আপনাকে বৈশিষ্ট্যগুলির পাশাপাশি আপনার MapReduce, Pig এবং Hive অ্যাপ্লিকেশনগুলি দেখতে সক্ষম করে যাতে আপনি সহজেই তাদের কার্যকারিতা বৈশিষ্ট্যগুলি নির্ণয় করতে পারেন৷
Ambari এছাড়াও নিম্নলিখিত ক্ষমতা প্রদান করে:
-
নোড সহ মাস্টার সার্ভিস ম্যাপিং।
-
আপনি যে পরিষেবাগুলি ইনস্টল করতে চান তা চয়ন করার ক্ষমতা৷
৷ -
সহজ কাস্টম স্ট্যাক নির্বাচন।
-
একটি ক্লিনার ইন্টারফেস।
-
সুবিন্যস্ত ইনস্টলেশন, পর্যবেক্ষণ, এবং ব্যবস্থাপনা।
উপসংহার
Hadoop হল একটি খুব কার্যকরী সমাধান কোম্পানিগুলির জন্য যেগুলি প্রচুর পরিমাণে ডেটা সঞ্চয় এবং বিশ্লেষণ করতে চায়। বিতরণ করা সিস্টেমে ডেটা ম্যানেজমেন্টের জন্য এটি একটি অনেক চাওয়া-পাওয়া টুল। যেহেতু এটি ওপেন সোর্স, এটি কোম্পানিগুলির জন্য অবাধে উপলভ্য। Hadoop সম্পর্কে আরও জানতে, Apache Software Foundation ওয়েবসাইটে অফিসিয়াল ডকুমেন্টেশন দেখুন।
আপনি Hadoop ব্যবহার করেছেন? কোনো মন্তব্য করতে বা প্রশ্ন জিজ্ঞাসা করতে প্রতিক্রিয়া ট্যাবটি ব্যবহার করুন৷
৷