
একটি Redis SQL ক্যোয়ারী চালানো কঠিন হতে হবে না। আমি আসলে এই পয়েন্টটি কয়েক বছর আগে উত্থাপন করেছি যখন একজন বন্ধুর সাথে কথা বলছিলাম যিনি একটি খুচরা কোম্পানিতে ডেটা গুদামজাতকরণ সমাধান পরিচালনা করেন। আমরা রেডিসের প্রশ্নগুলির বিষয়ে কথা বলতে শুরু করেছিলাম যখন তিনি একটি সমস্যার মুখোমুখি হয়েছিলেন তা ব্যাখ্যা করেছিলেন৷
৷“আমাদের ডেটা গুদামজাতকরণ সমাধানগুলির সাথে আমাদের একটি ব্যথার বিষয় রয়েছে৷ আমরা এমন ক্ষেত্রে ব্যবহার করেছি যেখানে আমাদের ডেটা রেকর্ড করতে হবে এবং রিয়েল-টাইমে বিশ্লেষণাত্মক ক্রিয়াকলাপগুলি করতে হবে। যাইহোক, কখনও কখনও ফলাফল পেতে কয়েক মিনিট সময় লাগে। Redis এখানে সাহায্য করতে পারেন? মনে রাখবেন যে আমরা একবারে আমাদের SQL-ভিত্তিক সমাধানটি ছিঁড়তে এবং প্রতিস্থাপন করতে পারি না। আমরা একটি সময়ে শুধুমাত্র একটি শিশুর পদক্ষেপ নিতে পারি৷৷ ”
এখন, আপনি যদি আমার বন্ধুর মতো একই পরিস্থিতিতে থাকেন তবে আপনার জন্য আমাদের কাছে সুখবর রয়েছে। আপনি রেডিস কোয়েরি চালাতে এবং আপনার আর্কিটেকচারে রেডিসকে ব্যতীত চালু করতে পারেন এমন অনেক উপায় রয়েছে আপনার বর্তমান SQL-ভিত্তিক সমাধান ব্যাহত করা।
আসুন জেনে নেই কিভাবে আপনি এটি করতে পারেন। কিন্তু আমরা আরও এগিয়ে যাওয়ার আগে, আমাদের কাছে একজন রেডিস হ্যাকাথন প্রতিযোগী রয়েছে যিনি তার নিজস্ব অ্যাপ তৈরি করেছেন যা আপনাকে এসকিউএল-এর সাথে Redis-এ ডেটা জিজ্ঞাসা করতে দেয়।
নিচের ভিডিওটি দেখুন।
রিডিস ডেটা স্ট্রাকচার হিসাবে আপনার টেবিলগুলি পুনরায় তৈরি করুন
রেডিস ডেটা স্ট্রাকচারে আপনার টেবিল ম্যাপ করা বেশ সহজ। অনুসরণ করার জন্য সবচেয়ে দরকারী ডেটা স্ট্রাকচার হল:
- হ্যাশ
- বাছাই করা সেট
- সেট করুন
আপনি এটি করতে পারেন এমন একটি উপায় হল প্রতিটি সারিকে হ্যাশ হিসাবে একটি কী দিয়ে সংরক্ষণ করা যা টেবিলের প্রাথমিক কী ভিত্তিক এবং কীটি একটি সেট বা একটি সাজানো সেটে সংরক্ষণ করা হয়৷
চিত্র 1 রেডিস ডেটা স্ট্রাকচারে আপনি কীভাবে একটি টেবিল ম্যাপ করতে পারেন তার একটি উদাহরণ দেখায়। এই উদাহরণে, আমাদের কাছে পণ্য নামক একটি টেবিল রয়েছে। প্রতিটি সারি হ্যাশ ডেটা স্ট্রাকচারে ম্যাপ করা হয়।
প্রাথমিক আইডি সহ সারি, 10001 কী:পণ্য:10001 সহ হ্যাশ হিসাবে প্রবেশ করবে। এই উদাহরণে আমাদের কাছে দুটি সাজানো সেট রয়েছে:প্রথমটি প্রাথমিক কী দ্বারা সেট করা ডেটার মাধ্যমে পুনরাবৃত্তি করা এবং দ্বিতীয়টি মূল্যের উপর ভিত্তি করে জিজ্ঞাসা করা৷
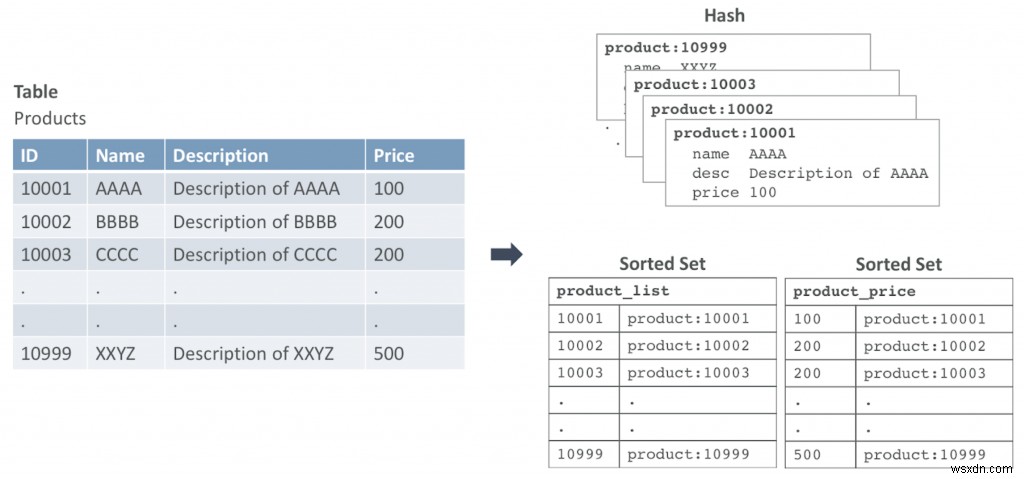
এই বিকল্পের সাহায্যে, আপনাকে SQL কমান্ডের পরিবর্তে Redis কোয়েরি ব্যবহার করতে আপনার কোডে পরিবর্তন করতে হবে। নীচে SQL এবং Redis সমতুল্য কমান্ডের কিছু উদাহরণ রয়েছে:
ক. তথ্য সন্নিবেশ করান
SQL: insert into Products (id, name, description, price) values = (10200, “ZXYW”,“Description for ZXYW”, 300);
Redis: MULTI HMSET product:10200 name ZXYW desc “Description for ZXYW” price 300 ZADD product_list 10200 product:10200 ZADD product_price 300 product:10200 EXEC
বি. পণ্য আইডি দ্বারা প্রশ্ন
SQL: select * from Products where id = 10200
Redis: HGETALL product:10200
গ. মূল্য দ্বারা প্রশ্ন
SQL: select * from Product where price < 300
Redis: ZRANGEBYSCORE product_price 0 300
এটি কীগুলি প্রদান করে:পণ্য:10001, পণ্য:10002, পণ্য:10003। এখন প্রতিটি কী-এর জন্য HGETALL চালান।
HGETALL product:10001 HGETALL product:10002 HGETALL product:10003
Redis ডেটা স্ট্রাকচারে স্বয়ংক্রিয়ভাবে আপনার টেবিল ম্যাপ করতে DataFrames ব্যবহার করুন
এখন, আপনি যদি আপনার সমাধানগুলিতে SQL ইন্টারফেস বজায় রাখতে চান এবং এটিকে দ্রুততর করার জন্য শুধুমাত্র অন্তর্নিহিত ডেটা স্টোরকে Redis-এ পরিবর্তন করতে চান, তাহলে আপনি Apache Spark এবং Spark-Redis লাইব্রেরি ব্যবহার করে তা করতে পারেন৷
স্পার্ক-রেডিস লাইব্রেরি আপনাকে রেডিস ডেটা সংরক্ষণ এবং অ্যাক্সেস করতে ডেটাফ্রেম API ব্যবহার করতে দেয়। অন্য কথায়, আপনি SQL কমান্ড ব্যবহার করে ডেটা সন্নিবেশ, আপডেট এবং অনুসন্ধান করতে পারেন, তবে ডেটা অভ্যন্তরীণভাবে Redis ডেটা স্ট্রাকচারে ম্যাপ করা হয়৷
প্রথমে, আপনাকে স্পার্ক-রিডিস ডাউনলোড করতে হবে এবং জার ফাইলটি পেতে লাইব্রেরি তৈরি করতে হবে। উদাহরণস্বরূপ, spark-redis 2.3.1 এর সাথে, আপনি spark-redis-2.3.1-SNAPSHOT-jar-with- dependencies.jar পাবেন।
তারপরে আপনাকে নিশ্চিত করতে হবে যে আপনার রেডিস ইনস্ট্যান্স চলছে। আমাদের উদাহরণে, আমরা লোকালহোস্ট এবং ডিফল্ট পোর্ট 6379-এ Redis চালাব।
এছাড়াও আপনি Apache Spark ইঞ্জিনে আপনার প্রশ্ন চালাতে পারেন। আপনি কীভাবে এটি করতে পারেন তার একটি উদাহরণ এখানে দেওয়া হল:
$ spark-shell --jars spark-redis-2.3.1-SNAPSHOT-jar-with-dependencies.jar
scala> import org.apache.spark.sql.SparkSession
scala> val spark = SparkSession
.builder()
.appName("redis-sql")
.master("local[*]")
.config("spark.redis.host","localhost")
.config("spark.redis.port","6379").getOrCreate()
scala> import spark.sql
scala> import spark.implicits._
scala> sql("create table if not exists products(id string, name string, description string, price int) using org.apache.spark.sql.redis options (table 'product')")
scala> sql("insert into products values = ('10200','ZXYW','Description of ZXYW', 300)")
scala> val results = sql("select * from products")
scala> results.show()
+-----+----+-------------------+-----+
| id|name| description|price|
+-----+----+-------------------+-----+
|10200|ZXYW|Description of ZXYW| 300|
+-----+----+-------------------+-----+ এখন আপনি Redis ডেটা স্ট্রাকচার হিসেবে এই ডেটা অ্যাক্সেস করতে আপনার Redis ক্লায়েন্ট ব্যবহার করতে পারেন:
127.0.0.1:6379> keys product* 1) "product:2e3f8611dbe94a588706a2aaea547caa"
একটি আরও কার্যকর পদ্ধতি হবে স্ক্যান কমান্ড ব্যবহার করা কারণ এটি আপনাকে ডেটার মাধ্যমে নেভিগেট করার সাথে সাথে পেজিনেট করতে দেয়৷
127.0.0.1:6379> scan 0 match product* 1) "3" 2) 1) "product:2e3f8611dbe94a588706a2aaea547caa" 127.0.0.1:6379> hgetall product:2e3f8611dbe94a588706a2aaea547caa 1) "name" 2) "ZXYW" 3) "price" 4) "300" 5) "description" 6) "Description of ZXYW" 7) "id" 8) "10200"
এবং সেখানে আমাদের এটি রয়েছে - দুটি সহজ উপায়ে আপনি কোনও বাধা ছাড়াই একটি রেডিস এসকিউএল কোয়েরি চালাতে পারেন। আরও এক ধাপ এগিয়ে, আপনি হয়ত জানতে চাইতে পারেন কেন আপনার SQL সার্ভার রিডিস প্রয়োজন আমাদের নতুন শ্বেতপত্রে৷
৷কিন্তু Redis-এর সাথে রিয়েল-টাইম ডেটা সম্পর্কিত, রিয়েল-টাইম অভিজ্ঞতা প্রদান করতে আপনি এটি ব্যবহার করতে পারেন এমন অনেক উপায়ের মধ্যে এটি শুধুমাত্র একটি।
আপনি যদি আবিষ্কার করতে চান যে কীভাবে রেডিস আপনাকে রিয়েল-টাইম ডেটা ট্রান্সমিশনের গ্যারান্টি দিতে পারে, তাহলে আমাদের সাথে যোগাযোগ করতে ভুলবেন না।
