

ইন্টারনেট প্রোটোকল সংস্করণ 4 (IPv4) হল ইন্টারনেট এবং অন্যান্য প্যাকেট-সুইচড নেটওয়ার্কে মান-ভিত্তিক ইন্টারনেটওয়ার্কিং পদ্ধতির মূল প্রোটোকলগুলির মধ্যে একটি। IPv4 এখনও সবচেয়ে ব্যাপকভাবে নিয়োজিত ইন্টারনেট প্রোটোকল। Google-এর IPv6 পরিসংখ্যান দেখায় যে 24 এপ্রিল, 2025-এ Google পরিষেবাগুলিতে ট্র্যাফিকের 44.29% IPv6-এর উপরে, যার অর্থ হল 55.71% IPv4-এর উপরে৷
এই হ্যান্ডবুকটি আপনাকে IPv4 এর প্রতিটি দিক দিয়ে নিয়ে যাবে, IP ঠিকানা বোঝা থেকে প্যাকেট শিরোনাম এবং খণ্ডিতকরণ পরীক্ষা করা পর্যন্ত। আপনি শিখবেন:
-
কিভাবে IP ঠিকানা কাজ করে এবং তাদের বিভিন্ন ফর্ম্যাট
-
স্থির-দৈর্ঘ্য থেকে CIDR
পর্যন্ত নেটওয়ার্ক অ্যাড্রেসিং স্কিম -
বিশেষ IPv4 ঠিকানা এবং তাদের ব্যবহার
-
IPv4 হেডারে প্রতিটি ক্ষেত্রের গঠন এবং উদ্দেশ্য
-
কিভাবে IPv4 বিভিন্ন নেটওয়ার্ক জুড়ে প্যাকেট ফ্র্যাগমেন্টেশন পরিচালনা করে
আপনি একজন নেটওয়ার্ক ইঞ্জিনিয়ার, সফটওয়্যার ডেভেলপার বা আইটি পেশাদারই হোন না কেন, আধুনিক কম্পিউটার নেটওয়ার্কের সাথে কাজ করার জন্য IPv4 বোঝা অত্যন্ত গুরুত্বপূর্ণ।
আমরা যা কভার করব:
-
পটভূমি
-
IP ঠিকানা বোঝা
-
নেটওয়ার্ক আইডি এবং হোস্ট আইডি
-
কিভাবে নেটওয়ার্ক বনাম হোস্ট অংশ নির্ধারণ করতে হয়
-
স্থির-দৈর্ঘ্যের পদ্ধতি
-
এখানে অসুবিধা কি? 🤔
-
-
ক্লাসফুল অ্যাড্রেসিং
-
আইপি অ্যাড্রেস অ্যাসাইনমেন্ট
-
এখানে অসুবিধা কি? 🤔
-
-
CIDR:ক্লাসলেস ইন্টারডোমেন রাউটিং
- বাস্তব জগতের উদাহরণ
-
সাবনেট মাস্ক
-
অন্তর্বর্তী সারাংশ – IPv4 ঠিকানাগুলি
-
নিজেকে পরীক্ষা করুন
-
উপসর্গ স্বরলিপি এবং সাবনেট মাস্কের মধ্যে রূপান্তর
-
সাবনেট মাস্কের সাথে পিছনের দিকে কাজ করা
-
নন-বাইট-সারিবদ্ধ উপসর্গ
-
নেটওয়ার্ক সদস্যপদ নির্ধারণ
-
-
বিশেষ IPv4 ঠিকানা
-
"এই হোস্ট" ঠিকানা:0.0.0.0
-
"এই নেটওয়ার্ক" ঠিকানাগুলি
৷ -
সম্প্রচার ঠিকানা
-
লুপব্যাক ঠিকানা:127.0.0.0/8
-
বিশেষ IPv4 ঠিকানার সারাংশ
-
-
IPv4 হেডার
-
হেডার স্ট্রাকচার
-
IPv4 হেডার – অন্তর্বর্তী সারাংশ
-
-
IPv4 ফ্র্যাগমেন্টেশন
-
কেন ফ্র্যাগমেন্টেশন প্রয়োজন
-
আইপিতে ফ্র্যাগমেন্টেশন কিভাবে কাজ করে
-
শনাক্তকরণ ক্ষেত্র
-
ফ্র্যাগমেন্ট অফসেট
-
আরও টুকরো টুকরো এবং পতাকা খণ্ডিত করবেন না
-
ফ্র্যাগমেন্টেশন উদাহরণ
-
IPv4 ফ্র্যাগমেন্টেশন – সারাংশ
-
-
সারাংশ – IPv4
-
অ্যাড্রেসিং এবং নেটওয়ার্ক স্ট্রাকচার
-
IPv4 হেডার স্ট্রাকচার
-
ফ্র্যাগমেন্টেশন
-
চূড়ান্ত শব্দ
-
-
লেখক সম্পর্কে
-
অতিরিক্ত রেফারেন্স
আমরা শুরু করার আগে দ্রুত নোট
-
আপনি আমার YouTube চ্যানেলে কম্পিউটার নেটওয়ার্ক সম্পর্কে আরও বিষয়বস্তু খুঁজে পেতে পারেন:কম্পিউটার নেটওয়ার্ক প্লেলিস্ট
-
আমি কম্পিউটার নেটওয়ার্ক সম্পর্কে একটি বই কাজ করছি! আপনি কি প্রাথমিক সংস্করণ পড়তে এবং প্রতিক্রিয়া প্রদান করতে আগ্রহী? আমাকে একটি ইমেল পাঠান:gitting.things@gmail.com
পটভূমি
আইপি মানে "ইন্টারনেট প্রোটোকল", তাই IPv4 হল ইন্টারনেট প্রোটোকল সংস্করণ 4। এটি 1981 সালের সেপ্টেম্বরে প্রকাশিত IETF দ্বারা RFC 791-এ বর্ণনা করা হয়েছিল, এবং SATNET (আটলান্টিক প্যাকেট স্যাটেলাইট নেটওয়ার্ক) এ 1982 সালে প্রথম উৎপাদনের জন্য স্থাপন করা হয়েছিল, যা একটি প্রাথমিক স্যাটেলাইট নেটওয়ার্ক ছিল যা ইন্টারনেটের প্রাথমিক সূচনা করেছিল।
IPv4 সংযোগহীন এবং একটি সর্বোত্তম প্রচেষ্টা ডেলিভারি মডেলে কাজ করে। এর মানে এটি ডেলিভারি, প্যাকেটের সঠিক ক্রম বা ডেটার বৈধতার গ্যারান্টি দেয় না। এটি দ্রুত এবং নমনীয় হওয়ার জন্য ডিজাইন করা হয়েছে৷
৷আইপি ঠিকানা বোঝা
আইপি অ্যাড্রেসগুলি হল ক্রমানুসারী, যৌক্তিক ঠিকানা যা আজকে বেশিরভাগ ইন্টারনেট সংযোগকে শক্তি দেয়৷ প্রতিটি 4 নিয়ে গঠিত বাইট, অথবা 32 বিট এগুলি সাধারণত ডটেড দশমিক স্বরলিপিতে লেখা হয়, উদাহরণস্বরূপ:

নিজেকে পরীক্ষা করুন - নিম্নলিখিত ঠিকানাটি কি একটি বৈধ IP ঠিকানা প্রতিনিধিত্ব করে?

না। যেহেতু বিন্দুগুলো বিভিন্ন বাইটকে আলাদা করে, তাই প্রতিটি মান অবশ্যই 0 এর মধ্যে হতে হবে এবং 127 . যেহেতু 392 নম্বর 127 থেকে বড় , এটি একটি একক বাইটে উপস্থাপন করা যাবে না।

নেটওয়ার্ক আইডি এবং হোস্ট আইডি
IP ঠিকানাগুলির দুটি অংশ রয়েছে:একটি নেটওয়ার্ক শনাক্তকারী৷ (বা নেটওয়ার্ক আইডি) যা নেটওয়ার্কের সমস্ত হোস্ট এবং একটি হোস্ট শনাক্তকারী এর অন্তর্গত (বা হোস্ট আইডি) যা এই নেটওয়ার্কে নির্দিষ্ট হোস্টকে শনাক্ত করে।
নেটওয়ার্ক শনাক্তকারী নেটওয়ার্কের সমস্ত হোস্টের জন্য একই হবে এবং এটিকে "প্রিফিক্স"ও বলা হয়। উদাহরণস্বরূপ, 201.22.3-এর একটি নেটওয়ার্ক শনাক্তকারী বিবেচনা করুন৷ . প্রদত্ত যে এটি নেটওয়ার্ক উপসর্গ, নিম্নলিখিত ঠিকানাগুলি:
201.22.3.15
201.22.3.91
একই নেটওয়ার্কের অংশ, কারণ তারা একই উপসর্গ ভাগ করে। প্রথম ঠিকানা হোস্ট নম্বর 15 এর অন্তর্গত এই নেটওয়ার্কে, এবং দ্বিতীয়টি হোস্ট নম্বর 91 এর অন্তর্গত .
এই ঠিকানাটির একটি ভিন্ন উপসর্গ, বা একটি ভিন্ন নেটওয়ার্ক শনাক্তকারী রয়েছে এবং এইভাবে একটি ভিন্ন নেটওয়ার্কের অন্তর্গত:
201.22.14.50
উপরের উদাহরণগুলিতে, 3 বাইট বা 24 বিট সমন্বিত একটি নেটওয়ার্ক শনাক্তকারী এবং 1 বাইট বা 8 বিট সমন্বিত একটি হোস্ট শনাক্তকারী রয়েছে৷

নেটওয়ার্ক বনাম হোস্ট অংশগুলি কীভাবে নির্ধারণ করবেন
একটি প্রশ্ন উঠছে:আপনি কীভাবে জানবেন কোন বিটগুলি নেটওয়ার্ক আইডির অংশ এবং কোনটি হোস্ট আইডির অংশ? এই চ্যালেঞ্জ মোকাবেলায় সময়ের সাথে সাথে বেশ কিছু পন্থা বিবর্তিত হয়েছে।
স্থির-দৈর্ঘ্যের পদ্ধতি
আসুন এই সমাধানটি বিবেচনা করা যাক:প্রতিটি আইপি ঠিকানার জন্য, প্রথম, সর্বাধিক-গুরুত্বপূর্ণ বাইট নেটওয়ার্ক আইডিকে প্রতিনিধিত্ব করবে এবং বাকি তিনটি, সবচেয়ে কম-গুরুত্বপূর্ণ বাইট হোস্ট আইডিকে প্রতিনিধিত্ব করবে। এইভাবে আইপি ঠিকানাগুলি পড়া সত্যিই সহজ। উদাহরণস্বরূপ এই ঠিকানার জন্য:
20.12.1.92
আপনি জানেন যে এটি নেটওয়ার্ক 20 বর্ণনা করে , এবং হোস্ট 12.1.92 সেই নেটওয়ার্কের ভিতরে। যে কোনো IP ঠিকানা যা 20 দিয়ে শুরু হয় না , যেমন 22.1.2.3 , একটি ভিন্ন নেটওয়ার্কে থাকবে এবং যে কোনো IP ঠিকানা যা 20 দিয়ে শুরু হবে , যেমন 20.1.2.3 , একই নেটওয়ার্কের মধ্যে থাকবে।

এখানে অসুবিধা কি? 🤔
নেটওয়ার্ক আইডি উপস্থাপন করার জন্য শুধুমাত্র একটি বাইট (8 বিট) সহ, আপনার কাছে শুধুমাত্র 2^8 বা 256 আছে , বিভিন্ন নেটওয়ার্ক। অবশ্যই, বাস্তব জগতে এর চেয়ে অনেক বেশি নেটওয়ার্ক রয়েছে। এমনকি ইন্টারনেটের প্রথম দিকে, বিশ্ববিদ্যালয় এবং বড় কোম্পানিগুলির প্রত্যেকের নিজস্ব নেটওয়ার্ক শনাক্তকারীর প্রয়োজন ছিল৷
সাধারণভাবে, নেটওয়ার্ক আইডির জন্য একটি নির্দিষ্ট দৈর্ঘ্য এবং হোস্ট আইডির জন্য একটি নির্দিষ্ট দৈর্ঘ্য ব্যবহার করা যথেষ্ট নমনীয় নয়। আপনি যদি সিদ্ধান্ত নেন যে দুটি সর্বাধিক-গুরুত্বপূর্ণ বাইট নেটওয়ার্ক আইডিকে প্রতিনিধিত্ব করবে এবং দুটি কম-গুরুত্বপূর্ণ বাইট হোস্ট আইডিকে প্রতিনিধিত্ব করবে, আপনি 2^16, বা 65,536 পর্যন্ত প্রতিনিধিত্ব করতে পারেন নেটওয়ার্ক, যা যথেষ্ট নয়। তদুপরি, কিছু নেটওয়ার্ক, যেমন বড় কোম্পানিগুলির, 65,536 এর চেয়ে বেশি প্রয়োজন হতে পারে হোস্ট আইডি।
ক্লাসফুল অ্যাড্রেসিং
সমাধানটি কিছু নমনীয়তা প্রদানের মধ্যে রয়েছে। "ক্লাসফুল অ্যাড্রেসিং" নামে আরেকটি পদ্ধতি বিবেচনা করুন। এই পদ্ধতিতে, নেটওয়ার্ক আইডির জন্য নিবেদিত বিটের সংখ্যা এক ঠিকানা থেকে অন্য ঠিকানায় পরিবর্তিত হয়, এবং আপনি ঠিকানাটির প্রথম, সবচেয়ে-গুরুত্বপূর্ণ বাইট দেখে নেটওয়ার্ক আইডি বলতে পারেন৷
-
1এর মধ্যে একটি সংখ্যা দিয়ে শুরু হওয়া যেকোনো ঠিকানা এবং127"ক্লাস A" এর অন্তর্গত, যার অর্থ হল এর নেটওয়ার্ক আইডি 1 বাইট নিয়ে গঠিত, হোস্ট আইডির জন্য 3 বাইট রেখে৷ -
128এর মধ্যে একটি সংখ্যা দিয়ে শুরু হওয়া যেকোনো ঠিকানা এবং191"ক্লাস B" এর অন্তর্গত, যার মানে হল এর নেটওয়ার্ক আইডি 2 বাইট লম্বা, এবং এর হোস্ট আইডিও 2 বাইট লম্বা৷ -
192এর মধ্যে একটি সংখ্যা দিয়ে শুরু হওয়া যেকোনো ঠিকানা এবং223"ক্লাস সি" এর অন্তর্গত, তাই এটিতে একটি নেটওয়ার্ক আইডির 3 বাইট এবং হোস্ট আইডির 1 বাইট রয়েছে৷
আপনি নীচের টেবিলে এই পদ্ধতির সম্পূর্ণ উপস্থাপনা দেখতে পারেন:
ক্লাস ফার্স্ট বাইট রেঞ্জনেটওয়ার্ক আইডি সাইজহোস্ট আইডি সাইজ A1 - 127 1 বাইট3 বাইটB128 - 191 2 বাইট2 বাইটC192 - 223 3 বাইট1 বাইটD224 - 239 (মাল্টিকাস্ট)ই240 - 255 (সংরক্ষিত)

উদাহরণস্বরূপ, এই ঠিকানাটি কোন শ্রেণীর অন্তর্গত?
(1) 130.12.204.5
যেহেতু এটি 130 দিয়ে শুরু হয় , যা 128 এর মধ্যে এবং 191 , এটি "ক্লাস B" এর অন্তর্গত। এর মানে হল এর নেটওয়ার্ক আইডি হল 130.12 , এবং এর হোস্ট আইডি হল 204.5 . আসুন এটিকে "ঠিকানা নম্বর 1" হিসাবে চিহ্নিত করি।
এই ঠিকানা এবং নিম্নলিখিত ঠিকানা (2) একই নেটওয়ার্কের অন্তর্গত?
(2) 130.90.2.40
না, যেহেতু তাদের আলাদা নেটওয়ার্ক শনাক্তকারী রয়েছে, তারা একই নেটওয়ার্কের মধ্যে নেই৷
৷নিম্নলিখিত ঠিকানাটি কোন শ্রেণীর অন্তর্গত?
(3) 200.1.1.9
এটি ক্লাস C এর অন্তর্গত, এটির প্রথম বাইটের মান হিসাবে, 200 , 192 এর মধ্যে এবং 223 . এর মানে হল এর নেটওয়ার্ক শনাক্তকারী হল 200.1.1 , এবং এই উপসর্গ দিয়ে শুরু হওয়া যেকোনো ঠিকানা একই নেটওয়ার্কের মধ্যে থাকবে। এই নির্দিষ্ট ঠিকানা হোস্ট 9 বর্ণনা করে এই নেটওয়ার্কের মধ্যে।
ছবি সম্পূর্ণ করতে, 224 এর মধ্যে একটি মান দিয়ে শুরু করা ঠিকানা এবং 239 "ক্লাস ডি" এর অন্তর্গত - অর্থাৎ, মাল্টিকাস্ট অ্যাড্রেস - অ্যাড্রেস যেগুলি একাধিক ডিভাইসের অন্তর্গত। 240 এর মধ্যে একটি মান দিয়ে শুরু করা ঠিকানা এবং 255 ভবিষ্যতে ব্যবহারের জন্য সংরক্ষিত ছিল। 0 দিয়ে শুরু হওয়া ঠিকানা বিশেষ ঠিকানা।
আইপি অ্যাড্রেস অ্যাসাইনমেন্ট
প্রথমদিকে ইন্টারনেটে, IPv4 ঠিকানাগুলি সংস্থাগুলিকে ইন্টারনেট অ্যাসাইনড নম্বর অথরিটি (IANA) দ্বারা বরাদ্দ করা হয়েছিল। ইন্টারনেট বৃদ্ধির সাথে সাথে, এই দায়িত্বটি পাঁচটি আঞ্চলিক ইন্টারনেট রেজিস্ট্রি (RIRs) কে বিতরণ করা হয়েছিল যারা বিভিন্ন ভৌগলিক অঞ্চলের জন্য ঠিকানা বরাদ্দ পরিচালনা করে। বড় প্রতিষ্ঠানগুলি তাদের প্রয়োজনের ভিত্তিতে ঠিকানার ব্লকগুলি পাবে, ঠিকানা ক্লাসগুলি এই ব্লকগুলির আকার নির্ধারণ করে৷
এখানে অসুবিধা কি? 🤔
যদিও ক্লাসফুল অ্যাড্রেসিং স্থির-দৈর্ঘ্যের পদ্ধতির তুলনায় আরও নমনীয়তার অনুমতি দেয়, এমনকি এই পদ্ধতিটিও যথেষ্ট নমনীয় নয়।
এই দৃশ্যটি বিবেচনা করুন:মাত্র দুইজন প্রতিষ্ঠাতা সহ একটি ছোট স্টার্টআপ কোম্পানির একটি নেটওয়ার্ক শনাক্তকারী প্রয়োজন৷ তাদের কোন ক্লাস লাগবে?
ক্লাস এ বা ক্লাস বি পাওয়া অত্যধিক হবে, তাই তারা একটি ক্লাস সি পেতে পারে – 256 এর অনুমতি দেয় ঠিকানা এটি বর্তমানে প্রয়োজনের চেয়ে বেশি, তবে কিছু সম্প্রসারণের অনুমতি দেয়। স্টার্টআপ 256-এর বেশি হলে কী হবে কর্মচারী (এবং ডিভাইস)?
এই মুহুর্তে, তাদের একটি ক্লাস B ঠিকানা পেতে হবে, 65,536 এর কম নয় ঠিকানা, যখন তাদের প্রয়োজন হয় তখন 256 একটু বেশি হয় ঠিকানা এর অর্থ হল 60,000 এর থেকে বেশি অপচয় করা ঠিকানা।
1990 এর দশকের গোড়ার দিকে এটি একটি বাস্তব সমস্যা হয়ে দাঁড়ায় কারণ ইন্টারনেট দ্রুত বর্ধনশীল ছিল। আরও আইপি অ্যাড্রেসের প্রয়োজনীয়তা স্পষ্ট হয়ে ওঠে, এবং আইপিভি4 অ্যাড্রেস স্পেসের আসন্ন ক্লান্তি ছিল। ক্ষেত্রে যেখানে 60,000 ঠিকানা নষ্ট করা আর সহ্য করা যায় না।
CIDR:ক্লাসলেস ইন্টারডোমেন রাউটিং
ঠিকানার এই ঘাটতি সামাল দেওয়ার জন্য একটি পদক্ষেপ ছিল 1993 সালে ক্লাসফুল অ্যাড্রেসিং ত্যাগ করা এবং CIDR - ক্লাসলেস ইন্টারডোমেন রাউটিং নামক আরেকটি পদ্ধতিতে স্যুইচ করা। এই পদ্ধতিটি আজও ব্যবহৃত হয়৷
নেটওয়ার্ক আইডি এবং হোস্ট আইডি নির্বাচন করার সময় CIDR নমনীয়তার জন্য অনুমতি দেয়। এটি নেটওয়ার্ক অ্যাডমিনিস্ট্রেটরদের A, B, বা C ক্লাসে সীমাবদ্ধ না থেকে সঠিক আকারের সাবনেট তৈরি করতে দেয়।
একটি সহজ উদাহরণ দিয়ে শুরু করা যাক। CIDR স্বরলিপিতে, আমরা নেটওয়ার্ক অংশের জন্য কতগুলি বিট ব্যবহার করা হয় তা নির্দেশ করে একটি প্রত্যয় যোগ করি:
(4) 200.8.3.1/16
এই স্ল্যাশ স্বরলিপি কতগুলি বিট নেটওয়ার্ক আইডি বর্ণনা করে তা নির্দিষ্ট করে। উপরের উদাহরণে (4), প্রথম 16 বিট (বা 2 বাইট) নেটওয়ার্ক আইডির জন্য ব্যবহৃত হয়। সুতরাং, এই ক্ষেত্রে, 200.8 নেটওয়ার্ক শনাক্তকারী, এবং 3.1 হোস্ট শনাক্তকারী। সত্য যে 200.8 নেটওয়ার্ক আইডি মানে হল 200.8.0.0 থেকে সমস্ত ঠিকানা 200.8.255.255 এর মাধ্যমে এই নেটওয়ার্কে আছে৷

এই অতিরিক্ত ঠিকানাগুলি বিবেচনা করুন:
(5) 200.2.13.5
(6) 200.8.21.6
16-এর এই ঠিকানা উপসর্গ দেওয়া হয়েছে বিট, অথবা 2 বাইট, এই ঠিকানাগুলির মধ্যে কোনটি একই নেটওয়ার্কের অন্তর্গত যেমন উদাহরণ (4) (200.8.3.1/16 )?
প্রথম ঠিকানা (5) (200.2.13.5 ) প্রথম 16 হিসাবে এই নেটওয়ার্কের অন্তর্গত নয় বিটস – 200.2 , প্রথম 16 থেকে আলাদা উদাহরণ ঠিকানার বিট।
দ্বিতীয় ঠিকানা (6) (200.8.21.6 ) উদাহরণ ঠিকানার মতো একই নেটওয়ার্কের অন্তর্গত।

বাস্তব জগতের উদাহরণ
অনুশীলনে, একটি ISP একটি বড় ব্লক পেতে পারে যেমন 104.16.0.0/12 RIR থেকে। এটি তাদের 104.16.0.0 থেকে সমস্ত ঠিকানার নিয়ন্ত্রণ দেয় 104.31.255.255 এ . ISP তারপর গ্রাহকদের জন্য ছোট সাবনেট বরাদ্দ করতে পারে, যেমন একটি ছোট ব্যবসাকে /24 দেওয়া 256 সহ সাবনেট ঠিকানা, অথবা একটি বড় কোম্পানি একটি /20 4,096 সহ সাবনেট ঠিকানা।
সাবনেট মাস্ক
নেটওয়ার্ক উপসর্গ প্রকাশ করার আরেকটি উপায় হল একটি সাবনেট মাস্ক ব্যবহার করে, যেমন:
255.255.0.0
বাইনারিতে রূপান্তরিত হলে, 255 দশমিকে আটটি 1 সমান s বাইনারি - তাই সমস্ত বিট চালু আছে। সুতরাং আপনি যদি এই মুখোশটিকে বাইনারিতে অনুবাদ করেন, আপনি পাবেন:
11111111 11111111 00000000 00000000
অন্য কথায়, 16 বিট চালু আছে, যার মানে 16 এর একটি নেটওয়ার্ক উপসর্গ বিট উভয় কনভেনশন (CIDR স্বরলিপি এবং সাবনেট মাস্ক) খুব ঘন ঘন ব্যবহার করা হয়।

CIDR এর সাথে, একটি ঠিকানা বিভিন্ন নেটওয়ার্ক উপসর্গ বা সাবনেট মাস্ক দেওয়া বিভিন্ন নেটওয়ার্কে থাকতে পারে। আপনি যদি একটি ভিন্ন উপসর্গ সহ একই উদাহরণের ঠিকানা বিবেচনা করেন, তাহলে বলুন 8 বিট - উভয় অতিরিক্ত ঠিকানা একই নেটওয়ার্কের অন্তর্গত হবে, কারণ তারা সকলেই প্রথম 8 ভাগ করে বিটস – 200 .
আপনি কিভাবে 8 এর একটি নেটওয়ার্ক উপসর্গ উপস্থাপন করবেন একটি সাবনেট মাস্ক হিসাবে বিট? আপনার প্রথম 8 দরকার বিট চালু করতে হবে, যার মানে 255 দশমিকে, এবং অবশিষ্ট বিটগুলি বন্ধ, ফলে এই সাবনেট মাস্ক:
255.0.0.0

আপনি 24 এর একটি নেটওয়ার্ক উপসর্গ ব্যবহার করলে কি হবে বিট? প্রথমত, আপনি কীভাবে এটিকে সাবনেট মাস্ক হিসাবে প্রকাশ করবেন? আপনার প্রয়োজন 24 বিট চালু করতে হবে, যাতে 3 গুণ 8 বিট অন হতে হয়, ফলে:
255.255.255.0

এখন, অতিরিক্ত ঠিকানাগুলির কোনোটিই উদাহরণ ঠিকানার মতো একই নেটওয়ার্কের মধ্যে থাকে না, কারণ তারা 200.8.3 এর নেটওয়ার্ক আইডি ভাগ করে না .

নোট করুন যে নেটওয়ার্ক উপসর্গগুলিকে সম্পূর্ণ বাইট উপস্থাপন করতে হবে না। উদাহরণস্বরূপ, আপনি 12 এর একটি নেটওয়ার্ক উপসর্গ ব্যবহার করতে পারেন বিট, অথবা 11 বিট, অথবা 22 বিট যখন উপসর্গের দৈর্ঘ্য 8 এর একাধিক না হয় , সাবনেট মাস্কের 0 ছাড়া অন্য একটি মান থাকবে অথবা 255 এর একটি অবস্থানে।
এটি স্টার্টআপ কোম্পানি সংক্রান্ত সমস্যার সমাধান করে। যদি একটি স্টার্টআপে 300 থাকে কর্মচারী, তাদের একটি 23 পেতে হবে -বিট নেটওয়ার্ক আইডি, 9 ছেড়ে তাদের নেটওয়ার্কের মধ্যে হোস্টের জন্য বিট। এর মানে হল 2^9, অথবা 512 ঠিকানা, যা যথেষ্ট হওয়া উচিত।
অন্তর্বর্তী সারাংশ – IPv4 ঠিকানাগুলি
এই বিভাগে, আপনি IPv4 ঠিকানা সম্পর্কে শিখেছেন। IP ঠিকানা হল শ্রেণীবদ্ধ, যৌক্তিক ঠিকানা যা 4 নিয়ে গঠিত বাইট IP ঠিকানাগুলির দুটি অংশ রয়েছে:একটি নেটওয়ার্ক শনাক্তকারী যা নেটওয়ার্কের সমস্ত হোস্টের অন্তর্গত, এবং একটি হোস্ট শনাক্তকারী যা নেটওয়ার্কের নির্দিষ্ট হোস্টকে সনাক্ত করে৷
আপনি নেটওয়ার্ক শনাক্তকারী এবং হোস্ট শনাক্তকারী নির্ধারণের জন্য বিভিন্ন বিকল্প অন্বেষণ করেছেন:
-
স্থির-দৈর্ঘ্যের পদ্ধতি – খুব কঠোর এবং সীমিত
-
ক্লাসফুল অ্যাড্রেসিং পন্থা – আরও ভাল কিন্তু এখনও অপব্যয়
-
CIDR (ক্লাসলেস ইন্টারডোমেন রাউটিং) – নমনীয় এবং দক্ষ
CIDR অনেক বেশি নমনীয়তা প্রদান করে এবং IPv4 ঠিকানার ঘাটতির উল্লেখযোগ্য সমস্যা কাটিয়ে উঠতে সাহায্য করে। যাইহোক, CIDR হল IPv4 ঠিকানার ঘাটতি পূরণের একটি অংশ, যার মধ্যে NAT (নেটওয়ার্ক অ্যাড্রেস ট্রান্সলেশন) এবং শেষ পর্যন্ত IPv6 সহ অন্যান্য সমাধান রয়েছে।
পরবর্তী বিভাগে বিশেষ IPv4 ঠিকানাগুলি অন্বেষণ করবে এবং তারপর IPv4 প্যাকেটগুলির শিরোনাম পরীক্ষা করবে৷
নিজেকে পরীক্ষা করুন
এখন আপনি যে ধারণাগুলি শিখেছেন তা অনুশীলন করুন এবং নিশ্চিত করুন যে আপনি সেগুলির সাথে স্বাচ্ছন্দ্য বোধ করেন৷
উত্তরগুলি পরীক্ষা করার আগে নিম্নলিখিত প্রশ্নের উত্তর দেওয়ার চেষ্টা করার জন্য কিছুক্ষণ সময় নিন।
প্রিফিক্স নোটেশন এবং সাবনেট মাস্কের মধ্যে রূপান্তর করা
আপনি কিভাবে 16 এর একটি নেটওয়ার্ক উপসর্গ উপস্থাপন করবেন বিট, এভাবে লেখা /16 , একটি সাবনেট মাস্ক হিসাবে?
আপনার প্রয়োজন 16 যে বিট আছে. যখন 8 বিট চালু আছে আপনি 255 পাবেন দশমিকে, তাই আপনি ব্যবহার করবেন:
255.255.0.0

এই নেটওয়ার্ক উপসর্গ দেওয়া, এই ঠিকানাগুলি কি একই নেটওয়ার্কের অন্তর্গত?

হ্যাঁ, তারা করে, কারণ তারা একই সবচেয়ে-গুরুত্বপূর্ণ 16 শেয়ার করে বিট, বা দুই বাইট

এই ঠিকানাটি কি আগের ঠিকানাগুলির মতো একই নেটওয়ার্কের অন্তর্গত?

হ্যাঁ, এটা করে। আবার, এটি একই দুটি সবচেয়ে উল্লেখযোগ্য বাইট শেয়ার করে।

এই এক সম্পর্কে কি? এটি কি আগের ঠিকানাগুলির মতো একই নেটওয়ার্কের অন্তর্গত?
৷
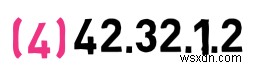
না, যেহেতু প্রথম দুটি বাইট 42.31 নয় - এটি একটি ভিন্ন নেটওয়ার্ক। তাই এই ঠিকানা হোস্ট 1.2 বর্ণনা করে , নেটওয়ার্কের মধ্যে 42.32 .

সাবনেট মাস্কের সাথে পিছনের দিকে কাজ করা
এর অন্য উপায় কাছাকাছি চেষ্টা করা যাক. আপনার কাছে এই সাবনেট মাস্ক আছে:
255.255.255.0
আপনি কিভাবে এটি একটি নেটওয়ার্ক উপসর্গ ব্যবহার করে প্রকাশ করবেন?
আপনার কাছে 255 তিনটি ঘটনা আছে , যার মানে তিনবার 8 যে বিটগুলি চালু আছে, তাই সামগ্রিকভাবে আপনার 24 আছে যে বিট আছে. তাই আপনি /24ও লিখতে পারেন . এর মানে 3 বাইট।

এই সাবনেট মাস্ক দেওয়া, উপরের ঠিকানা (1) এবং (3) কি একই নেটওয়ার্কের অন্তর্গত?

তারা করে, কারণ তাদের উভয়েরই একই সবচেয়ে উল্লেখযোগ্য তিনটি বাইট রয়েছে – নেটওয়ার্ক 42.31.93 .

ঠিকানা (1) এবং (2) সম্পর্কে কি?

এই নেটওয়ার্ক উপসর্গ দেওয়া, তারা একই নেটওয়ার্কের অন্তর্গত নয়। প্রথম ঠিকানাটি নেটওয়ার্ক 42.31.93 এর অন্তর্গত , এবং দ্বিতীয় ঠিকানাটি নেটওয়ার্ক 42.31.1 এর অন্তর্গত .

নন-বাইট-সারিবদ্ধ উপসর্গ
নেটওয়ার্ক উপসর্গগুলিকে 8 এ সারিবদ্ধ করতে হবে না বিট, বা সম্পূর্ণ বাইট। ধরা যাক আপনার কাছে 14 এর একটি নেটওয়ার্ক উপসর্গ রয়েছে বিট আপনি কীভাবে এটিকে একটি সাবনেট মাস্কে রূপান্তর করবেন?
ভাল, প্রথম বাইট পরিষ্কার:আপনার আছে 8 বিট অন, তাই প্রথম বাইট হল 255 . পরেরটির কি হবে?
বাইনারিতে, আপনি ছয়টি অতিরিক্ত 1s এবং তারপর 2 0s রাখতে চান - তাই বাইনারিতে আপনি লিখবেন:
11111100
দশমিকে রূপান্তর করে, এই বাইনারি সংখ্যাটি 252 প্রতিনিধিত্ব করে . তাই আপনার সাবনেট মাস্ক হল:
255.252.0.0
এই রূপান্তর করার আরেকটি উপায়:আপনি জানেন যে বাইনারিতে আটটি 1s 255 প্রতিনিধিত্ব করে দশমিকে। আপনি এটাও জানেন যে 11 বাইনারিতে 3 , তাই আপনি সহজভাবে 3 বিয়োগ করতে পারেন 255 থেকে এবং 252 পান .

এরপরে, অন্যভাবে চেষ্টা করুন। আপনার কাছে নিম্নলিখিত সাবনেট মাস্ক রয়েছে:
255.255.224.0
কত বিট নেটওয়ার্ক উপসর্গ প্রতিনিধিত্ব করে?
প্রথম দুটি বাইট পরিষ্কার:আপনার 16 আছে বিট তৃতীয় বাইটকে বাইনারিতে রূপান্তর করা হচ্ছে:224 দশমিকে হল 11100000 বাইনারি মধ্যে এর মানে আপনার কাছে একটি অতিরিক্ত তিনটি 1s আছে, তাই আপনি উপরে /19 এর উপসর্গ হিসাবে সাবনেট মাস্ক লিখতে পারেন বিটস – 16 দুটি 255 এর জন্য বিট বাইট, এবং 3 224-এর জন্য অতিরিক্ত বিট বাইট।

নেটওয়ার্ক সদস্যপদ নির্ধারণ
আসুন নিম্নলিখিত ঠিকানাগুলি বিবেচনা করি:

তারা কি একই নেটওয়ার্কের অংশ? 🤔
এটি সাবনেট মাস্কের উপর নির্ভর করে।
যদি নেটওয়ার্ক উপসর্গ /8 হয় , তাহলে তারা একই নেটওয়ার্কের অংশ, কারণ তারা একই নেটওয়ার্ক আইডি ভাগ করে।

অন্যদিকে, যদি নেটওয়ার্ক উপসর্গ /16 হয় , তারপর তাদের আলাদা নেটওয়ার্ক আইডি আছে, এবং এইভাবে একই নেটওয়ার্কের অন্তর্গত নয়। কিন্তু মাঝে উপসর্গ দিয়ে কি হবে? তারা কি /9 এর একটি উপসর্গের জন্য একই নেটওয়ার্কে থাকবে ? /14 ?
এই প্রশ্নের কাছে যাওয়ার উপায় হল এই ঠিকানাগুলির দ্বিতীয় বাইটকে বাইনারিতে রূপান্তর করা। প্রথম ঠিকানার জন্য, এই বাইট হল 24 , যা বাইনারিতে হয়:
00011000
দ্বিতীয় ঠিকানার জন্য, দ্বিতীয় বাইট হল 23 , যা বাইনারিতে হয়:
00010111
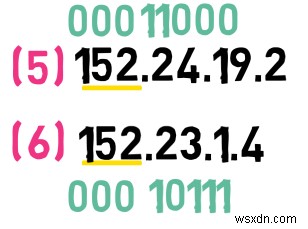
আপনি দেখতে পাচ্ছেন যে সবচেয়ে উল্লেখযোগ্য 4 দ্বিতীয় বাইটের মধ্যে থাকা বিটগুলি অভিন্ন। আপনি যদি প্রথম 8 যোগ করেন ঠিকানার বিট, আপনি দেখতে পাচ্ছেন যে সবচেয়ে তাৎপর্যপূর্ণ 12 এই ঠিকানাগুলির বিট একই।
সুতরাং, আপনার যদি /11 এর একটি নেটওয়ার্ক উপসর্গ থাকে , এই ঠিকানাগুলি কি একই নেটওয়ার্কের অন্তর্গত?
হ্যাঁ, তারা করে – তাদের সবচেয়ে উল্লেখযোগ্য 11 বিটগুলি অভিন্ন৷
/13 সম্পর্কে কি? ?
না, এই নেটওয়ার্ক উপসর্গের সাথে, তারা তাদের 13 হিসাবে একই নেটওয়ার্ক শনাক্তকারী ভাগ করে না থ বিট আলাদা।
এই অনুশীলনটি আপনাকে সাবনেট মাস্ক এবং নেটওয়ার্ক উপসর্গগুলির সাথে স্বাচ্ছন্দ্য বোধ করতে সহায়তা করবে। পরবর্তী বিভাগে, আপনি বিশেষ আইপি ঠিকানা সম্পর্কে শিখবেন এবং তারপর আইপি প্যাকেটগুলির শিরোনামটি পরীক্ষা করবেন৷
বিশেষ IPv4 ঠিকানা
এখন আপনি আইপি ঠিকানা এবং সাবনেট মাস্কগুলির সাথে স্বাচ্ছন্দ্য বোধ করছেন, আসুন কিছু আইপি ঠিকানা অন্বেষণ করি যার বিশেষ অর্থ রয়েছে৷
"এই হোস্ট" ঠিকানা:0.0.0.0
ঠিকানা 0.0.0.0 মানে "এই হোস্ট" এবং দুটি পরিস্থিতিতে ব্যবহৃত হয়:
প্রথমত, যখন একটি মেশিন বুট হয়ে যায় এবং এখনও আইপি ঠিকানা থাকে না। আইপি ঠিকানাগুলি যৌক্তিক ঠিকানা যা একটি মেশিনে বরাদ্দ করা প্রয়োজন। এই অ্যাসাইনমেন্টের আগে, একটি ডিভাইসের কোনো আইপি ঠিকানা নেই। ডিভাইসটিকে এই পর্যায়ে যোগাযোগ করার প্রয়োজন হলে, এটি এই বিশেষ ঠিকানাটি ব্যবহার করতে পারে, 0.0.0.0 .
দ্বিতীয়ত, সমস্ত নেটওয়ার্ক ইন্টারফেসে ইনকামিং সংযোগের জন্য শুনতে প্রয়োজন এমন নেটওয়ার্ক অ্যাপ্লিকেশনগুলি লেখার সময়। উদাহরণস্বরূপ, যদি একটি মেশিনের দুটি ইন্টারফেস থাকে - একটি IP ঠিকানা 1.1.1.1 সহ , এবং আরেকটি ঠিকানা 2.2.2.2 সহ – ঠিকানায় শুনছি 0.0.0.0 মানে কোন নেটওয়ার্ক ইন্টারফেস সেগুলি গ্রহণ করুক না কেন সংযোগ গ্রহণ করা।
"এই নেটওয়ার্ক" ঠিকানাগুলি
৷বিশেষ ঠিকানাগুলির আরেকটি শ্রেণি হল যেগুলি শূন্য দিয়ে শুরু হয়, যেখানে শূন্যের অর্থ "এই নেটওয়ার্ক।"
উদাহরণস্বরূপ, আপনার যদি ঠিকানা সহ একটি মেশিন থাকে:
12.34.55.55
এবং 16 এর একটি নেটওয়ার্ক উপসর্গ বিট, এই মেশিনটি তার সম্পূর্ণ ঠিকানা ব্যবহার করে নেটওয়ার্কের অন্য ডিভাইসে একটি প্যাকেট পাঠাতে পারে, উদাহরণস্বরূপ 12.34.66.66 , অথবা বিকল্পভাবে বিশেষ শূন্য স্বরলিপি ব্যবহার করুন এবং প্যাকেটটি এখানে পাঠান:
0.0.66.66
এর মানে "হোস্ট 66.66-এ একটি প্যাকেট পাঠান৷ এই নেটওয়ার্কে।" অবশ্যই, এই ঠিকানাটিকে সঠিকভাবে ব্যাখ্যা করার জন্য প্রাপককে অবশ্যই প্রাসঙ্গিক নেটওয়ার্ক উপসর্গটি জানতে হবে৷
সম্প্রচার ঠিকানা
ঠিকানা 255.255.255.255 , যেখানে সমস্ত বিট 1 সেট করা আছে , স্থানীয় নেটওয়ার্কের সমস্ত হোস্টের ঠিকানা - সম্প্রচার ঠিকানা। এটি ইথারনেটের সম্প্রচার ঠিকানার অনুরূপ (FF:FF:FF:FF:FF:FF ) উভয় ক্ষেত্রেই, সমস্ত বিট 1 এ সেট করা আছে .
একটি সঠিক নেটওয়ার্ক শনাক্তকারী ব্যবহার করে যেখানে হোস্ট শনাক্তকারীটি 1s-এ সেট করা থাকে দূরবর্তী নেটওয়ার্কগুলিতে একটি সম্প্রচার প্যাকেট পাঠাতে ব্যবহার করা যেতে পারে। উদাহরণস্বরূপ, একটি নেটওয়ার্ক 12.34.0.0/16 বিবেচনা করুন এবং 12.35.0.0/16 এর নেটওয়ার্ক আইডি সহ আরেকটি নেটওয়ার্ক . যদি 12.34.55.55 এ একটি মেশিন অন্য নেটওয়ার্কের সমস্ত ডিভাইসে একটি প্যাকেট পাঠাতে চায়, এটি গন্তব্য ঠিকানা ব্যবহার করতে পারে:12.35.255.255 .
যদিও এটি আইপি স্পেসিফিকেশন (RFC) অনুসারে অনুমোদিত, বাস্তবে এই বৈশিষ্ট্যটি প্রায়শই অক্ষম করা হয় কারণ এটি নিরাপত্তা দুর্বলতা তৈরি করতে পারে৷
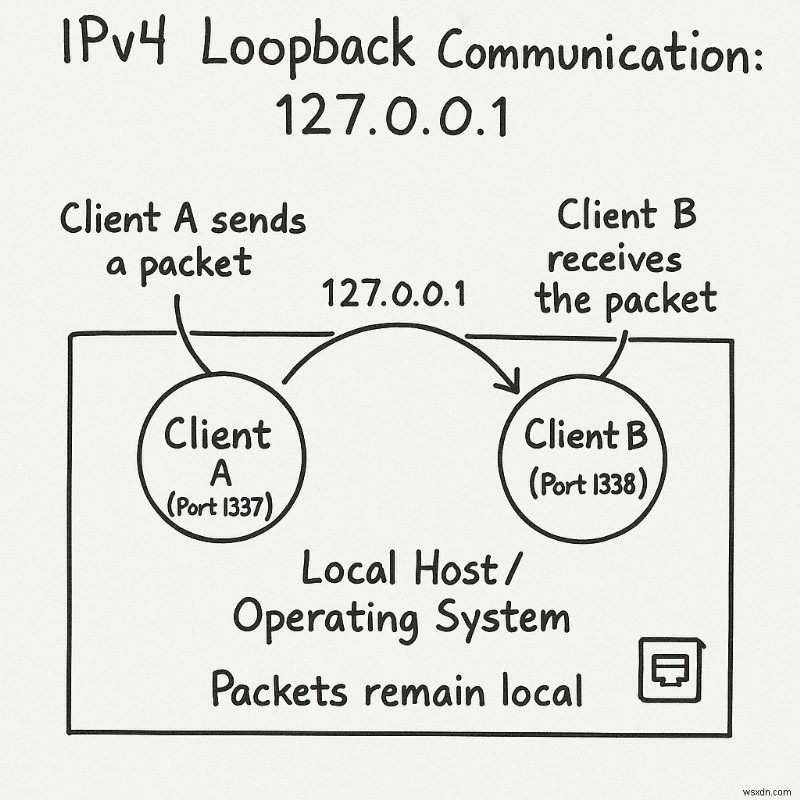
লুপব্যাক ঠিকানা:127.0.0.0/8
নেটওয়ার্কের সমস্ত ঠিকানা 127.0.0.0/8 (অর্থাৎ, 127 দিয়ে শুরু হওয়া সমস্ত ঠিকানা ) লুপব্যাক ঠিকানা। এই ঠিকানাগুলির যেকোনো একটিতে পাঠানো প্যাকেটগুলি প্রকৃত নেটওয়ার্কে রাখা হয় না তবে অপারেটিং সিস্টেমের মধ্যে স্থানীয়ভাবে প্রক্রিয়া করা হয়। এটি উন্নয়ন এবং ডিবাগিংয়ের জন্য অত্যন্ত দরকারী৷
উদাহরণস্বরূপ, একটি সাধারণ চ্যাট প্রোগ্রাম তৈরি করার সময়, আপনার দুটি ক্লায়েন্ট প্রয়োজন যারা ডেটা বিনিময় করে। একটি পদ্ধতি হল দুটি ভিন্ন শারীরিক কম্পিউটার ব্যবহার করা, কিন্তু এটি ক্লান্তিকর – আপনাকে একটি কম্পিউটারে একটি বার্তা লিখতে হবে, অন্য কম্পিউটারটি প্রাপ্ত হয়েছে কিনা তা দেখতে অন্য কম্পিউটারটি পরীক্ষা করতে হবে, তারপরে দ্বিতীয় কম্পিউটারে একটি বার্তা লিখতে হবে এবং রসিদ যাচাই করতে প্রথমটিতে ফিরে যেতে হবে৷
একটি লুপব্যাক ঠিকানা ব্যবহার করা একটি অনেক সহজ পদ্ধতি। উভয় ক্লায়েন্ট একই মেশিনে চলতে পারে এবং একে অপরের সাথে সংযোগ করতে পারে। আপনি একই শারীরিক কম্পিউটারে দুটি ভিন্ন ক্লায়েন্ট প্রোগ্রাম চালাতে পারেন এবং অতিরিক্ত মেশিনের প্রয়োজন ছাড়াই তাদের মধ্যে বার্তা বিনিময় করতে পারেন।
উদাহরণস্বরূপ, আপনি 127.0.0.1 ঠিকানাটি ব্যবহার করতে পারেন , একজন ক্লায়েন্ট পোর্টে শুনছে 1337 এবং অন্যটি 1338 পোর্টে . যখন ক্লায়েন্ট A ক্লায়েন্ট B কে একটি প্যাকেট পাঠায়, এই প্যাকেটটি কখনই আপনার নেটওয়ার্ক কার্ড ছেড়ে যায় না কিন্তু অপারেটিং সিস্টেমের মধ্যে থাকে। ক্লায়েন্ট B লুপব্যাক ইন্টারফেস থেকে প্যাকেটটি এমনভাবে গ্রহণ করে যেন এটি ফিজিক্যাল নেটওয়ার্ক থেকে পেয়েছে।
ডিবাগিং সম্পূর্ণ হওয়ার পরে, আপনার ক্লায়েন্ট কোড পরিবর্তন করার প্রয়োজন নেই - শুধুমাত্র পার্থক্য হল তারা লুপব্যাক ঠিকানার পরিবর্তে বাস্তব আইপি ঠিকানা ব্যবহার করে যোগাযোগ করবে।
বিশেষ IPv4 ঠিকানার সারাংশ
বিশেষ IPv4 ঠিকানাগুলিকে সংক্ষিপ্ত করতে যা আপনি শিখেছেন:
বিশেষ ঠিকানা মানে ব্যবহার0.0.0.0 "এই হোস্ট"বুট করার সময় বা 0 দিয়ে শুরু হওয়া সমস্ত ইন্টারফেস ঠিকানা শুনতে ব্যবহৃত হয় "এই নেটওয়ার্ক"স্থানীয় নেটওয়ার্কে হোস্টে পাঠানো হচ্ছে255.255.255.255 স্থানীয় নেটওয়ার্ক নেটওয়ার্ক আইডিতে সমস্ত হোস্টকে ব্রডকাস্ট পাঠানো হচ্ছে হোস্ট অংশে সমস্ত 1s সহ নির্দেশিত সম্প্রচার একটি নির্দিষ্ট নেটওয়ার্কের সমস্ত হোস্টকে পাঠানো হচ্ছে127.0.0.0/8 শারীরিক নেটওয়ার্ক ব্যবহার না করে লুপব্যাক টেস্টিং এবং ডিবাগিং পরবর্তী বিভাগে, আপনি IPv4 হেডারের গঠন সম্পর্কে শিখবেন।
এখন যেহেতু আপনি IP ঠিকানা, সাবনেট এবং বিশেষ ঠিকানাগুলি বুঝতে পেরেছেন, এখন IPv4 শিরোনাম গঠনটি বিশদভাবে পরীক্ষা করার সময় এসেছে৷

উপরের চিত্রটি RFC 791-এ সংজ্ঞায়িত IPv4-এর শিরোনাম দেখায়। আসুন প্রতিটি ক্ষেত্র পরীক্ষা করি:
সংস্করণ (4 বিট)
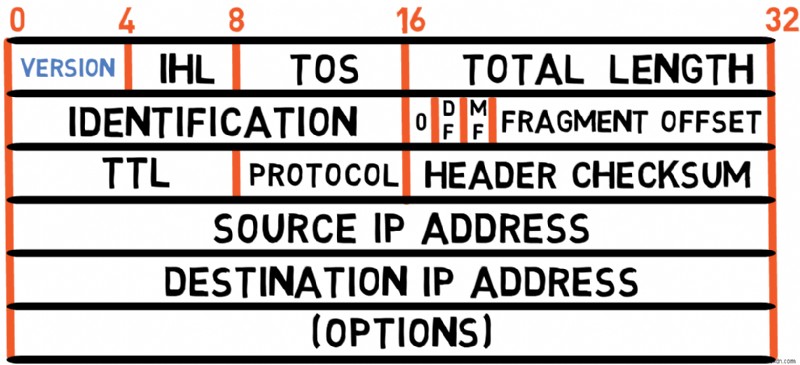
হেডারটি ভার্সন ফিল্ড দিয়ে শুরু হয়, যা চারটি বিট নিয়ে গঠিত। একটি IPv4 প্যাকেটের জন্য, সংস্করণটি হল 4 , তাই এই ক্ষেত্রটি সর্বদা 4 এর মান বহন করবে (বা 0100 বাইনারিতে)।
❓ কেন হেডার ভার্সন ফিল্ড দিয়ে শুরু হয়? 🤔
(দ্রষ্টব্য - যখন আমি ❓মার্ক দিয়ে একটি বাক্য শুরু করি - এটি আপনাকে সম্বোধন করা একটি প্রশ্ন, এবং আমি আপনাকে পড়ার আগে এটির উত্তর দেওয়ার জন্য উৎসাহিত করি)।
কারণ বাকি ক্ষেত্র সংস্করণ অনুযায়ী ভিন্ন হতে পারে. যদি একটি নেটওয়ার্ক ডিভাইস একটি IP প্যাকেট পড়ে এবং সংস্করণ ক্ষেত্রটি 4 এর মান বহন করে , এটা আশা করবে প্যাকেটের অবশিষ্টাংশ IPv4 কাঠামো অনুসরণ করবে। যদি এটি অন্য মান বহন করে, যেমন 6 , অবশিষ্ট ক্ষেত্রগুলি আলাদা, যেমন IPv6।

এই ক্ষেত্রটি নিজেই শিরোনামের দৈর্ঘ্য নির্দেশ করে৷
❓ কেন আমাদের দৈর্ঘ্য নির্দিষ্ট করতে হবে? 🤔
ইথারনেটের বিপরীতে, যেখানে হেডারের আকার স্থির থাকে, ঐচ্ছিক ক্ষেত্রের কারণে IPv4 হেডারের দৈর্ঘ্য পরিবর্তিত হতে পারে। বিশেষ বিকল্প ছাড়া একটি আইপি প্যাকেটের জন্য, হেডারে 20 থাকে বাইট, যা সবচেয়ে সাধারণ কেস।
IHL ক্ষেত্র সরাসরি বাইটে দৈর্ঘ্য নির্দিষ্ট করে না কিন্তু 4-বাইট শব্দের ইউনিটে। তাই 20 এর দৈর্ঘ্য নির্দিষ্ট করতে বাইট, মান হবে 5 (5 × 4 =20)। এই এনকোডিং 60 পর্যন্ত হেডারের দৈর্ঘ্য নির্দিষ্ট করার সময় ক্ষেত্রটিকে শুধুমাত্র 4 বিট ব্যবহার করার অনুমতি দেয় বাইট (যখন IHL =15 )।
একটি সাধারণ IPv4 প্যাকেট তাই বাইট 0x45 দিয়ে শুরু হয় হেক্সাডেসিমেলে, মানে এটির সংস্করণ 4 IP প্রোটোকলের, এবং হেডার হল 20 বাইট দীর্ঘ।
পরিষেবার প্রকার (TOS) (8 বিট)

এই ক্ষেত্রের পিছনে ধারণা হল যে সমস্ত প্যাকেট সমান গুরুত্বপূর্ণ নয়। আপনি হয়তো কিছু প্যাকেটকে অন্যের চেয়ে অগ্রাধিকার দিতে চাইতে পারেন।
উদাহরণস্বরূপ, রিয়েল-টাইম ডেটা বহনকারী প্যাকেটগুলি (যেমন ভয়েস বা ভিডিও কনফারেন্সিং) প্যাকেট বহন করে, বলুন, ইমেল বা ফাইল ডাউনলোডের চেয়ে বেশি সময়-সংবেদনশীল। যদি একটি রাউটার বর্তমানে উচ্চ লোডের সম্মুখীন হয়, তবে এটি আদর্শভাবে সময়-সংবেদনশীল প্যাকেটগুলিকে অগ্রাধিকার দেওয়া উচিত৷
পরিষেবার ধরন ক্ষেত্রটি প্রেরকদের তাদের প্যাকেটের অগ্রাধিকার নির্দেশ করতে দেয়। যাইহোক, সর্বজনীন ইন্টারনেটে, এই ক্ষেত্রটি প্রায়ই রাউটার দ্বারা উপেক্ষা করা হয় কারণ যে কোনো প্রেরক যেকোনো অগ্রাধিকার মান সেট করতে পারে। বেশিরভাগ ক্ষেত্রে, এই ক্ষেত্রটি 0 এর মান বহন করে .
মোট দৈর্ঘ্য (16 বিট)
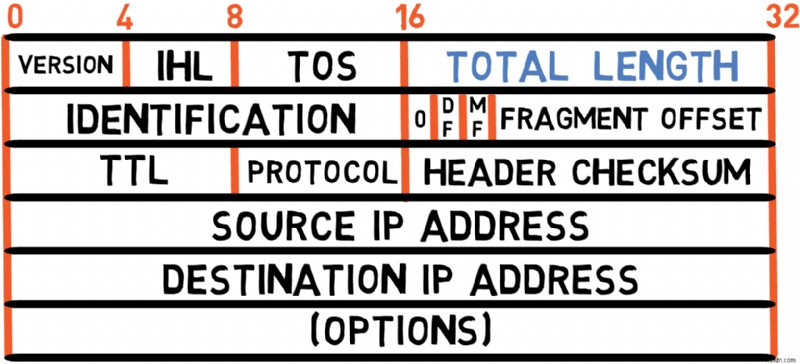
এই ক্ষেত্রটি হেডার এবং পেলোড (ডেটা) উভয়ই সহ IP প্যাকেটের মোট দৈর্ঘ্য নির্দিষ্ট করে।
❓ কেন দৈর্ঘ্য নির্দিষ্ট করার জন্য এটি প্রয়োজন? 🤔
Unfortunately, the IP layer doesn’t necessarily know if some of the bytes in the packet are actually a padding of the second layer. I described this in detail in a previous post, where I showed that in Ethernet protocol, in some cases, the receiving Ethernet entity cannot tell which bytes belong to the payload and which bytes are simply padding. The IP layer needs to know precisely which bytes belong to the actual packet, hence the Total Length field.
❓What is the maximum size of an IPv4 packet? 🤔
Since this field is 16 bits long, an IPv4 packet may contain a maximum of 2^16-1 bytes, or 65,535 bytes, including the header. The minimum size is 20 bytes, consisting of just the header without options or payload.
Fragmentation Fields (32 bits)
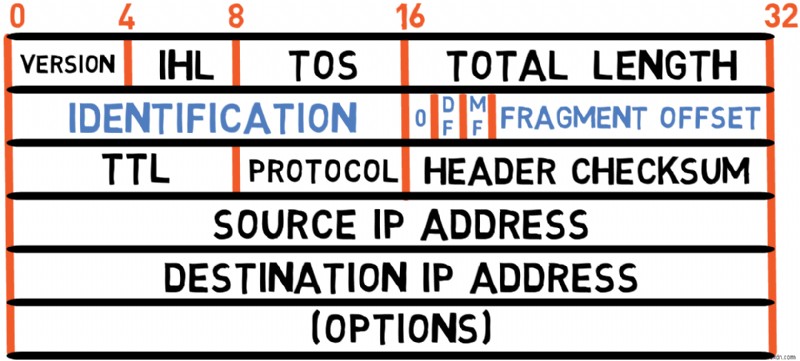
The next four bytes are dedicated to fragmentation control. I’ll cover these fields in a separate section, as they involve a complex topic deserving special attention.
Time to Live (8 bits)

Despite its name, this field doesn't actually measure time but rather the maximum number of routing hops a packet can traverse before being discarded.
To understand its purpose, consider this scenario:If Machine A sends a packet to Machine B through a series of routers, but there's a routing loop where Router 2 sends to Router 3, which sends to Router 4, which sends back to Router 2, the packet could circulate indefinitely, consuming bandwidth and never reaching its destination.
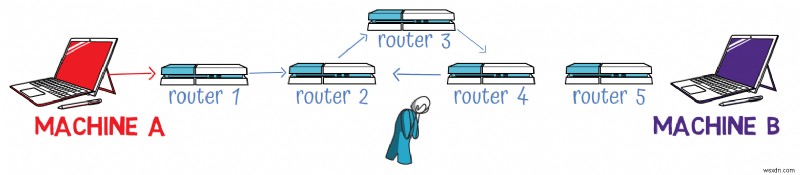
The TTL field prevents this by setting a limit on how many hops a packet can take:
-
The sender sets an initial TTL value (often
64or128) -
Each router that handles the packet decrements the TTL by
1 -
If a router receives a packet with TTL =
1, it decrements it to0and discards the packet -
The router then sends an ICMP "Time Exceeded" message back to the original sender
This doesn't solve the underlying problem of routing loops, but it prevents packets from circulating forever.
In IPv6, this field is renamed "Hop Limit," which more accurately describes its function.
Protocol (8 bits)

This field describes the payload of the IPv4 packet. যেমন:
-
A value of
6means the payload is TCP -
A value of
17means the payload is UDP
This helps the receiving system know which protocol handler should process the packet's contents. It's similar to the Type field in Ethernet, which specifies the protocol of the layer encapsulated within the Ethernet frame.
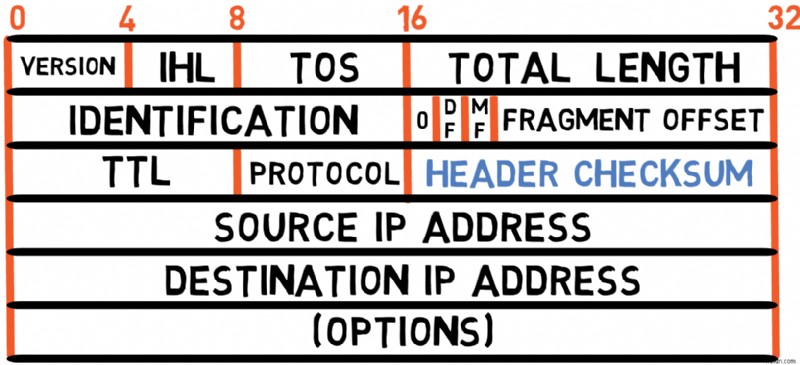
This is a 16-bit checksum used to verify the validity of the header only (that is, excluding the payload). The sender computes this value based on the fields of the header, and the receiver also computes it to validate that the header was received correctly.
❓The checksum must be recalculated by each router. কেন এমন হল? 🤔
Because the TTL field changes at each hop. For example, if a packet starts with TTL =7 , each router will:
-
Verify the current checksum based on TTL =
7 -
Decrement TTL to
6 -
Calculate a new checksum based on TTL =
6 -
Forward the packet with the new checksum
If the checksum verification fails, the device drops the packet. This prevents packets with corrupted headers (which might have incorrect destination addresses, for instance) from being forwarded.
Source and Destination Addresses (32 bits each)
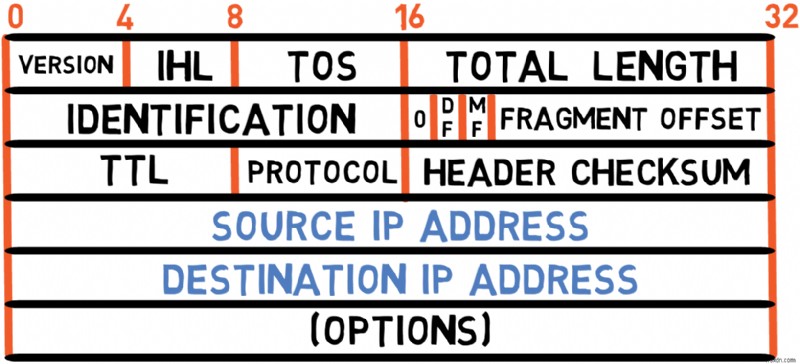
These fields contain the source and destination IPv4 addresses, respectively. Each is 4 bytes (32 bits) long, as you learned in the previous sections on IPv4 addressing.
Options (Variable Length)
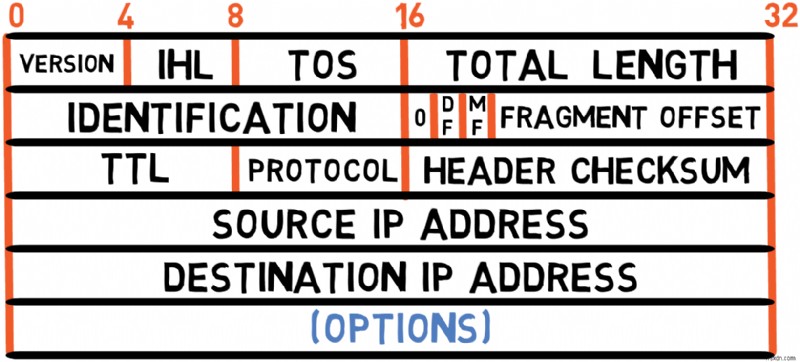
Most IPv4 packets don't include options, but when present, they can provide additional functionality:
-
Record Route :Each router that handles the packet adds its own address to this option, creating a trace of the packet's path
-
Source Routing :Allows the sender to specify the route the packet should take:
-
Strict Source Routing:The entire route must be followed exactly
-
Loose Source Routing:Certain routers must be traversed, but the exact path between them is flexible
-
Padding
In some cases, the header ends with padding bytes (usually 0 s).
❓Why does the IPv4 header have padding?🤔
As explained before, the IHL field specifies the header length in 4-byte units, so the total header length must be a multiple of 4 bytes. If options make the header length not divisible by 4, padding bytes (usually 0 ) are added to reach the next multiple of 4.
For example, if you have 3 bytes of options, you would need 1 byte of padding to make the total header length a multiple of 4 bytes.
You've now learned about the structure of the IPv4 header, with the exception of the fragmentation fields which I’ll cover in the next section.
The IPv4 header efficiently packs all the necessary routing and control information into a compact structure, typically 20 bytes long (without options). This design allows for fast processing by routers while providing the flexibility needed for internet communication. It is amazing how prominent IPv4 is, even so many years after its publication.
In the next section, you'll learn about IPv4 fragmentation.
IPv4 Fragmentation
In the previous section, you learned about most of the IPv4 header structure, with the exception of 32 bits dedicated to fragmentation. This topic deserves special attention, as it reveals important aspects of how IP packets travel across different networks.
Why Fragmentation Is Needed
To understand what fragmentation is and why it's needed, consider the following network scenario:
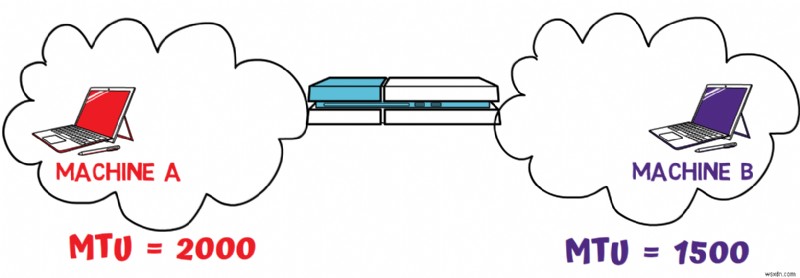
In this diagram, you have two different networks where Machine A resides in one network and Machine B resides in another. A router forwards packets between these two networks.
These two networks have different Maximum Transmission Units (MTUs). MTU refers to the maximum size of a frame that can be transmitted in a network. যেমন:
-
Machine B is connected to an Ethernet network with an MTU of
1500bytes -
Machine A is connected to a different network with an MTU of
2000bytes
Different MTUs stem from the different protocols and hardware that different networks have. Ethernet has an MTU of 1500 বাইট This maximum size was chosen because RAM was expensive back in the late 1970s when Ethernet was planned, and a receiver would need more RAM if a frame could be bigger. Other networks were devised at different times where RAM prices might have been lower, or just have other considerations that affect the MTU.
Now, consider this scenario:Machine A wants to send a packet to Machine B. This packet is 1800 bytes long. From A's perspective, there's no problem since its network supports packets of this size. Machine A transmits the packet.
When the router receives this packet, it faces a problem:it cannot simply forward the packet to B's network because the packet is too big for the network's MTU. The router must fragment the packet – splitting it into smaller chunks of up to 1500 bytes, which will then be reassembled by Machine B.
How Fragmentation Works in IP
Let's examine the scenario further. The router needs to take an IP packet of 1800 bytes and split it into two fragments, each consisting of up to 1500 বাইট If Machine A sends another packet of 1800 bytes to Machine B, the router will have to split that one too – resulting in four different fragments that will be reassembled into two separate packets.

When Machine B receives these fragments, it must ensure that it reassembles fragment #1 together with fragment #2 of packet A, and fragment #1 with fragment #2 of packet B – and not, for instance, fragment #1 of packet A with fragment #2 of packet B. It must also reassemble the fragments in the correct order – so structure a packet that consists of #1#2 and not #2#1.

Identification Field
First, focus on making sure Machine B reassembles fragments of the same packet (for example, fragment #1 and fragment #2 of packet A in the example above, rather than fragment #1 of packet A and fragment #2 of packet B). This is achieved using the identification field of IPv4. Fragments belonging to the same packet will have the same identification value. For example, both fragments of packet A might have identification set to 100 , and both fragments of packet B might have identification of 200 .

It's important to note that sharing identification values isn't sufficient for fragments to belong to the same packet. Fragments of the same packet must also share:
-
The same source IP address
-
The same destination IP address
-
The same protocol value (indicating whether the payload is TCP, UDP, and so on)
Fragment Offset
Since IP is a connectionless protocol, there's no guarantee that fragments will arrive at Machine B in the correct order. Fragment #2 of packet A may arrive before fragment #1. To handle this issue, each fragment carries an Offset field, which denotes the offset from the beginning of the original packet.
The Offset field consists of 13 bits, which means it can carry values from 0 to 8191 (2^13-1). This poses a potential problem, as the maximum size of an IP packet can be 65,535 bytes (since the Total Length field of the IP header consists of 16 bits).
To address this limitation, the value encoded in the Offset field is actually multiplied by 8 (2^3). This means the minimum size of a fragment is 8 bytes, with the exception of the last fragment.
❓Why do IP packets carry an offset in bytes divided by 8, instead of just a sequential fragment number?🤔
While using sequence numbers might seem simpler, it would create problems when packets need to be fragmented multiple times.
For example, if Computer A sends a packet to the first router, which fragments it into pieces of 1480 bytes and 320 bytes, and then these fragments are sent to another router that needs to fragment them again into even smaller pieces, how would you number them?
With byte offsets, the solution is straightforward – if the first fragment has an offset of 0 and the next one has an offset of 1480 , then if we need to split them into maximum 800 -byte fragments, we'd have:
-
First fragment:
800bytes with offset0 -
Second fragment:
680bytes with offset800 -
Third fragment:
320bytes with offset1480
More Fragments and Don't Fragment Flags
When Machine B receives a fragment, it needs to know whether this is an entire packet by itself or if it should expect additional fragments. For this purpose, each IP fragment carries a More Fragments (MF ) bit that is set to 1 for every fragment that is not the last fragment of the packet. For the last fragment, it's set to 0 .
In case the packet consists of a single fragment – the MF bit will be set to 0 , and the offset field will also hold the value 0 (that is, 13 bits of 0 s).
Another bit related to fragmentation is the Don't Fragment (DF ) bit. When this flag is turned on, intermediate devices should not fragment the original packet, even if it exceeds the MTU. Instead, they should drop it and typically send an ICMP "Fragmentation Needed" message back to the source.
In our example, if Machine A sets the Don't Fragment bit to 1 , the router would drop the packet, and notify Machine A about it.
Note that right after the identification field and before the DF flag, there is a reserved bit set to 0 . This bit was reserved in case it is needed in the future, for a reason unknown to the original authors of IPv4.
Fragmentation Example
Consider again our example above – with Machine A residing in a network where the MTU is 2000 , and Machine B residing in a network where the MTU is 1500 . Machine A sends a packet which is 1800 bytes long.
❓Can you fill the values in these tables?
First Fragment:
Total Length IdentificationDon’t FragmentMore FragmentsOffsetSecond Fragment:
Total Length IdentificationDon’t FragmentMore FragmentsOffsetFor our example above, the values of the relevant fragmentation fields in IP would be as follows:
First Fragment:
-
Total Length:
1500(including20bytes of IP header, so1480bytes of payload) -
Identification:
1337(arbitrary value) -
Don't Fragment bit:
0(off, to allow further fragmentation if needed) -
More Fragments bit:
1(on, as this is not the last fragment) -
Offset:
0(it's the first fragment)
Second Fragment:
-
Total Length:
340(including20bytes of IP header, so320bytes of payload – together with the first fragment, we get to1800bytes of payload) -
Identification:
1337(same as first fragment, indicating they belong together) -
Don't Fragment bit:
0(off, to allow further fragmentation if needed) -
More Fragments bit:
0(off, as this is the last fragment) -
Offset:
185(1480/8 =185, or0xB9in hexadecimal)
IPv4 Fragmentation – Summary
You've now learned about the final part of the IPv4 Header:fragmentation. Fragmentation is necessary to allow packets to travel across networks with different MTUs. The IPv4 header includes several fields specifically designed to support fragmentation:
-
Identification (16 bits):Identifies which fragments belong together
-
Flags (3 bits):Including the "More Fragments" and "Don't Fragment" flags
-
Fragment Offset (13 bits):Indicates where in the original packet this fragment belongs
With this knowledge, you now understand every bit and byte of the IPv4 header and how IP packets can traverse networks with different characteristics.
Summary – IPv4
In this comprehensive guide to IPv4, you've learned about the fundamental building blocks of Internet communications. Let's recap the key concepts we covered:
Addressing and Network Structure
-
IPv4 addresses are 32-bit numbers typically written in dotted decimal notation
-
Networks can be identified using various methods:
-
Fixed-length approach (historically)
-
Classful addressing (A, B, C, D, E classes)
-
CIDR (modern approach allowing flexible network sizes)
-
-
Special addresses serve specific purposes:
-
0.0.0.0for "this host" -
127.0.0.0/8for loopback -
255.255.255.255for broadcast
-
-
The header contains crucial fields for packet routing and processing:
-
Version and IHL for header interpretation
-
Type of Service for traffic prioritization
-
Total Length for packet size
-
Various fields for fragmentation control
-
TTL to prevent infinite routing loops
-
Protocol to identify the encapsulated protocol
-
Checksum for error detection
-
Source and destination addresses
-
Fragmentation
-
Allows IPv4 packets to traverse networks with different MTUs
-
Uses three key fields:
-
Identification to group fragments
-
Flags to control fragmentation
-
Fragment Offset to reassemble packets
-
Final Words
While IPv4 has limitations, particularly its address space constraints, its elegant design and robust features have allowed it to remain the backbone of the Internet for over four decades. Understanding IPv4 provides essential context for working with modern networks and helps in transitioning to newer protocols like IPv6.
About the Author
Omer Rosenbaum is Swimm’s Chief Technology Officer. He's the author of the Brief YouTube Channel. He's also a cyber training expert and founder of Checkpoint Security Academy. He's the author of Gitting Things Done (in English) and Computer Networks (in Hebrew). You can find him on Twitter.
Additional References
- Computer Networks Playlist - on my Brief channel
বিনামূল্যে কোড শিখুন. freeCodeCamp-এর ওপেন সোর্স পাঠ্যক্রম 40,000-এরও বেশি লোককে ডেভেলপার হিসেবে চাকরি পেতে সাহায্য করেছে। শুরু করুন
