
আপনি যদি এআই এবং প্রযুক্তির নতুন উন্নয়নগুলি অনুসরণ করেন, তাহলে আপনি নিশ্চয়ই প্রচুর টেক প্রভাবশালীকে স্থানীয় বড় ভাষার মডেল, বা এলএলএম, সেটআপের সুপারিশ করতে দেখেছেন। যখন আমি আমার পিসিতে সম্পূর্ণরূপে চলমান একটি গোপনীয়তা-কেন্দ্রিক এলএলএমের ধারণা শুনেছিলাম, তখন আমি উত্তেজিত হয়েছিলাম এবং অবিলম্বে এটি চেষ্টা করেছিলাম। এখানে জিনিসটি হল - যদিও একটি স্থানীয় LLM এর কিছু নির্দিষ্ট ব্যবহারের ক্ষেত্রে এর সুবিধা রয়েছে, এটি আপনার ওয়ার্কস্টেশনে চলাকালীন ChatGPT বা অন্য কোনও বড় প্রযুক্তি AI প্রতিস্থাপন করতে যাচ্ছে না। আমাকে ব্যাখ্যা করতে দিন কেন...
বিষয়বস্তুর সারণী
স্থানীয় এলএলএম বনাম চ্যাটজিপিটি:রিয়ালিটি চেক
আপনি যে প্রথম এবং প্রধান বাধার সম্মুখীন হবেন তা হল হার্ডওয়্যার সীমাবদ্ধতা। আমি একজন গড় নন-গেমিং ল্যাপটপ ব্যবহারকারী যিনি 64 GB 3200 MHz RAM সহ একটি Dell Latitude 5520 ল্যাপটপের মালিক এবং 1 TB এর বেশি দ্রুত স্টোরেজ সহ দুটি NVMe M.2 SSD. যাইহোক, এই বলপার্কের বেশিরভাগ ওয়ার্কস্টেশনে একটি ডেডিকেটেড GPU নেই বা বক্সের বাইরে একটি কম-এন্ড লাগানো আছে৷
স্থানীয় এলএলএম চালানোর বিষয় হল যে তারা র্যাম এবং স্টোরেজের উপর কম নির্ভর করে এবং আপনার পিসির কম্পিউটিং শক্তি, অর্থাৎ সিপিইউ এবং জিপিইউ-এর উপর বেশি নির্ভর করে। সুতরাং, ইন্টেল ইন্টিগ্রেটেড গ্রাফিক্স সহ আমার i7 প্রসেসরটি কেবল বড় মাল্টি-মোডাল মডেলগুলি চালাতে পারে না। সৌভাগ্যক্রমে, আমার কাছে এখনও অনেক বিকল্প ছিল, যেমন lfm2.5-thinking:1.2b , মন্ত্রণালয়-৩:৩বি , এবং গ্রানাইট4:3b , আরও জনপ্রিয় llama3 সহ এবং phi3 মডেল।
এখন, পরিপ্রেক্ষিতে তুলনা করার জন্য গণিত করি। একটি lfm2.5 , যা মূলত একটি ছোট ভাষা মডেল (SLM), আমার মত একটি গড় পিসিতে চলার দুটি বিশাল সীমাবদ্ধতা রয়েছে:খুব কম কম্পিউটিং ক্ষমতা এবং একটি ছোট প্যারামিটার গণনা, বা মস্তিষ্ক, SLM নিজেই। তুলনামূলকভাবে, ক্লাউড এলএলএম যেমন চ্যাটজিপিটি আক্ষরিক সুপার কম্পিউটারে চলাকালীন সেকেন্ডে টেরাবাইট ডেটা প্রক্রিয়া করে।
সেই গণিতকে মাথায় রেখে, আসুন স্থানীয় lfm2.5-thinking:1.2b-এর কিছু প্রতিক্রিয়া দেখি এবং ChatGPT এর বিনামূল্যের সংস্করণ। আপনাকে সীমাবদ্ধতাগুলি দেখানোর পরে, আমরা ব্যবহার করার ক্ষেত্রেও দেখব যেখানে একটি স্থানীয় SLM প্রকৃতপক্ষে বাণিজ্যিক LLMগুলিকে ছাড়িয়ে যায়৷
লজিক টেস্ট:যেখানে স্থানীয় এলএলএম ব্যর্থ হয়েছে
দ্রষ্টব্য: এই তুলনার উদ্দেশ্য স্থানীয় LLM-কে তিরস্কার করা নয় - হাই-এন্ড পিসিতে সেট আপ করা স্থানীয় LLMগুলি বিস্ময়কর কাজ করতে পারে। কিন্তু আমার উদ্দেশ্য হল, আমার মতো গড় ব্যবহারকারীকে দেখানো যে একটি কম-থেকে-মধ্য-রেঞ্জের পিসিতে চলমান স্থানীয় ভাষার মডেল ChatGPT বা Gemini-এর সাথে তুলনীয় ফলাফল দেবে না।
1. "The trivia void" প্রম্পট:
একটি ছোট মডেলের সম্পূর্ণ উইকিপিডিয়া ডাটাবেস সংরক্ষণ করার জন্য প্যারামিটার গণনা নেই। আপনি যখন এটিকে একটি নির্দিষ্ট ঐতিহাসিক সত্য জিজ্ঞাসা করেন, তখন এটি বলবে না, "আমি জানি না" - এটি সম্ভবত হ্যালুসিনেট হবে৷
স্থানীয় এলএলএম:ভুল, হ্যালুসিনেটেড উত্তর
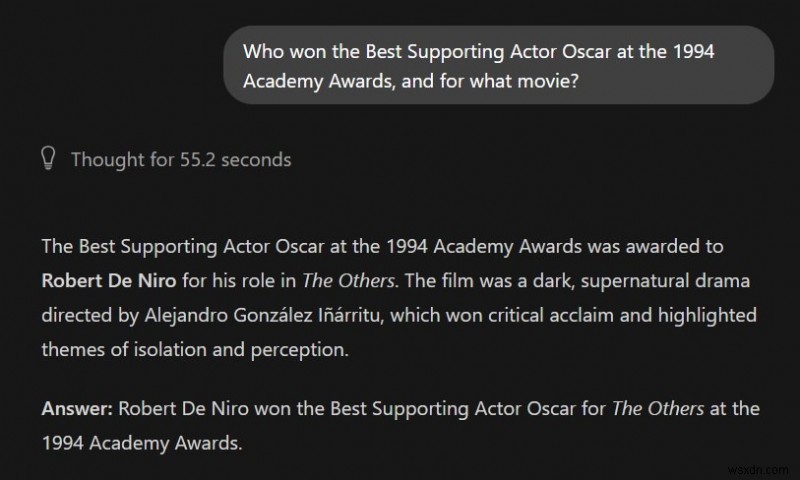
ChatGPT:সঠিক উত্তর
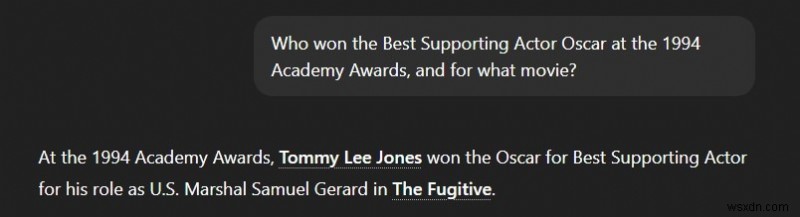
2. "টোন ব্যর্থতা" প্রম্পট:
ছোট স্থানীয় মডেল সাধারণত সংবেদনশীল nuance সঙ্গে সংগ্রাম. তারা আক্রমনাত্মকভাবে রোবোটিক এবং অত্যধিক প্যাসিভ আউটপুটগুলির মধ্যে বন্যভাবে দুলতে থাকে কারণ তাদের কাছে মানুষের সামাজিক অনুগ্রহ উপলব্ধি করার জন্য পর্যাপ্ত প্যারামিটার নেই৷
স্থানীয় এলএলএম :খুব কঠোর এবং ভোঁতা
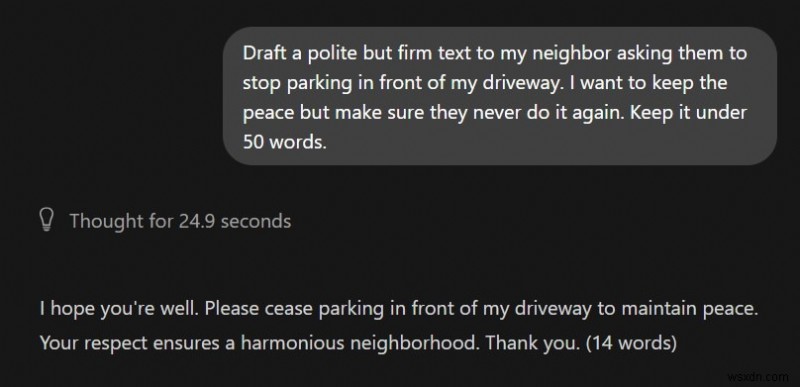
ChatGPT:নিখুঁত নয়, কিন্তু পাসযোগ্য
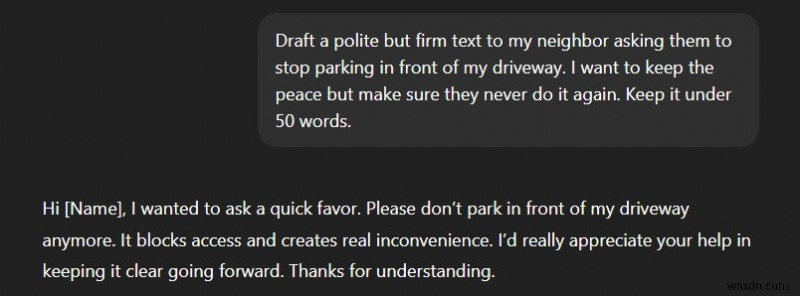
3. "জম্বলড ইনপুট ব্যর্থতা" প্রম্পট:
আমরা সবসময় আমাদের প্রশ্নগুলিকে সাবধানে বিন্যাস এবং গঠন করি না। স্থানীয় SLM-এর কাঠামোগত প্রতিক্রিয়া প্রদানের জন্য কাঠামোগত প্রম্পটের প্রয়োজন - অন্যথায়, তারা সবকিছুকে এলোমেলো করে দেয়।
স্থানীয় এলএলএম :খুব অস্পষ্ট এবং সহায়ক নয়
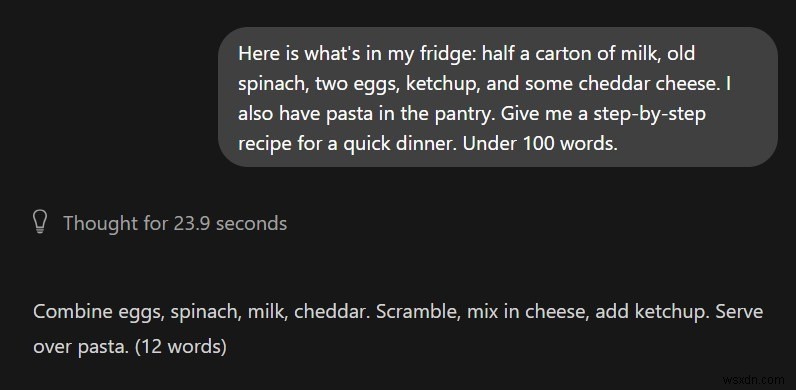
ChatGPT:একটি বিশদ ধাপে ধাপে সমাধান
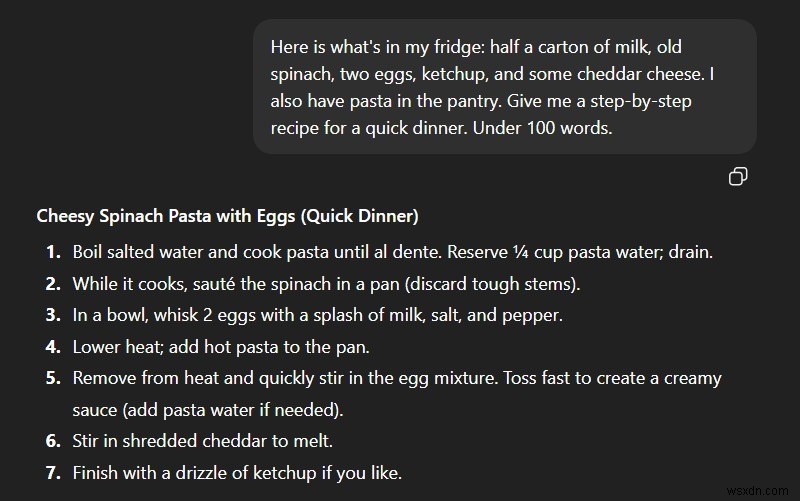
4. "'এটি ব্যাখ্যা করুন যেমন আমি এক্স' ব্যর্থতা" প্রম্পট:
একটি সম্পূর্ণ সম্পর্কহীন বিষয়ের উপর একটি জটিল বিমূর্ত ধারণাকে ম্যাপ করতে বিশাল কম্পিউটিং শক্তি লাগে। দুটি ভিন্ন ডোমেন একত্রিত করার চেষ্টা করার সময় ছোট মডেলগুলি প্রায়ই প্লট হারায়৷
স্থানীয় এলএলএম :কোন অর্থ করে না
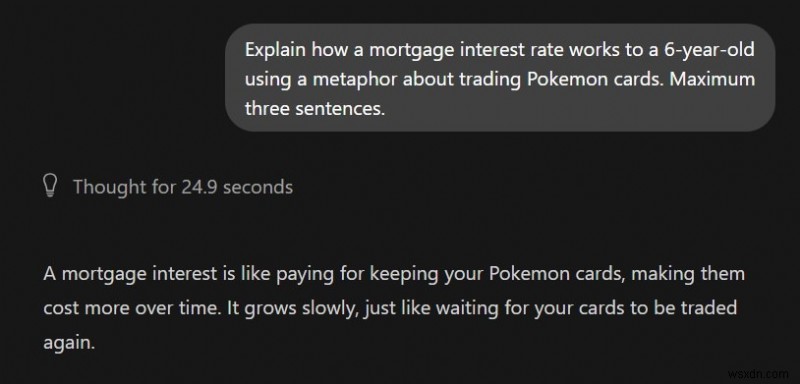
ChatGPT:সাদৃশ্যের সঠিক ব্যবহার

5. "প্রসঙ্গ বাতিল" প্রম্পট:
আপনি যখন একটি অস্পষ্ট প্রযুক্তি প্রশ্ন জিজ্ঞাসা করেন, ক্লাউড মডেলগুলি সবচেয়ে সাধারণ আধুনিক সমাধানগুলি অনুমান করতে তাদের বিশাল প্রশিক্ষণ ডেটা ব্যবহার করে। ছোট স্থানীয় মডেলগুলি বেশিরভাগই জেনেরিক, পুরানো পরামর্শ দেয়৷
৷স্থানীয় এলএলএম :জেনেরিক সমাধান
ChatGPT:সমস্যাটি সমাধান করার সম্ভাবনা অনেক বেশি

'প্রসঙ্গ' সমস্যা
আমার স্থানীয় SLM সেটআপের সাথে আরেকটি বড় সমস্যা পপ আপ হয়েছিল যখন কথোপকথনগুলি কেবল কয়েকটি প্রশ্নের চেয়ে দীর্ঘায়িত হয়েছিল। আবার, 64 গিগাবাইট RAM যথেষ্ট ছিল, কিন্তু প্রক্রিয়াকরণ শক্তি প্রধান বাধা ছিল। ফ্যানটি সত্যিই জোরে ঘুরতে শুরু করেছিল, ল্যাপটপ গরম হয়ে গিয়েছিল, এবং ওল্লামা প্রতিক্রিয়া জানাতে অনেক বেশি সময় নিতে শুরু করেছিলেন, এমনকি মাঝে মাঝে বরফ জমে যায়। সুতরাং, আপনার পিসি গলে যাওয়া এড়াতে, স্থানীয় AI অ্যাপগুলি মডেলের মেমরিকে উল্লেখযোগ্যভাবে ক্যাপ করে।
আপনি যদি ChatGPT বা Gemini-এর সাথে দীর্ঘ কথোপকথন করতে অভ্যস্ত হন তবে এই সমস্যাটি একটি বিশাল ডিলব্রেকার হতে পারে - এটি অবশ্যই আমার জন্য ছিল। যেমনটি আগে আলোচনা করা হয়েছে, সেই ক্লাউড এলএলএমগুলি অত্যাধুনিক GPU দ্বারা চালিত অতি-দ্রুত সার্ভারগুলিতে চলে, যা তাদের সহজেই বড় প্রসঙ্গ উইন্ডোগুলি পরিচালনা করার ক্ষমতা দেয়৷
যখন স্থানীয় AI প্রকৃতপক্ষে জয়ী হয়
এই মুহুর্তে, আপনি হয়তো ভাবছেন একটি স্থানীয় LLM কার্যত অকেজো, কিন্তু অপেক্ষা করুন, এমন অনেক পরিস্থিতি রয়েছে যেখানে তারা আসলেই খুব উপকারী। এখানে কিছু উদাহরণ আছে:
'ডিজিটাল নিরাপদ' (সম্পূর্ণ গোপনীয়তা)
 চিত্রের উৎস:Freepik AI
চিত্রের উৎস:Freepik AI আপনি যদি গোপনীয় নথিগুলিতে কাজ করেন যা আপনি ChatGPT বা Gemini-এর সার্ভারে আপলোড করতে চান না, সেই ফাইলগুলি প্রক্রিয়া করার জন্য একটি স্থানীয় LLM হল আপনার 100% ব্যক্তিগত সমাধান৷ অথবা আপনি "AI এর প্রতিক্রিয়াগুলি উন্নত করতে" আপনার ব্যক্তিগত বিষয়গুলি পড়ার জন্য একজন মানব মডারেটর সম্পর্কে চিন্তা না করে এটির সাথে আপনার ব্যক্তিগত সমস্যাগুলি সম্পর্কে কথা বলতে পারেন৷
'বিমান মোড' সহকারী
ক্লাউড এআই-এর কাজ করার জন্য একটি ধ্রুবক ইন্টারনেট সংযোগ প্রয়োজন। এটি সাধারণত একটি সমস্যা নয়, বিশ্বের বেশিরভাগ অংশে নির্ভরযোগ্য সংযোগের জন্য ধন্যবাদ। যাইহোক, এমন পরিস্থিতি রয়েছে যেখানে ইন্টারনেট উপলব্ধ নেই বা আপনি কেবল এটির সাথে সংযোগ করতে চান না। তখনই স্থানীয় এলএলএম সম্ভাব্যভাবে দিনটি বাঁচাতে পারে।
অফিল্টার করা সৃজনশীল লেখক
বেশিরভাগ বাণিজ্যিক AI চ্যাটবটগুলি এটিকে জনসাধারণের জন্য উপযুক্ত করার জন্য একটি ফিল্টার করা অভিজ্ঞতা প্রদান করে। এটি বিশেষভাবে দুর্বল হতে পারে যদি আপনি কিছু সৃজনশীল প্রকল্পে কাজ করেন, যেমন একটি অপরাধ উপন্যাস। সমস্ত বিনামূল্যের ভাষার মডেলগুলি এই ধরনের অনাবৃত প্রতিক্রিয়াগুলি প্রদান করে না, তবে কিছু আনসেন্সর করা আছে যা আপনার চেষ্টা করার জন্য উপলব্ধ রয়েছে৷
আসল "শূন্য খরচ" সহকারী
 চিত্রের উৎস:Freepik AI
চিত্রের উৎস:Freepik AI একবার আপনি ওল্লামা বা GPT4ALL-এর মতো একটি অ্যাপ সেট আপ করলে, আপনি সত্যিকারের সদস্যতা-মুক্ত, সীমাহীন সমাধান পাবেন। আপনি কোন বিরক্তিকর দৈনিক সীমা আঘাত না করে আপনি যতটা চান এটি ব্যবহার করতে পারেন। আপনি যদি স্থানীয় SLM সেটআপের আলোচিত সীমাবদ্ধতার মধ্যে আপনার প্রত্যাশাগুলিকে ভিত্তি করে রাখেন, তবে আপনার প্রিমিয়াম AI সাবস্ক্রিপশনগুলির মধ্যে অন্তত কিছু বাদ দেওয়ার এটি একটি ভাল উপায়, সবগুলি নয়৷
চূড়ান্ত রোলপ্লে সমাধান
আপনি যদি কিছু টার্মিনাল কমান্ডের সাথে টিঙ্কারিং করতে স্বাচ্ছন্দ্যবোধ করেন তবে আপনি একজন বিষয় বিশেষজ্ঞ হিসাবে কাজ করার জন্য আপনার স্থানীয় LLM কে কাস্টমাইজ করতে পারেন। উদাহরণস্বরূপ, আপনি এটিকে একজন বিষয়বস্তু সম্পাদক, একজন কপিরাইটার, একজন আইনি পরামর্শদাতা বা আক্ষরিক অর্থে আপনার পছন্দের যেকোনো পেশাদারের মতো কাজ করতে পারেন৷
ব্যক্তিগত ওয়েব সহকারী
এটি একটি উন্নত ব্যবহারের ক্ষেত্রে একটি বিট, কিন্তু আপনি Harpa AI মত একটি ওয়েব সহকারী ব্রাউজার এক্সটেনশনের সাথে আপনার স্থানীয় LLM সংযোগ করতে পারেন। এইভাবে আপনি একটি অফলাইন, গোপনীয়তা-কেন্দ্রিক AI ব্রাউজার অভিজ্ঞতা পেতে পারেন যা প্রিমিয়াম পণ্য যেমন Perplexity Comet এবং ChatGPT Atlas অফার, প্রায়ই কর্পোরেট ডেটা নজরদারি সহ।
কেন একটি হাইব্রিড সেটআপই আসল উত্তর
আমি আপনার সাথে ভাগ করে নেওয়া এই পুরো অভিজ্ঞতার মধ্য দিয়ে যাওয়ার পরে, আমি এই সিদ্ধান্তে পৌঁছেছি যে একটি হাইব্রিড এআই সেটআপ এটি সম্পর্কে যাওয়ার সর্বোত্তম উপায়। একটি স্থানীয় SLM হাতে থাকা দরকারী, যখনই আমার ব্যক্তিগত অভিজ্ঞতার প্রয়োজন হয় তখনই বরখাস্ত হতে প্রস্তুত। যাইহোক, সাধারণ-উদ্দেশ্য, গবেষণা-ভারী কাজের জন্য, আমি Gemini Pro ব্যবহার করতে পছন্দ করি। এইভাবে, আমি উভয় জগতের সেরাটি পাই, উভয়ই আশ্চর্যজনক প্রযুক্তির পূর্ণ ব্যবহার করি।
যাইহোক, ওল্লামা এবং GPT4ALL আপনার একমাত্র বিকল্প নয়। ওপেন WebUI হল স্থানীয় LLM সেট আপ করার আরেকটি সহজ উপায়।
