
উন্নত ভেক্টর এক্সটেনশন (AVX , স্যান্ডি ব্রিজ নতুন এক্সটেনশন নামেও পরিচিত৷ ) হল মার্চ 2008 সালে ইন্টেল দ্বারা প্রস্তাবিত ইন্টেল এবং এএমডি থেকে মাইক্রোপ্রসেসরের জন্য x86 নির্দেশনা সেট আর্কিটেকচারের এক্সটেনশন এবং প্রথমে Q1 2011-এ স্যান্ডি ব্রিজ প্রসেসর শিপিংয়ের সাথে ইন্টেল দ্বারা সমর্থিত এবং পরবর্তীতে Q1 বা Bulldship 0 প্রসেস-এ এএমডি 3ওজশিপিং। নতুন বৈশিষ্ট্য, নতুন নির্দেশাবলী এবং একটি নতুন কোডিং স্কিম প্রদান করে৷
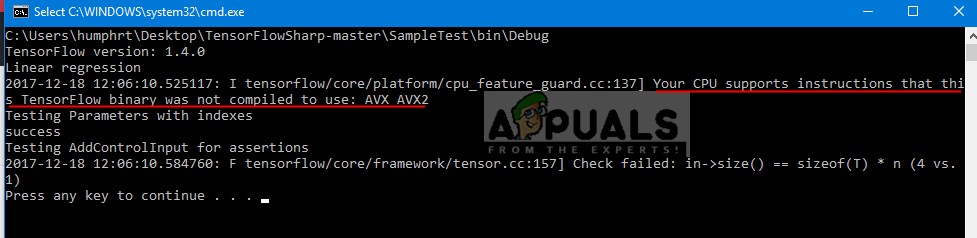
এই সতর্কতা বার্তাটি TensorFlow-এর শেয়ার করা লাইব্রেরি দ্বারা প্রিন্ট করা হয়েছে৷ বার্তাটি যেমন ইঙ্গিত করে, শেয়ার করা লাইব্রেরিতে আপনার সিপিইউ ব্যবহার করতে পারে এমন নির্দেশাবলী অন্তর্ভুক্ত করে না৷
এই সতর্কতার কারণ কি?
TensorFlow 1.6 এর পরে, বাইনারিগুলি এখন AVX নির্দেশাবলী ব্যবহার করে যা আর পুরানো CPU-তে নাও চলতে পারে। সুতরাং পুরানো CPUগুলি AVX চালাতে অক্ষম হবে, যখন নতুনগুলির জন্য, ব্যবহারকারীকে তাদের CPU-এর জন্য উত্স থেকে টেনসরফ্লো তৈরি করতে হবে। নীচে এই বিশেষ সতর্কতা সম্পর্কে আপনার জানা দরকার এমন সমস্ত তথ্য রয়েছে৷ এছাড়াও, ভবিষ্যতে ব্যবহারের জন্য এই সতর্কতা থেকে পরিত্রাণ পাওয়ার একটি পদ্ধতি৷
AVX কি করে?
বিশেষ করে, AVX এফএমএ (ফিউজড মাল্টিপ্লাই-অ্যাড) চালু করেছে; যা ফ্লোটিং-পয়েন্ট মাল্টিপ্লাই-অ্যাড অপারেশন, এবং এই সমস্ত অপারেশন একক ধাপে সম্পন্ন হয়। এটি কোনো সমস্যা ছাড়াই অনেকগুলি ক্রিয়াকলাপের গতি বাড়াতে সাহায্য করে। এটি বীজগণিত গণনাকে আরও দ্রুত এবং সহজ ব্যবহার করে, এছাড়াও ডট-প্রোডাক্ট, ম্যাট্রিক্স মাল্টিপ্লাই, কনভোলিউশন ইত্যাদি। এবং এগুলি প্রতিটি মেশিন-লার্নিং প্রশিক্ষণের জন্য সবচেয়ে বেশি ব্যবহৃত এবং মৌলিক ক্রিয়াকলাপ। AVX এবং FMA সমর্থন করে এমন CPUগুলি পুরানোগুলির তুলনায় অনেক দ্রুত হবে৷ কিন্তু সতর্কবার্তাটি বলে যে আপনার CPU AVX সমর্থন করে, তাই এটি একটি ভাল পয়েন্ট৷
৷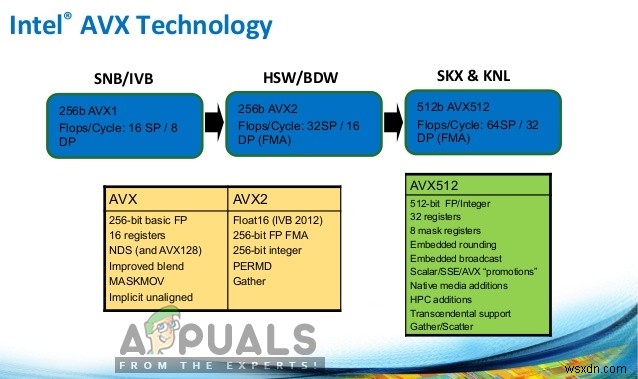
এটি ডিফল্টরূপে ব্যবহার করা হয় না কেন?
কারণ TensorFlow ডিফল্ট ডিস্ট্রিবিউশন CPU এক্সটেনশন ছাড়াই তৈরি করা হয়েছে। CPU এক্সটেনশন দ্বারা এটি AVX, AVX2, FMA, ইত্যাদি বলে। এই সমস্যাটিকে ট্রিগার করে এমন নির্দেশাবলী উপলব্ধ ডিফল্ট বিল্ডগুলিতে ডিফল্টরূপে সক্রিয় করা হয় না। তাদের সক্রিয় না হওয়ার কারণ হল যতটা সম্ভব CPU-এর সাথে এটিকে আরও সামঞ্জস্যপূর্ণ করা। এছাড়াও এই এক্সটেনশনগুলি তুলনা করার জন্য, সেগুলি GPU এর পরিবর্তে CPU-তে অনেক ধীর। CPU ছোট আকারের মেশিন-লার্নিং-এ ব্যবহৃত হয় যখন GPU-এর ব্যবহার প্রত্যাশিত হয় যখন এটি একটি মাঝারি বা বড়-স্কেল মেশিন-লার্নিং প্রশিক্ষণের জন্য ব্যবহার করা হয়।
সতর্কতা ঠিক করা হচ্ছে!
এই সতর্কবাণী শুধুমাত্র সহজ বার্তা. এই সতর্কতাগুলির উদ্দেশ্য হল উৎস থেকে নির্মিত TensorFlow সম্পর্কে আপনাকে জানানো। আপনি যখন উৎস থেকে টেনসরফ্লো তৈরি করেন তখন এটি মেশিনে দ্রুত হতে পারে। সুতরাং এই সমস্ত সতর্কতাগুলি আপনাকে উৎস থেকে তৈরি করা TensorFlow সম্পর্কে বলছে৷
৷যদি আপনার মেশিনে একটি GPU থাকে, তাহলে আপনি AVX সমর্থন থেকে এই সতর্কতাগুলি উপেক্ষা করতে পারেন৷ কারণ সর্বাধিক ব্যয়বহুলগুলি একটি GPU ডিভাইসে প্রেরণ করা হবে। এবং যদি আপনি এই ত্রুটিটি আর দেখতে না চান, তাহলে আপনি কেবল এটি যোগ করে এটিকে উপেক্ষা করতে পারেন:
OS মডিউল আমদানি করুন আপনার প্রধান প্রোগ্রাম কোডে এবং এটির জন্য ম্যাপিং অবজেক্ট সেট করুন
# For disabling the warning import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
কিন্তু আপনি যদি Unix এ থাকেন , তারপর ব্যাশ শেলে এক্সপোর্ট কমান্ড ব্যবহার করুন
export TF_CPP_MIN_LOG_LEVEL=2
কিন্তু যদি GPU না থাকে, এবং আপনি যতটা সম্ভব আপনার CPU ব্যবহার করতে চান, তাহলে আপনার CPU-এর জন্য AVX, AVX2, এবং FMA সক্ষম করার জন্য অপ্টিমাইজ করা উৎস থেকে TensorFlow তৈরি করা উচিত।
