
যদি আপনাকে পাঠ্যের একটি বড় সংগ্রহ দেওয়া হয় এবং আপনি এটি থেকে কিছু অর্থ বের করতে চান তবে আপনি কী করবেন?
একটি ভাল সূচনা হল আপনার পাঠ্যকে n-গ্রামে ভাগ করা .
এখানে একটি বর্ণনা আছে :
কম্পিউটেশনাল ভাষাবিজ্ঞান এবং সম্ভাব্যতার ক্ষেত্রে, একটি n-গ্রাম হল পাঠ্যের একটি প্রদত্ত ক্রম থেকে n আইটেমের একটি সংলগ্ন ক্রম। – উইকিপিডিয়া
উদাহরণস্বরূপ :
যদি আমরা বাক্যাংশটি গ্রহণ করি "হ্যালো সেখানে, আপনি কেমন আছেন?" তারপর ইউনিগ্রাম (একটি উপাদানের এনগ্রাম) হবে:"Hello", "there", "how", "are", "you" , এবং বিগগ্রাম (দুটি উপাদানের এনগ্রাম):["Hello", "there"], ["there", "how"], ["how", "are"], ["are", "you"] .
আপনি যদি চিত্রগুলির সাথে আরও ভালভাবে শিখেন তবে এখানে তার একটি ছবি রয়েছে:
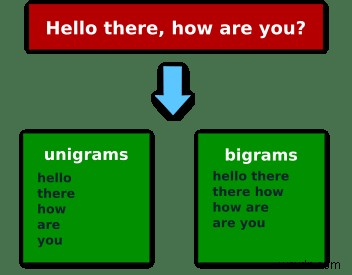
এখন দেখা যাক কিভাবে আপনি রুবিতে এটি বাস্তবায়ন করতে পারেন!
নমুনা ডেটা ডাউনলোড করা হচ্ছে
আমরা আমাদের হাত নোংরা করার আগে আমাদের কিছু নমুনা ডেটার প্রয়োজন হবে৷
আপনার সাথে কাজ করার মতো কিছু না থাকলে আপনি কয়েকটি উইকিপিডিয়া বা ব্লগ নিবন্ধ ডাউনলোড করতে পারেন। এই বিশেষ ক্ষেত্রে, আমি #ruby freenode এর চ্যানেল থেকে কিছু IRC লগ ডাউনলোড করার সিদ্ধান্ত নিয়েছি।
লগগুলি এখানে পাওয়া যাবে৷ :
irclog.whitequark.org/ruby
ডেটা ফরম্যাটের উপর একটি নোট :
আপনি যে রিসোর্সটি বিশ্লেষণ করতে চান তার একটি প্লেইন টেক্সট সংস্করণ উপলব্ধ না হলে, আপনি পৃষ্ঠাটি পার্স করতে এবং ডেটা বের করতে Nokogiri ব্যবহার করতে পারেন৷
irc লগগুলি .txt যোগ করে প্লেইন টেক্সটে পাওয়া যায় ইউআরএলের শেষে তাই আমরা এর সুবিধা নেব।
এই ক্লাসটি আমাদের জন্য ডেটা ডাউনলোড এবং সংরক্ষণ করবে:
require 'restclient'
class LogParser
LOG_DIR = 'irc_logs'
def initialize(date)
@date = date
@log_name = "#{LOG_DIR}/irc-log-#{@date}.txt"
end
def download_page(url)
return log_contents if File.exist? @log_name
RestClient.get(url).body
end
def save_page(page)
File.open(@log_name, "w+") { |f| f.puts page }
end
def log_contents
File.readlines(@log_name).join
end
def get_messages
page = download_page("https://irclog.whitequark.org/ruby/#{@date}.txt")
save_page(page)
page
end
end
log = LogParser.new("2015-04-15")
msg = log.get_messages
এটা বেশ সোজা ক্লাস।
আমরা আমাদের HTTP ক্লায়েন্ট হিসাবে RestClient ব্যবহার করি এবং তারপরে আমরা একটি ফাইলে ফলাফলগুলি সংরক্ষণ করি যাতে আমাদের প্রোগ্রামে পরিবর্তন করার সময় আমাদের তাদের একাধিকবার অনুরোধ করতে না হয়৷
ডেটা বিশ্লেষণ করা
এখন যেহেতু আমাদের ডেটা আছে আমরা তা বিশ্লেষণ করতে পারি৷
৷এখানে একটি সাধারণ এনগ্রাম ক্লাস।
এই ক্লাসে আমরা Array#each_cons পদ্ধতি ব্যবহার করি যা ngrams তৈরি করে।
কারণ এই পদ্ধতিটি একটি Enumerator প্রদান করে আমাদের to_a কল করতে হবে একটি Array পেতে এটিতে .
class Ngram
def initialize(input)
@input = input
end
def ngrams(n)
@input.split.each_cons(n).to_a
end
end
তারপর আমরা একটি লুপ ব্যবহার করে সবকিছু একসাথে রাখি, Hash#merge! &Enumerable#sort_by .
এরকম :
# Filter words that appear less times than this
MIN_REPETITIONS = 20
total = {}
# Get the logs for the first 15 days of the month and return the bigrams
(1..15).each do |n|
day = '%02d' % [n]
total.merge!(get_trigrams_for_date "2015-04-#{day}") { |k, old, new| old + new }
end
# Sort in descending order
total = total.sort_by { |k, v| -v }.reject { |k, v| v < MIN_REPETITIONS }
total.each { |k, v| puts "#{v} => #{k}" }
রাখে দ্রষ্টব্য:
get_trigrams_for_dateপদ্ধতিটি এখানে সংক্ষিপ্ততার জন্য নয়, তবে আপনি এটি গিথুবে খুঁজে পেতে পারেন।
আউটপুটটি দেখতে এইরকম :
112 => i want to 83 => link for more 82 => is there a 71 => you want to 66 => i don't know 66 => i have a 65 => i need to
আপনি দেখতে পাচ্ছেন যে জিনিসগুলি করতে চাওয়া #রুবি 🙂
-এ খুব জনপ্রিয়উপসংহার
এখন আপনার পালা!
আপনার সম্পাদক খুলুন এবং কিছু এন-গ্রাম বিশ্লেষণের সাথে খেলা শুরু করুন। এন-গ্রামগুলিকে কার্যকরভাবে দেখার আরেকটি উপায় হল গুগল এনগ্রাম ভিউয়ার।
প্রাকৃতিক ভাষা প্রক্রিয়াকরণ (NLP) একটি আকর্ষণীয় বিষয় হতে পারে, উইকিপিডিয়ার বিষয়টির একটি ভাল ওভারভিউ রয়েছে৷
আপনি এখানে এই পোস্টের জন্য সম্পূর্ণ কোড খুঁজে পেতে পারেন:https://github.com/matugm/ngram-analysis/blob/master/irc_histogram.rb
