
ওয়েব স্ক্র্যাপিং শুধুমাত্র ডেটা বিজ্ঞান উত্সাহীদেরই উত্তেজিত করে না বরং শিক্ষার্থী বা একজন শিক্ষার্থীকে, যারা ওয়েবসাইটগুলির গভীরে খনন করতে চায়। পাইথন,
সহ অনেক ওয়েবস্ক্র্যাপিং লাইব্রেরি প্রদান করে-
স্ক্র্যাপি
-
Urllib
-
সুন্দর স্যুপ
-
সেলেনিয়াম
-
পাইথন অনুরোধ
-
LXML
আমরা একটি ওয়েবপেজ থেকে ডেটা স্ক্র্যাপ করার জন্য পাইথনের lxml লাইব্রেরি নিয়ে আলোচনা করব, যা C তে লেখা libxml2 XML পার্সিং লাইব্রেরির উপরে তৈরি করা হয়েছে, যা এটিকে Beautiful Soup-এর চেয়ে দ্রুততর করতে সাহায্য করে কিন্তু কিছু কম্পিউটারে ইনস্টল করা কঠিন, বিশেষ করে Windows .
lxml ইনস্টল এবং আমদানি করা হচ্ছে
lxml কমান্ড লাইন থেকে পিপ ব্যবহার করে ইনস্টল করা যেতে পারে,
pip install lxml
অথবা
conda install -c anaconda lxml
lxml ইনস্টলেশন সম্পূর্ণ হলে, html মডিউল আমদানি করুন, যা lxml থেকে HTML পার্স করে।
>>> from lxml import html
আপনি যে পৃষ্ঠাটি স্ক্র্যাপ করতে চান তার সোর্স কোডটি পুনরুদ্ধার করুন- আমাদের কাছে দুটি পছন্দ আছে হয় আমরা পাইথন অনুরোধ লাইব্রেরি বা urllib ব্যবহার করতে পারি এবং পৃষ্ঠার সম্পূর্ণ HTML ধারণকারী একটি lxml HTML উপাদান অবজেক্ট তৈরি করতে এটি ব্যবহার করতে পারি। আমরা পৃষ্ঠার HTML সামগ্রী ডাউনলোড করতে অনুরোধ লাইব্রেরি ব্যবহার করতে যাচ্ছি৷
৷পাইথন অনুরোধগুলি ইনস্টল করতে, আপনার পছন্দের টার্মিনালে এই সাধারণ কমান্ডটি চালান -
$ pipenv install requests
ইয়াহু ফাইন্যান্স থেকে ডেটা স্ক্র্যাপ করা
ধরা যাক আমরা google.finance বা yahoo.finance থেকে স্টক/ইকুইটি ডেটা স্ক্র্যাপ করতে চাই। নিচে yahoo ফাইনান্স থেকে Microsoft কর্পোরেশনের স্ক্রিনশট দেওয়া হল,
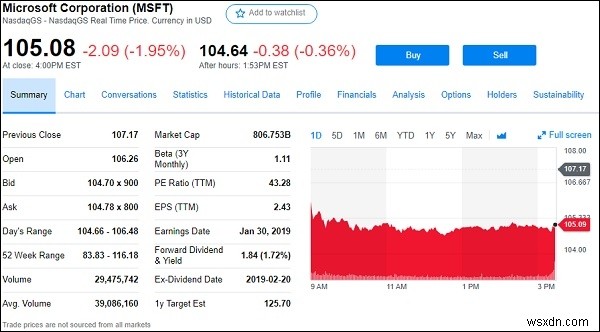
তাই উপরে থেকে (https://finance.yahoo.com/quote/msft ), আমরা স্টকের সমস্ত ক্ষেত্র এক্সট্রাক্ট করতে যাচ্ছি যা উপরে দেখা যাচ্ছে,
-
পূর্ববর্তী বন্ধ, খোলা, বিড, জিজ্ঞাসা, দিনের পরিসীমা, 52 সপ্তাহের পরিসর, ভলিউম এবং আরও অনেক কিছু৷
python lxml মডিউল −
ব্যবহার করে এটি সম্পন্ন করার জন্য নীচে কোড দেওয়া হলlxml_scrape3.py
from lxml import html
import requests
from time import sleep
import json
import argparse
from collections import OrderedDict
from time import sleep
def parse(ticker):
url = "http://finance.yahoo.com/quote/%s?p=%s"%(ticker,ticker)
response = requests.get(url, verify = False)
print ("Parsing %s"%(url))
sleep(4)
parser = html.fromstring(response.text)
summary_table = parser.xpath('//div[contains(@data-test,"summary-table")]//tr')
summary_data = OrderedDict()
other_details_json_link = "https://query2.finance.yahoo.com/v10/finance/quoteSummary/{0}? formatted=true&lang=en-
US®ion=US&modules=summaryProfile%2CfinancialData%2CrecommendationTrend%2
CupgradeDowngradeHistory%2Cearnings%2CdefaultKeyStatistics%2CcalendarEvents&
corsDomain=finance.yahoo.com".format(ticker)summary_json_response=requests.get(other_details_json_link)
try:
json_loaded_summary = json.loads(summary_json_response.text)
y_Target_Est = json_loaded_summary["quoteSummary"]["result"][0]["financialData"] ["targetMeanPrice"]['raw']
earnings_list = json_loaded_summary["quoteSummary"]["result"][0]["calendarEvents"]['earnings']
eps = json_loaded_summary["quoteSummary"]["result"][0]["defaultKeyStatistics"]["trailingEps"]['raw']
datelist = []
for i in earnings_list['earningsDate']:
datelist.append(i['fmt'])
earnings_date = ' to '.join(datelist)
for table_data in summary_table:
raw_table_key = table_data.xpath('.//td[contains(@class,"C(black)")]//text()')
raw_table_value = table_data.xpath('.//td[contains(@class,"Ta(end)")]//text()')
table_key = ''.join(raw_table_key).strip()
table_value = ''.join(raw_table_value).strip()
summary_data.update({table_key:table_value})
summary_data.update({'1y Target Est':y_Target_Est,'EPS (TTM)':eps,'Earnings Date':earnings_date,'ticker':ticker,'url':url})
return summary_data
except:
print ("Failed to parse json response")
return {"error":"Failed to parse json response"}
if __name__=="__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('ticker',help = '')
args = argparser.parse_args()
ticker = args.ticker
print ("Fetching data for %s"%(ticker))
scraped_data = parse(ticker)
print ("Writing data to output file")
with open('%s-summary.json'%(ticker),'w') as fp:
json.dump(scraped_data,fp,indent = 4) উপরের কোডটি চালানোর জন্য, আপনার কমান্ড টার্মিনালে নীচে সহজ টাইপ করুন -
c:\Python\Python361>python lxml_scrape3.py MSFT
lxml_scrap3.py চালানোর সময় আপনি দেখতে পাবেন, আপনার বর্তমান কাজের ডিরেক্টরিতে একটি .json ফাইল তৈরি করা হয়েছে "stockName-summary.json" এর মতো কিছু নামকরণ করা হয়েছে কারণ আমি ইয়াহু ফিনান্স থেকে msft(microsoft) ক্ষেত্রগুলি বের করার চেষ্টা করছি, তাই একটি ফাইল − "msft-summary.json" নামে তৈরি।
নিচে উত্পন্ন আউটপুট −
এর স্ক্রিনশট আছে
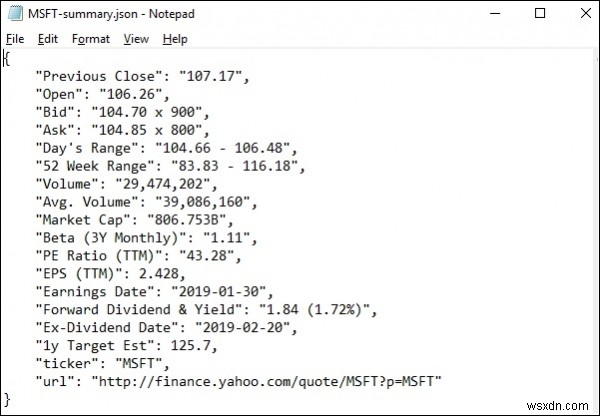
তাই আমরা সফলভাবে lxml এবং অনুরোধগুলি ব্যবহার করে মাইক্রোসফ্টের yahoo.finance থেকে সমস্ত প্রয়োজনীয় ডেটা স্ক্র্যাপ করেছি এবং তারপরে একটি ফাইলে ডেটা সংরক্ষণ করেছি যা পরে মাইক্রোসফ্ট স্টকের দামের গতিবিধি শেয়ার বা বিশ্লেষণ করতে ব্যবহার করা যেতে পারে৷
