
এই নিবন্ধে, আমরা Scikit-learn:A Python Machine Learning Library-এ লার্নিং মডেল বিল্ডিং সম্পর্কে জানব।
এটি একটি বিনামূল্যের মেশিন লার্নিং লাইব্রেরি। এটি বিভিন্ন অ্যালগরিদমকে সমর্থন করে যেমন র্যান্ডম ফরেস্ট, ভেক্টর মেশিন এবং কে-নিকটবর্তী প্রতিবেশীদের সরাসরি বাস্তবায়নের সাথে নম্পি এবং স্কিপি।
ডেটাসেট আমদানি করা হচ্ছে
pandaUrl আমদানি করুন =<এখানে আপনার URL উল্লেখ করুন>data=pandas.rad_csv(url)
ডেটা অন্বেষণ এবং পরিষ্কার করা
আমরা আমাদের প্রয়োজন অনুযায়ী রেকর্ড নির্দিষ্ট/ফিল্টার করতে হেড পদ্ধতি ব্যবহার করতে পারি।
data.head()data.head(n=4) # রেকর্ড 4 হতে সীমাবদ্ধ করে
আমরা ডেটাসেটের শেষ কয়েকটি রেকর্ডও বাস্তবায়ন করতে পারি
data.tail()data.tail(n=4) # রেকর্ড 4 হতে সীমাবদ্ধ করে
এখন ডেটা ভিজ্যুয়ালাইজেশনের পর্যায়ে আসে
এর জন্য, আমরা আমাদের ডেটা কল্পনা করতে Seaborn মডিউল এবং matplotlib ব্যবহার করি
pltsns.set(style="whitegrid", color_codes=True)# হিসাবে siborn আমদানি করুন /প্রে>ডেটা প্রি-প্রসেস করা হচ্ছে
sklearn import preprocessingle =preprocessing.LabelEncoder()# থেকে কলামগুলিকে সাংখ্যিক মানসেনকোডেড_মানে রূপান্তর করুন =le.fit_transform(কলামের নামের তালিকা)মুদ্রণ(এনকোডেড_মান)
অবশেষে আমরা ডেটা সেট প্রশিক্ষণের মাধ্যমে মডেল বিল্ডিংয়ের পর্যায়ে পৌঁছেছি।
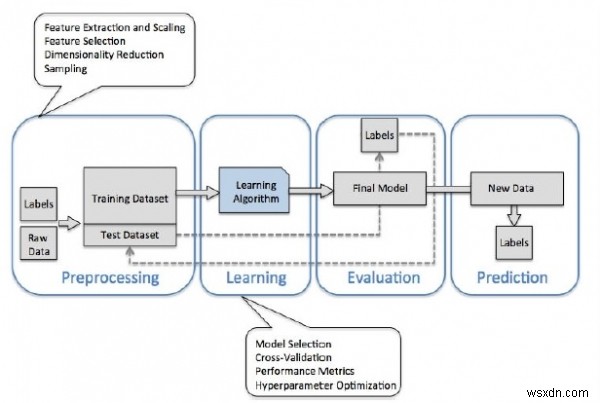
উপসংহার
এই নিবন্ধে, আমরা স্কিট-লার্ন-এ মডেল বিল্ডিং সম্পর্কে শিখেছি - পাইথনে উপলব্ধ একটি লাইব্রেরি।
