আপনি ক্রোম, ফায়ারফক্স, এজ বা সাফারির মতো জনপ্রিয় ব্রাউজারগুলির মধ্যে একটির সাথে কাজ করতে অভ্যস্ত হতে পারেন, তবে এর অর্থ এই নয় যে সেখানে আলাদা ব্রাউজার নেই৷
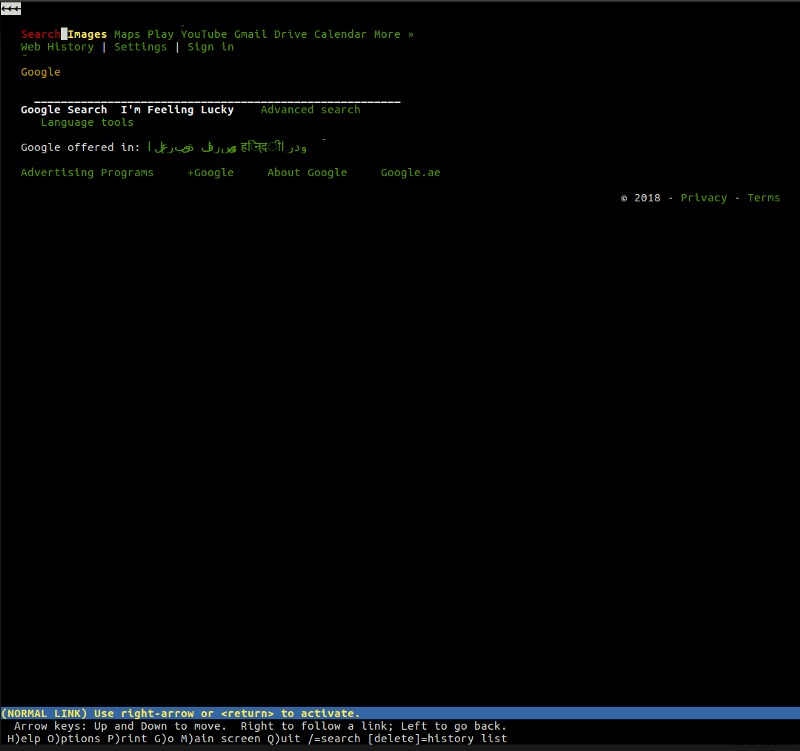
lynx, উদাহরণস্বরূপ, একটি হালকা ওজনের, পাঠ্য-ভিত্তিক ব্রাউজার যা আপনার কমান্ড লাইন থেকে কাজ করে। লিংক্সের কেন্দ্রস্থলে একই সঠিক নীতিগুলি রয়েছে যা আপনি অন্য কোনও "মূলধারার" ব্রাউজারগুলিতে পাবেন। একজন ব্যবহারকারী একটি ওয়েব ঠিকানা (URL) প্রবেশ করেন, ব্রাউজার নথিটি নিয়ে আসে এবং এটি রেন্ডার করে — একমাত্র পার্থক্য হল যে lynx একটি ভিজ্যুয়াল রেন্ডারিং ইঞ্জিন ব্যবহার করে না বরং একটি টেক্সট-ভিত্তিক ইন্টারফেস ব্যবহার করে, যা Google এর মতো ওয়েবসাইটগুলিকে এইরকম দেখায়:
একটি ব্রাউজার কী করে তা আমরা বিস্তৃতভাবে বুঝতে পারি, তবে আসুন আমরা এই বুদ্ধিমান অ্যাপ্লিকেশনগুলি আমাদের জন্য কী কী পদক্ষেপ নেয় তা আরও ঘনিষ্ঠভাবে দেখি৷
একটি ব্রাউজার কি করে?
দীর্ঘ গল্প সংক্ষেপে, একটি ব্রাউজারের কাজ প্রধানত থাকে:
- DNS রেজোলিউশন
- HTTP বিনিময়
- রেন্ডারিং
- ধুয়ে ফেলুন এবং পুনরাবৃত্তি করুন
DNS রেজোলিউশন
এই প্রক্রিয়াটি নিশ্চিত করে যে ব্যবহারকারী একবার URL এ প্রবেশ করলে, ব্রাউজার জানে যে এটি কোন সার্ভারের সাথে সংযোগ করতে হবে। google.com খুঁজে পেতে ব্রাউজার একটি DNS সার্ভারের সাথে যোগাযোগ করে 216.58.207.110-এ অনুবাদ করে , একটি IP ঠিকানা যার সাথে ব্রাউজার সংযোগ করতে পারে৷
৷ HTTP এক্সচেঞ্জ
ব্রাউজার একবার শনাক্ত করেছে যে কোন সার্ভারটি আমাদের অনুরোধটি পরিবেশন করতে যাচ্ছে, এটি এটির সাথে একটি TCP সংযোগ শুরু করবে এবং HTTP বিনিময় শুরু করবে . এটি ব্রাউজারের সার্ভারের সাথে যা প্রয়োজন তার সাথে যোগাযোগ করার এবং সার্ভারের উত্তর দেওয়ার একটি উপায় ছাড়া কিছুই নয়৷
HTTP হল ওয়েবে যোগাযোগের জন্য সবচেয়ে জনপ্রিয় প্রোটোকলের নাম, এবং সার্ভারের সাথে যোগাযোগ করার সময় ব্রাউজারগুলি বেশিরভাগই HTTP এর মাধ্যমে কথা বলে। একটি HTTP বিনিময় ক্লায়েন্ট (আমাদের ব্রাউজার) একটি অনুরোধ পাঠাতে জড়িত , এবং সার্ভার একটি প্রতিক্রিয়া দিয়ে উত্তর দিচ্ছে৷ .
উদাহরণস্বরূপ, ব্রাউজার সফলভাবে google.com এর পিছনে সার্ভারের সাথে সংযুক্ত হওয়ার পরে , এটি একটি অনুরোধ পাঠাবে যা নিচের মত দেখাচ্ছে:
GET / HTTP/1.1Host: google.comAccept: */*
আসুন অনুরোধটি ভেঙে দেওয়া যাক, লাইন দ্বারা লাইন:
GET / HTTP/1.1 :এই প্রথম লাইনের সাথে, ব্রাউজার সার্ভারকে / অবস্থানে নথিটি পুনরুদ্ধার করতে বলে , যোগ করে যে অনুরোধের বাকি অংশ HTTP/1.1 প্রোটোকল অনুসরণ করবে (এটি 1.0ও ব্যবহার করতে পারে অথবা 2 )Host: google.com :এটি হল HTTP/1.1-এ একমাত্র HTTP হেডার বাধ্যতামূলক . যেহেতু সার্ভার একাধিক ডোমেন পরিবেশন করতে পারে (google.com , google.co.uk , ইত্যাদি) এখানে ক্লায়েন্ট উল্লেখ করেছেন যে অনুরোধটি সেই নির্দিষ্ট হোস্টের জন্য ছিলAccept: */* :একটি ঐচ্ছিক শিরোনাম, যেখানে ব্রাউজার সার্ভারকে বলছে যে এটি যেকোন ধরনের প্রতিক্রিয়া ফিরিয়ে দেবে। সার্ভারের একটি রিসোর্স থাকতে পারে যা JSON, XML বা HTML ফর্ম্যাটে পাওয়া যায়, তাই এটি পছন্দের ফর্ম্যাট বেছে নিতে পারে
ব্রাউজারের পরে, যা একটি ক্লায়েন্ট হিসাবে কাজ করে৷ , এর অনুরোধের সাথে সম্পন্ন করা হয়েছে, সার্ভারের উত্তর দেওয়ার পালা। এটি একটি প্রতিক্রিয়ার মত দেখায়:
HTTP/1.1 200 OKCache-Control: private, max-age=0Content-Type: text/html; charset=ISO-8859-1Server: gwsX-XSS-Protection: 1; mode=blockX-Frame-Options: SAMEORIGINSet-Cookie: NID=1234; expires=Fri, 18-Jan-2019 18:25:04 GMT; path=/; domain=.google.com; HttpOnly
<!doctype html><html">......</html>
ওহ, এটি হজম করার জন্য অনেক তথ্য। সার্ভার আমাদের জানায় যে অনুরোধটি সফল হয়েছে (200 OK ) এবং প্রতিক্রিয়া-এ কয়েকটি শিরোনাম যোগ করে , উদাহরণস্বরূপ, এটি বিজ্ঞাপন দেয় কোন সার্ভার আমাদের অনুরোধ প্রক্রিয়া করেছে (Server: gws ), X-XSS-Protection কি এই প্রতিক্রিয়ার নীতি এবং আরও অনেক কিছু।
এই মুহূর্তে, আপনাকে প্রতিক্রিয়ার প্রতিটি লাইন বোঝার দরকার নেই। আমরা এই সিরিজে HTTP প্রোটোকল, এর শিরোনাম এবং আরও অনেক কিছু কভার করব।
আপাতত, আপনাকে যা বুঝতে হবে তা হল ক্লায়েন্ট এবং সার্ভার তথ্য বিনিময় করছে এবং তারা HTTP এর মাধ্যমে তা করে।
রেন্ডারিং
শেষ, কিন্তু কম নয়, রেন্ডারিং প্রক্রিয়া একটি ব্রাউজার কতটা ভালো হবে যদি এটি ব্যবহারকারীকে শুধুমাত্র মজাদার চরিত্রের একটি তালিকা দেখায়?
<!doctype html><html">......</html>
শরীরে প্রতিক্রিয়ার, সার্ভার Content-Type অনুযায়ী প্রতিক্রিয়ার উপস্থাপনা অন্তর্ভুক্ত করে হেডার আমাদের ক্ষেত্রে, বিষয়বস্তুর ধরন text/html সেট করা হয়েছে , তাই আমরা প্রতিক্রিয়াতে এইচটিএমএল মার্কআপ আশা করছি — যা আমরা বডিতে খুঁজে পাই।
এখানেই একটি ব্রাউজার সত্যিই উজ্জ্বল হয়। এটি এইচটিএমএল পার্স করে, মার্কআপে অন্তর্ভুক্ত অতিরিক্ত সংস্থানগুলি লোড করে (উদাহরণস্বরূপ, জাভাস্ক্রিপ্ট ফাইল বা সিএসএস ডকুমেন্ট আনতে পারে) এবং যত তাড়াতাড়ি সম্ভব ব্যবহারকারীর কাছে সেগুলি উপস্থাপন করে৷
আরও একবার, শেষ ফলাফল এমন কিছু যা গড় জো বুঝতে পারে।
ব্রাউজারের অ্যাড্রেস বারে এন্টার চাপলে আসলে কী ঘটে তার আরও বিশদ সংস্করণের জন্য আমি "কী ঘটে যখন..." পড়ার পরামর্শ দিই, প্রক্রিয়াটির পিছনের মেকানিক্স ব্যাখ্যা করার একটি অত্যন্ত বিস্তৃত প্রচেষ্টা৷
যেহেতু এটি নিরাপত্তার উপর দৃষ্টি নিবদ্ধ করা একটি সিরিজ, তাই আমরা এইমাত্র যা শিখেছি তার উপর আমি একটি ইঙ্গিত দিতে যাচ্ছি:আক্রমণকারীরা HTTP বিনিময় এবং রেন্ডারিং অংশে দুর্বলতা থেকে সহজেই জীবিকা নির্বাহ করে . দুর্বলতা, এবং দূষিত ব্যবহারকারী, অন্যত্রও লুকিয়ে থাকে, কিন্তু সেই স্তরগুলিতে একটি ভাল নিরাপত্তা পদ্ধতি ইতিমধ্যেই আপনাকে আপনার নিরাপত্তা ভঙ্গি উন্নত করতে অগ্রগতি করতে দেয়৷
বিক্রেতা
সেখানে 4টি সবচেয়ে জনপ্রিয় ব্রাউজার বিভিন্ন বিক্রেতাদের অন্তর্গত:
- Google দ্বারা ক্রোম
- Mozilla দ্বারা ফায়ারফক্স
- অ্যাপলের সাফারি
- Microsoft দ্বারা প্রান্ত
তাদের বাজারের অনুপ্রবেশ বাড়ানোর জন্য একে অপরের সাথে লড়াই করার পাশাপাশি, ওয়েব মান উন্নত করার জন্য বিক্রেতারা একে অপরের সাথে জড়িত থাকে , যা ব্রাউজারগুলির জন্য এক ধরণের "ন্যূনতম প্রয়োজনীয়তা"৷
৷
W3C হল মানগুলির বিকাশের পিছনে মূল অংশ, কিন্তু ব্রাউজারগুলির জন্য তাদের নিজস্ব বৈশিষ্ট্যগুলি বিকাশ করা অস্বাভাবিক নয় যা শেষ পর্যন্ত এটিকে ওয়েব মান হিসাবে তৈরি করে এবং নিরাপত্তাও এর ব্যতিক্রম নয়৷
উদাহরণস্বরূপ, Chrome 51, SameSite কুকিজ প্রবর্তন করেছে, এমন একটি বৈশিষ্ট্য যা ওয়েব অ্যাপ্লিকেশনগুলিকে CSRF নামে পরিচিত একটি বিশেষ ধরনের দুর্বলতা থেকে পরিত্রাণ পেতে দেয় (পরে এ বিষয়ে আরও)। অন্যান্য বিক্রেতারা সিদ্ধান্ত নিয়েছে যে এটি একটি ভাল ধারণা এবং এটি অনুসরণ করেছে, যার ফলে SameSite একটি ওয়েব স্ট্যান্ডার্ড হয়েছে:এখন পর্যন্ত, Safari হল SameSite কুকি সমর্থন ছাড়াই একমাত্র প্রধান ব্রাউজার৷

এটি আমাদের 2টি জিনিস বলে:
- সাফারি তাদের ব্যবহারকারীদের নিরাপত্তার বিষয়ে যথেষ্ট যত্নশীল বলে মনে হচ্ছে না (শুধু মজা করছি:Safari 12-এ SameSite কুকিজ পাওয়া যাবে, যা আপনি এই নিবন্ধটি পড়ার সময় ইতিমধ্যেই প্রকাশিত হয়ে থাকতে পারে)
- একটি ব্রাউজারে একটি দুর্বলতা প্যাচ করার অর্থ এই নয় যে আপনার সমস্ত ব্যবহারকারী নিরাপদ
প্রথম পয়েন্টটি সাফারিতে একটি শট (যেমন আমি উল্লেখ করেছি, মজা করছি!), যখন দ্বিতীয় পয়েন্টটি সত্যিই গুরুত্বপূর্ণ। ওয়েব অ্যাপ্লিকেশন ডেভেলপ করার সময়, আমাদের শুধু নিশ্চিত করতে হবে না যে সেগুলি বিভিন্ন ব্রাউজারে একই রকম দেখায়, বরং তারা নিশ্চিত করে যে আমাদের ব্যবহারকারীরা প্ল্যাটফর্ম জুড়ে একইভাবে সুরক্ষিত রয়েছে৷
ওয়েব নিরাপত্তার প্রতি আপনার কৌশলটি ব্রাউজারের বিক্রেতা আমাদের যা করতে দেয় সেই অনুযায়ী পরিবর্তিত হওয়া উচিত . আজকাল, বেশিরভাগ ব্রাউজার একই বৈশিষ্ট্যগুলির সেটকে সমর্থন করে এবং খুব কমই তাদের সাধারণ রোডম্যাপ থেকে বিচ্যুত হয়, কিন্তু উপরের একটির মতো দৃষ্টান্তগুলি এখনও ঘটে থাকে এবং আমাদের নিরাপত্তা কৌশল নির্ধারণ করার সময় এটি আমাদের বিবেচনায় নেওয়া দরকার৷
আমাদের ক্ষেত্রে, যদি আমরা সিদ্ধান্ত নিই যে আমরা শুধুমাত্র SameSite কুকিজের মাধ্যমে CSRF আক্রমণ কমাতে যাচ্ছি, তাহলে আমাদের সচেতন হওয়া উচিত যে আমরা আমাদের Safari ব্যবহারকারীদের ঝুঁকির মধ্যে ফেলছি। এবং আমাদের ব্যবহারকারীদেরও তা জানা উচিত।
সবশেষে কিন্তু অন্তত নয়, আপনার মনে রাখা উচিত যে আপনি একটি ব্রাউজার সংস্করণ সমর্থন করবেন কিনা তা সিদ্ধান্ত নিতে পারেন:প্রতিটি ব্রাউজার সংস্করণকে সমর্থন করা অব্যবহার্য হবে (ইন্টারনেট এক্সপ্লোরার 6 সম্পর্কে চিন্তা করুন)। প্রধান ব্রাউজারগুলির শেষ কয়েকটি সংস্করণ সমর্থিত কিনা তা নিশ্চিত করা, যদিও, সাধারণত একটি ভাল সিদ্ধান্ত। যদিও আপনি একটি নির্দিষ্ট প্ল্যাটফর্মে সুরক্ষা দেওয়ার পরিকল্পনা না করে থাকেন, তবে সাধারণত আপনার ব্যবহারকারীদের জানানোর পরামর্শ দেওয়া হয়।
প্রো টিপ :আপনি কখনই আপনার ব্যবহারকারীদের পুরানো ব্রাউজার ব্যবহার করতে উত্সাহিত করবেন না, বা সক্রিয়ভাবে তাদের সমর্থন করবেন। যদিও আপনি সমস্ত প্রয়োজনীয় সতর্কতা অবলম্বন করতে পারেন, অন্যান্য ওয়েব বিকাশকারীরা তা নাও করতে পারেন। প্রধান ব্রাউজারগুলির একটির সর্বশেষ সমর্থিত সংস্করণ ব্যবহার করতে ব্যবহারকারীদের উত্সাহিত করুন৷৷
বিক্রেতা বা স্ট্যান্ডার্ড বাগ?
সত্য যে গড় ব্যবহারকারী একটি 3য় পক্ষের ক্লায়েন্ট (ব্রাউজার) এর মাধ্যমে আমাদের অ্যাপ্লিকেশন অ্যাক্সেস করে তা একটি পরিষ্কার, সুরক্ষিত ব্রাউজিং অভিজ্ঞতার দিকে অন্য মাত্রা যোগ করে:ব্রাউজার নিজেই একটি নিরাপত্তা দুর্বলতা উপস্থাপন করতে পারে।
বিক্রেতারা সাধারণত পুরস্কার প্রদান করে (ওরফে বাগ বাউন্টি ) নিরাপত্তা গবেষকদের যারা ব্রাউজারেই একটি দুর্বলতা খুঁজে পেতে পারেন। এই বাগগুলি আপনার বাস্তবায়নের সাথে আবদ্ধ নয়, বরং ব্রাউজার কীভাবে তার নিজের নিরাপত্তা পরিচালনা করে।
উদাহরণস্বরূপ, Chrome পুরষ্কার প্রোগ্রাম, নিরাপত্তা প্রকৌশলীদের তারা খুঁজে পাওয়া দুর্বলতাগুলি রিপোর্ট করতে Chrome নিরাপত্তা দলের সাথে যোগাযোগ করতে দেয়৷ যদি এই দুর্বলতাগুলি নিশ্চিত করা হয়, একটি প্যাচ জারি করা হয়, একটি নিরাপত্তা পরামর্শমূলক নোটিশ সাধারণত জনসাধারণের জন্য প্রকাশ করা হয় এবং গবেষক প্রোগ্রাম থেকে একটি (সাধারণত আর্থিক) পুরস্কার পান৷
Google-এর মতো কোম্পানিগুলি তাদের বাগ বাউন্টি প্রোগ্রামগুলিতে তুলনামূলকভাবে ভাল পরিমাণে পুঁজি বিনিয়োগ করে, কারণ এটি তাদের অ্যাপ্লিকেশনে কোনো সমস্যা হলে আর্থিক সুবিধার প্রতিশ্রুতি দিয়ে গবেষকদের আকর্ষণ করতে দেয়।
একটি বাগ বাউন্টি প্রোগ্রামে, প্রত্যেকেই জয়ী হয়:বিক্রেতা তার সফ্টওয়্যারটির নিরাপত্তা উন্নত করতে পরিচালনা করে এবং গবেষকরা তাদের অনুসন্ধানের জন্য অর্থ পান। আমরা পরে এই প্রোগ্রামগুলি নিয়ে আলোচনা করব, কারণ আমি বিশ্বাস করি বাগ বাউন্টি উদ্যোগগুলি নিরাপত্তা ল্যান্ডস্কেপে তাদের নিজস্ব অংশের প্রাপ্য৷
Jake Archibald হল Google-এর একজন ডেভেলপার অ্যাডভোকেট যিনি সম্প্রতি একাধিক ব্রাউজারকে প্রভাবিত করে এমন একটি দুর্বলতা আবিষ্কার করেছেন৷ তিনি তার প্রচেষ্টার নথিভুক্ত করেছেন, কিভাবে তিনি বিভিন্ন বিক্রেতাদের সাথে যোগাযোগ করেছেন এবং তাদের প্রতিক্রিয়া একটি আকর্ষণীয় ব্লগ পোস্টে যা আমি আপনাকে পড়ার সুপারিশ করব৷
ডেভেলপারদের জন্য একটি ব্রাউজার
এতক্ষণে, আমাদের একটি খুব সহজ কিন্তু বরং গুরুত্বপূর্ণ ধারণা বোঝা উচিত ছিল:ব্রাউজারগুলি হল সাধারণ ইন্টারনেট সার্ফারের জন্য তৈরি করা HTTP ক্লায়েন্ট .
তারা অবশ্যই একটি প্ল্যাটফর্মের খালি HTTP ক্লায়েন্টের চেয়ে বেশি শক্তিশালী (NodeJS-এর require('http') সম্পর্কে চিন্তা করুন , উদাহরণস্বরূপ), কিন্তু দিনের শেষে, তারা "শুধু" সহজ HTTP ক্লায়েন্টের একটি স্বাভাবিক বিবর্তন৷
ডেভেলপার হিসেবে, আমাদের পছন্দের HTTP ক্লায়েন্ট সম্ভবত ড্যানিয়েল স্টেনবার্গের সিআরএল, ওয়েব ডেভেলপাররা প্রতিদিন ব্যবহার করা সবচেয়ে জনপ্রিয় সফ্টওয়্যার প্রোগ্রামগুলির মধ্যে একটি। এটি আমাদের কমান্ড লাইন থেকে একটি HTTP অনুরোধ পাঠানোর মাধ্যমে ফ্লাইতে একটি HTTP বিনিময় করতে দেয়:
$ curl -I localhost:8080
HTTP/1.1 200 OKserver: ecstatic-2.2.1Content-Type: text/htmletag: "23724049-4096-"2018-07-20T11:20:35.526Z""last-modified: Fri, 20 Jul 2018 11:20:35 GMTcache-control: max-age=3600Date: Fri, 20 Jul 2018 11:21:02 GMTConnection: keep-alive
উপরের উদাহরণে, আমরা localhost:8080/-এ নথির অনুরোধ করেছি , এবং একটি স্থানীয় সার্ভার সফলভাবে উত্তর দিয়েছে৷
৷
কমান্ড লাইনে প্রতিক্রিয়ার বডি ডাম্প করার পরিবর্তে, এখানে আমরা -I ব্যবহার করেছি পতাকা যা cURL কে বলে আমরা শুধুমাত্র প্রতিক্রিয়া শিরোনামে আগ্রহী। এটিকে একধাপ এগিয়ে নিয়ে, আমরা cURL কে আরও কিছু তথ্য ডাম্প করার নির্দেশ দিতে পারি, এতে করে প্রকৃত অনুরোধ সহ, যাতে আমরা এই সম্পূর্ণ HTTP এক্সচেঞ্জটি আরও ভালভাবে দেখতে পারি। আমাদের যে বিকল্পটি ব্যবহার করতে হবে তা হল -v (শব্দ):
$ curl -I -v localhost:8080* Rebuilt URL to: localhost:8080/* Trying 127.0.0.1...* Connected to localhost (127.0.0.1) port 8080 (#0)> HEAD / HTTP/1.1> Host: localhost:8080> User-Agent: curl/7.47.0> Accept: */*>< HTTP/1.1 200 OKHTTP/1.1 200 OK< server: ecstatic-2.2.1server: ecstatic-2.2.1< Content-Type: text/htmlContent-Type: text/html< etag: "23724049-4096-"2018-07-20T11:20:35.526Z""etag: "23724049-4096-"2018-07-20T11:20:35.526Z""< last-modified: Fri, 20 Jul 2018 11:20:35 GMTlast-modified: Fri, 20 Jul 2018 11:20:35 GMT< cache-control: max-age=3600cache-control: max-age=3600< Date: Fri, 20 Jul 2018 11:25:55 GMTDate: Fri, 20 Jul 2018 11:25:55 GMT< Connection: keep-aliveConnection: keep-alive
<* Connection #0 to host localhost left intact
প্রায় একই তথ্য মূলধারার ব্রাউজারগুলিতে তাদের DevTools-এর মাধ্যমে উপলব্ধ৷
৷
আমরা যেমন দেখেছি, ব্রাউজারগুলি বিস্তৃত HTTP ক্লায়েন্ট ছাড়া আর কিছুই নয়। অবশ্যই, তারা প্রচুর পরিমাণে বৈশিষ্ট্য যুক্ত করে (শংসাপত্র ব্যবস্থাপনা, বুকমার্কিং, ইতিহাস ইত্যাদির কথা চিন্তা করুন) তবে সত্য হল যে তারা মানুষের জন্য HTTP ক্লায়েন্ট হিসাবে জন্মগ্রহণ করেছিল। এটি গুরুত্বপূর্ণ, কারণ বেশিরভাগ ক্ষেত্রেই আপনার ওয়েব অ্যাপ্লিকেশনের নিরাপত্তা পরীক্ষা করার জন্য ব্রাউজারের প্রয়োজন হয় না, কারণ আপনি কেবল "এটি কার্ল" করতে পারেন এবং প্রতিক্রিয়াটি দেখতে পারেন৷
একটি চূড়ান্ত জিনিস যা আমি উল্লেখ করতে চাই, তা হল যেকোন কিছু একটি ব্রাউজার হতে পারে . আপনার যদি এমন একটি মোবাইল অ্যাপ্লিকেশন থাকে যা HTTP প্রোটোকলের মাধ্যমে API ব্যবহার করে, তাহলে অ্যাপটি হল আপনার ব্রাউজার — এটি শুধুমাত্র একটি উচ্চ কাস্টমাইজড একটি যা আপনি নিজেই তৈরি করেছেন, যেটি শুধুমাত্র একটি নির্দিষ্ট ধরনের HTTP প্রতিক্রিয়া বুঝতে পারে (আপনার নিজস্ব API থেকে)।
HTTP প্রোটোকলের মধ্যে
আমরা যেমন উল্লেখ করেছি, HTTP বিনিময়৷ এবং রেন্ডারিং পর্যায়গুলি হল সেইগুলি যা আমরা বেশিরভাগই কভার করতে যাচ্ছি, কারণ তারা সবচেয়ে বেশি সংখ্যক আক্রমণ ভেক্টর প্রদান করে দূষিত ব্যবহারকারীদের জন্য।
পরবর্তী প্রবন্ধে, আমরা HTTP প্রোটোকলের উপর গভীরভাবে নজর দেব এবং HTTP এক্সচেঞ্জগুলিকে সুরক্ষিত করার জন্য আমাদের কী ব্যবস্থা নেওয়া উচিত তা বোঝার চেষ্টা করব৷
মূলত odino.org এ প্রকাশিত (29 জুলাই 2018)।
_আপনি আমাকে টুইটারে অনুসরণ করতে পারেন - র্যান্টস স্বাগতম!_ ?
বিনামূল্যে কোড শিখুন. freeCodeCamp-এর ওপেন সোর্স পাঠ্যক্রম 40,000-এরও বেশি লোককে ডেভেলপার হিসেবে চাকরি পেতে সাহায্য করেছে। শুরু করুন


 _এর দ্বারা ফটো [Unsplash](https://unsplash.com/photos/cVMaxt672ss?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" rel="noopener" target="_blank" title="">লিয়াম টাকার উপর
_এর দ্বারা ফটো [Unsplash](https://unsplash.com/photos/cVMaxt672ss?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" rel="noopener" target="_blank" title="">লিয়াম টাকার উপর 