
একটি কনভোল্যুশনাল নিউরাল নেটওয়ার্ক তৈরি করা থেকে iOS এ একটি OCR স্থাপন করা
প্রকল্পের জন্য প্রেরণা ✍️ ??
যখন আমি কয়েক মাস আগে MNIST ডেটাসেটের জন্য গভীর শিক্ষার মডেল তৈরি করতে শিখছিলাম, তখন আমি একটি iOS অ্যাপ তৈরি করেছিলাম যা হাতে লেখা অক্ষরগুলিকে স্বীকৃতি দেয়৷
আমার বন্ধু Kaichi Momose একটি জাপানি ভাষা শেখার অ্যাপ তৈরি করছিল, Nukon। তিনি কাকতালীয়ভাবে এটিতে একটি অনুরূপ বৈশিষ্ট্য থাকতে চেয়েছিলেন। তারপরে আমরা একটি অঙ্ক শনাক্তকারীর চেয়ে আরও পরিশীলিত কিছু তৈরি করতে সহযোগিতা করেছি:জাপানি অক্ষরের (হিরাগানা এবং কাতাকানা) জন্য একটি OCR (অপটিক্যাল ক্যারেক্টার রিকগনিশন/রিডার)৷
নুকনের বিকাশের সময়, জাপানি ভাষায় হাতের লেখার স্বীকৃতির জন্য কোনো API উপলব্ধ ছিল না। আমাদের নিজস্ব ওসিআর তৈরি করা ছাড়া আমাদের কোনো উপায় ছিল না। স্ক্র্যাচ থেকে একটি তৈরি করে আমরা সবচেয়ে বড় সুবিধা পেয়েছি যে আমাদের অফলাইনে কাজ করে। ব্যবহারকারীরা ইন্টারনেট ছাড়াই পাহাড়ের গভীরে থাকতে পারে এবং এখনও জাপানি ভাষা শেখার তাদের দৈনন্দিন রুটিন বজায় রাখতে নুকন খুলতে পারে। আমরা পুরো প্রক্রিয়া জুড়ে অনেক কিছু শিখেছি, কিন্তু আরও গুরুত্বপূর্ণ, আমরা আমাদের ব্যবহারকারীদের জন্য আরও ভালো পণ্য পাঠানোর জন্য রোমাঞ্চিত হয়েছি।
এই নিবন্ধটি কীভাবে আমরা iOS অ্যাপগুলির জন্য একটি জাপানি OCR তৈরি করেছি তার প্রক্রিয়াটি ভেঙে দেবে। যারা অন্য ভাষা/প্রতীকগুলির জন্য একটি তৈরি করতে চান, তাদের জন্য ডেটাসেট পরিবর্তন করে এটি কাস্টমাইজ করতে নির্দ্বিধায়৷
আর কিছু না করে, আসুন দেখে নেওয়া যাক কী কভার করা হবে:
পার্ট 1️⃣:ডেটাসেট এবং প্রিপ্রসেস ছবিগুলি প্রাপ্ত করুন
অংশ 2️⃣:CNN (Convolutional Neural Network) তৈরি ও প্রশিক্ষণ দিন
অংশ 3️⃣:প্রশিক্ষিত মডেলটিকে iOS-এ একীভূত করুন
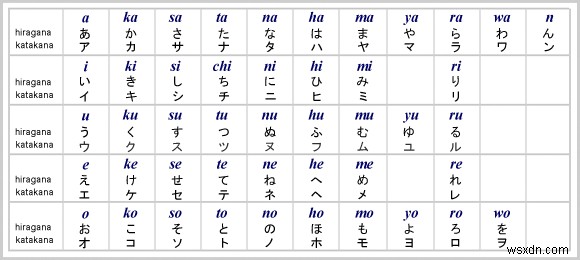
ডেটাসেট এবং প্রিপ্রসেস ইমেজগুলি পান?
ডেটাসেটটি ETL ক্যারেক্টার ডেটাবেস থেকে এসেছে, যাতে হাতে লেখা অক্ষর এবং চিহ্নগুলির নয়টি সেট রয়েছে৷ যেহেতু আমরা হিরাগানার জন্য একটি OCR তৈরি করতে যাচ্ছি, তাই ETL8 হল ডেটাসেট যা আমরা ব্যবহার করব।
.npz-এ ছবিগুলি পড়তে এবং সংরক্ষণ করে বিন্যাস। import struct
import numpy as np
from PIL import Image
sz_record = 8199
def read_record_ETL8G(f):
s = f.read(sz_record)
r = struct.unpack('>2H8sI4B4H2B30x8128s11x', s)
iF = Image.frombytes('F', (128, 127), r[14], 'bit', 4)
iL = iF.convert('L')
return r + (iL,)
def read_hiragana():
# Type of characters = 70, person = 160, y = 127, x = 128
ary = np.zeros([71, 160, 127, 128], dtype=np.uint8)
for j in range(1, 33):
filename = '../../ETL8G/ETL8G_{:02d}'.format(j)
with open(filename, 'rb') as f:
for id_dataset in range(5):
moji = 0
for i in range(956):
r = read_record_ETL8G(f)
if b'.HIRA' in r[2] or b'.WO.' in r[2]:
if not b'KAI' in r[2] and not b'HEI' in r[2]:
ary[moji, (j - 1) * 5 + id_dataset] = np.array(r[-1])
moji += 1
np.savez_compressed("hiragana.npz", ary)
একবার আমাদের hiragana.npz আছে সংরক্ষিত, চলুন ফাইলটি লোড করে এবং চিত্রের মাত্রাগুলিকে 32x32 পিক্সেলে পুনর্নির্মাণ করে ছবি প্রক্রিয়াকরণ শুরু করি . আমরা ঘোরানো এবং জুম করা অতিরিক্ত চিত্রগুলি তৈরি করতে ডেটা বৃদ্ধিও যোগ করব৷ যখন আমাদের মডেলকে বিভিন্ন কোণ থেকে অক্ষর চিত্রের উপর প্রশিক্ষণ দেওয়া হয়, তখন আমাদের মডেল মানুষের হাতের লেখার সাথে আরও ভালভাবে মানিয়ে নিতে পারে।
import scipy.misc
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.models import Sequential
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
# 71 characters
nb_classes = 71
# input image dimensions
img_rows, img_cols = 32, 32
ary = np.load("hiragana.npz")['arr_0'].reshape([-1, 127, 128]).astype(np.float32) / 15
X_train = np.zeros([nb_classes * 160, img_rows, img_cols], dtype=np.float32)
for i in range(nb_classes * 160):
X_train[i] = scipy.misc.imresize(ary[i], (img_rows, img_cols), mode='F')
y_train = np.repeat(np.arange(nb_classes), 160)
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2)
# convert class vectors to categorical matrices
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
# data augmentation
datagen = ImageDataGenerator(rotation_range=15, zoom_range=0.20)
datagen.fit(X_train)CNN তৈরি এবং প্রশিক্ষণ?️
এখন মজা অংশ আসে! আমরা আমাদের মডেলের জন্য একটি CNN (Convolutional Neural Network) তৈরি করতে Keras ব্যবহার করব। যখন আমি প্রথম মডেলটি তৈরি করেছি, আমি হাইপার-প্যারামিটার নিয়ে পরীক্ষা করেছি এবং সেগুলি একাধিকবার টিউন করেছি। নীচের সংমিশ্রণটি আমাকে সর্বোচ্চ নির্ভুলতা দিয়েছে — 98.77%। নিজেকে বিভিন্ন পরামিতি নিয়ে খেলতে নির্দ্বিধায়৷
model = Sequential()
def model_6_layers():
model.add(Conv2D(32, 3, 3, input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model_6_layers()
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
model.fit_generator(datagen.flow(X_train, y_train, batch_size=16),
samples_per_epoch=X_train.shape[0],
nb_epoch=30, validation_data=(X_test, y_test))আপনি যদি মডেলের কার্যক্ষমতা অসন্তোষজনক খুঁজে পান তাহলে এখানে কিছু টিপস রয়েছে৷ প্রশিক্ষণের ধাপে:
মডেল হল ওভারফিটিং৷
এর মানে হল যে মডেলটি ভালভাবে সাধারণীকৃত নয়। স্বজ্ঞাত ব্যাখ্যার জন্য এই নিবন্ধটি দেখুন।
কিভাবে ওভারফিটিং সনাক্ত করতে হয় :acc (নির্ভুলতা) বাড়তে থাকে, কিন্তু val_acc (বৈধতা নির্ভুলতা) প্রশিক্ষণ প্রক্রিয়ার বিপরীত করে।
ওভারফিটিং এর কিছু সমাধান :নিয়মিতকরণ (উদাঃ ড্রপআউট), ডেটা বৃদ্ধি, ডেটাসেটের মানের উন্নতি
মডেলটি "লার্নিং" কিনা তা কীভাবে জানবেন
val_loss হলে মডেলটি শিখছে না প্রশিক্ষণ চলার সাথে সাথে (বৈধতা ক্ষতি) বাড়ে বা কমে না।
TensorBoard ব্যবহার করুন - এটি সময়ের সাথে মডেল পারফরম্যান্সের জন্য ভিজ্যুয়ালাইজেশন প্রদান করে। এটি প্রতিটি একক যুগের দিকে তাকানোর এবং ক্রমাগত মান তুলনা করার ক্লান্তিকর কাজ থেকে মুক্তি পায়৷
যেহেতু আমরা আমাদের নির্ভুলতার সাথে সন্তুষ্ট, আমরা ফাইল হিসাবে ওজন এবং মডেল কনফিগারেশন সংরক্ষণ করার আগে ড্রপআউট স্তরগুলি সরিয়ে ফেলি৷
for k in model.layers:
if type(k) is keras.layers.Dropout:
model.layers.remove(k)
model.save('hiraganaModel.h5')
iOS অংশে যাওয়ার আগে একমাত্র কাজটি হল hiraganaModel.h5 রূপান্তর করা একটি CoreML মডেলে।
import coremltools
output_labels = [
'あ', 'い', 'う', 'え', 'お',
'か', 'く', 'こ', 'し', 'せ',
'た', 'つ', 'と', 'に', 'ね',
'は', 'ふ', 'ほ', 'み', 'め',
'や', 'ゆ', 'よ', 'ら', 'り',
'る', 'わ', 'が', 'げ', 'じ',
'ぞ', 'だ', 'ぢ', 'づ', 'で',
'ど', 'ば', 'び',
'ぶ', 'べ', 'ぼ', 'ぱ', 'ぴ',
'ぷ', 'ぺ', 'ぽ',
'き', 'け', 'さ', 'す', 'そ',
'ち', 'て', 'な', 'ぬ', 'の',
'ひ', 'へ', 'ま', 'む', 'も',
'れ', 'を', 'ぎ', 'ご', 'ず',
'ぜ', 'ん', 'ぐ', 'ざ', 'ろ']
scale = 1/255.
coreml_model = coremltools.converters.keras.convert('./hiraganaModel.h5',
input_names='image',
image_input_names='image',
output_names='output',
class_labels= output_labels,
image_scale=scale)
coreml_model.author = 'Your Name'
coreml_model.license = 'MIT'
coreml_model.short_description = 'Detect hiragana character from handwriting'
coreml_model.input_description['image'] = 'Grayscale image containing a handwritten character'
coreml_model.output_description['output'] = 'Output a character in hiragana'
coreml_model.save('hiraganaModel.mlmodel')
output_labels সমস্ত সম্ভাব্য আউটপুট যা আমরা পরে iOS-এ দেখতে পাব।
মজার ঘটনা:আপনি যদি জাপানি বোঝেন, আপনি হয়তো জানেন যে আউটপুট অক্ষরের ক্রম হিরাগানার "বর্ণানুক্রমিক ক্রম" এর সাথে মেলে না। এটা বুঝতে আমাদের কিছুটা সময় লেগেছে যে ETL8-এর ছবিগুলি "বর্ণানুক্রমিক ক্রমে" ছিল না (এটি উপলব্ধি করার জন্য কাইচিকে ধন্যবাদ)। ডেটাসেটটি একটি জাপানি বিশ্ববিদ্যালয় দ্বারা সংকলিত হয়েছে, যদিও…?
প্রশিক্ষিত মডেলটিকে iOS-এ একীভূত করবেন?
আমরা অবশেষে সবকিছু একত্রিত করছি! hiraganaModel.mlmodel টেনে আনুন একটি Xcode প্রকল্পে। তারপর আপনি এই মত কিছু দেখতে পাবেন:
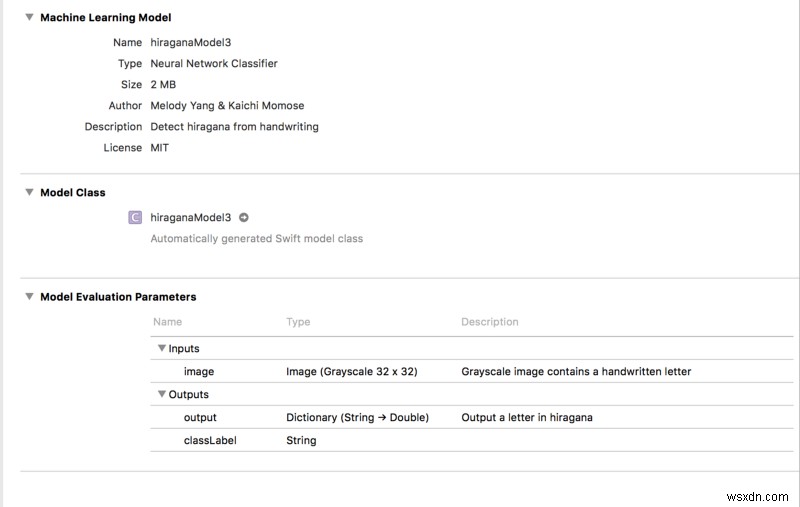
দ্রষ্টব্য :মডেল অনুলিপি করার পরে Xcode একটি কর্মক্ষেত্র তৈরি করবে। আমাদের কোডিং পরিবেশকে ওয়ার্কস্পেসে পরিবর্তন করতে হবে অন্যথায় ML মডেল কাজ করবে না!
শেষ লক্ষ্য হল আমাদের হিরাগানা মডেল একটি চিত্রের মাধ্যমে একটি চরিত্রের ভবিষ্যদ্বাণী করা। এটি অর্জন করতে, আমরা একটি সাধারণ UI তৈরি করব যাতে ব্যবহারকারী লিখতে পারে এবং আমরা ব্যবহারকারীর লেখা একটি চিত্র বিন্যাসে সংরক্ষণ করব। অবশেষে, আমরা ছবির পিক্সেল মান পুনরুদ্ধার করি এবং সেগুলিকে আমাদের মডেলে ফিড করি৷
৷আসুন এটি ধাপে ধাপে করি:
-
UIView-এ অক্ষর "আঁকুন"UIBezierPathসহ
import UIKit
class viewController: UIViewController {
@IBOutlet weak var canvas: UIView!
var path = UIBezierPath()
var startPoint = CGPoint()
var touchPoint = CGPoint()
override func viewDidLoad() {
super.viewDidLoad()
canvas.clipsToBounds = true
canvas.isMultipleTouchEnabled = true
}
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
startPoint = point
}
}
override func touchesMoved(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
touchPoint = point
}
path.move(to: startPoint)
path.addLine(to: touchPoint)
startPoint = touchPoint
draw()
}
func draw() {
let strokeLayer = CAShapeLayer()
strokeLayer.fillColor = nil
strokeLayer.lineWidth = 8
strokeLayer.strokeColor = UIColor.orange.cgColor
strokeLayer.path = path.cgPath
canvas.layer.addSublayer(strokeLayer)
}
// clear the drawing in view
@IBAction func clearPressed(_ sender: UIButton) {
path.removeAllPoints()
canvas.layer.sublayers = nil
canvas.setNeedsDisplay()
}
}
strokeLayer.strokeColor যে কোন রঙ হতে পারে। যাইহোক, canvas এর পটভূমির রঙ কালো হতে হবে . যদিও আমাদের প্রশিক্ষণ চিত্রগুলির একটি সাদা ব্যাকগ্রাউন্ড এবং কালো স্ট্রোক রয়েছে, ML মডেলটি এই শৈলীর সাথে একটি ইনপুট চিত্রে ভাল প্রতিক্রিয়া দেখায় না৷
2. UIView চালু করুন UIImage এ এবং CVPixelBuffer
এক্সটেনশনে, দুটি সহায়ক ফাংশন আছে। একসাথে, তারা ছবিগুলিকে একটি পিক্সেল বাফারে অনুবাদ করে, যা পিক্সেল মানগুলির সমতুল্য। ইনপুট width এবং height উভয়ই 32 হওয়া উচিত যেহেতুআমাদের মডেলের ইনপুট মাত্রা হল ৩২ বাই ৩২ পিক্সেল৷
যত তাড়াতাড়ি আমাদের pixelBuffer আছে , আমরা model.prediction() কল করতে পারি এবং pixelBuffer পাস করুন . এবং আমরা সেখানে যেতে! আমাদের একটি আউটপুট classLabel থাকতে পারে !
@IBAction func recognizePressed(_ sender: UIButton) {
// Turn view into an image
let resultImage = UIImage.init(view: canvas)
let pixelBuffer = resultImage.pixelBufferGray(width: 32, height: 32)
let model = hiraganaModel3()
// output a Hiragana character
let output = try? model.prediction(image: pixelBuffer!)
print(output?.classLabel)
}
extension UIImage {
// Resizes the image to width x height and converts it to a grayscale CVPixelBuffer
func pixelBufferGray(width: Int, height: Int) -> CVPixelBuffer? {
return _pixelBuffer(width: width, height: height,
pixelFormatType: kCVPixelFormatType_OneComponent8,
colorSpace: CGColorSpaceCreateDeviceGray(),
alphaInfo: .none)
}
func _pixelBuffer(width: Int, height: Int, pixelFormatType: OSType,
colorSpace: CGColorSpace, alphaInfo: CGImageAlphaInfo) -> CVPixelBuffer? {
var maybePixelBuffer: CVPixelBuffer?
let attrs = [kCVPixelBufferCGImageCompatibilityKey: kCFBooleanTrue,
kCVPixelBufferCGBitmapContextCompatibilityKey: kCFBooleanTrue]
let status = CVPixelBufferCreate(kCFAllocatorDefault,
width,
height,
pixelFormatType,
attrs as CFDictionary,
&maybePixelBuffer)
guard status == kCVReturnSuccess, let pixelBuffer = maybePixelBuffer else {
return nil
}
CVPixelBufferLockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
let pixelData = CVPixelBufferGetBaseAddress(pixelBuffer)
guard let context = CGContext(data: pixelData,
width: width,
height: height,
bitsPerComponent: 8,
bytesPerRow: CVPixelBufferGetBytesPerRow(pixelBuffer),
space: colorSpace,
bitmapInfo: alphaInfo.rawValue)
else {
return nil
}
UIGraphicsPushContext(context)
context.translateBy(x: 0, y: CGFloat(height))
context.scaleBy(x: 1, y: -1)
self.draw(in: CGRect(x: 0, y: 0, width: width, height: height))
UIGraphicsPopContext()
CVPixelBufferUnlockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
return pixelBuffer
}
}
3. UIAlertController দিয়ে আউটপুট দেখান
এই ধাপটি সম্পূর্ণ ঐচ্ছিক। শুরুতে জিআইএফ-এ যেমন দেখানো হয়েছে, ফলাফল জানাতে আমি একটি সতর্কতা নিয়ন্ত্রক যোগ করেছি।
func informResultPopUp(message: String) {
let alertController = UIAlertController(title: message,
message: nil,
preferredStyle: .alert)
let ok = UIAlertAction(title: "Ok", style: .default, handler: { action in
self.dismiss(animated: true, completion: nil)
})
alertController.addAction(ok)
self.present(alertController, animated: true) { () in
}
}ভয়লা ! আমরা এইমাত্র একটি OCR তৈরি করেছি যা ডেমো-রেডি (এবং অ্যাপ-স্টোর-প্রস্তুত)! ??
উপসংহার?
একটি ওসিআর তৈরি করা এত কঠিন নয়। আপনি যেমন দেখেছেন, এই নিবন্ধটি পদক্ষেপ এবং সমস্যা নিয়ে গঠিত এবং এই প্রকল্পটি তৈরি করার সময় আমি পড়েছিলাম। আমি আইওএস এর সাথে সংযোগ করে পাইথন কোডের একটি গুচ্ছ প্রদর্শনযোগ্য করার প্রক্রিয়াটি উপভোগ করেছি এবং আমি এটি চালিয়ে যেতে চাই।
আমি আশা করি এই নিবন্ধটি তাদের জন্য কিছু দরকারী তথ্য প্রদান করবে যারা একটি OCR তৈরি করতে চান কিন্তু কোথায় শুরু করবেন তার কোনো ধারণা নেই৷
আপনি সোর্স কোড খুঁজে পেতে পারেন এখানে.
বোনাস :আপনি যদি অগভীর অ্যালগরিদম নিয়ে পরীক্ষা করতে আগ্রহী হন, তাহলে পড়তে থাকুন!
[ঐচ্ছিক] অগভীর অ্যালগরিদম দিয়ে ট্রেন?
CNN বাস্তবায়ন করার আগে, Kaichi এবং আমি অন্যান্য মেশিন লার্নিং অ্যালগরিদম পরীক্ষা করেছিলাম যে তারা কাজটি সম্পন্ন করতে পারে কিনা (এবং আমাদের কিছু কম্পিউটিং খরচ বাঁচাতে!)। আমরা কেএনএন এবং র্যান্ডম ফরেস্ট বেছে নিয়েছি।
তাদের পারফরম্যান্স মূল্যায়ন করার জন্য, আমরা আমাদের বেসলাইন নির্ভুলতাকে 1/71 =0.014 হিসাবে সংজ্ঞায়িত করেছি৷
আমরা ধরে নিয়েছিলাম যে একজন ব্যক্তি জাপানি ভাষা সম্পর্কে জ্ঞান ছাড়াই একটি চরিত্র সঠিক অনুমান করার 1.4% সম্ভাবনা থাকতে পারে।
এইভাবে, মডেলটি ভাল কাজ করবে যদি এর নির্ভুলতা 1.4% অতিক্রম করতে পারে। দেখা যাক ব্যাপারটা ছিল কিনা। ?
KNN
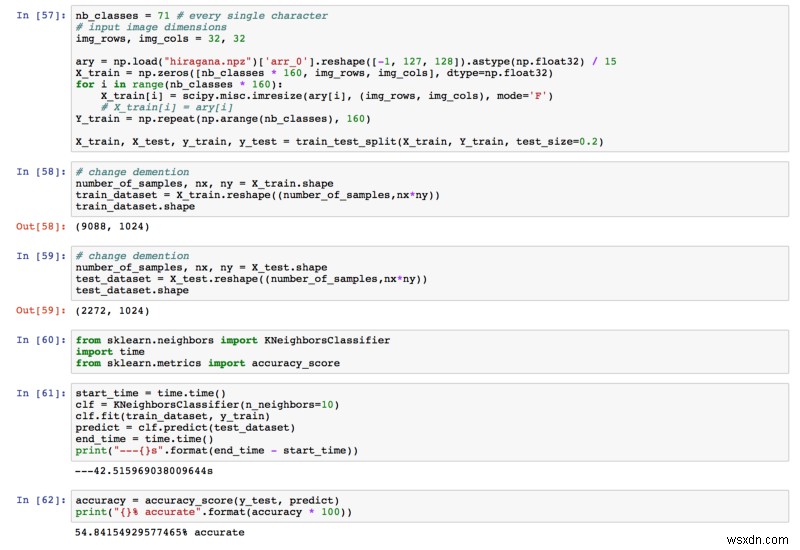
আমরা যে চূড়ান্ত নির্ভুলতা পেয়েছি তা ছিল 54.84%। ইতিমধ্যে 1.4% এর থেকে অনেক বেশি!
এলোমেলো বন
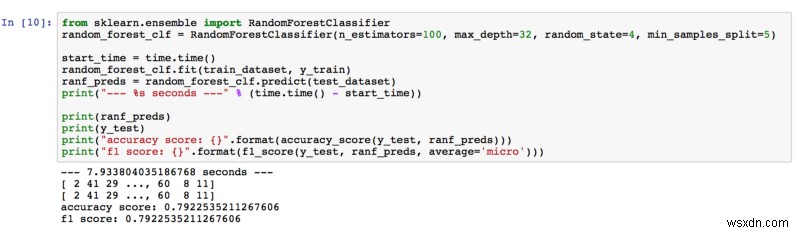
79.23% এর নির্ভুলতা, তাই র্যান্ডম ফরেস্ট আমাদের প্রত্যাশা ছাড়িয়ে গেছে। হাইপার-প্যারামিটার টিউন করার সময়, আমরা অনুমানকারীর সংখ্যা এবং গাছের গভীরতা বাড়িয়ে আরও ভাল ফলাফল পেয়েছি। আমরা ভেবেছিলাম যে বনে আরও গাছ (আনুমানিক) থাকার অর্থ চিত্রটিতে আরও বৈশিষ্ট্য শেখা হয়েছে। এছাড়াও, গাছ যত গভীর, বৈশিষ্ট্যগুলি থেকে এটি আরও বিশদ শিখেছে।
আপনি যদি আরও শিখতে আগ্রহী হন, আমি এই কাগজটি খুঁজে পেয়েছি যা র্যান্ডম ফরেস্টের সাথে চিত্রের শ্রেণীবিভাগ নিয়ে আলোচনা করে৷
পড়ার জন্য আপনাকে ধন্যবাদ। কোন চিন্তা এবং প্রতিক্রিয়া স্বাগত জানানো হয়!
