

GNU/Linux ডিস্ট্রিবিউশনে টেক্সট পরিচালনার জন্য প্রচুর প্রোগ্রাম রয়েছে, যার বেশিরভাগই GNU কোর ইউটিলিটিগুলি দ্বারা সরবরাহ করা হয়। এখানে কিছুটা শেখার বক্ররেখা রয়েছে, তবে সঠিকভাবে ব্যবহার করা হলে এই ইউটিলিটিগুলি খুব দরকারী এবং দক্ষ প্রমাণিত হতে পারে।
এখানে তেরোটি শক্তিশালী টেক্সট ম্যানিপুলেশন টুল রয়েছে প্রতিটি কমান্ড-লাইন ব্যবহারকারীর জানা উচিত।
1. বিড়াল
বিড়ালকেবিড়ালকে কনট করার জন্য ডিজাইন করা হয়েছিল enate ফাইল কিন্তু প্রায়শই একটি একক ফাইল প্রদর্শন করতে ব্যবহৃত হয়। কোনো যুক্তি ছাড়াই, বিড়াল Ctrl পর্যন্ত স্ট্যান্ডার্ড ইনপুট পড়ে + D চাপা হয় (টার্মিনাল থেকে বা পাইপ ব্যবহার করলে অন্য প্রোগ্রাম আউটপুট থেকে)। স্ট্যান্ডার্ড ইনপুট একটি - দিয়েও স্পষ্টভাবে নির্দিষ্ট করা যেতে পারে .
বিড়ালের বেশ কয়েকটি দরকারী বিকল্প রয়েছে, উল্লেখযোগ্যভাবে:
-Aপ্রতিটি লাইনের শেষে "$" প্রিন্ট করে এবং ক্যারেট নোটেশন ব্যবহার করে অমুদ্রিত অক্ষর প্রদর্শন করে।-nসমস্ত লাইন সংখ্যা।-bসংখ্যা রেখা যা ফাঁকা নয়।-sএকটি একক ফাঁকা লাইনের একটি সিরিজ ফাঁকা লাইন কমিয়ে দেয়।
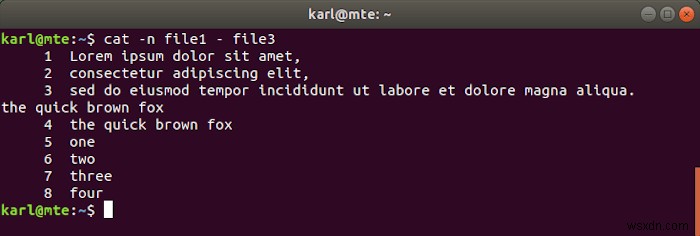
নিম্নলিখিত উদাহরণে, আমরা ফাইল 1, স্ট্যান্ডার্ড ইনপুট এবং ফাইল3 এর বিষয়বস্তুগুলিকে একত্রিত ও সংখ্যায়ন করছি৷
cat -n file1 - file3
2. সাজান
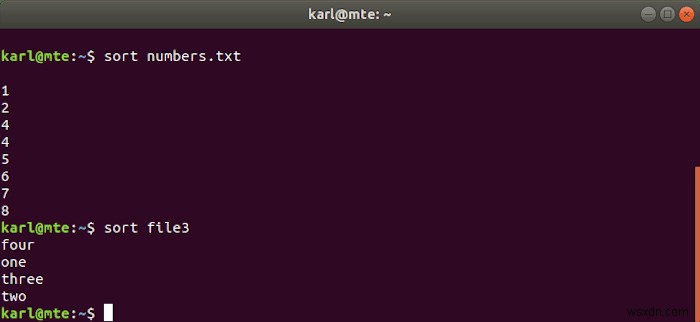
এর নাম অনুসারে, sort ফাইলের বিষয়বস্তু বর্ণানুক্রমিক এবং সংখ্যা অনুসারে সাজায়।
3. ইউনিক
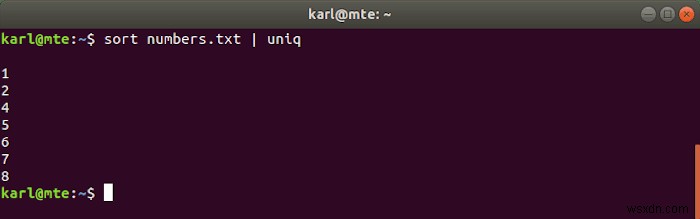
Uniq একটি সাজানো ফাইল নেয় এবং ডুপ্লিকেট লাইনগুলি সরিয়ে দেয়। এটি প্রায়শই sort দিয়ে চেইন করা হয় একক আদেশে।
4. com
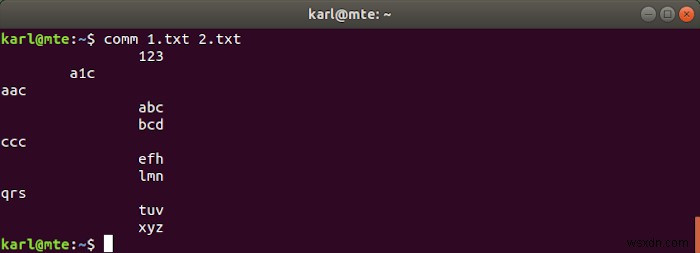
Comm দুটি সাজানো ফাইলের তুলনা করতে ব্যবহৃত হয়, লাইন দ্বারা লাইন। এটি তিনটি কলাম আউটপুট করে:প্রথম দুটি কলামে যথাক্রমে প্রথম এবং দ্বিতীয় ফাইলের জন্য অনন্য লাইন রয়েছে এবং তৃতীয়টি উভয় ফাইলে পাওয়া লাইনগুলি প্রদর্শন করে৷
5. কাটা
অক্ষর, ক্ষেত্র বা বাইটের উপর ভিত্তি করে লাইনের নির্দিষ্ট বিভাগ পুনরুদ্ধার করতে কাট ব্যবহার করা হয়। এটি একটি ফাইল থেকে বা স্ট্যান্ডার্ড ইনপুট থেকে পড়তে পারে যদি কোনো ফাইল নির্দিষ্ট করা না থাকে৷
অক্ষরের অবস্থান অনুসারে কাটা
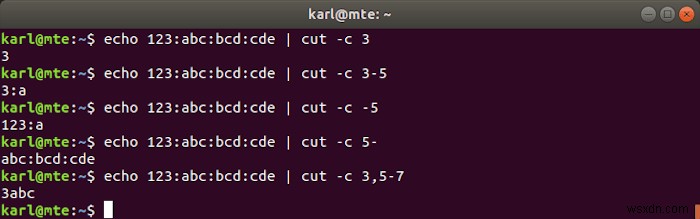
-c বিকল্প একটি একক অক্ষর অবস্থান বা অক্ষরের এক বা একাধিক ব্যাপ্তি নির্দিষ্ট করে৷
যেমন:
-c 3:৩য় অক্ষর।-c 3-5:৩য় থেকে ৫ম অক্ষর।-c -5অথবা-c 1-5:১ম থেকে ৫ম অক্ষর।-c 5-:5ম অক্ষর থেকে লাইনের শেষ পর্যন্ত।-c 3,5-7:৩য় এবং ৫ম থেকে ৭ম অক্ষর।
ক্ষেত্র অনুসারে কাটা
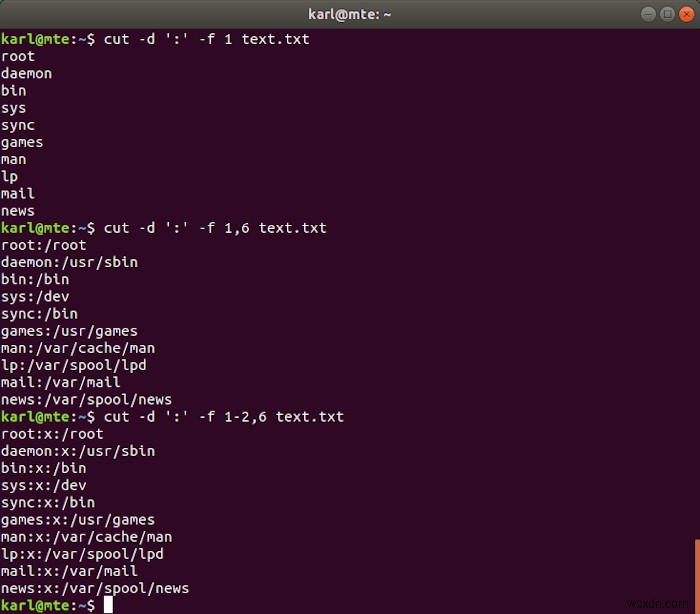
ক্ষেত্রগুলি একটি একক অক্ষর সমন্বিত একটি বিভাজন দ্বারা পৃথক করা হয়, যা -d দিয়ে নির্দিষ্ট করা হয় বিকল্প -f বিকল্পটি উপরের মত একই বিন্যাস ব্যবহার করে একটি ক্ষেত্র অবস্থান বা ক্ষেত্রগুলির এক বা একাধিক ব্যাপ্তি নির্বাচন করে৷
6. dos2unix
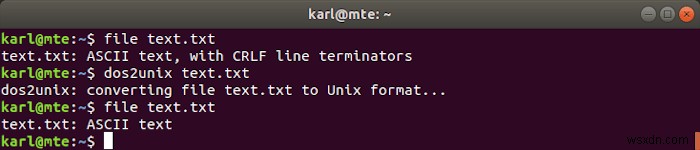
GNU/Linux এবং Unix সাধারণত লাইন ফিড (LF) দিয়ে টেক্সট লাইন বন্ধ করে দেয়, যখন Windows ক্যারেজ রিটার্ন এবং লাইন ফিড (CRLF) ব্যবহার করে। লিনাক্সে CRLF পাঠ্য পরিচালনা করার সময় সামঞ্জস্যের সমস্যা দেখা দিতে পারে, যেখানে dos2unix আসে। এটি CRLF টার্মিনেটরকে LF-তে রূপান্তর করে।
নিম্নলিখিত উদাহরণে, file dos2unix ব্যবহার করার আগে এবং পরে টেক্সট ফরম্যাট চেক করতে কমান্ড ব্যবহার করা হয় .
7. ভাঁজ
পাঠ্যের দীর্ঘ লাইন পড়া এবং পরিচালনা করা সহজ করতে, আপনি fold ব্যবহার করতে পারেন , যা একটি নির্দিষ্ট প্রস্থে লাইন মোড়ানো হয়।
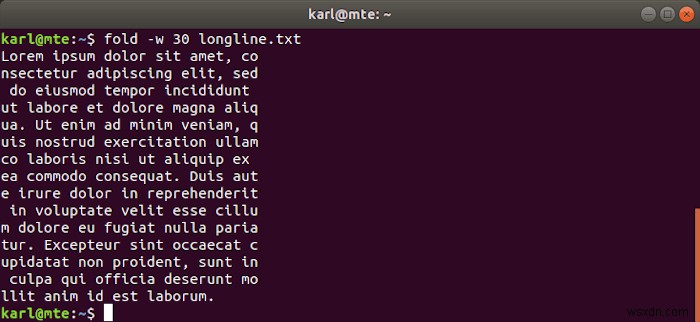
ভাঁজ ডিফল্টরূপে নির্দিষ্ট প্রস্থের সাথে মেলে, যেখানে প্রয়োজনে শব্দ ভাঙা।
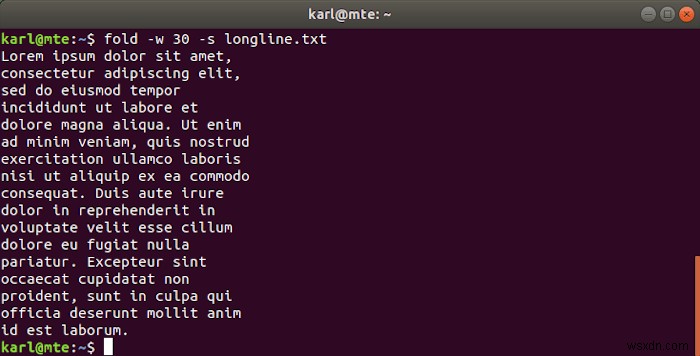
fold -w 30 longline.txt
শব্দ ভাঙা অবাঞ্ছিত হলে, আপনি -s ব্যবহার করতে পারেন শূন্যস্থানে বিরতির বিকল্প।
fold -w 30 -s longline.txt
8. iconv
এই টুলটি পাঠ্যকে এক এনকোডিং থেকে অন্য এনকোডিং-এ রূপান্তর করে, যা অস্বাভাবিক এনকোডিংগুলির সাথে কাজ করার সময় খুবই কার্যকর৷
iconv -f input_encoding -t output_encoding -o output_file input_file
- "ইনপুট_এনকোডিং" হল সেই এনকোডিং যা থেকে আপনি রূপান্তর করছেন৷ ৷
- “output_encoding” হল সেই এনকোডিং যা আপনি রূপান্তর করছেন।
- “output_file” হল ফাইলের নাম iconv এতে সেভ করা হবে।
- “input_file” হল ফাইলের নাম iconv থেকে পড়া হবে।
দ্রষ্টব্য: আপনি iconv -l দিয়ে উপলব্ধ এনকোডিং তালিকা করতে পারেন
9. sed
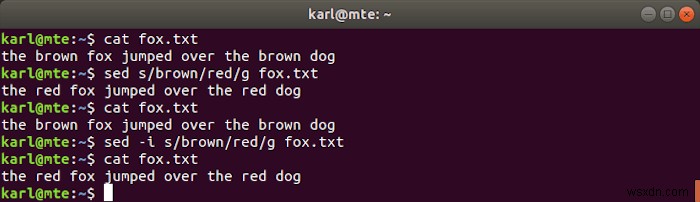
sed একটি শক্তিশালী এবং নমনীয় s tream ed itor, সাধারণত নিম্নলিখিত সিনট্যাক্সের সাথে স্ট্রিংগুলি খুঁজে পেতে এবং প্রতিস্থাপন করতে ব্যবহৃত হয়।
নিম্নলিখিত কমান্ডটি নির্দিষ্ট ফাইল (বা স্ট্যান্ডার্ড ইনপুট) থেকে পড়বে, পাঠ্যের অংশগুলি প্রতিস্থাপন করবে যা রেগুলার এক্সপ্রেশন প্যাটার্নের সাথে মেলে প্রতিস্থাপন স্ট্রিং দিয়ে এবং ফলাফলটি টার্মিনালে আউটপুট করবে।
sed s/pattern/replacement/g filename
পরিবর্তে আসল ফাইলটি পরিবর্তন করতে, আপনি -i ব্যবহার করতে পারেন পতাকা৷
10. wc
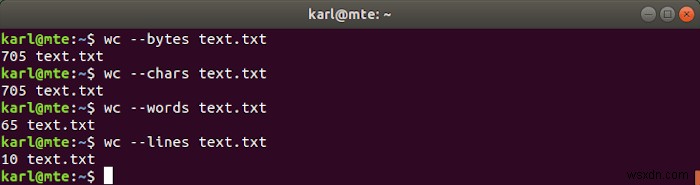
wc ইউটিলিটি ফাইলে বাইট, অক্ষর, শব্দ বা লাইনের সংখ্যা প্রিন্ট করে।
11. বিভক্ত
আপনি split ব্যবহার করতে পারেন একটি ফাইলকে ছোট ফাইলে, লাইনের সংখ্যা দ্বারা, আকার অনুসারে বা নির্দিষ্ট সংখ্যক ফাইলে ভাগ করতে।
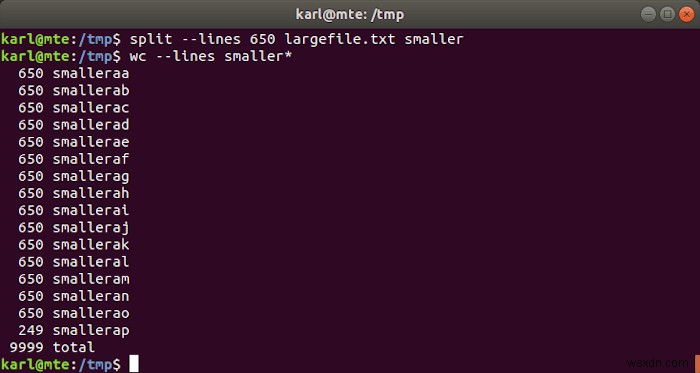
রেখার সংখ্যা দ্বারা বিভাজন
split -l num_lines input_file output_prefix
বাইট দ্বারা বিভক্ত করা৷
split -b bytes input_file output_prefix
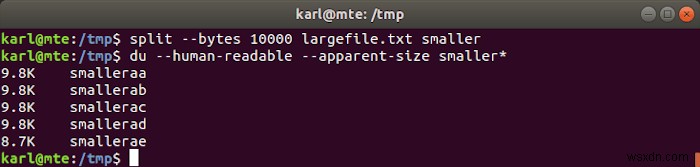
একটি নির্দিষ্ট সংখ্যক ফাইলে বিভক্ত করা
split -n num_files input_file output_prefix

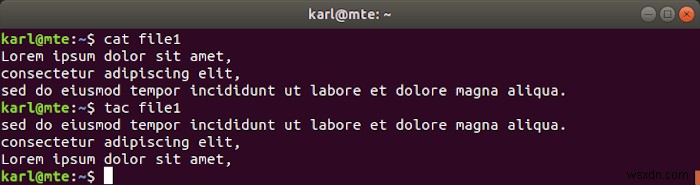
12. tac
Tac, যা বিপরীতে বিড়াল, ঠিক তাই করে:এটি বিপরীত ক্রমে লাইন সহ ফাইল প্রদর্শন করে।
13. tr
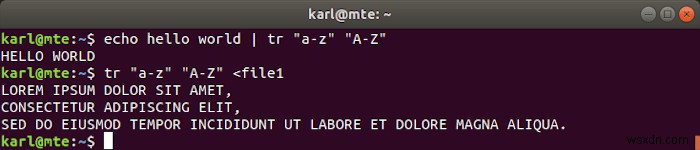
tr টুলটি অক্ষরের সেট অনুবাদ বা মুছে ফেলার জন্য ব্যবহৃত হয়।
অক্ষরের একটি সেট সাধারণত হয় একটি স্ট্রিং বা অক্ষরের রেঞ্জ। উদাহরণস্বরূপ:
- “A-Z”:সমস্ত বড় হাতের অক্ষর
- “a-z0-9”:ছোট হাতের অক্ষর এবং সংখ্যা
- “\n[:punct:]”:নতুন লাইন এবং বিরামচিহ্নের অক্ষর
আরো বিস্তারিত জানার জন্য tr ম্যানুয়াল পৃষ্ঠা দেখুন।
একটি সেট অন্য সেটে অনুবাদ করতে, নিম্নলিখিত সিনট্যাক্স ব্যবহার করুন:
tr SET1 SET2
উদাহরণস্বরূপ, ছোট হাতের অক্ষরগুলিকে তাদের বড় হাতের সমতুল্য দিয়ে প্রতিস্থাপন করতে, আপনি নিম্নলিখিতগুলি ব্যবহার করতে পারেন:
tr "a-z" "A-Z"
অক্ষরের একটি সেট মুছতে, -d ব্যবহার করুন পতাকা৷
tr -d SET

অক্ষরের একটি সেটের পরিপূরক মুছে ফেলতে (যেমন সেট ছাড়া সবকিছু), ব্যবহার করুন -dc .
tr -dc SET

উপসংহার
লিনাক্স কমান্ড লাইনের ক্ষেত্রে অনেক কিছু শেখার আছে। আশা করি, উপরের কমান্ডগুলি আপনাকে কমান্ড লাইনে পাঠ্যের সাথে আরও ভালভাবে মোকাবেলা করতে সহায়তা করবে।
