
অনেক পছন্দ যা আমরা করি সংখ্যাগত সম্পর্কের চারপাশে আবর্তিত।
- আমরা কিছু খাবার খাই কারণ বিজ্ঞান বলে যে এগুলো আমাদের কোলেস্টেরল কমায়
- আমরা আমাদের শিক্ষাকে এগিয়ে নিয়েছি কারণ আমাদের বেতন বৃদ্ধি পাওয়ার সম্ভাবনা রয়েছে
- আমরা আশেপাশে একটি বাড়ি কিনি যা আমরা বিশ্বাস করি যে এর মূল্য সবচেয়ে বেশি হবে
আমরা কিভাবে এই সিদ্ধান্তে আসতে পারি? সম্ভবত, কেউ প্রচুর পরিমাণে ডেটা সংগ্রহ করেছে এবং সিদ্ধান্তগুলি তৈরি করতে এটি ব্যবহার করেছে। একটি সাধারণ কৌশল হল লিনিয়ার রিগ্রেশন, যা তত্ত্বাবধানে শিক্ষার একটি রূপ। তত্ত্বাবধানে শেখার বিষয়ে আরও তথ্যের জন্য এবং এটি প্রায়শই কীসের জন্য ব্যবহৃত হয় তার উদাহরণের জন্য, এই সিরিজের পার্ট 1 দেখুন।
রৈখিক সম্পর্ক
যখন দুটি মান — তাদের কল করুন x এবং y — একটি রৈখিক সম্পর্ক আছে, এর মানে হল x পরিবর্তন করা 1 দ্বারা সর্বদা y হবে একটি নির্দিষ্ট পরিমাণে পরিবর্তন করতে। উদাহরণ দেওয়া সহজ:
- 10 পিজ্জার দাম একটি পিজ্জার দাম 10 গুণ।
- একটি 10-ফুট লম্বা দেওয়ালে 5-ফুট দেওয়ালের তুলনায় দ্বিগুণ পেইন্টের প্রয়োজন হয়
গাণিতিকভাবে, এই ধরনের সম্পর্ক একটি লাইনের সমীকরণ ব্যবহার করে বর্ণনা করা হয়:
y = mx + b
গণিত ভয়ঙ্করভাবে বিভ্রান্তিকর হতে পারে, কিন্তু প্রায়ই এটি আমার কাছে যাদু বলে মনে হয়। আমি যখন প্রথম একটি রেখার সমীকরণ শিখেছিলাম, তখন আমার মনে আছে শুধু একটি সূত্র দিয়ে একটি লাইনে দূরত্ব, ঢাল এবং অন্যান্য বিন্দু গণনা করতে পারা কত সুন্দর ছিল।
কিন্তু কিভাবে আপনি এই সূত্র পেতে পারেন, যদি আপনি সব তথ্য পয়েন্ট হয়? উত্তর হল লিনিয়ার রিগ্রেশন — একটি খুব জনপ্রিয় মেশিন লার্নিং টুল।
লিনিয়ার রিগ্রেশনের একটি উদাহরণ
এই পোস্টে, আমরা একটি গানের বীট পার মিনিট (BPM) Spotify-এ এর জনপ্রিয়তার পূর্বাভাস দেয় কিনা তা অন্বেষণ করতে যাচ্ছি।
লিনিয়ার রিগ্রেশন মডেল দুটি ভেরিয়েবলের মধ্যে সম্পর্ক। একটিকে "ব্যাখ্যামূলক পরিবর্তনশীল" বলা হয় এবং অন্যটিকে "নির্ভরশীল পরিবর্তনশীল" বলা হয়।
আমাদের উদাহরণে, আমরা দেখতে চাই যে BPM জনপ্রিয়তা "ব্যাখ্যা" করতে পারে কিনা। তাই BPM হবে আমাদের ব্যাখ্যামূলক পরিবর্তনশীল। এটি জনপ্রিয়তাকে নির্ভরশীল পরিবর্তনশীল করে তোলে।
মডেলটি ফর্মের সর্বোত্তম ফিটিং লাইন খুঁজে পেতে সর্বনিম্ন-বর্গক্ষেত্র রিগ্রেশন ব্যবহার করবে, আপনি এটি অনুমান করেছেন, y = mx + b .
যদিও একাধিক ব্যাখ্যামূলক ভেরিয়েবল থাকতে পারে, এই উদাহরণের জন্য আমরা সরল রৈখিক রিগ্রেশন পরিচালনা করব যেখানে শুধুমাত্র একটি আছে।
নিম্ন-বর্গক্ষেত্র কি?
লিনিয়ার রিগ্রেশন করার বিভিন্ন উপায় আছে। তাদের মধ্যে একটিকে "অন্যতম বর্গক্ষেত্র" বলা হয়। এটি প্রতিটি ডেটা পয়েন্ট থেকে লাইন পর্যন্ত উল্লম্ব বিচ্যুতির বর্গক্ষেত্রের যোগফলকে ছোট করে সর্বোত্তম ফিটিং লাইন গণনা করে।
আমি জানি এটি বিভ্রান্তিকর শোনাচ্ছে, কিন্তু এটি মূলত শুধু বলছে, "আমাকে এমন একটি লাইন তৈরি করুন যা উক্ত লাইন এবং ডেটা পয়েন্টগুলির মধ্যে স্থানের পরিমাণ কমিয়ে দেয়।"
স্কোয়ারিং এবং সমষ্টির কারণ হল ধনাত্মক এবং নেতিবাচক মানগুলির মধ্যে কোনও বাতিলকরণ নেই৷
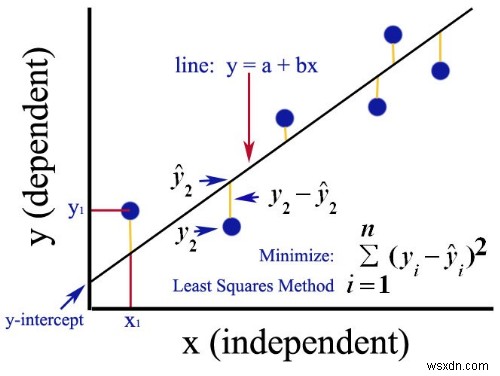
Quora-এ আমি এখানে একটি চিত্র পেয়েছি যা এটি ব্যাখ্যা করার জন্য একটি সুন্দর কাজ করে।
ডেটাসেট
আমরা Kaggle থেকে এই ডেটাসেটটি ব্যবহার করব:https://www.kaggle.com/leonardopena/top50spotify2019 আপনি এটি একটি CSV হিসাবে ডাউনলোড করতে পারেন৷
ডেটাসেটের 16টি কলাম আছে; যাইহোক, আমরা শুধুমাত্র তিনটি সম্পর্কে যত্নশীল - "ট্র্যাক নাম," "বিটস পার মিনিট," এবং "জনপ্রিয়তা।" মেশিন লার্নিংয়ের সবচেয়ে গুরুত্বপূর্ণ ধাপগুলির মধ্যে একটি হল আপনার ডেটা সঠিকভাবে ফরম্যাট করা, যাকে প্রায়ই "মুংগিং" বলা হয়। আপনি পূর্বোক্ত তিনটি কলাম ব্যতীত সমস্ত ডেটা মুছে ফেলতে পারেন৷
৷
আপনার CSV দেখতে এইরকম হওয়া উচিত: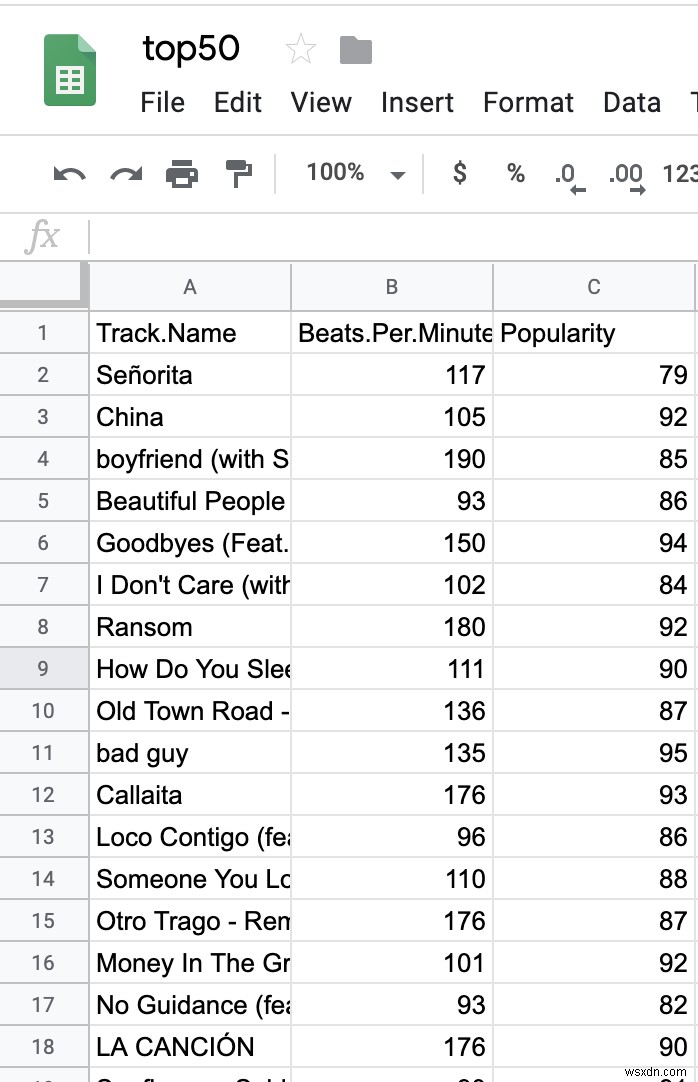
রিগ্রেশন করতে রুবি ব্যবহার করা
এই উদাহরণে, আমরা ruby_linear_regression ব্যবহার করব মণি ইনস্টল করতে, চালান:
gem install ruby_linear_regression
ঠিক আছে, আমরা কোডিং শুরু করতে প্রস্তুত! একটি নতুন রুবি ফাইল তৈরি করুন এবং এগুলি যোগ করুন:
require "ruby_linear_regression"
require "csv"
এরপর, আমরা আমাদের CSV ডেটা পড়ি এবং #shift কল করি , হেডার সারি বাতিল করতে। বিকল্পভাবে, আপনি CSV ফাইল থেকে প্রথম সারিটি মুছে ফেলতে পারেন।
csv = CSV.read("top50.csv")
csv.shift
আমাদের x-ডেটা পয়েন্ট এবং y-ডেটা পয়েন্ট ধরে রাখতে দুটি খালি অ্যারে তৈরি করি।
x_data = []
y_data = []
...এবং আমরা .each ব্যবহার করে পুনরাবৃত্তি করি Beats Per Minute যোগ করার পদ্ধতি আমাদের x অ্যারে এবং Popularity এর ডেটা আমাদের y অ্যারে তথ্য.
আপনি এখানে আসলে কি ঘটছে তা দেখতে আগ্রহী হলে, আপনি আপনার
rowলগ ইন করে পরীক্ষা করতে পারেন হয় একটিputsদিয়ে অথবাp. যেমন:puts row
csv.each do |row|
x_data.push( [row[1].to_i] )
y_data.push( row[2].to_i )
end
এখন ruby_linear_regression ব্যবহার করার সময় মণি আমরা আমাদের রিগ্রেশন মডেলের একটি নতুন উদাহরণ তৈরি করব, আমাদের ডেটা লোড করব এবং আমাদের মডেলকে প্রশিক্ষণ দেব:
linear_regression = RubyLinearRegression.new
linear_regression.load_training_data(x_data, y_data)
linear_regression.train_normal_equation
এর পরে, আমরা গড় বর্গাকার ত্রুটি (MSE) প্রিন্ট করব — পর্যবেক্ষণ করা মান এবং পূর্বাভাসিত মানগুলির মধ্যে পার্থক্যের একটি পরিমাপ। পার্থক্যটি বর্গ করা হয় যাতে নেতিবাচক এবং ইতিবাচক মান একে অপরকে বাতিল না করে। আমরা MSE কমিয়ে আনতে চাই কারণ আমরা চাই না আমাদের পূর্বাভাসিত এবং বাস্তব মানের মধ্যে দূরত্ব বড় হোক।
puts "Trained model with the following cost fit #{linear_regression.compute_cost}"
পরিশেষে, আসুন একটি ভবিষ্যদ্বাণী করতে কম্পিউটারকে আমাদের মডেল ব্যবহার করতে দিন। বিশেষভাবে, 250 BPM সহ একটি গান কতটা জনপ্রিয় হবে? prediction_data-এ বিভিন্ন মান নিয়ে নির্দ্বিধায় খেলা করুন অ্যারে
prediction_data = [250]
predicted_popularity = linear_regression.predict(prediction_data)
puts "Predicted popularity: #{predicted_popularity.round}"
ফলাফল
আসুন আমাদের কনসোলে প্রোগ্রামটি চালাই এবং দেখি আমরা কী পাই!
➜ ~ ruby spotify_regression.rb
Trained model with the following cost fit 9.504882197447587
Predicted popularity: 91
শান্ত! আসুন "250" থেকে "50" পরিবর্তন করি এবং দেখুন আমাদের মডেল কী ভবিষ্যদ্বাণী করে।
➜ ~ ruby spotify_regression.rb
Trained model with the following cost fit 9.504882197447587
Predicted popularity: 86
দেখা যাচ্ছে যে প্রতি মিনিটে বেশি বীট সহ গান বেশি জনপ্রিয়।
সম্পূর্ণ প্রোগ্রাম
এখানে আমার সম্পূর্ণ ফাইলটি কেমন দেখাচ্ছে:
require 'csv'
require 'ruby_linear_regression'
x_data = []
y_data = []
csv = CSV.read("top50.csv")
csv.shift
# Load data from CSV file into two arrays -- one for independent variables X (x_data) and one for the dependent variable y (y_data)
# Row[0] = title
# Row[1] = BPM
# Row[2] = Popularity
csv.each do |row|
x_data.push( [row[1].to_i] )
y_data.push( row[2].to_i )
end
# Create regression model
linear_regression = RubyLinearRegression.new
# Load training data
linear_regression.load_training_data(x_data, y_data)
# Train the model using the normal equation
linear_regression.train_normal_equation
# Output the cost
puts "Trained model with the following cost fit #{linear_regression.compute_cost}"
# Predict the popularity of a song with 250 BPM
prediction_data = [250]
predicted_popularity = linear_regression.predict(prediction_data)
puts "Predicted popularity: #{predicted_popularity.round}"
পরবর্তী ধাপগুলি
৷
এটি একটি খুব সাধারণ উদাহরণ, কিন্তু তবুও, আপনি শুধু আপনার প্রথম লিনিয়ার রিগ্রেশন চালিয়েছেন, যা মেশিন লার্নিংয়ের জন্য ব্যবহৃত একটি মূল কৌশল। আপনি যদি আরও কিছুর জন্য আকুল হয়ে থাকেন, তাহলে এখানে আরও কিছু জিনিস রয়েছে যা আপনি পরবর্তীতে করতে পারেন:- আমরা যে রুবি রত্নটি ব্যবহার করছিলাম তার জন্য আমরা যে গণিতটি হুডের নীচে ঘটছে তা দেখতে ব্যবহার করছিলাম - মূল ডেটা সেটে ফিরে যান এবং চেষ্টা করুন মডেলে অতিরিক্ত ভেরিয়েবল যোগ করা এবং একটি মাল্টি-ভেরিয়েবল রৈখিক রিগ্রেশন চালান তা আমাদের MSE কমাতে পারে কিনা তা দেখতে। উদাহরণস্বরূপ, সম্ভবত "ভ্যালেন্স" (গানটি কতটা ইতিবাচক) জনপ্রিয়তার ক্ষেত্রে একটি ভূমিকা পালন করে। - একটি গ্রেডিয়েন্ট ডিসেন্ট মডেল ব্যবহার করে দেখুন, যা ruby_linear_regression ব্যবহার করেও চালানো যেতে পারে মণি
