
AI গবেষণা এজেন্টদের পরিচিতি
একাডেমিক গবেষণা দ্রুত চলে—আরএক্সআইভি এবং অন্যান্য প্রি-প্রিন্ট সার্ভারে প্রতিদিন নতুন কাগজগুলি উপস্থিত হয়৷ ম্যানুয়ালি চালিয়ে যাওয়া অপ্রতিরোধ্য হতে পারে৷ এই নির্দেশিকাতে, আমরা একটি AI গবেষণা সহকারী তৈরি করব যে:
- একজন গবেষকের প্রাকৃতিক-ভাষা প্রশ্ন বোঝেন
- আরএক্সিভ অ্যাবস্ট্রাক্টের ভেক্টর ডাটাবেসে সবচেয়ে প্রাসঙ্গিক কাগজপত্র খুঁজে পায়
- মূল অন্তর্দৃষ্টিগুলিকে সংক্ষিপ্ত করে এবং ব্যাখ্যা করে কিভাবে তারা প্রশ্নের উত্তর দেয়
- গভীরভাবে পড়ার জন্য একটি সরাসরি PDF লিঙ্ক প্রদান করে
আমরা এটি মাস্ত্র দিয়ে সম্পন্ন করব , AI এজেন্ট তৈরির জন্য একটি ওপেন সোর্স TypeScript ফ্রেমওয়ার্ক এবং Upstash সার্ভারহীন রেডিস এবং ভেক্টর স্টোরেজের জন্য। এখানে AI গবেষণার উপর দৃষ্টি নিবদ্ধ করা আমাদের নিবন্ধ এজেন্টের একটি লাইভ ডেমো রয়েছে। আপনার চেষ্টা করার জন্য এটি Vercel এ স্থাপন করা হয়েছে।
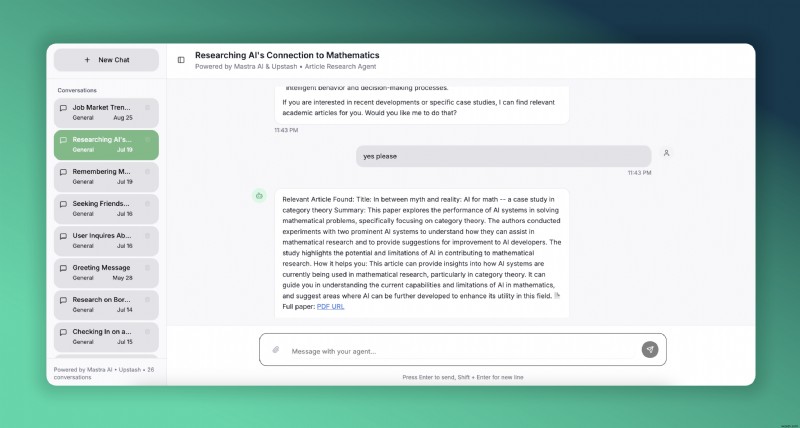
মাস্ত্রা কি?
Mastra হল একটি ব্যাটারি-অন্তর্ভুক্ত ফ্রেমওয়ার্ক যা প্রোডাকশন-গ্রেড এআই এজেন্ট তৈরি করা সহজ করে তোলে।
- এজেন্ট এবং ওয়ার্কফ্লো — রচনা এজেন্ট, সরঞ্জাম, এবং বহু-পদক্ষেপ কর্মপ্রবাহ
- পুনরুদ্ধার-অগমেন্টেড জেনারেশন (RAG) - অন্তর্নির্মিত মেমরি এবং ভেক্টর স্টোর
- মাল্টি-এলএলএম - OpenAI, Claude এবং আরও অনেক কিছুর সাথে কাজ করে৷
আমরা একটি এজেন্ট তৈরি করব যা মেমরির জন্য Upstash Redis ব্যবহার করে। প্রাসঙ্গিক গবেষণা নিবন্ধগুলি খুঁজে পাওয়ার জন্য এটিতে একটি সরঞ্জামও থাকবে, যা আমরা পূর্বে একটি Upstash ভেক্টর ডাটাবেসে এম্বেড করে রাখব৷
আরও গভীরে ডুব দেওয়ার জন্য, Mastra ডকুমেন্টেশন দেখুন।
প্রজেক্টের জন্য টেক স্ট্যাক
- মাস্ত্রা ফ্রেমওয়ার্ক AI এজেন্ট এবং টুল তৈরি করতে
- Upstash Redis এজেন্টকে কথোপকথনের স্মৃতি দিতে
- আপস্ট্যাশ ভেক্টর রিসার্চ আর্টিকেল অ্যাবস্ট্রাক্টের এমবেডিং সঞ্চয় করতে
- Next.js এবং Vercel ওয়েব অ্যাপ্লিকেশন তৈরি এবং স্থাপন করতে
আমরা আমাদের ডেমো অ্যাপ্লিকেশনের জন্য অনুরোধ সীমিত করতে Upstash Ratelimit ব্যবহার করব।
ইমপ্লিমেন্টেশন ওয়াকথ্রু
এই অ্যাপ্লিকেশনটি তৈরি করার জন্য দুটি প্রধান উপাদান তৈরি করা জড়িত:Mastra সার্ভার এবং ওয়েব অ্যাপ্লিকেশন। যদিও তারা একই প্রকল্পে থাকতে পারে, তাদের আলাদা রাখা পরিষ্কার। মাস্ট্রা সার্ভার দিয়ে শুরু করা যাক।
একটি Mastra প্রকল্প তৈরি করা
একটি নতুন মাস্টার প্রকল্প তৈরি করতে, আপনার টার্মিনালে নিম্নলিখিত কমান্ডটি চালান৷
৷npm create mastra@latestএটি কয়েকটি প্রশ্ন জিজ্ঞাসা করবে; এই প্রকল্পের জন্য, ডিফল্ট সেটিংস ঠিক আছে৷
এজেন্ট এবং টুল তৈরি করা
একটি এজেন্ট কনফিগার করার প্রথম ধাপ হল এর নাম, উদ্দেশ্য এবং সরঞ্জামগুলিকে সংজ্ঞায়িত করা। প্রদত্ত কাজের জন্য একটি ভাষা মডেল বেছে নেওয়াও গুরুত্বপূর্ণ। এই প্রকল্পে, আমাদের একটি এজেন্ট এবং একটি টুল থাকবে৷
৷export const articleAgent = new Agent({
name: "articleAgent",
instructions: instruction,
model: openai('gpt-4o'),
tools: { articleQueryTool },
memory: memory
});
একটি এজেন্ট কনফিগার করা উপরে দেখানো হিসাবে সহজ. আমরা আমাদের articleAgent সংজ্ঞায়িত করি একটি instruction সহ (যা একটি সিস্টেম প্রম্পট হিসাবে কাজ করে), এটি ডেডিকেটেড tools , model , এবং আরেকটি গুরুত্বপূর্ণ উপাদান:memory .
এজেন্টের স্মৃতি
Mastra এজেন্টদের চ্যাট ইতিহাস এবং শব্দার্থিক স্মরণ ক্ষমতা উভয়ই প্রদান করে। স্টোরেজে মেমরি বজায় রাখার মাধ্যমে, এজেন্ট আরও ব্যক্তিগতকৃত এবং সঠিক উত্তর দিতে পারে। আসুন আমাদের এজেন্টের মেমরি কনফিগারেশন দেখি।
export const memory = new Memory({
storage: myUpstashStore,
options: {
lastMessages: 10,
semanticRecall: false,
threads: {
generateTitle: true
}
}
});
চ্যাট ইতিহাস সক্ষম করতে, আমরা আমাদের স্টোরেজ বিকল্প হিসাবে Upstash Redis ব্যবহার করি। আমরা এটিকে একটি UpstashStore হিসেবে শুরু করি বস্তু, যা MastraStorage প্রসারিত করে , নিশ্চিত করে যে এটি আমাদের মাস্ট্রা এজেন্টের সাথে নির্বিঘ্নে কাজ করে।
export const myUpstashStore = new UpstashStore({
url: process.env.UPSTASH_REDIS_REST_URL!,
token: process.env.UPSTASH_REDIS_REST_TOKEN!,
});আমরা পূর্বে আমাদের এজেন্টে একটি শব্দার্থিক প্রত্যাহার বৈশিষ্ট্য যোগ করার কথা উল্লেখ করেছি, যা এটিকে বর্তমান প্রেক্ষাপটের সাথে সম্পর্কিত পূর্ববর্তী বার্তাগুলি বিবেচনা করার অনুমতি দেয়। এর জন্য, এজেন্টের একটি ভেক্টর ডাটাবেস এবং বার্তাগুলি প্রক্রিয়া করার জন্য একটি এমবেডার প্রয়োজন৷ যেহেতু আমাদের সর্বজনীন ডেমো ব্যক্তিগত ব্যবহারের জন্য নয় এবং বিভিন্ন থ্রেড জুড়ে বার্তাগুলি মনে রাখার প্রয়োজন নেই, তাই আমরা এই বৈশিষ্ট্যটি ব্যবহার করব না, তবে এটি নিম্নরূপ প্রয়োগ করা যেতে পারে৷
export const myUpstashVector = new UpstashVector({
url: process.env.UPSTASH_VECTOR_REST_URL!,
token: process.env.UPSTASH_VECTOR_REST_TOKEN!,
});
export const memory = new Memory({
storage: myUpstashStore,
vector: myUpstashVector,
embedder: openai.embedding("text-embedding-3-small"),
options: {
lastMessages: 10,
semanticRecall: {
topK: 3,
messageRange: 2,
scope: 'resource'
},
threads: {
generateTitle: true
}
}
});শব্দার্থিক রিকল কনফিগারেশনে, topK messageRange পুনরুদ্ধার করার জন্য অনুরূপ বার্তাগুলির সংখ্যা নির্দিষ্ট করে প্রতিটি ম্যাচের সাথে কতটা পারিপার্শ্বিক প্রসঙ্গ অন্তর্ভুক্ত করতে হবে তা নির্ধারণ করে এবং স্কোপ সেট করে 'রিসোর্স' থেকে 'রিসোর্স' নামের ব্যবহারকারীর সাথে যুক্ত সমস্ত থ্রেড জুড়ে এজেন্ট অনুসন্ধান করে। এই ক্রস-থ্রেড মেমরিটি আপস্ট্যাশের সাথে উপলব্ধ একটি শক্তিশালী।
সরঞ্জাম
একটি টুল তৈরি করা একটি এজেন্ট তৈরির মতোই সহজ। আমরা একটি নাম, বিবরণ, ইনপুট এবং আউটপুট স্কিমা এবং এজেন্টের টুলের ক্ষমতার প্রয়োজন হলে চালানোর জন্য একটি ফাংশন প্রদান করি।
export const articleQueryTool = createTool({
id: 'get-relevant-article',
description: 'Get relevant article information',
inputSchema: z.object({
question: z.string().describe('the question about the field'),
}),
outputSchema: z.object({
bestOption: z.object({
abstract: z.string().describe('the abstract of the article'),
title: z.string().describe('the title of the article'),
pdfUrl: z.string().describe('the PDF URL of the article')
})
}),
execute: async ({ context }) => {
return await querySimilar(context.question);
},
});ইনপুট এবং আউটপুট স্কিমা যাচাই করতে আমরা Zod ব্যবহার করি। এটি ধারাবাহিক প্রতিক্রিয়া বজায় রাখতে সাহায্য করে এবং LLM থেকে সম্ভাব্য ত্রুটিগুলি কমিয়ে দেয়। আমরা টুল ব্যবহার করার জন্য একটি ফাংশন সংজ্ঞায়িত করি। আমাদের টুলটি গবেষণা নিবন্ধের একটি বড় সংগ্রহের জন্য জিজ্ঞাসা করবে, যা নিয়মিতভাবে arXiv API এর মাধ্যমে আপডেট করা হয় এবং আমাদের Upstash Vector ডাটাবেসে এম্বেড করা হয়।
const querySimilar = async (query: string) => {
const { embedding } = await embed({
value: query,
model: openai.embedding("text-embedding-3-small"),
});
const results = await myMastraUpstashVector.query({
indexName: "arxiv",
queryVector: embedding,
topK: 3,
});
if (results && results.length > 0) {
const bestMatch = results[0];
const metadata = bestMatch.metadata as ArxivPaper;
return {
bestOption: {
abstract: metadata.abstract,
title: metadata.title,
pdfUrl: metadata.pdfUrl
}
};
}
throw new Error("No relevant information found");
}
আমরা একটি UpstashVector এর মাধ্যমে আমাদের ভেক্টর ডাটাবেসে সহজ অপারেশন করতে পারি উদাহরণ, যা MastraVector প্রসারিত করে . উপরে, আমরা অনুরূপ নিবন্ধের বিমূর্তগুলির জন্য অনুসন্ধান করি যা আমরা আগে থেকে এম্বেড করেছি এবং সরঞ্জামটিতে সেরা ফলাফল ফিরিয়ে দিই। মনে রাখবেন যে আমরা ক্যোয়ারীটির জন্য একই এমবেডিং মডেল ব্যবহার করি যেমনটি আমরা নিবন্ধগুলির জন্য করেছি৷ আমরা পরে আরো বিস্তারিতভাবে নিবন্ধ এমবেডিং ব্যাখ্যা করব৷
মাস্ত্রা ইন্সট্যান্স
export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
deployer: new VercelDeployer()
});
কোন এজেন্ট ব্যবহার করতে হবে তা আমরা সহজভাবে উল্লেখ করি এবং আমাদের Mastra বস্তু প্রস্তুত। আমরা ইন-মেমরি স্টোরেজের বাইরেও ডেটা বজায় রাখার জন্য স্টোরেজ প্রদান করি। আপনি উপলব্ধ স্থাপনার কনফিগারেশন থেকেও চয়ন করতে পারেন; আমরা Vercel ব্যবহার করে স্থাপন করব।
create-mastra-app থেকে ডিফল্ট বিকল্পগুলির সাথে , আমাদের কাছে ইতিমধ্যেই প্রয়োজনীয় ফাইল কাঠামো আছে:
.
└── mastra
├── agents
│ └── index.ts
├── tools
│ └── index.ts
└── index.ts
স্থাপন করার আগে শুধুমাত্র একটি ধাপ বাকি আছে:আমাদের পরিবেশ পরিবর্তনশীল।
OPENAI_API_KEY=
UPSTASH_VECTOR_REST_URL=
UPSTASH_VECTOR_REST_TOKEN=
UPSTASH_REDIS_REST_URL=
UPSTASH_REDIS_REST_TOKEN=
এগুলিকে আপনার .env.local এ রাখুন স্থানীয় উন্নয়নের জন্য ফাইল করুন এবং সেগুলিকে আপনার স্থাপনার পরিবেশে যুক্ত করুন৷
এখন আমরা আমাদের Mastra সার্ভার তৈরি এবং স্থাপন করতে প্রস্তুত৷
৷npm run build && vercel --prodকিভাবে স্থাপন করতে হয় তা দেখতে আপনি Vercel ডকুমেন্টেশন চেক করতে পারেন।
বিকাশ করার সময়, আমরা আমাদের সার্ভারের আউটপুট দেখতে Mastra খেলার মাঠ ব্যবহার করতে পারি। নিম্নলিখিত কমান্ড চালান:
npm run devএটি একটি ওয়েব ইন্টারফেসের একটি লিঙ্ক প্রদান করবে যেখানে আপনি আমাদের এজেন্টের সাথে চ্যাট করতে পারবেন, সরঞ্জামগুলি স্পষ্টভাবে চালাতে পারবেন এবং আমাদের সার্ভারের ক্ষমতাগুলি অন্বেষণ করতে পারবেন৷
এখন আবেদনের অন্য অংশ সম্পর্কে কথা বলার সময়।
Next.js সার্ভার
একবার Mastra সার্ভার সেট আপ হয়ে গেলে, আমাদের তিনটি জিনিস পরিচালনা করতে হবে:UI, Mastra সার্ভারের সাথে যোগাযোগ এবং একটি নিবন্ধ পরিষেবা যা arXiv API এর সাথে কথা বলে এবং বিমূর্তগুলি Upstash ভেক্টরে এম্বেড করে। সার্ভারের কার্যকারিতা প্রকাশ করার জন্য Mastra এর একটি ক্লায়েন্ট SDK আছে। এটির মাধ্যমে, আপনি এজেন্ট, সরঞ্জাম, মেমরি এবং আরও অনেক কিছু অ্যাক্সেস করতে পারেন। এর ব্যবহার সহজবোধ্য, তবে আমরা কিছু উদাহরণ শেয়ার করব। আরো বিস্তারিত জানার জন্য, আপনি এখানে ডকুমেন্টেশন চেক করতে পারেন। একটি Next.js প্রকল্পে, আপনি সহজভাবে ক্লায়েন্ট SDK ইনস্টল এবং ব্যবহার করতে পারেন।
npm install @mastra/client-js@latest
আপনার কোডে, MastraClient এর একটি উদাহরণ তৈরি করুন আপনার প্রকল্পে এটি ব্যবহার করার জন্য।
import { MastraClient } from "@mastra/client-js";
export const mastra_sdk = new MastraClient({
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API!,
retries: 3,
});
আপনাকে NEXT_PUBLIC_MASTRA_API সেট করতে হবে আপনার মাস্টার সার্ভারের ঠিকানায়। আপনি স্থানীয়ভাবে বিকাশ করলে, এটি একটি localhost হবে ঠিকানা যেহেতু 3000 এ সম্ভবত একটি পোর্ট বিরোধ হবে , স্থানীয়ভাবে চালানোর সময় আপনি Mastra সার্ভারের কনফিগারেশন পরিবর্তন করতে পারেন, নিম্নরূপ:
export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
server: {
port: 4111,
timeout: 10000,
}
});
এখন, যখন আমরা মাস্ট্রা সার্ভার স্থানীয়ভাবে npm run dev দিয়ে চালাই , এটি 4111 পোর্টে পরিবেশন করা হয় . আমরা NEXT_PUBLIC_MASTRA_API সেট করতে পারি http://localhost:4111 এ যখন আমরা স্থানীয়ভাবে Next.js প্রকল্প চালাই।
আসুন দেখি কিভাবে আমরা Mastra এর ক্লায়েন্ট SDK ব্যবহার করতে পারি।
export const MASTRA_CONFIG = {
resourceId: process.env.NEXT_PUBLIC_RESOURCE_ID || "articleAgent",
agentId: "articleAgent",
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API || "http://localhost:4111",
retries: 3,
}; // this is exported in another file so that we can use it anywhere in the codebase.
// Get your agent and simply stream your response through your agent object.
const agent = mastra_sdk.getAgent(MASTRA_CONFIG.agentId);
const response = await agent.stream({
messages: [message],
resourceId: MASTRA_CONFIG.resourceId,
threadId: threadId
});আপনি আপনার সরঞ্জাম এবং এজেন্ট পেতে পারেন, এবং একবার আপনার কাছে সেগুলি হয়ে গেলে, আপনি ক্লায়েন্ট SDK-এর মাধ্যমে প্রকৃত বস্তুগুলির সাথে যা করতে পারেন প্রায় সবকিছুই করতে পারেন৷
যেহেতু আমরা এই ডেমো প্রকল্পটি সর্বজনীনভাবে প্রকাশ করব, তাই এজেন্টের উপর ভারী বোঝা এড়ানো গুরুত্বপূর্ণ। এখানেই Upstash Ratelimit আসে। প্রতিটি স্ট্রিম রিকোয়েস্টের আগে, আমরা চেক করব ব্যবহারকারী রেট-সীমিত কিনা। আমাদের রেট লিমিটার কনফিগার করতে, আমাদের Upstash Redis প্রয়োজন হবে। আমরা আমাদের Mastra এজেন্টের জন্য একই Redis ডাটাবেস ব্যবহার করতে পারি।
import { Ratelimit } from '@upstash/ratelimit';
import { Redis } from '@upstash/redis';
// Using the same Redis DB across the project
export const rateLimit = new Ratelimit({
redis: new Redis({
url: process.env.UPSTASH_REDIS_MEMORY_URL!,
token: process.env.UPSTASH_REDIS_MEMORY_TOKEN!
}),
limiter: Ratelimit.slidingWindow(10, '10s'),
prefix: 'upstash-ratelimit',
});
// Fetch the below function before every stream.
export async function isRateLimited(id: string): Promise<boolean> {
const { success } = await rateLimit.limit(id);
return !success;
}এইভাবে, আমরা নিশ্চিত করি যে আমাদের শেষ পয়েন্টগুলি ভারী বোঝার মধ্যে থাকবে না।
Mastra এর সাথে চ্যাট এজেন্ট তৈরি করার সময়, Mastra এর থ্রেড জেনারেশনের কিছু বৈশিষ্ট্য জানা সহায়ক হতে পারে। মনে রাখবেন যে আমরা যখন এজেন্টের জন্য মেমরি কনফিগার করি, তখন আমরা generateTitle সেট করি true এ threads-এ বস্তু এটি Mastra নতুন তৈরি থ্রেডের জন্য স্বয়ংক্রিয়ভাবে শিরোনাম তৈরি করে। কিন্তু এখানে ধরা হল:স্পষ্টভাবে একটি থ্রেড তৈরি করা সম্ভব, কিন্তু স্বয়ংক্রিয় শিরোনাম প্রজন্ম সেভাবে ট্রিগার হয় না। সাধারণত, একটি নতুন থ্রেড তৈরি করার উপায় নিম্নরূপ:
const thread = await mastraClient.createMemoryThread({
title: "New Conversation",
metadata: { category: "support" },
resourceId: "resource-1",
agentId: "agent-1",
});
যাইহোক, এটি স্বয়ংক্রিয়ভাবে শিরোনাম তৈরি করার এজেন্টের ক্ষমতা কেড়ে নেয়, যেহেতু আপনি এটি ম্যানুয়ালি সেট করছেন। title ছেড়ে যাচ্ছে খালি ক্ষেত্রও কাজ করে না। এই ক্ষেত্রে, আমরা খেলার মাঠ কি করে তা দেখতে পারি। বিকাশের সময় আপনার সার্ভারের ক্ষমতাগুলি অনুভব করার জন্য মাস্টার দ্বারা সরবরাহ করা খেলার মাঠটির কথা মনে আছে? যদি আমরা ব্রাউজারের বিকাশকারী সরঞ্জামগুলিতে নেটওয়ার্ক ট্যাবটি পরিদর্শন করি, আমরা দেখতে পাই যে যখন একটি নতুন থ্রেড তৈরি করা হয়, এটি আসলে এটি তৈরি করার জন্য একটি API অনুরোধ পাঠায় না। পরিবর্তে, এটি আপনার প্রথম বার্তা জমা দেওয়ার জন্য অপেক্ষা করে। এর পরে, এটি একটি নতুন উত্পন্ন থ্রেড আইডি সহ একটি স্ট্রিম অনুরোধ পাঠায়। এটি মাস্ট্রাকে বলে যে এই আইডির সাথে কোনও থ্রেড নেই, তাই এটি একটি তৈরি করা উচিত এবং যদি generateTitle সত্য, প্রথম বার্তার উপর ভিত্তি করে একটি শিরোনাম তৈরি করুন৷
চলুন আমাদের প্রকল্পের শেষ উপাদানটি নিয়ে চলুন:arXiv নিবন্ধগুলি৷
৷arXiv প্রবন্ধ
arXiv বিভিন্ন ক্ষেত্রে প্রায় 2.4 মিলিয়ন গবেষণা নিবন্ধের জন্য একটি ওপেন-অ্যাক্সেস সংরক্ষণাগার। articleQueryTool Upstash ভেক্টর ডাটাবেসকে জিজ্ঞাসা করে, যা arXiv API-এর মাধ্যমে আনা নিবন্ধ দ্বারা খাওয়ানো হয়। API ব্যবহার করা সহজ; আপনি এখানে আরো বিস্তারিত জানতে পারেন।
আমাদের প্রজেক্টে, আমরা প্রতিদিন প্রবন্ধ সংগ্রহ করি এবং সঞ্চয় করি। প্রথমবার সার্ভারটি চালানোর সময়, এটি নির্দিষ্ট বিভাগ থেকে প্রায় 30,000 নিবন্ধ নিয়ে আসে। এর পরে, এটি আগের দিন প্রকাশিত নতুন নিবন্ধগুলি নিয়ে আসে। নিবন্ধের বিভাগগুলি নির্দিষ্ট করতে এবং প্রাথমিক বড় ব্যাচ আনতে হবে কিনা, আমরা সংশ্লিষ্ট পরিবেশের ভেরিয়েবল সেট করি। কমা দ্বারা পৃথক করা arXiv-এর শ্রেণীবিন্যাস ব্যবহার করে আমাদের কাঙ্ক্ষিত নিবন্ধের বিভাগগুলি প্রদান করা উচিত। আপনি এখানে বিভাগগুলি দেখতে পারেন৷
৷CATEGORIES=cs.AI
RUN_BEGINNING_STACK=falseআপনি যদি আরও ব্যাপক ডাটাবেস চান, আপনি arXiv এর বাল্ক ডেটা অ্যাক্সেস ব্যবহার করতে পারেন। এটি ছাড়া, আমরা প্রতি API ক্যোয়ারী 30,000 নিবন্ধের মধ্যে সীমাবদ্ধ, যা আমাদের উদ্দেশ্যে যথেষ্ট।
arXiv-এর একটি সাধারণ প্রশ্ন এইরকম দেখায়:
const categories = process.env.CATEGORIES?.split(',') || []; // Get the desired categories and split them for the query.
const searchQuery = categories.length === 1 ? `cat:${categories[0]}` : `(${categories.map(c => `cat:${c}`).join(" OR ")})`;
const query = `search_query=${searchQuery}&sortBy=submittedDate&sortOrder=descending`;
const url = `http://export.arxiv.org/api/query?${query}`;
const response = await axios.get(url); // Make the API call with the constructed URL.আমরা প্রতিদিন সর্বশেষ নিবন্ধ পেতে এবং প্রাথমিক স্ট্যাক আনতে একই রকম কল করি।
নিবন্ধগুলি আনার পরে, আমরা সেগুলিকে স্বাভাবিক করি এবং আপস্ট্যাশ ভেক্টরে সঞ্চয়ের জন্য এম্বেড করি। এটি অবশ্যই একই ভেক্টর ডাটাবেস হতে হবে যা আমাদের Mastra টুল ব্যবহার করে। "স্বাভাবিককরণ" দ্বারা আমরা বোঝাই যে আনা নিবন্ধগুলিকে একটি আদর্শ ArxivPaper-এ পার্স করা টাইপ, যা আমরা আমাদের কোডবেস জুড়ে ব্যবহার করব।
export interface ArxivPaper {
id: string;
title: string;
abstract: string;
authors: string[];
published: string;
pdfUrl: string;
category: string;
}// The type for our articles, across our codebase.
async function storeAbstracts(papers: ArxivPaper[]) {
const embeddingModel = openai.embedding("text-embedding-3-small"); // The same model used to query on the Mastra side.
const embeddings = await embedArticles(papers, embeddingModel)
// Put the embeddings into the required form with their metadata.
const vectorsToUpsert = getVectorsToUpsert(embeddings, papers)
for (let j = 0; j < vectorsToUpsert.length; j++) {
await vectorStore.upsert(vectorsToUpsert[j], { namespace: "arxiv" }); // Upsert the embeddings with their metadata to Upstash Vector.
}
}সর্বশেষ গবেষণার সাথে আমাদের ডাটাবেস বর্তমান থাকা নিশ্চিত করার জন্য, আমরা নির্ধারিত কাজ সম্পাদনের জন্য Upstash QStash প্রয়োগ করি। Vercel এ আমাদের স্থাপনার প্রেক্ষিতে, আমাদের ফাংশন টাইমআউট প্রতিরোধ করতে হবে যা বর্ধিত প্রক্রিয়াকরণের ব্যবধানের সাথে ঘটতে পারে। আমরা আমাদের সার্ভারে একটি পাবলিক API এন্ডপয়েন্ট উন্মোচন করে এর সমাধান করি, আমাদের QStash ইন্সট্যান্সকে দৈনিক ডাটাবেস আপডেট ফাংশন নির্ভরযোগ্যভাবে ট্রিগার করতে সক্ষম করে।
// src/app/api/arxiv_reneval/route.ts
import { verifySignatureAppRouter } from "@upstash/qstash/nextjs"
import { fetchAndUpsertYesterday} from "@/services/arxiv"
async function handler(request: Request) {
console.log("Fetching and upserting yesterday's papers...")
await fetchAndUpsertYesterday()
console.log("Fetching and upserting yesterday's papers completed")
return Response.json({ success: true })
}
export const POST = verifySignatureAppRouter(handler)প্রতিদিন সকাল 6:00 AM UTC-এ স্বয়ংক্রিয়ভাবে এই এন্ডপয়েন্টে অনুরোধগুলি ট্রিগার করতে Upstash কনসোলের মাধ্যমে একটি সময়সূচী কনফিগার করা যেতে পারে।
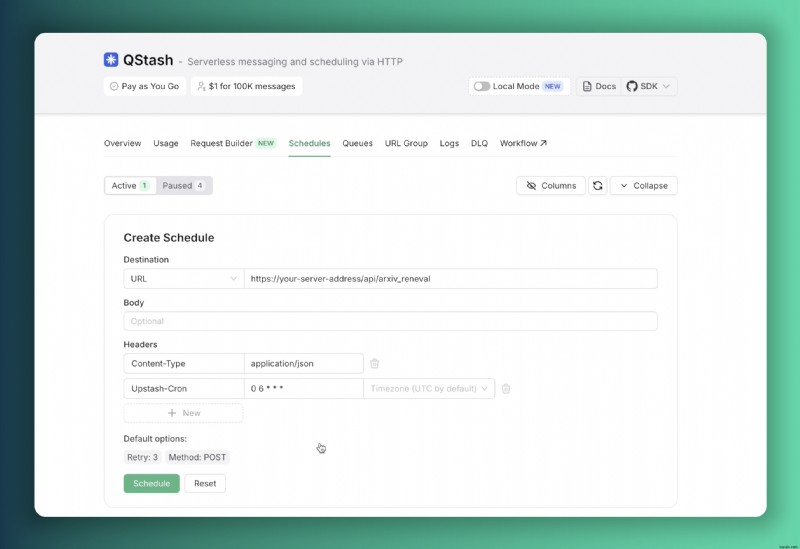
এই সময়সূচী কনফিগারেশনের সাথে, আমাদের সার্ভার প্রতিদিন সকালে স্বয়ংক্রিয় ডেটাবেস আপডেটগুলি সম্পাদন করবে, অবিচ্ছিন্ন ডেটা সতেজতা নিশ্চিত করবে৷
আমাদের QStash উদাহরণের জন্য শংসাপত্রও প্রদান করা উচিত, সমস্ত প্রয়োজনীয় env ভেরিয়েবল উদাহরণ env ফাইলে দেওয়া আছে৷
যে বেশ এটা. আপনি যদি চান, আপনি চেষ্টা এবং কোড সঙ্গে প্রায় খেলা করতে পারেন. শুধু সংগ্রহস্থল কাঁটাচামচ এবং উন্নয়ন শুরু. আপনি এখানে Mastra অংশের ভান্ডারে যেতে পারেন এবং এখানে অন্যান্য রেপোতে যেতে পারেন। তাদের কাঁটা দেওয়ার পরে:
- এগুলিকে আপনার স্থানীয় মেশিনে ক্লোন করুন৷ ৷
- আপনার পরিবেশের ভেরিয়েবলগুলি পূরণ করুন (উদাহরণ
.envফাইল প্রদান করা হয়)। - পৃথক টার্মিনালে উভয় প্রকল্পের জন্য রুট ডিরেক্টরিতে যান।
- নিম্নলিখিত কমান্ড চালান:
npm install
npm run devএখন আপনি http://localhost:3000.
-এ আপনার আবেদন দেখতে পারেনMastra এর সাথে, আপনি এর অন্যান্য টেমপ্লেট যেমন RAG, ওয়ার্কফ্লো এবং নেটওয়ার্ক ব্যবহার করে আরও জটিল জিনিস তৈরি করতে পারেন। মনে হয় মেমরি এবং স্টোরেজ এই সমস্ত উদ্দেশ্যে একটি গুরুত্বপূর্ণ ভূমিকা পালন করে। এখানেই আপস্ট্যাশ জ্বলজ্বল করে।
