
আপনি কি কখনো লক্ষ্য করেছেন কিভাবে সার্চ বক্স আপনার টাইপ করার সাথে সাথে শব্দের পরামর্শ দেয়? দেখা যাচ্ছে, এই পরামর্শগুলির বেশিরভাগই একটি সাধারণ বর্ণানুক্রমিক ক্রমে প্রদর্শিত হয় এবং খুব সহায়ক নয়৷
কিন্তু যদি একটি সার্চ বক্স সময়ের সাথে সাথে আরও স্মার্ট হতে পারে?
লোকেরা আসলে কী ক্লিক করে তা থেকে শেখা এবং প্রথমে সবচেয়ে জনপ্রিয় ফলাফলগুলি দেখায়?
এটি আমরা তৈরি করব:
আমরা দেখব কিভাবে Redis সাজানো সেটগুলি একটি বুদ্ধিমান স্বয়ংসম্পূর্ণ সিস্টেমকে শক্তি দিতে পারে যা ব্যবহারকারীর আচরণ থেকে শেখে এবং সময়ের সাথে সাথে আরও সঠিক (প্রথম জনপ্রিয় ফলাফল দেখায়) হয়ে ওঠে৷
স্মার্ট স্বয়ংসম্পূর্ণ সিস্টেমের ধারণা
একটি মৌলিক অনুসন্ধান বাক্স একটি পদ্ধতি ব্যবহার করবে যা প্রিফিক্স ম্যাচিং নামক একটি ফলাফলকে প্রথমে দেখাবে তা নির্ধারণ করতে।
আপনি টাইপ করার সাথে সাথে এটি A-Z ক্রমে মিল দেখায়। লোকেরা আসলে কোন ফলাফলে সবচেয়ে বেশি ক্লিক করে তা আসলে চিন্তা করে না৷
৷আমরা এটিকে আরও স্মার্ট করতে যাচ্ছি। আমাদের অনুসন্ধান বাক্সটি লোকেরা কী পছন্দ করে তা থেকে শিখবে . যখন লোকেরা একটি অনুসন্ধান ফলাফলে ক্লিক করে, আমরা পরের বার সেই ফলাফলটি প্রথম দেখাব৷
এর অর্থ হল আমাদের অনুসন্ধানটি সময়ের সাথে সাথে আরও ভাল এবং আরও সহায়ক হয়ে ওঠে স্বয়ংক্রিয়ভাবে শীর্ষে সর্বাধিক জনপ্রিয় ফলাফলগুলি দেখিয়ে৷
৷সার্চ অ্যাপ্লিকেশনের জন্য কেন এটি গুরুত্বপূর্ণ
একটি চলচ্চিত্র অনুসন্ধান অ্যাপ্লিকেশন বিবেচনা করুন:যখন ব্যবহারকারীরা "int" টাইপ করে। তারা দেখতে পারে:
- "ইন্টারসেপ্টর"
- "ইন্টারস্টেট 60"
- "ইন্টারস্টেলার"
একটি "প্রথাগত" সিস্টেমে, এগুলি বর্ণানুক্রমিকভাবে প্রদর্শিত হবে। যাইহোক, ব্যবহারকারীরা যদি ধারাবাহিকভাবে "ইন্টারস্টেলার" এ ক্লিক করেন, তাহলে আমরা এটিকে স্বয়ংসম্পূর্ণ পরামর্শের শীর্ষে উন্নীত করতে চাই।
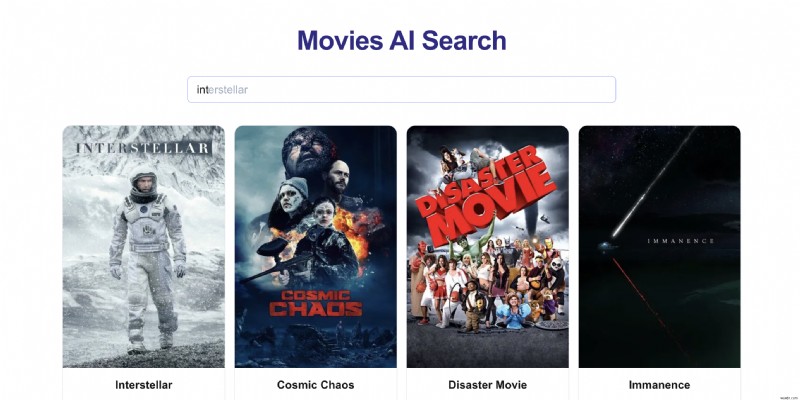
এই স্মার্ট র্যাঙ্কিং সিস্টেমটি এর জন্য সত্যিই ভাল কাজ করে:
- স্ট্রিমিং পরিষেবাগুলি৷ লোকেরা সবচেয়ে বেশি কী দেখছে তা দেখানোর জন্য Netflix বা YouTube-এর মতো
- অনলাইন স্টোর সার্চ করার সময় প্রথমে জনপ্রিয় পণ্য দেখাতে
- সহায়তা কেন্দ্র লোকেদের সবচেয়ে সাধারণ প্রশ্ন দেখাতে
- অনুসন্ধান সহ যেকোনো ওয়েবসাইট বেশির ভাগ মানুষ প্রথমে কী ক্লিক করেন তা দেখাতে
রিডিস সাজানো সেট বোঝা
আসুন বুঝতে পারি কেন Redis সাজানো সেটগুলি একটি স্বয়ংসম্পূর্ণ সিস্টেম তৈরির জন্য দুর্দান্ত৷
একটি রেডিস সাজানো সেট একটি স্মার্ট তালিকার মতো যেখানে:
- প্রতিটি আইটেম অনন্য (একটি সেটের মতো)
- প্রতিটি আইটেমের একটি স্কোর রয়েছে (অর্ডার করার জন্য)
- আইটেমগুলি দ্রুত তাদের স্কোর অনুসারে বাছাই করা যেতে পারে
আমাদের স্বয়ংসম্পূর্ণ সিস্টেমের জন্য, আমরা দুটি সাজানো সেট ব্যবহার করব:
- টেক্সট উপসর্গের সাথে মিলে যাওয়ার জন্য একটি (যেমন "int" মেলে "ইন্টারস্টেলার")
- প্রতিটি পরামর্শ কতটা জনপ্রিয় তা ট্র্যাক করার জন্য আরেকটি
এই দুটি সেট ব্যবহারকারীদের টাইপ হিসাবে সবচেয়ে প্রাসঙ্গিক ফলাফলের পরামর্শ দিতে একসাথে কাজ করে৷
ফাউন্ডেশন:বর্ণানুক্রমিক ক্রম
রেডিস বাছাই করা সেটগুলি বর্ণানুক্রমিক ক্রম বজায় রাখে যখন সমস্ত সদস্যের স্কোর একই থাকে। এটি অনুসন্ধানের পরামর্শ তৈরি করার জন্য উপযুক্ত কারণ এটি আমাদের করতে দেয়:
- সমস্ত উপসর্গ সঞ্চয় করুন একটি একক ডেটা কাঠামোতে অনুসন্ধানযোগ্য পদগুলির
-
ZRANKব্যবহার করুন O(log N) সময়
তে যেকোনো উপসর্গের শুরুর অবস্থান খুঁজে বের করতে -
ZSCANব্যবহার করুন সেই অবস্থান থেকে শুরু হওয়া সমস্ত ম্যাচ দক্ষতার সাথে পুনরুদ্ধার করতে - ব্যবহার করুন
ZMSCOREপ্রতিটি ম্যাচের জনপ্রিয়তা স্কোর পেতে -
ZINCRBYব্যবহার করুন প্রতিটি ম্যাচের জনপ্রিয়তা স্কোর বাড়াতে
এর একটি সহজ উদাহরণ তাকান. যখন আমরা আমাদের সার্চ সিস্টেমে "ইন্টারস্টেলার" মুভি যোগ করি, তখন আমরা এটিকে এভাবে ভেঙে দেই:
- স্কোর:0, সদস্য:"আমি"
- স্কোর:0, সদস্য:"IN"
- স্কোর:0, সদস্য:"INT"
- স্কোর:0, সদস্য:"INTE"
- স্কোর:0, সদস্য:"ইন্টার"
- স্কোর:0, সদস্য:"INTERSTELLAR$Interstellar" (প্রদর্শন বিন্যাস সহ সম্পূর্ণ এন্ট্রি)
দেখুন কিভাবে আমরা $ ব্যবহার করি ডিসপ্লে সংস্করণ থেকে অনুসন্ধান সংস্করণ বিভক্ত করতে? এইভাবে, ব্যবহারকারীরা বড় হাতের বা ছোট হাতের অক্ষর নিয়ে চিন্তা না করেই অনুসন্ধান করতে পারেন, তবে আমরা এখনও সিনেমার শিরোনামটি দেখাই যে এটি কেমন হওয়া উচিত।
আমরা কীভাবে ডেটা সংরক্ষণ করি
আমরা আমাদের স্বয়ংসম্পূর্ণ কাজ করার জন্য দুটি Redis সাজানো সেট ব্যবহার করি:
1. সিনেমার শিরোনামের তালিকা
চলুন movies নামে একটি সাজানো সেটের ট্র্যাক রাখা যাক . এটিকে একটি অভিধানের মতো ভাবুন যা আমাদের দ্রুত চলচ্চিত্রগুলি খুঁজে পেতে সহায়তা করে৷ যখন কেউ "int" টাইপ করে, তখন আমরা সেই অক্ষরগুলি দিয়ে শুরু হওয়া সমস্ত মুভি খুঁজে পেতে পারি৷
"int" এর প্রথম উপস্থিতি ZRANK দ্বারা পাওয়া যাবে এবং তারপর সেই অবস্থান থেকে শুরু করে ওয়াইল্ড কার্ড INT*$* সহ পুরো সিনেমার নাম আনা হবে৷
2. জনপ্রিয় চলচ্চিত্রের তালিকা
চলুন movie-popularity নামে একটি সাজানো সেটেরও নজর রাখি . এটি আমাদের "ট্রেন্ডিং মুভি" তালিকা৷
যখনই কেউ অনুসন্ধান ফলাফলে একটি মুভিতে ক্লিক করে, সেই মুভিটি ZINCRBY ব্যবহার করে তার স্কোর বৃদ্ধি করে আরও জনপ্রিয় হয় . সর্বাধিক ক্লিক করা চলচ্চিত্রগুলি ভবিষ্যতের অনুসন্ধানগুলিতে প্রথমে প্রদর্শিত হয়৷
এটি এমন যে নেটফ্লিক্স আপনাকে ট্রেন্ডিং মুভিগুলি দেখায় - লোকেরা যত বেশি কিছু দেখবে, সুপারিশগুলিতে এটি তত বেশি প্রদর্শিত হবে৷
আমাদের ক্ষেত্রে, INT*$*-এর সঠিক মিল খুঁজে বের করার পর , আমরা movie-popularity এ গিয়ে তাদের স্কোর পরীক্ষা করি সবচেয়ে জনপ্রিয় পেতে।
অ্যালগরিদমিক ফ্লো
graph TD
A[User types 'int'] --> B[ZRANK: Find lexicographic position of 'INT']
B --> C[ZSCAN: Retrieve matches starting from position (movies set)]
C --> D[Filter: Extract complete terms containing '$']
D --> E[ZMSCORE: Get popularity scores for all matches (movie-popularity set)]
E --> F[Rank: Return highest-scored suggestion]
G[User selects suggestion] --> H[ZINCRBY: Increment popularity score]
H --> I[Future searches: Higher scored items rank first]
I --> Aব্যবহারকারীরা অনুসন্ধান এবং পরামর্শগুলিতে ক্লিক করার সাথে সাথে সিস্টেম শিখতে এবং উন্নতি করে। যত বেশি মানুষ এটি ব্যবহার করবে, এটি প্রথমে সবচেয়ে প্রাসঙ্গিক পরামর্শগুলি দেখানোর ক্ষেত্রে তত ভাল হয়৷
৷আসুন স্বয়ংসম্পূর্ণ সিস্টেম তৈরি করি
আসুন দেখি কিভাবে আমরা ধাপে ধাপে এই স্বয়ংসম্পূর্ণ সিস্টেমটি তৈরি করি। আমরা এটি অত্যন্ত সহজ রাখব!
ধাপ 1:মুভির শিরোনাম Redis এ যোগ করা
প্রথমে, আমাদের মুভির শিরোনামগুলিকে Redis-এ যোগ করতে হবে যাতে আমরা সেগুলি পরে অনুসন্ধান করতে পারি। আপনি যেকোনো জায়গা থেকে মুভিগুলির একটি সাধারণ তালিকা দিয়ে শুরু করতে পারেন - হতে পারে আপনার ডাটাবেস বা শুধুমাত্র একটি টেক্সট ফাইল। এখানে আমরা কিভাবে তাদের যোগ করি:
import { Redis } from "@upstash/redis";
const redis = new Redis({
url: process.env.UPSTASH_REDIS_URL!,
token: process.env.UPSTASH_REDIS_TOKEN!,
});
// Example: your list of titles
const titles = [
"Interceptor",
"Interstate 60",
"Interstellar",
// ... more titles
];
async function populateAutocomplete() {
// Insert prefixes and full titles into the 'movies' sorted set
for (const title of titles) {
let term = title.toUpperCase();
let terms = [];
for (let i = 1; i < term.length; i++) {
terms.push({ score: 0, member: term.substring(0, i) });
}
terms.push({ score: 0, member: term });
terms.push({ score: 0, member: term + "$" + title });
await redis.zadd("movies", ...terms);
}
// Insert all titles into the 'movie-popularity' sorted set for popularity tracking
await redis.zadd(
"movie-popularity",
...titles.map((title) => ({
score: 0,
member: title.toUpperCase(),
})),
);
}
populateAutocomplete();আসুন উপরের কোডটি কী করে তা ভেঙে দেওয়া যাক:
-
প্রতিটি সিনেমার শিরোনামের জন্য, আমরা সঞ্চয় করি:
- সকল সম্ভাব্য আংশিক মিল (যেমন "INT", "INTE", "INTER" এর জন্য "Interstellar")
- সম্পূর্ণ শিরোনাম নিজেই
- প্রদর্শনের জন্য একটি বিন্যাসিত সংস্করণ
-
আমরা একটি পৃথক তালিকাও তৈরি করি যা ট্র্যাক করে প্রতিটি সিনেমা কতটা জনপ্রিয়, শূন্য ভিউ থেকে শুরু করে
এটি আমাদের ব্যবহারকারীদের টাইপ করার সময় এবং তারা যা ক্লিক করে তা থেকে শিখতে স্মার্ট পরামর্শগুলি দেখানোর জন্য আমাদের যা দরকার তা দেয়৷
ধাপ 2:সেরা মিল খোঁজা
এর পরে, আমরা মিলগুলি খুঁজে পেতে এই মুভির শিরোনামগুলির মাধ্যমে কীভাবে অনুসন্ধান করি তা দেখব। আমাদের matchQuery ফাংশন সমস্ত ভারী উত্তোলন করে:
export const matchQuery = async (query: string): Promise<string | null> => {
const upperQuery = query.toUpperCase();
// Step 1: Find starting position using lexicographic ordering
let rank = await redis.zrank("movies", upperQuery);
if (rank === null) return null;
// Step 2: Efficiently scan for matches from that position
const scanResult = await redis.zscan("movies", rank, {
match: `${upperQuery}*$*`,
count: 1000,
});
// Step 3: Extract complete entries and get their popularity scores
const completeTitles = scanResult[1].filter(
(el, idx) => idx % 2 === 0 && el.includes("$"),
);
const baseNames = completeTitles.map((title) => title.split("$")[0]);
const scores = await redis.zmscore("movie-popularity", baseNames);
// Step 4: Return the highest-scored (most popular) match
const maxScore = Math.max(...scores);
const bestMatchIndex = scores.indexOf(maxScore);
return completeTitles[bestMatchIndex].split("$")[1];
};ব্যবহারকারীর পছন্দ থেকে শেখা
যখন কেউ একটি চলচ্চিত্রের শিরোনাম নির্বাচন করে, তখন আমরা তার স্কোরে 1 পয়েন্ট যোগ করি। প্রস্তাবনা তালিকায় বেশি পয়েন্ট সহ সিনেমাগুলি বেশি দেখায়৷ এটা যে সহজ!
লোকেরা আসলে কী বেছে নেয় তার ট্র্যাক রাখার মাধ্যমে সিস্টেমটি সময়ের সাথে আরও স্মার্ট হয়ে ওঠে৷
৷const onSubmit = async (title: string) => {
// Handle submit logic here
await redis.zincrby("movie-popularity", 1, title.toUpperCase());
};এটা কতটা দ্রুত?
প্রতিটি অপারেশনে যে সময় লাগে তা ভেঙে এই সমাধানটি কত দ্রুত তা দেখা যাক:
- ZRANK :O(log N) - লগারিদমিক লুকআপ সময়
- ZSCAN :O(log N + M) - যেখানে M হল প্রত্যাবর্তিত উপাদানের সংখ্যা
- ZMSCORE :O(N) - যেখানে N হল মিলিত ফলাফলের সংখ্যা, মোট ডেটাসেটের আকার নয়
- ZINCRBY :O(log N) - লগারিদমিক জটিলতার সাথে পারমাণবিক বৃদ্ধি
আমরা আরো মুভির শিরোনাম যোগ করার সাথে সাথে পারফরম্যান্স ধারাবাহিক থাকে৷
উপসংহার:যা আমরা একসাথে তৈরি করেছি
আপনি এইমাত্র শিখেছেন কিভাবে একটি স্মার্ট সার্চ বক্স তৈরি করতে হয় যা সময়ের সাথে সাথে কোনো AI ছাড়াই আরও ভালো হয়!
আমাদের স্বয়ংসম্পূর্ণ ব্যক্তিরা কী বেছে নেয় তা থেকে শেখে এবং আরও ভাল পরামর্শ দেখানোর জন্য সেই তথ্য ব্যবহার করে৷
এটি দ্রুত, সহজ, এবং যত বেশি মানুষ এটি ব্যবহার করে তত বেশি সহায়ক হয়ে ওঠে৷
৷Redis অপ্টিমাইজেশান কৌশল সম্পর্কে কথা বলতে চান বা আপনার নিজস্ব বাস্তবায়ন শেয়ার করতে চান? ডিসকর্ডে আমাদের সাথে যোগ দিন!
