
RedisTimeSeries হল একটি Redis মডিউল যা Redis-এ নেটিভ টাইম-সিরিজ ডেটা স্ট্রাকচার নিয়ে আসে। টাইম-সিরিজ সলিউশন, যা আগে সাজানো সেটের (বা রেডিস স্ট্রীম) উপরে তৈরি করা হয়েছিল, RedisTimeSeries বৈশিষ্ট্যগুলি যেমন উচ্চ-ভলিউম সন্নিবেশ, লো-লেটেন্সি রিড, নমনীয় ক্যোয়ারী ভাষা, ডাউন-স্যাম্পলিং এবং আরও অনেক কিছু থেকে উপকৃত হতে পারে!
সাধারণভাবে বলতে গেলে, সময়-সিরিজের ডেটা (তুলনামূলকভাবে) সহজ। এটি বলার পরে, আমাদের অন্যান্য বৈশিষ্ট্যগুলিকেও ফ্যাক্টর করতে হবে:
- ডেটা বেগ:যেমন প্রতি সেকেন্ডে হাজার হাজার ডিভাইস থেকে শত শত মেট্রিক্স চিন্তা করুন
- ভলিউম (বিগ ডেটা):কয়েক মাস (এমনকি বছর) ধরে ডেটা জমা হওয়ার কথা ভাবুন
সুতরাং, RedisTimeSeries এর মতো ডাটাবেসগুলি সামগ্রিক সমাধানের একটি অংশ মাত্র। কিভাবে সংগ্রহ করা যায় সে সম্পর্কেও আপনাকে ভাবতে হবে (ইনজেস্ট), প্রক্রিয়া, এবং পাঠান আপনার সমস্ত ডেটা RedisTimeSeries-এ। আপনার যা প্রয়োজন তা হল একটি স্কেলযোগ্য ডেটা পাইপলাইন যা প্রযোজক এবং ভোক্তাদের দ্বিগুণ করার জন্য বাফার হিসাবে কাজ করতে পারে।
সেখানেই অ্যাপাচি কাফকা আসে! মূল ব্রোকার ছাড়াও, এর উপাদানগুলির একটি সমৃদ্ধ ইকোসিস্টেম রয়েছে, যার মধ্যে রয়েছে কাফকা কানেক্ট (যা এই ব্লগ পোস্টে উপস্থাপিত সমাধান আর্কিটেকচারের একটি অংশ), একাধিক ভাষায় ক্লায়েন্ট লাইব্রেরি, কাফকা স্ট্রিম, মিরর মেকার, ইত্যাদি। 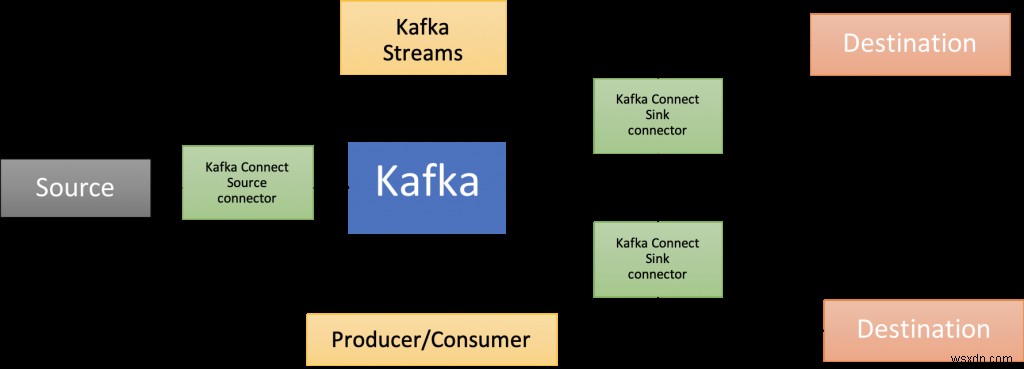
এই ব্লগ পোস্টটি সময়-সিরিজ ডেটা বিশ্লেষণের জন্য অ্যাপাচি কাফকার সাথে RedisTimeSeries কীভাবে ব্যবহার করতে হয় তার একটি বাস্তব উদাহরণ প্রদান করে৷
কোডটি এই GitHub রেপোতে পাওয়া যায় https://github.com/abhirockzz/redis-timeseries-kafka
প্রথমে ব্যবহারের ক্ষেত্রে অন্বেষণ করে শুরু করা যাক। দয়া করে মনে রাখবেন যে এটি ব্লগ পোস্টের উদ্দেশ্যে সহজ রাখা হয়েছে এবং তারপর পরবর্তী বিভাগে আরও ব্যাখ্যা করা হয়েছে৷
পরিস্থিতি:ডিভাইস পর্যবেক্ষণ
কল্পনা করুন যে অনেকগুলি অবস্থান রয়েছে, তাদের প্রত্যেকটিতে একাধিক ডিভাইস রয়েছে এবং আপনাকে ডিভাইসের মেট্রিক্স নিরীক্ষণ করার দায়িত্ব দেওয়া হয়েছে—আপাতত আমরা তাপমাত্রা এবং চাপ বিবেচনা করব। এই মেট্রিকগুলি RedisTimeSeries-এ সংরক্ষণ করা হবে (অবশ্যই!) এবং কীগুলির জন্য নিম্নলিখিত নামকরণের রীতি ব্যবহার করুন—
TS.ADD কমান্ড ব্যবহার করে আপনি কীভাবে ডেটা পয়েন্ট যোগ করবেন সে সম্পর্কে ধারণা দেওয়ার জন্য এখানে কয়েকটি উদাহরণ দেওয়া হল:
# লেবেল সহ অবস্থান 3-এ ডিভাইস 2-এর জন্য তাপমাত্রা:
TS.ADD temp:3:2 * 20 LABELS metric temp location 3 device 2
অবস্থান 3-এ ডিভাইস 2-এর জন্য # চাপ:
TS.ADD pressure:3:2 * 60 LABELS metric pressure location 3 device 2
সমাধান আর্কিটেকচার
উচ্চ স্তরে সমাধানটি কেমন দেখায় তা এখানে:
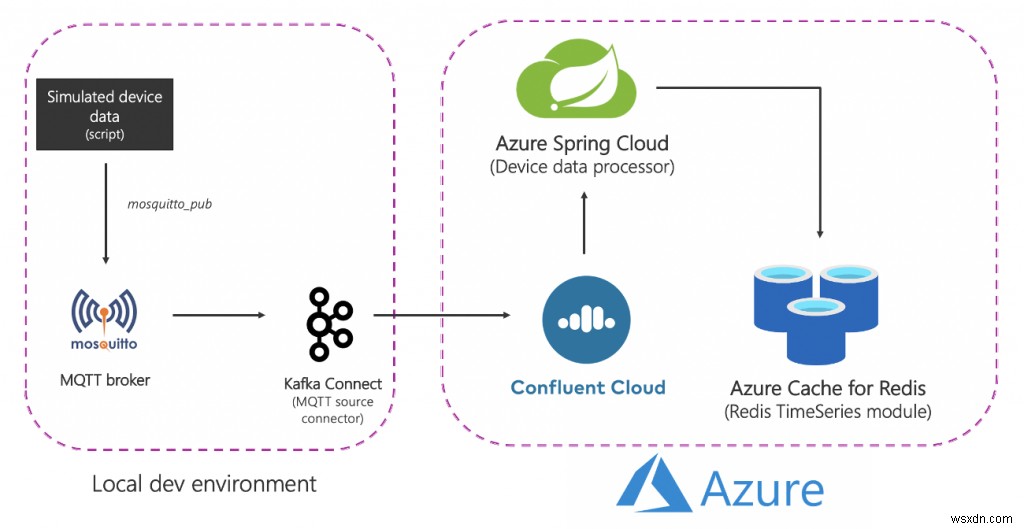
আসুন এটি ভেঙে ফেলি:
উৎস (স্থানীয়) উপাদান
- MQTT ব্রোকার (মশা): MQTT আইওটি ব্যবহারের ক্ষেত্রে একটি ডি-ফ্যাক্টো প্রোটোকল। আমরা যে দৃশ্যকল্পটি ব্যবহার করব তা হল IoT এবং টাইম সিরিজের সংমিশ্রণ - এই বিষয়ে পরে আরও।
- কাফকা কানেক্ট:MQTT সোর্স সংযোগকারী MQTT ব্রোকার থেকে কাফকা ক্লাস্টারে ডেটা স্থানান্তর করতে ব্যবহৃত হয়।
অ্যাজুর পরিষেবাগুলি
- রেডিস এন্টারপ্রাইজ টিয়ারের জন্য আজুর ক্যাশে:এন্টারপ্রাইজ টিয়ারগুলি রেডিস এন্টারপ্রাইজের উপর ভিত্তি করে তৈরি, রেডিস থেকে রেডিসের একটি বাণিজ্যিক রূপ। RedisTimeSeries-এর পাশাপাশি, এন্টারপ্রাইজ টিয়ারও RediSearch এবং RedisBloom সমর্থন করে। গ্রাহকদের এন্টারপ্রাইজ স্তরগুলির জন্য লাইসেন্স অধিগ্রহণ সম্পর্কে চিন্তা করতে হবে না। Redis-এর জন্য Azure Cache এই প্রক্রিয়াটিকে সহজতর করবে যেখানে, গ্রাহকরা Azure Marketplace অফারের মাধ্যমে এই সফ্টওয়্যারটির লাইসেন্স পেতে এবং এর জন্য অর্থ প্রদান করতে পারেন৷
- আজুরে কনফ্লুয়েন্ট ক্লাউড:একটি সম্পূর্ণরূপে পরিচালিত অফার যা অ্যাপাচি কাফকাকে একটি পরিষেবা হিসাবে প্রদান করে, Azure থেকে কনফ্লুয়েন্ট ক্লাউড পর্যন্ত একটি সমন্বিত প্রভিশনিং স্তরকে ধন্যবাদ৷ এটি ক্রস-প্ল্যাটফর্ম পরিচালনার ভার কমায় এবং Azure পরিকাঠামোতে কনফ্লুয়েন্ট ক্লাউড ব্যবহার করার জন্য একটি একত্রিত অভিজ্ঞতা প্রদান করে, যার ফলে আপনি সহজেই আপনার Azure অ্যাপ্লিকেশনের সাথে কনফ্লুয়েন্ট ক্লাউড সংহত করতে পারবেন।
- Azure স্প্রিং ক্লাউড:Azure-এ স্প্রিং বুট মাইক্রোসার্ভিস স্থাপন করা Azure স্প্রিং ক্লাউডের জন্য সহজ ধন্যবাদ৷ Azure স্প্রিং ক্লাউড অবকাঠামোগত উদ্বেগ দূর করে, কনফিগারেশন ব্যবস্থাপনা, পরিষেবা আবিষ্কার, CI/CD ইন্টিগ্রেশন, নীল-সবুজ স্থাপনা এবং আরও অনেক কিছু প্রদান করে। পরিষেবাটি সমস্ত ভারী উত্তোলন করে যাতে বিকাশকারীরা তাদের কোডে ফোকাস করতে পারে৷ ৷
অনুগ্রহ করে মনে রাখবেন যে কিছু পরিষেবা স্থানীয়ভাবে হোস্ট করা হয়েছিল শুধুমাত্র জিনিসগুলি সহজ রাখার জন্য। প্রোডাকশন গ্রেড স্থাপনায় আপনি এগুলিকে Azure-এও চালাতে চাইবেন। উদাহরণস্বরূপ আপনি Azure Kubernetes পরিষেবাতে MQTT সংযোগকারীর সাথে কাফকা কানেক্ট ক্লাস্টার পরিচালনা করতে পারেন।
সংক্ষেপে, এখানে শেষ থেকে শেষ প্রবাহ:
- একটি স্ক্রিপ্ট সিমুলেটেড ডিভাইস ডেটা তৈরি করে যা স্থানীয় MQTT ব্রোকারকে পাঠানো হয়।
- এই ডেটা MQTT কাফকা কানেক্ট সোর্স কানেক্টর দ্বারা তোলা হয় এবং Azure-এ চলমান কনফ্লুয়েন্ট ক্লাউড কাফকা ক্লাস্টারের একটি বিষয়ে পাঠানো হয়।
- এটি Azure স্প্রিং ক্লাউডে হোস্ট করা স্প্রিং বুট অ্যাপ্লিকেশন দ্বারা আরও প্রক্রিয়া করা হয়, যা পরে এটিকে রেডিস উদাহরণের জন্য Azure ক্যাশে টিকে থাকে৷
এটি ব্যবহারিক জিনিস দিয়ে শুরু করার সময়! তার আগে, নিশ্চিত করুন যে আপনার কাছে নিম্নলিখিতগুলি আছে৷
৷পূর্বশর্ত:
- একটি Azure অ্যাকাউন্ট—আপনি এখানে বিনামূল্যে একটি পেতে পারেন
- Azure CLI ইনস্টল করুন
- জেডিকে 11 যেমন OpenJDK
- Maven এবং Git-এর একটি সাম্প্রতিক সংস্করণ
পরিকাঠামোর উপাদানগুলি সেট আপ করুন
রেডিস (এন্টারপ্রাইজ টিয়ার) এর জন্য Azure ক্যাশের বিধান করতে ডকুমেন্টেশন অনুসরণ করুন যা RedisTimeSeries মডিউলের সাথে আসে।
Azure মার্কেটপ্লেসে কনফ্লুয়েন্ট ক্লাউড ক্লাস্টারের ব্যবস্থা করুন। এছাড়াও একটি কাফকা বিষয় তৈরি করুন (mqtt.device-stats) and create credentials (API key and secret) that you will use later on to connect to your cluster securely.

আপনি Azure পোর্টাল ব্যবহার করে Azure স্প্রিং ক্লাউডের একটি উদাহরণ প্রদান করতে পারেন বা Azure CLI ব্যবহার করতে পারেন:
az spring-cloud create -n <name of Azure Spring Cloud service> -g <resource group name> -l <enter location e.g southeastasia>
এগিয়ে যাওয়ার আগে, GitHub রেপো ক্লোন করা নিশ্চিত করুন:
git clone https://github.com/abhirockzz/redis-timeseries-kafka
cd redis-timeseries-kafkaস্থানীয় পরিষেবাগুলি সেটআপ করুন৷
উপাদান অন্তর্ভুক্ত:
- Mosquitto MQTT দালাল
- MQTT উৎস সংযোগকারীর সাথে কাফকা সংযোগ করুন
- ড্যাশবোর্ডে টাইম-সিরিজ ডেটা ট্র্যাক করার জন্য গ্রাফানা
MQTT ব্রোকার
আমি স্থানীয়ভাবে Mac-এ মশার দালাল ইনস্টল করে শুরু করেছি।
brew install mosquitto
brew services start mosquittoআপনি আপনার OS এর সাথে সম্পর্কিত পদক্ষেপগুলি অনুসরণ করতে পারেন বা নির্দ্বিধায় এই ডকার চিত্রটি ব্যবহার করতে পারেন৷
৷গ্রাফনা
আমি Mac-এ স্থানীয়ভাবে Grafana ইনস্টল এবং শুরু করেছি৷
brew install grafana
brew services start grafanaআপনি আপনার OS এর জন্য একই কাজ করতে পারেন বা এই ডকার ইমেজটি ব্যবহার করতে দ্বিধা বোধ করতে পারেন।
docker run -d -p 3000:3000 --name=grafana -e "GF_INSTALL_PLUGINS=redis-datasource" grafana/grafanaকাফকা সংযোগ
আপনি এইমাত্র ক্লোন করা রেপোতে connect-distributed.properties ফাইলটি খুঁজে পেতে সক্ষম হবেন। বৈশিষ্ট্যগুলির জন্য মান প্রতিস্থাপন করুন যেমন bootstrap.servers, sasl.jaas.config ইত্যাদি।
প্রথমে, স্থানীয়ভাবে অ্যাপাচি কাফকা ডাউনলোড এবং আনজিপ করুন।
একটি স্থানীয় কাফকা সংযোগ ক্লাস্টার শুরু করুন:
export KAFKA_INSTALL_DIR=<kafka installation directory e.g. /home/foo/kafka_2.12-2.5.0>
$KAFKA_INSTALL_DIR/bin/connect-distributed.sh connect-distributed.propertiesMQTT সোর্স সংযোগকারী ম্যানুয়ালি ইনস্টল করতে:
- এই লিঙ্ক থেকে সংযোগকারী/প্লাগইন ZIP ফাইলটি ডাউনলোড করুন, এবং,
- কানেক্ট ওয়ার্কারের plugin.path কনফিগারেশন বৈশিষ্ট্যে তালিকাভুক্ত ডিরেক্টরিগুলির মধ্যে এটিকে এক্সট্র্যাক্ট করুন
যদি আপনি স্থানীয়ভাবে কনফ্লুয়েন্ট প্ল্যাটফর্ম ব্যবহার করেন, তাহলে কেবল কনফ্লুয়েন্ট হাব CLI ব্যবহার করুন: confluent-hub install confluentinc/kafka-connect-mqtt:latest
MQTT উৎস সংযোগকারী উদাহরণ তৈরি করুন
mqtt-source-config.json ফাইলটি চেক করতে ভুলবেন না। নিশ্চিত করুন যে আপনি kafka.topic-এর জন্য সঠিক বিষয়ের নাম লিখছেন এবং mqtt.topics অপরিবর্তিত রেখেছেন।
curl -X POST -H 'Content-Type: application/json'
http://localhost:8083/connectors -d @mqtt-source-config.json
# wait for a minute before checking the connector status
curl http://localhost:8083/connectors/mqtt-source/statusডিভাইস ডেটা প্রসেসর অ্যাপ্লিকেশন স্থাপন করুন
GitHub রেপোতে আপনি এইমাত্র ক্লোন করেছেন, consumer/src/resources folder and replace the values for:
- Redis হোস্ট, পোর্ট এবং প্রাথমিক অ্যাক্সেস কী-এর জন্য Azure ক্যাশে
- Azure API কী এবং গোপনে কনফ্লুয়েন্ট ক্লাউড
অ্যাপ্লিকেশন JAR ফাইল তৈরি করুন:
cd consumer
export JAVA_HOME=<enter absolute path e.g. /Library/Java/JavaVirtualMachines/zulu-11.jdk/Contents/Home>
mvn clean packageএকটি Azure স্প্রিং ক্লাউড অ্যাপ্লিকেশন তৈরি করুন এবং এতে JAR ফাইল স্থাপন করুন:
az spring-cloud app create -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --runtime-version Java_11
az spring-cloud app deploy -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group> --jar-path target/device-data-processor-0.0.1-SNAPSHOT.jarসিমুলেটেড ডিভাইস ডেটা জেনারেটর শুরু করুন
আপনি এইমাত্র ক্লোন করা GitHub রেপোতে স্ক্রিপ্টটি ব্যবহার করতে পারেন:
./gen-timeseries-data.shদ্রষ্টব্য—এটি যা করে তা হল ডেটা পাঠাতে mosquitto_pub CLI কমান্ড ব্যবহার করে।
ডিভাইস-পরিসংখ্যান MQTT বিষয়ে ডেটা পাঠানো হয় (এটি না কাফকা বিষয়)। আপনি CLI গ্রাহক ব্যবহার করে দুবার চেক করতে পারেন:
mosquitto_sub -h localhost -t device-statsকনফ্লুয়েন্ট ক্লাউড পোর্টালে কাফকা বিষয় দেখুন। Azure Spring Cloud:
-এ আপনার ডিভাইস ডেটা প্রসেসর অ্যাপের লগগুলিও পরীক্ষা করা উচিতaz spring-cloud app logs -f -n device-data-processor -s <name of Azure Spring Cloud instance> -g <name of resource group>Grafana ড্যাশবোর্ড উপভোগ করুন!৷
লোকালহোস্ট:3000 এ Grafana UI এ ব্রাউজ করুন।
Grafana-এর জন্য Redis ডেটা সোর্স প্লাগইন Redis-এর জন্য Azure ক্যাশে সহ যেকোনো Redis ডাটাবেসের সাথে কাজ করে। একটি ডেটা উত্স কনফিগার করতে এই ব্লগ পোস্টে নির্দেশাবলী অনুসরণ করুন৷
৷আপনার ক্লোন করা গিটহাব রেপোতে গ্রাফানা_ড্যাশবোর্ড ফোল্ডারে ড্যাশবোর্ডগুলি আমদানি করুন (ড্যাশবোর্ডগুলি কীভাবে আমদানি করতে হয় সে সম্পর্কে আপনার সহায়তার প্রয়োজন হলে গ্রাফানা ডকুমেন্টেশন পড়ুন)।
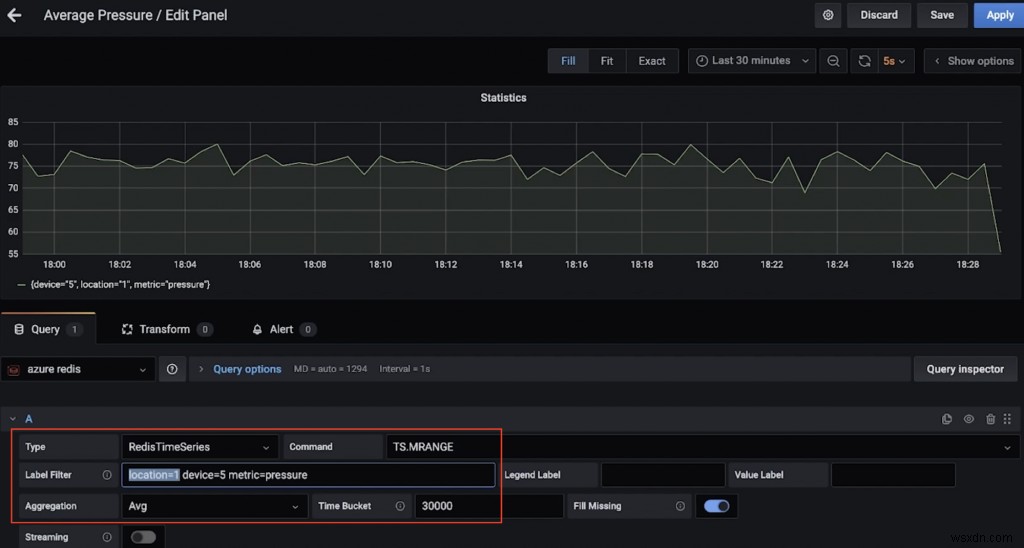
উদাহরণস্বরূপ, এখানে একটি ড্যাশবোর্ড রয়েছে যা অবস্থান 1 এ ডিভাইস 5 এর জন্য গড় চাপ (30 সেকেন্ডের বেশি) দেখায় (TS.MRANGE ব্যবহার করে)।
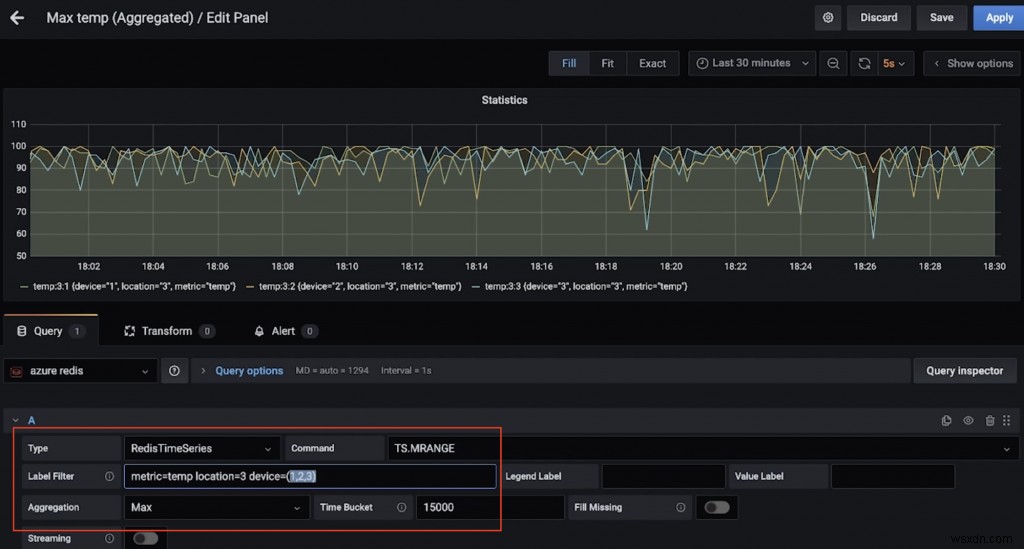
এখানে আরেকটি ড্যাশবোর্ড রয়েছে যা অবস্থান 3-এ একাধিক ডিভাইসের জন্য সর্বোচ্চ তাপমাত্রা (15 সেকেন্ডের বেশি) দেখায় (আবারও, TS.MRANGE কে ধন্যবাদ)।
তাহলে, আপনি কিছু RedisTimeSeries কমান্ড চালাতে চান?
redis-cli-কে ক্র্যাঙ্ক করুন এবং Redis উদাহরণের জন্য Azure ক্যাশে সংযোগ করুন:
redis-cli -h <azure redis hostname e.g. myredis.southeastasia.redisenterprise.cache.azure.net> -p 10000 -a <azure redis access key> --tlsসহজ প্রশ্ন দিয়ে শুরু করুন:
# pressure in device 5 for location 1
TS.GET pressure:1:5
# temperature in device 5 for location 4
TS.GET temp:4:5অবস্থান অনুসারে ফিল্টার করুন এবং সব -এর জন্য তাপমাত্রা এবং চাপ পান ডিভাইস:
TS.MGET WITHLABELS FILTER location=3একটি নির্দিষ্ট সময়সীমার মধ্যে এক বা একাধিক স্থানে সমস্ত ডিভাইসের জন্য তাপমাত্রা এবং চাপ বের করুন:
TS.MRANGE - + WITHLABELS FILTER location=3
TS.MRANGE - + WITHLABELS FILTER location=(3,5)– + শুরু থেকে সর্বশেষ টাইমস্ট্যাম্প পর্যন্ত সবকিছু বোঝায়, তবে আপনি আরও নির্দিষ্ট হতে পারেন।
MRANGE is what we needed! We can also filter by a specific device in a location and further drill down by either temperature or pressure:
TS.MRANGE - + WITHLABELS FILTER location=3 device=2
TS.MRANGE - + WITHLABELS FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS FILTER location=3 device=2 metric=tempএই সব একত্রিত করা যেতে পারে.
# all the temp data points are not useful. how about an average (or max) instead of every temp data points?
TS.MRANGE - + WITHLABELS AGGREGATION avg 10000 FILTER location=3 metric=temp
TS.MRANGE - + WITHLABELS AGGREGATION max 10000 FILTER location=3 metric=tempএই একত্রীকরণ করার জন্য একটি নিয়ম তৈরি করা এবং এটি একটি ভিন্ন সময়ের সিরিজে সংরক্ষণ করাও সম্ভব৷
একবার আপনি হয়ে গেলে, অবাঞ্ছিত খরচ এড়াতে সম্পদ মুছে ফেলতে ভুলবেন না।
সম্পদ মুছুন
- কনফ্লুয়েন্ট ক্লাউড ক্লাস্টার মুছে ফেলার জন্য ডকুমেন্টেশনের ধাপগুলি অনুসরণ করুন—আপনার যা প্রয়োজন তা হল কনফ্লুয়েন্ট প্রতিষ্ঠানটি মুছে ফেলা।
- একইভাবে, রেডিস ইনস্ট্যান্সের জন্যও আপনার Azure ক্যাশে মুছে ফেলা উচিত।
আপনার স্থানীয় মেশিনে:
- কাফকা সংযোগ ক্লাস্টার বন্ধ করুন
- মশার দালাল বন্ধ করুন (যেমন ব্রু সার্ভিস মশারি বন্ধ করুন)
- গ্রাফানা পরিষেবা বন্ধ করুন (যেমন ব্রু পরিষেবাগুলি গ্রাফানা বন্ধ করুন)
আমরা রেডিস এবং কাফকা ব্যবহার করে টাইম-সিরিজ ডেটা গ্রহণ, প্রক্রিয়া এবং অনুসন্ধান করার জন্য একটি ডেটা পাইপলাইন অন্বেষণ করেছি। আপনি যখন পরবর্তী পদক্ষেপগুলি সম্পর্কে চিন্তা করেন এবং একটি প্রোডাকশন গ্রেড সমাধানের দিকে যান, তখন আপনার আরও কিছু বিষয় বিবেচনা করা উচিত৷
অতিরিক্ত বিবেচনা
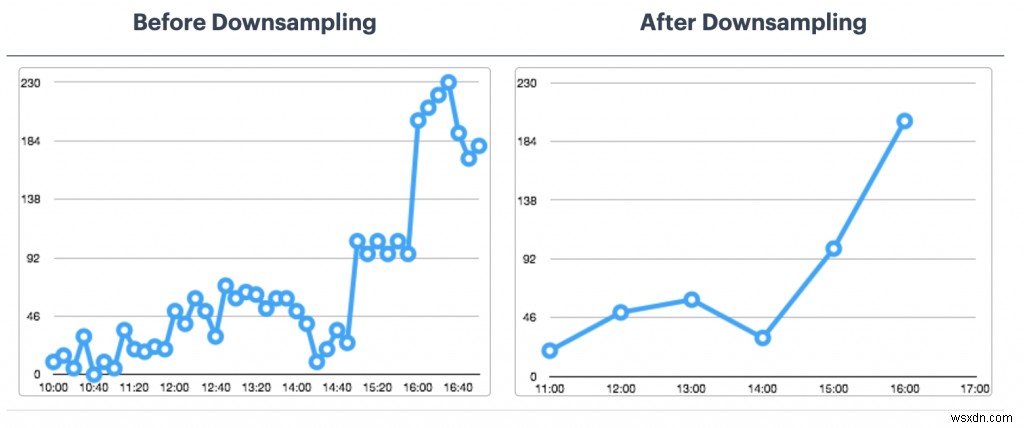
RedisTimeSeries অপ্টিমাইজ করা
- ধারণ নীতি:আপনার টাইম-সিরিজ ডেটা পয়েন্টগুলি করবেন না থেকে এটি সম্পর্কে চিন্তা করুন ডিফল্টরূপে ছাঁটা বা মুছে ফেলুন৷
- ডাউন-স্যাম্পলিং এবং একত্রিতকরণের নিয়ম:আপনি চিরকালের জন্য ডেটা সঞ্চয় করতে চান না, তাই না? এটির যত্ন নেওয়ার জন্য উপযুক্ত নিয়মগুলি কনফিগার করা নিশ্চিত করুন (যেমন TS.CREATERULE temp:1:2 temp:avg:30 AGGREGATION avg 30000)।
- ডুপ্লিকেট ডেটা নীতি:আপনি কীভাবে নকল নমুনাগুলি পরিচালনা করতে চান? নিশ্চিত করুন যে ডিফল্ট নীতি (ব্লক) আসলেই আপনার যা প্রয়োজন। যদি না হয়, অন্যান্য বিকল্প বিবেচনা করুন।
এটি একটি সম্পূর্ণ তালিকা নয়। অন্যান্য কনফিগারেশন বিকল্পের জন্য, অনুগ্রহ করে RedisTimeSeries ডকুমেন্টেশন পড়ুন
দীর্ঘমেয়াদী ডেটা ধারণ সম্পর্কে কি?
সময় সিরিজ সহ ডেটা মূল্যবান! আপনি এটিকে আরও প্রক্রিয়া করতে চাইতে পারেন (যেমন অন্তর্দৃষ্টি, ভবিষ্যদ্বাণীমূলক রক্ষণাবেক্ষণ, ইত্যাদি বের করতে মেশিন লার্নিং চালান)। এটি সম্ভব হওয়ার জন্য, আপনাকে এই ডেটা দীর্ঘ সময়ের জন্য ধরে রাখতে হবে এবং এটি সাশ্রয়ী এবং দক্ষ হওয়ার জন্য, আপনি একটি স্কেলযোগ্য অবজেক্ট স্টোরেজ পরিষেবা ব্যবহার করতে চান যেমন Azure ডেটা লেক স্টোরেজ জেন 2 (ADLS Gen2) .
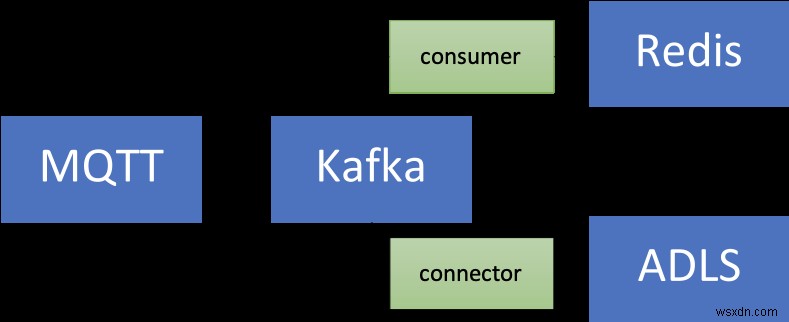
যে জন্য একটি সংযোগকারী আছে! আপনি কনফ্লুয়েন্ট ক্লাউডের জন্য সম্পূর্ণ-পরিচালিত Azure ডেটা লেক স্টোরেজ Gen2 সিঙ্ক সংযোগকারী ব্যবহার করে ADLS-এ ডেটা প্রক্রিয়া ও সংরক্ষণ করে এবং তারপর Azure Synapse অ্যানালিটিক্স বা Azure Databricks ব্যবহার করে মেশিন লার্নিং চালাতে পারেন।
মাপযোগ্যতা
আপনার টাইম-সিরিজ ডেটা ভলিউম শুধুমাত্র এক দিকে যেতে পারে-উপরে! আপনার সমাধান মাপযোগ্য হওয়ার জন্য এটি গুরুত্বপূর্ণ:
- মূল অবকাঠামো:পরিচালিত পরিষেবাগুলি দলগুলিকে অবকাঠামো সেট আপ এবং বজায় রাখার পরিবর্তে সমাধানের দিকে মনোনিবেশ করার অনুমতি দেয়, বিশেষত যখন এটি ডাটাবেস এবং রেডিস এবং কাফকার মতো স্ট্রিমিং প্ল্যাটফর্মের মতো জটিল বিতরণ সিস্টেমগুলির ক্ষেত্রে আসে৷
- কাফকা কানেক্ট:যতদূর ডেটা পাইপলাইন সম্পর্কিত, আপনি ভাল হাতে আছেন যেহেতু কাফকা কানেক্ট প্ল্যাটফর্মটি সহজাতভাবে রাষ্ট্রহীন এবং অনুভূমিকভাবে স্কেলযোগ্য। আপনি কীভাবে আপনার কাফকা কানেক্ট কর্মী ক্লাস্টারগুলিকে স্থপতি এবং আকার দিতে চান তার পরিপ্রেক্ষিতে আপনার কাছে অনেকগুলি বিকল্প রয়েছে৷
- কাস্টম অ্যাপ্লিকেশন:এই সমাধানের ক্ষেত্রে যেমন ছিল, আমরা কাফকা বিষয়গুলিতে ডেটা প্রক্রিয়া করার জন্য একটি কাস্টম অ্যাপ্লিকেশন তৈরি করেছি। ভাগ্যক্রমে, একই স্কেলেবিলিটি বৈশিষ্ট্যগুলি তাদের ক্ষেত্রেও প্রযোজ্য। অনুভূমিক স্কেলের পরিপ্রেক্ষিতে, এটি শুধুমাত্র আপনার কাছে থাকা কাফকা বিষয়ের পার্টিশনের সংখ্যা দ্বারা সীমাবদ্ধ৷
একীকরণ :এটা শুধু গ্রাফনা নয়! RedisTimeSeries এছাড়াও Prometheus এবং Telegraf এর সাথে একীভূত হয়। যাইহোক, এই ব্লগ পোস্টটি লেখার সময় কোন কাফকা সংযোগকারী নেই—এটি একটি দুর্দান্ত অ্যাড-অন হবে!
উপসংহার

অবশ্যই, আপনি সময়-সিরিজ কাজের চাপ সহ (প্রায়) সবকিছুর জন্য রেডিস ব্যবহার করতে পারেন! ডেটা পাইপলাইনের জন্য শেষ থেকে শেষ আর্কিটেকচার এবং টাইম-সিরিজ ডেটা সোর্স থেকে রেডিস এবং তার পরেও ইন্টিগ্রেশন সম্পর্কে চিন্তা করতে ভুলবেন না।
