
RediSearch 2.0-এর উন্নয়নে প্রথম মাইলফলক প্রকাশের ঘোষণা দিতে পেরে আমরা আনন্দিত। RediSearch হল একটি রিয়েল-টাইম সার্চ ইঞ্জিন যা আপনাকে বিভিন্ন জটিল প্রশ্নের উত্তর দিতে আপনার Redis ডেটা জিজ্ঞাসা করতে দেয়।
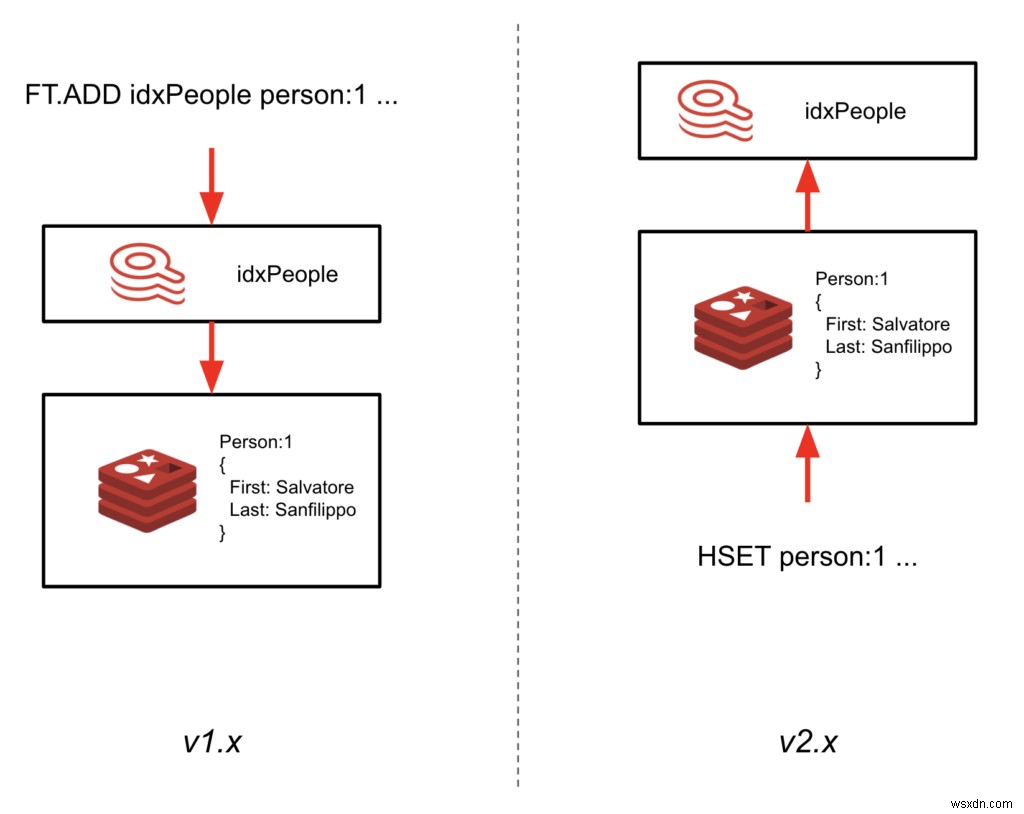
এই মাইলফলক, ডাব 2.0-M01, সূচকগুলিকে ডেটার সাথে সিঙ্কে রাখার পদ্ধতির পুনঃস্থাপত্য চিহ্নিত করে৷ সূচকের মাধ্যমে ডেটা লেখার পরিবর্তে (FT.ADD ব্যবহার করে কমান্ড), RediSearch এখন হ্যাশে লেখা ডেটা অনুসরণ করবে এবং স্বয়ংক্রিয়ভাবে এটিকে সূচী করবে।
এখানে বড় সুবিধা হল আপনি এখন আপনার বিদ্যমান Redis উদাহরণে RediSearch যোগ করতে পারেন এবং আপনার অ্যাপ্লিকেশন কোড আপডেট না করেই একটি গৌণ সূচক তৈরি করতে পারেন। এটি আপনাকে অবিলম্বে RediSearch মডিউল লোড করে এবং স্কিমা সংজ্ঞায়িত করে আপনার বিদ্যমান ডেটাতে RediSearch ব্যবহার শুরু করতে দেয়। RediSearch 2.0-এর সাধারণ প্রাপ্যতা এই শরতে প্রত্যাশিত৷
(দ্রষ্টব্য: এই নতুন বৈশিষ্ট্যটি API-তে কিছু পরিবর্তন এনেছে (নীচে তালিকাভুক্ত)। আমরা যতটা সম্ভব পশ্চাদপদ সামঞ্জস্য বজায় রাখার চেষ্টা করি, কিন্তু এই ক্ষেত্রে এটি সম্ভব হয়নি। আমরা গ্রাহকদের প্রতিক্রিয়া সংগ্রহ করার সাথে সাথে সামঞ্জস্য এবং সংশোধন করার পরিকল্পনা করছি।)
API পরিবর্তনগুলি৷
উপরে উল্লিখিত হিসাবে, এই RediSearch 2.0 মাইলস্টোনটিতে API-তে বেশ কিছু পরিবর্তন রয়েছে:
- সূচকটি আর মূল স্থানে থাকে না। আপনি যদি ডাটাবেসের মধ্যে সূচী তালিকার জন্য index কী (idx:
) ব্যবহার করেন, উদাহরণস্বরূপ, এটি আর কাজ করবে না। যাইহোক, আমরা একটি কমান্ড চালু করেছি FT._LIST ডাটাবেসের সমস্ত সূচক ফেরত দিতে। - সূচীগুলি অবশ্যই একটি উপসর্গ/ফিল্টার দিয়ে তৈরি করতে হবে৷ এগুলি উল্লেখ করে যে কোন নথিগুলি RediSearch দ্বারা স্বয়ংক্রিয়ভাবে সূচিত হবে৷ আপনি একটি সাধারণ উপসর্গ এবং/অথবা একটি জটিল ফিল্টার অভিব্যক্তি নির্দিষ্ট করতে পারেন।
- আপগ্রেড করা সম্ভব নয়। আপনার যদি RediSearch এর একটি পুরানো সংস্করণের সাথে একটি RDB তৈরি করা থাকে তবে RediSearch 2.0 এটি পড়তে সক্ষম হবে না। বর্তমানে, আপনাকে সম্পূর্ণ ডেটা সেট পুনরায় সূচী করতে হবে। তবে, আমরা GA রিলিজের জন্য একটি আপগ্রেড প্রক্রিয়া নিয়ে কাজ করছি৷
- এটি শুধুমাত্র Redis 6 এবং তার উপরে কাজ করে৷৷
- FT কমান্ডগুলিকে তাদের Redis-সমতুল্য কমান্ডে ম্যাপ করা হয়েছে। এটি বিদ্যমান অ্যাপ্লিকেশনগুলিকে এখনও RediSearch 2.0 এর সাথে কাজ করার অনুমতি দেয়৷ ম্যাপিংগুলি নিম্নরূপ:
- FT.ADD => HSET
- FT.DEL => DEL (ডিফল্টরূপে ডিডি)
- FT.GET => <চিহ্ন>HGETALL
- FT.MGET => <চিহ্ন>HGETALL
- উল্টানো সূচক নিজেই আর আরডিবিতে সংরক্ষিত হয় না . এর মানে এই নয় যে স্থিরতা সমর্থিত নয়। RediSearch RDB-তে সূচক সংজ্ঞা সংরক্ষণ করে এবং Redis শুরু হওয়ার পরে পটভূমিতে ডেটা সূচী করে। আপনি FT.INFO ব্যবহার করে ইন্ডেক্সিং স্ট্যাটাস চেক করে রিইন্ডেক্সিং শেষ হলে জানতে পারবেন আদেশ।
নতুন API
API এর সবচেয়ে বড় আপডেট হল কিভাবে সূচক তৈরি করা হয়। RediSearch 2.0-এ FT.CREATE কমান্ড সূচক তৈরি করতে ব্যবহৃত হয়। API-এর সংযোজনগুলি এখানে হলুদ রঙে হাইলাইট করা হয়েছে:
FT.CREATE {index}
ON {structure}
[PREFIX {count} {prefix} [{prefix} ..]
[FILTER {filter}]
[LANGUAGE_FIELD {lang_field}]
[LANGUAGE {lang}]
[SCORE_FIELD {score_field}]
[SCORE {score}]
[PAYLOAD_FIELD {payload_field}]
[TEMPORARY {seconds}]
[MAXTEXTFIELDS]
[NOOFFSETS] [NOHL] [NOFIELDS] [NOFREQS]
[STOPWORDS {num} {stopword} ...]
SCHEMA {field} [TEXT [NOSTEM] [WEIGHT {weight}] [PHONETIC {matcher}] | NUMERIC | GEO | TAG [SEPARATOR {sep}] ] [SORTABLE][NOINDEX] ... আসুন কিছু বিবরণে খনন করি:
- ON {structure} বর্তমানে শুধুমাত্র HASH সমর্থন করে
- PREFIX {count} {prefix} সূচীকে বলে যে এটি কোন কীগুলিকে সূচিত করতে হবে। আপনি সূচকে বেশ কয়েকটি উপসর্গ যোগ করতে পারেন। যেহেতু যুক্তিটি ঐচ্ছিক, তাই ডিফল্ট হল * (সমস্ত কী)
- ফিল্টার {ফিল্টার সম্পূর্ণ RediSearch এগ্রিগেশন এক্সপ্রেশন ল্যাঙ্গুয়েজ সহ একটি ফিল্টার এক্সপ্রেশন। এইমাত্র যোগ/পরিবর্তন করা কীটি অ্যাক্সেস করতে @__key ব্যবহার করা সম্ভব
- LANGUAGE এবং স্কোর আপনাকে ডিফল্ট ভাষা ওভাররাইড করতে দিন এবং সূচীকৃত সমস্ত নথির জন্য স্কোর করুন
- LANGUAGE_FIELD , SCORE_FIELD , এবং PAYLOAD_FIELD আপনাকে নথি-নির্দিষ্ট ভাষা এবং স্কোরিং এবং নথির মধ্যে একটি ক্ষেত্র হিসাবে পেলোড ব্যবহার করার অনুমতি দেয়৷
অন্যান্য সীমাবদ্ধতা এবং পরিবর্তন
RediSearch 2.0-M01 মাইলস্টোন আরও কিছু আপডেট নিয়ে আসে:
- NOSAVE আর সমর্থিত নয়৷
- হ্যাশ আপডেট করা বোঝায় যে পুরো নথিটি সূচীবদ্ধ হবে (কী স্পেস বিজ্ঞপ্তিগুলি কোন ক্ষেত্রগুলি পরিবর্তন করা হয়েছে তা সম্বোধন করে না)। তাই আংশিক আপডেট ধীর হবে. মনে রাখবেন যে আমরা এখনও এই পরিস্থিতিতে কর্মক্ষমতা উন্নত করার বিকল্পগুলি তদন্ত করছি৷
- ক্ষেত্রের নামগুলি এখন কেস সংবেদনশীল, তাই একটি ক্ষেত্র "FOO" ঘোষণা করা এবং "foo" হিসাবে সূচীকরণ কাজ করবে না৷
- The FT.ADD কমান্ড hset এ ম্যাপ করা হবে এখানে দেখানো হয়েছে:
FT.ADD idx doc1 1.0 LANGUAGE eng PAYLOAD payload FIELDS f1 v1 f2 v2
-এ ম্যাপ করা হয়েছে
HSET doc1 __score 1.0 __language eng __payload payload f1 v1 f2 v2
এর মানে হল আপনার সূচকের স্কোর, ভাষা এবং পেলোড ক্ষেত্রগুলিকে অবশ্যই __score, __language, __payload বলা হবে, যাতে ম্যাপিং প্রত্যাশিতভাবে কাজ করে।
- FT.ADDHASH আর সমর্থিত নয়। HSET ব্যবহার করুন .
- FT.OPTIMIZE আর সমর্থিত নয়, রেডিসার্চ গারবেজ কালেকশন ফাংশন ইনডেক্স অপ্টিমাইজ করার জন্য দায়ী৷
উপসংহার
আমরা এই পরিবর্তনগুলি নিয়ে সত্যিই উচ্ছ্বসিত কারণ আপনি এখন আপনার বিদ্যমান রেডিস ডাটাবেসে RediSearch লোড করতে পারেন এবং এই নথিগুলিকে ম্যানিপুলেট করার সময় আপনার অ্যাপ্লিকেশন লজিক আপডেট না করেই হ্যাশে থাকা আপনার বিদ্যমান ডেটা সূচক করতে পারেন৷ আপনি GitHub থেকে সোর্স কোড নিয়ে বা 1:99:1 ব্যবহার করে এই মাইলস্টোন রিলিজটি চেষ্টা করতে পারেন RedisSarch ডকার ইমেজ. এই সংস্করণটি এখনও উত্পাদনের জন্য প্রস্তুত নয়, তবে আমরা আপনার প্রতিক্রিয়া সংগ্রহ করার জন্য এটি এখন আপনার সাথে ভাগ করতে চেয়েছিলাম৷ অনুগ্রহ করে আমাদের GitHub সংগ্রহস্থলে বা Redis কমিউনিটি ফোরামে কোনো মন্তব্য বা সমস্যা শেয়ার করুন।
