
টেনসরফ্লো হল একটি মেশিন লার্নিং ফ্রেমওয়ার্ক যা Google প্রদান করে। এটি একটি ওপেন-সোর্স ফ্রেমওয়ার্ক যা পাইথনের সাথে অ্যালগরিদম, গভীর শিক্ষার অ্যাপ্লিকেশন এবং আরও অনেক কিছু বাস্তবায়নের জন্য ব্যবহৃত হয়। এটি গবেষণা এবং উৎপাদন উদ্দেশ্যে ব্যবহৃত হয়।
'টেনসরফ্লো' প্যাকেজটি নীচের কোড-
লাইনটি ব্যবহার করে উইন্ডোজে ইনস্টল করা যেতে পারেpip install tensorflow
'IMDB' ডেটাসেটে 50 হাজারের বেশি সিনেমার রিভিউ রয়েছে। এই ডেটাসেটটি সাধারণত প্রাকৃতিক ভাষা প্রক্রিয়াকরণের সাথে যুক্ত ক্রিয়াকলাপের সাথে ব্যবহৃত হয়।
নিচের কোডটি চালানোর জন্য আমরা Google Colaboratory ব্যবহার করছি। Google Colab বা Colaboratory ব্রাউজারে Python কোড চালাতে সাহায্য করে এবং এর জন্য শূন্য কনফিগারেশন এবং GPUs (গ্রাফিক্যাল প্রসেসিং ইউনিট) তে বিনামূল্যে অ্যাক্সেস প্রয়োজন। জুপিটার নোটবুকের উপরে কোলাবোরেটরি তৈরি করা হয়েছে।
ফলোইউং হল একটি প্লট তৈরি করার জন্য কোড স্নিপেট যা প্রশিক্ষিত IMDB ডেটাসেটে প্রশিক্ষণ এবং বৈধতা নির্ভুলতা কল্পনা করে −
উদাহরণ
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show() কোড ক্রেডিট − https://www.tensorflow.org/tutorials/keras/text_classification
আউটপুট
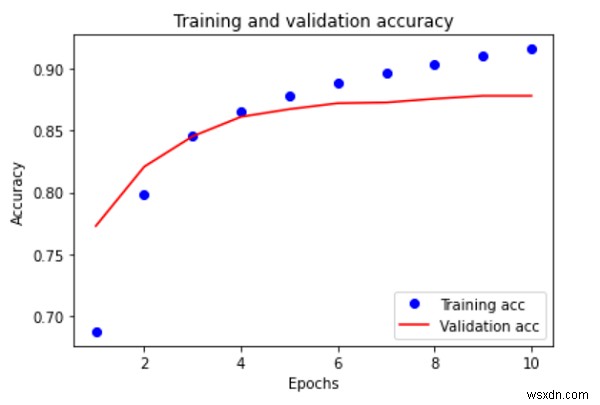
ব্যাখ্যা
-
একবার ডেটা মডেলের সাথে ফিট হয়ে গেলে, প্রকৃত মান এবং পূর্বাভাসিত মানগুলির তুলনা করা দরকার৷
-
এটি করার সর্বোত্তম উপায় হল ভিজ্যুয়ালাইজেশন।
-
তাই, 'matplotlib' লাইব্রেরি প্রশিক্ষণ এবং বৈধতা ডেটাসেটের ক্ষেত্রে নির্ভুলতা প্লট করতে ব্যবহৃত হয়৷
-
এটি মডেলের সাথে মানানসই ডেটা প্রশিক্ষণের জন্য নেওয়া পদক্ষেপের সংখ্যা (বা যুগ) এর উপর ভিত্তি করে।
