
প্রশিক্ষণের ফলাফলগুলি 'matplotlib' লাইব্রেরির সাহায্যে Python ব্যবহার করে Tensorflow এর মাধ্যমে কল্পনা করা যেতে পারে। কনসোলে ডেটা প্লট করার জন্য 'প্লট' পদ্ধতি ব্যবহার করা হয়।
আরো পড়ুন: টেনসরফ্লো কী এবং নিউরাল নেটওয়ার্ক তৈরি করতে টেনসরফ্লো-এর সাথে কেরাস কীভাবে কাজ করে?
আমরা কেরাস সিকোয়েন্সিয়াল এপিআই ব্যবহার করব, যা একটি অনুক্রমিক মডেল তৈরি করতে সহায়ক যা স্তরগুলির একটি প্লেইন স্ট্যাকের সাথে কাজ করতে ব্যবহৃত হয়, যেখানে প্রতিটি স্তরে একটি ইনপুট টেনসর এবং একটি আউটপুট টেনসর রয়েছে৷
একটি নিউরাল নেটওয়ার্ক যা অন্তত একটি স্তর ধারণ করে একটি কনভোলিউশনাল স্তর হিসাবে পরিচিত। আমরা শেখার মডেল তৈরি করতে কনভোলিউশনাল নিউরাল নেটওয়ার্ক ব্যবহার করতে পারি।
keras.Sequential মডেল ব্যবহার করে একটি ইমেজ ক্লাসিফায়ার তৈরি করা হয় এবং preprocessing.image_dataset_from_directory ব্যবহার করে ডেটা লোড করা হয়। ডেটা দক্ষতার সাথে ডিস্ক থেকে লোড করা হয়। ওভারফিটিং চিহ্নিত করা হয় এবং এটি প্রশমিত করার জন্য কৌশল প্রয়োগ করা হয়। এই কৌশলগুলির মধ্যে ডেটা বৃদ্ধি এবং ড্রপআউট অন্তর্ভুক্ত। 3700টি ফুলের ছবি রয়েছে। এই ডেটাসেটে 5টি সাব ডিরেক্টরি রয়েছে এবং প্রতি ক্লাসে একটি সাব ডিরেক্টরি রয়েছে। সেগুলি হল:ডেইজি, ড্যান্ডেলিয়ন, গোলাপ, সূর্যমুখী এবং টিউলিপ।
নিচের কোডটি চালানোর জন্য আমরা Google Colaboratory ব্যবহার করছি। Google Colab বা Colaboratory ব্রাউজারে Python কোড চালাতে সাহায্য করে এবং এর জন্য শূন্য কনফিগারেশন এবং GPUs (গ্রাফিক্যাল প্রসেসিং ইউনিট) তে বিনামূল্যে অ্যাক্সেস প্রয়োজন। জুপিটার নোটবুকের উপরে কোলাবোরেটরি তৈরি করা হয়েছে।
উদাহরণ
print("Calculating the accuracy")
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
print("Calculating the loss")
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
print("The results are being visualized")
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show() কোড ক্রেডিট −https://www.tensorflow.org/tutorials/images/classification
আউটপুট
Calculating the accuracy Calculating the loss The results are being visualized
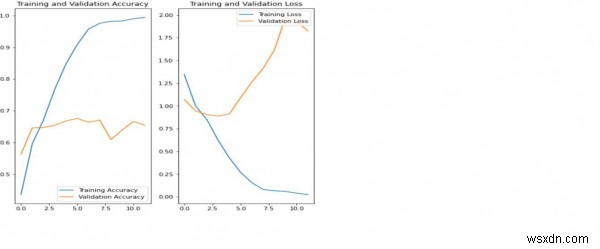
ব্যাখ্যা
-
উপরের প্লটগুলি নির্দেশ করে যে প্রশিক্ষণের সঠিকতা এবং বৈধতা নির্ভুলতা সিঙ্ক নয়৷
-
মডেলটি বৈধতা ডেটাসেটে প্রায় 60 শতাংশ নির্ভুলতা অর্জন করেছে৷
৷ -
এটি ওভারফিটিং নামে পরিচিত।
-
প্রশিক্ষণের নির্ভুলতা সময়ের সাথে সাথে রৈখিকভাবে বৃদ্ধি পেয়েছে, তবে প্রশিক্ষণ প্রক্রিয়ায় বৈধতা নির্ভুলতা প্রায় 60 শতাংশে স্থবির হয়ে পড়েছে।
-
যখন প্রশিক্ষণের উদাহরণের সংখ্যা কম হয়, তখন মডেলটি প্রশিক্ষণের উদাহরণ থেকে শব্দ বা অবাঞ্ছিত বিবরণ থেকে শেখে।
-
এটি নেতিবাচকভাবে নতুন উদাহরণে মডেলের কর্মক্ষমতা প্রভাবিত করে।
-
ওভারফিটিংয়ের কারণে, মডেলটি নতুন ডেটাসেটে ভালোভাবে সাধারণীকরণ করতে সক্ষম হবে না।
-
ওভারফিটিং এড়ানো যায় এমন অনেক উপায় রয়েছে। অতিরিক্ত ফিটিং কাটিয়ে উঠতে আমরা ডেটা অগমেন্টেশন ব্যবহার করব।
