
স্কেলের জন্য ওয়েব অ্যাপ্লিকেশনগুলি বিবেচনা করার সময় পটভূমির কাজগুলি মূল স্তম্ভগুলির মধ্যে একটি। মূল ধারণাটি সহজ:একজন ক্লায়েন্ট আপনার ওয়েব অ্যাপ্লিকেশনে একটি অনুরোধ করে এবং সেই অনুরোধটি পরিচালনা করার জন্য, আপনার অ্যাপটি বেশ কিছু সময় ব্যয়বহুল কাজ সম্পাদন করে। ক্লায়েন্টকে দ্রুত সাড়া দেওয়ার জন্য, অ্যাপটি একটি ব্যাকগ্রাউন্ড প্রসেসিং সিস্টেমে একটি ব্যাকগ্রাউন্ড জব সারিবদ্ধ করে। ব্যাকগ্রাউন্ড প্রসেসিং এর পরে সমস্ত ভারী উত্তোলনের সাথে কাজ করা হয়, যেমন গণনা বা I/O অপারেশন। আপনার ওয়েব অ্যাপ্লিকেশনগুলিকে স্কেল করার সময় কার্যকরভাবে ব্যাকগ্রাউন্ড কাজের উপর ঝুঁকে থাকা সবচেয়ে গুরুত্বপূর্ণ বিল্ডিং ব্লকগুলির মধ্যে একটি৷
Rails বিকাশকারী হিসাবে, আমরা বিভিন্ন সুবিধা, অসুবিধা এবং এমনকি ব্যাকএন্ড ডেটাবেস সহ বেছে নেওয়ার জন্য বেশ কয়েকটি চমত্কার লাইব্রেরি দিয়ে আশীর্বাদ পেয়েছি। এই লাইব্রেরিগুলি আমাদের অ্যাপ্লিকেশনগুলিকে দ্রুত প্রতিক্রিয়া জানাতে এবং কম সংস্থান সহ আরও ব্যবহারকারীদের পরিষেবা দেওয়ার অনুমতি দিয়ে যে কোনও ভারী উত্তোলন অফলোড করা সহজ করে তোলে৷
সম্প্রতি পর্যন্ত, আমরা Sidekiq ব্যবহার করতাম Honeybadger-এর ব্যাকগ্রাউন্ড প্রসেসিং কাজগুলির অধিকাংশ সম্পাদন করতে। এটি আমাদেরকে একটি উজ্জ্বল-দ্রুত ব্যবহারকারীর অভিজ্ঞতা এবং আমরা যে বিপুল পরিমাণ ডেটা গ্রহণ করি তা প্রক্রিয়াকরণের জন্য একটি শক্তিশালী পাইপলাইন বজায় রাখতে সাহায্য করেছে৷
সিডেকিক আমাদের জন্য কোথায় কম পড়ে?
এর নির্ভরযোগ্যতা সত্ত্বেও, রেডিসের কিছু সীমাবদ্ধতা রয়েছে। সম্প্রতি পর্যন্ত, আমরা আমাদের ত্রুটি-ট্র্যাকিং এন্ডপয়েন্টগুলির জন্য ইনজেস্ট পরিচালনা সহ আমাদের সমস্ত কাজের প্রক্রিয়াকরণের জন্য Sidekiq ব্যবহার করতাম। ত্রুটি ট্র্যাফিক অত্যন্ত পরিবর্তনশীল. আমরা প্রায়শই আমাদের সারিতে থাকা কাজের সংখ্যা 10x বা 20গুণ বাড়িয়ে দিতাম—যার ফলে আমাদের অটোস্কেলিং পর্যাপ্ত কর্মীকে ধরতে না পারা পর্যন্ত বড় ব্যাকলগ তৈরি হয়। কিন্তু সবচেয়ে বড় সমস্যা ছিল আমাদের ইলাস্টিক্যাচে ক্লাস্টারে মেমরির ক্লান্তি।
আমাদের ইলাস্টিক্যাচে ক্লাস্টারের মধ্য দিয়ে যাওয়ার পর্যাপ্ত চাকরির ট্র্যাফিক ছিল যে ডাউনস্ট্রিম প্রক্রিয়াকরণে কোনও উল্লেখযোগ্য বিলম্ব ক্লাস্টারের মেমরি ফুরিয়ে যাওয়ার ঝুঁকি তৈরি করবে। যদিও আমরা নন-কিউ ডেটা সঞ্চয় করার জন্য একটি পৃথক ক্লাস্টার ব্যবহার করি, সময়ের সাথে সাথে, আমাদের প্রাথমিক ক্লাস্টারেও কিছু নন-কিউ ডেটা দেখানো হয়েছে, যা মেমরির বাইরের ত্রুটির ক্ষেত্রে উচ্ছেদ হতে পারে। আরও জটিল সমস্যা, যদিও, ক্লাস্টারের মেমরি ফুরিয়ে গেলে নতুন চাকরি গ্রহণ করতে না পারা।
একটি গৌণ সমস্যা হল Redis/ElastiCache volatile-lru ব্যবহার করে ডিফল্টরূপে উচ্ছেদ নীতি। এর পরিণতি হল যে উচ্চ মেমরি ব্যবহারের সময়ে, Redis একটি TTL সেটের সাথে সাম্প্রতিকতম ব্যবহৃত ডেটা সরিয়ে দেবে। এক পর্যায়ে, হানিব্যাজারের একটি ইভেন্ট ছিল যেখানে আমাদের মেমরির ব্যবহার যথেষ্ট বেশি ছিল যে রেডিস তার ক্যাশে পরিষ্কার করা শুরু করে যখন আমরা এটি করতে চাইনি। সৌভাগ্যবশত, উচ্ছেদ করা ডেটা পুনরুত্পাদনযোগ্য ছিল (অতএব TTL), তাই আমরা কোনো স্থায়ী ডেটা হারাইনি৷
তবুও, এটি আমাদের কাছে একটি প্রশ্ন রেখে গেছে যেটির সমাধান করা দরকার - যদি একটি অনুরূপ ঘটনা ঘটে এবং আমরা এমন ডেটা হারাতে শুরু করি যা আমরা পুনর্নির্মাণ করতে পারিনি? আমরা কিভাবে নিশ্চিত করতে পারি যে আমরা কখনই গ্রাহকের ডেটা হারাবো না? গ্রাহকের ত্রুটি ডেটা পরিচালনা করা আমাদের ব্যবসার মূল বিষয়, তাই আমাদের এমন একটি সিস্টেম দরকার যা ডেটা হারানোর জন্য স্থিতিস্থাপক৷
ডেটা গ্রহণের জন্য কাফকা ব্যবহার করা
কাফকা একটি বিতরণ করা ইভেন্ট পাইপলাইন যা স্কেলেবিলিটি এবং স্থিতিস্থাপকতা উভয়ই অফার করে। আমাদের সাম্প্রতিক অন্তর্দৃষ্টি লঞ্চের সাথে, আমরা আমাদের ইভেন্ট ডেটা প্রক্রিয়া করার জন্য পরিকাঠামো হিসাবে কাফকাকে দাঁড় করানো প্রচুর অভিজ্ঞতা অর্জন করেছি। এর পরে, আমরা আমাদের ত্রুটির ইনজেশন ডেটা প্রক্রিয়া করার জন্য একই প্রযুক্তি স্ট্যাক ব্যবহার করতে চেয়েছিলাম। আমরা কাফকা ব্যবহার করে আরও ভাল প্রসারণযোগ্যতা এবং আরও সাশ্রয়ী মূল্যের সাথে অপ্রয়োজনীয় স্টোরেজ অর্জনের লক্ষ্য রেখেছি।
যেহেতু আমরা অন্তর্দৃষ্টিগুলির জন্য আমাদের নিজস্ব AWS MSK ক্লাস্টার চালাচ্ছিলাম, আমাদের ইতিমধ্যেই পরিকাঠামো এবং অটোস্কেলিং সেটআপ ছিল৷ এর অর্থ হল আমাদের "শুধু" কিছু বিষয় সেট আপ করতে হবে এবং কিছু ভোক্তা তৈরি করতে হবে যারা আমাদের Sidekiq কর্মীদের মতো একই কোড চালায়। ধারণাটি বেশ সহজ ছিল যা আমাদের কাফকা ভোক্তাদের সূক্ষ্ম টিউনিংয়ের উপর আরও বেশি ফোকাস করতে দেয়।
Sidekiq থেকে Karafka এ স্থানান্তর করা
হানিব্যাজার একটি মহিমান্বিত মনোলিথ হিসাবে স্থাপিত, এবং কারাফকা আমাদের সেই একই স্থাপত্য বজায় রাখতে সহায়তা করে। আমরা ইতিমধ্যেই আমাদের কিছু অন্তর্দৃষ্টি ডেটা প্রক্রিয়া করার জন্য Karafka ব্যবহার করছি, তাই কিছু নতুন গ্রাহক যোগ করা একটি সহজ কাজ ছিল৷
কারাফকা এবং সিডেকিকের মধ্যে একটি প্রধান পার্থক্য হল কীভাবে চাকরি পুনরুদ্ধার করা হয়। কারাফকার সাথে, কাজগুলি একক ভোক্তা দৌড়ে একসাথে ব্যাচ এবং প্রক্রিয়া করা হয়। ভোক্তার মধ্যে, আমরা বার্তার অ্যারের উপর পুনরাবৃত্তি করতে পারি এবং Sidekiq কর্মীকে ইনলাইনে চালাতে পারি:
class NoticeConsumer < ApplicationConsumer
def consume
messages.each do |message|
NoticeWorker.new.perform(message.payload)
end
end
end
আরেকটি পার্থক্য আমাদের বিবেচনা করতে হয়েছিল যে কীভাবে ত্রুটি পরিচালনা কাজ করে। Sidekiq এর সাথে, যেহেতু প্রতিটি কাজ পারমাণবিক, একজন কর্মী পুনরায় চেষ্টা এবং ব্যর্থতার কলব্যাকের মাধ্যমে তার নিজস্ব ত্রুটি পরিচালনা করে। কাফকার ব্যাচিং আচরণের সাথে, ত্রুটিগুলি পরিচালনা করার জন্য আরও বিকল্প রয়েছে। সবচেয়ে উল্লেখযোগ্যভাবে, কারাফকা ডেড লেটার কিউ নামে একটি প্রক্রিয়া সরবরাহ করে। এটি আপনাকে একটি ব্যাচ বা পৃথক ভিত্তিতে ত্রুটি পরিচালনা নির্দিষ্ট করতে দেয়৷
dead_letter_queue(
topic: "ingestion.errors.dead",
max_retries: 5,
independent: true
)
যখনই Karafka ভোক্তা কোনো পৃথক বার্তা প্রক্রিয়া করতে ব্যর্থতার সম্মুখীন হন, তখন এটি 5 বার পুনরায় প্রক্রিয়া করার চেষ্টা করবে। যদি এটি 5 তম প্রচেষ্টা ব্যর্থ হয়, বার্তাটি নির্দিষ্ট বিষয়ে পাঠানো হবে। independent: true বিকল্পটি ভোক্তাকে বলে যে সম্পূর্ণ ব্যাচের পরিবর্তে শুধুমাত্র ব্যর্থ বার্তাটি DLQ-তে পাঠানো দরকার৷
কারাফকা পর্যবেক্ষণ এবং স্কেলিং
দেখা যাচ্ছে, কারাফকা ভোক্তাদের মনিটরিং এবং স্কেল করা বেশ জটিল। আপনি AWS/MSK এবং Karafka উভয় থেকে ট্র্যাক করতে পারেন এমন অনেকগুলি জিনিস রয়েছে এবং অনেকগুলি নব আপনি আপনার সিস্টেম টিউন করতে পারেন৷ এটি আপনার কোড কি করছে, ডেটা প্রবাহের আচরণের প্রতি সতর্ক মনোযোগ প্রয়োজন।
AWS CloudWatch-এর মাধ্যমে আমরা অনেক কিছু নিরীক্ষণ করি, কিন্তু এখানে আমরা কয়েকটি কাফকা-নির্দিষ্ট মেট্রিক্স দেখি:
- SumOffsetLag — একটি নির্দিষ্ট বিষয় এবং ভোক্তা গোষ্ঠীর জন্য, এটি সমস্ত পার্টিশন জুড়ে সমস্ত অফসেট ল্যাগের সমষ্টি৷
- EstimatedMaxTimeLag — একটি নির্দিষ্ট বিষয় এবং ভোক্তা গোষ্ঠীর জন্য, এটি হল আনুমানিক বর্তমান অফসেটে সমস্ত পার্টিশন ধরতে যে পরিমাণ সময় লাগবে।
Karafka এছাড়াও কিছু দুর্দান্ত উপকরণ সরবরাহ করে, তবে আপনাকে এই ডেটা প্রকাশ করতে হবে এবং এটি নিজে সংরক্ষণ করতে হবে:
- প্রসেসিং_ল্যাগ * — এই মানটি বার্তার প্রতিটি ব্যাচের জন্য উপলব্ধ। এটি আপনাকে বলে যে কাফকার কাছ থেকে বার্তা নিতে এবং এটি প্রক্রিয়াকরণ শুরু করতে কারাফকার কত সময় লেগেছিল৷
- consumption_lag * — এই মানটি প্রসেসিং_ল্যাগ এর মত ব্যাচের শেষ বার্তাটি কাফকা সিস্টেমে প্রবেশ করার সময় থেকে, আপনার ভোক্তা এটি প্রক্রিয়া করা শুরু না করা পর্যন্ত।
- সময়কাল * — একজন গ্রাহকের পুরো ব্যাচের বার্তা প্রক্রিয়া করতে এই সময় লাগে।
দেখা যাচ্ছে, Sidekiq প্রসেস স্কেল করা কারাফকা কনজিউমার প্রসেস স্কেল করার চেয়ে অনেক আলাদা। Sidekiq-এর সমান্তরালকরণ বাড়ানোর সময়, আপনার Redis ইন্সট্যান্স যা হ্যান্ডেল করতে পারে তাতে আপনি আরও প্রসেস যোগ করতে পারেন। কাফকার সাথে, আপনার বিষয়ের প্রতি পার্টিশনে সর্বাধিক 1টি প্রক্রিয়া থাকতে বাধ্য। একটি সাধারণ নিয়ম হিসাবে, আপনি আপনার পরিকল্পনার চেয়ে বেশি পার্টিশন পেতে চাইবেন যেহেতু একজন কাফকা ভোক্তাকে 1টির বেশি পার্টিশনের জন্য বরাদ্দ করা যেতে পারে৷
আরেকটি বিষয় মনে রাখতে হবে যে কাফকা ভোক্তাদের স্কেল করা এবং স্কেল করা একটি খুব দীর্ঘ অপারেশন হতে পারে। একটি ভোক্তা গোষ্ঠী থেকে ভোক্তাদের যোগ করা এবং অপসারণ করার জন্য গ্রুপটিকে নিজেকে পুনরায় ভারসাম্য বজায় রাখতে হবে। এর মানে প্রয়োজন অনুযায়ী পার্টিশন পুনরায় বরাদ্দ করা। পুনরায় নিয়োগের সময়, গ্রাহকরা বার্তা প্রক্রিয়াকরণ বন্ধ করে দেয়। যদিও আপনি sticky-cooperative দিয়ে এই সমস্যাটি কিছুটা প্রশমিত করতে পারেন অ্যাসাইনমেন্ট, আপনি সাধারনত রিব্যালেন্সিং এড়াতে চান যদি আপনি অতিরিক্ত রিসোর্সিং করে পারেন।
আমরা বর্তমানে SumOffsetLag পর্যবেক্ষণ করছি আমাদের স্কেলিং মেট্রিকগুলির মধ্যে একটি হিসাবে। লক্ষণীয় একটি গুরুত্বপূর্ণ বিষয় হল যে পুনঃব্যালেন্সিংয়ের সময়, এই মেট্রিকটি রিপোর্ট করা হয় না। সুতরাং আপনি যেমন কল্পনা করতে পারেন, একটি পুনঃভারসাম্যের সময়কালে, এই মেট্রিকটি পুনরায় ভারসাম্য শেষ না হওয়া পর্যন্ত ব্যাপকভাবে বৃদ্ধি পাবে। এটি একটি ন্যূনতম স্কেলিং রাখা গুরুত্বপূর্ণ আরেকটি কারণ।
হানিব্যাজারে কারাফকার পরবর্তী কী?
আমরা এখন এক মাসেরও বেশি সময় ধরে আমাদের কাফকা/কারাফকা বাস্তবায়ন 100% চালাচ্ছি এবং এটা বলা নিরাপদ যে আমরা বেশ সন্তুষ্ট। তারপরও, এটা জেনে খুব ভালো লাগছে যে আমরা যদি কখনো প্রয়োজন হয় তাহলে একটি বোতাম চাপলে আমরা সবসময় Sidekiq-এর কাছে ফিরে যেতে পারি। এই সিস্টেমগুলির যে কোনও একটিতে রক্ষণাবেক্ষণের কাজ করার প্রয়োজন হলে এটি আমাদের আরও বেশি স্থিতিস্থাপকতা দেয়৷
সিডেকিক থেকে কারাফকাতে স্থানান্তরিত হওয়ার প্রক্রিয়ায়, আমরা কাফকা এবং কারাফকার সাথে কাজ করার বিষয়ে আরও অনেক কিছু শিখেছি। আপনি যদি হানিব্যাজার রত্নটির সাম্প্রতিকতম সংস্করণে আপডেট না করে থাকেন তবে আপনার এটি পরীক্ষা করা উচিত! আমি কারাফকা প্লাগইনে কিছু নতুন বৈশিষ্ট্য যোগ করেছি। যখন আপনি অন্তর্দৃষ্টি সক্ষম করেন, তখন আপনার কাফকা সিস্টেমের সামগ্রিক স্বাস্থ্যের উপর আপনাকে আরও ভাল দৃষ্টিভঙ্গি দিতে আমাদের রত্ন কিছু গুরুত্বপূর্ণ পরিসংখ্যান ট্র্যাক করা শুরু করবে৷
এছাড়াও, আমাদের কাছে এখন একটি অন্তর্দৃষ্টি কারাকফা ড্যাশবোর্ড রয়েছে যা আপনাকে এই ডেটাটি কল্পনা করতে এবং আপনার কাফকা গ্রাহকরা কীভাবে আচরণ করছে সে সম্পর্কে আপনাকে আরও ভালভাবে বুঝতে সাহায্য করবে। Karafka ড্যাশবোর্ডের প্লাগইনের জন্য মেট্রিক্স সক্ষম করা প্রয়োজন। এটি করতে আপনার honeybadger.yml এ নিম্নলিখিত কনফিগারেশন যোগ করুন :
karafka:
insights:
metrics: true
ড্যাশবোর্ডটি দেখতে কেমন তার একটি নমুনা এখানে রয়েছে:
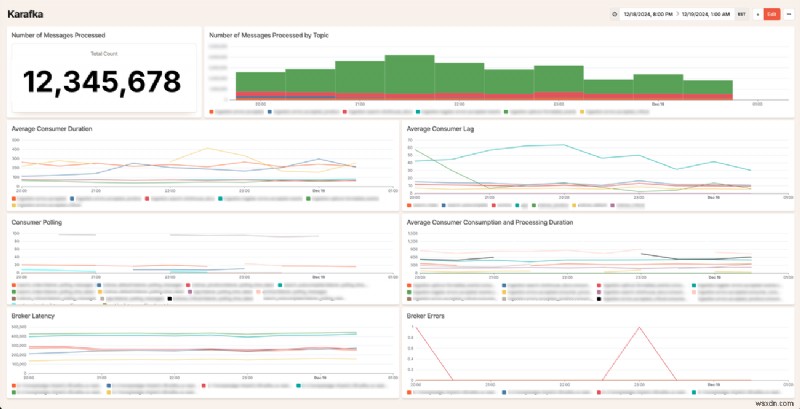
আমাদের গ্রাহকরা কীভাবে তাদের নিজস্ব Kafka সিস্টেম উন্নত করতে এই ডেটা ব্যবহার করে তা দেখে আমরা উত্তেজিত। আমরা কিভাবে Sidekiq থেকে Karafka এ স্থানান্তরিত হয়েছি, বা আমরা কিভাবে কাফকাকে সাধারণভাবে ব্যবহার করি সে সম্পর্কে আপনার কোনো প্রশ্ন থাকলে নির্দ্বিধায় যোগাযোগ করুন!
