
ওয়েব স্ক্র্যাপার তৈরির এই সিরিজে আবার স্বাগতম। এই টিউটোরিয়ালে, আমি আমার নিজের পডকাস্ট সাইট থেকে ডেটা স্ক্র্যাপ করার একটি উদাহরণ দিয়ে যাব। আমি কীভাবে ডেটা বের করেছি, কীভাবে সাহায্যকারী এবং ইউটিলিটি পদ্ধতিগুলি তাদের কাজগুলি সম্পন্ন করে এবং সমস্ত ধাঁধার অংশগুলি কীভাবে একত্রিত হয় তা আমি বিস্তারিতভাবে কভার করব।
বিষয়
- আমার পডকাস্ট স্ক্র্যাপিং
- প্রাই
- স্ক্র্যাপার
- সহায়ক পদ্ধতি
- পোস্ট লেখা
আমার পডকাস্ট স্ক্র্যাপ করা
আমরা এখন পর্যন্ত যা শিখেছি তা ব্যবহার করা যাক। বিভিন্ন কারণে, আমার পডকাস্ট এর মধ্যে একটি রিডিজাইন | স্ক্রীনের দীর্ঘদিন অপেক্ষা ছিল। আমি সকালে ঘুম থেকে উঠলে এমন কিছু সমস্যা ছিল যা আমাকে চিৎকার করে তোলে। তাই আমি মিডলম্যানের সাথে তৈরি এবং গিটহাব পেজগুলির সাথে হোস্ট করা একটি সম্পূর্ণ নতুন স্ট্যাটিক সাইট সেট আপ করার সিদ্ধান্ত নিয়েছি৷
আমি আমার প্রয়োজনে একটি মিডলম্যান ব্লগকে টুইক করার পরে নতুন ডিজাইনে অনেক সময় বিনিয়োগ করেছি। আমার ডাটাবেস-সমর্থিত সিনাট্রা অ্যাপ থেকে কন্টেন্ট ইম্পোর্ট করা বাকি ছিল, তাই আমার বিদ্যমান কন্টেন্ট স্ক্র্যাপ করে আমার নতুন স্ট্যাটিক সাইটে স্থানান্তর করতে হবে।
স্মাক ফ্যাশনে হাত দিয়ে এটি করা টেবিলে ছিল না - এমনকি একটি প্রশ্নও নয় - যেহেতু আমি আমার জন্য কাজটি করার জন্য আমার বন্ধু নোকোগিরি এবং মেকানাইজের উপর নির্ভর করতে পারি। আপনার সামনে যা আছে তা হল একটি যুক্তিসঙ্গতভাবে ছোট স্ক্র্যাপ কাজ যা খুব বেশি জটিল নয় কিন্তু কিছু আকর্ষণীয় টুইস্ট অফার করে যা ওয়েব স্ক্র্যাপিং নতুনদের জন্য শিক্ষামূলক হওয়া উচিত।
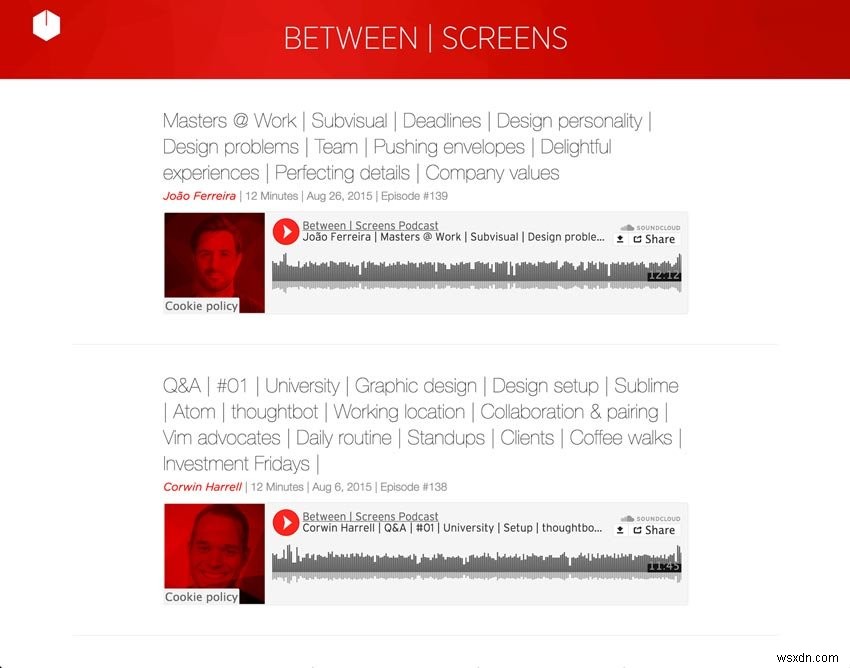
নীচে আমার পডকাস্ট থেকে দুটি স্ক্রিনশট আছে।
স্ক্রিনশট পুরানো পডকাস্ট
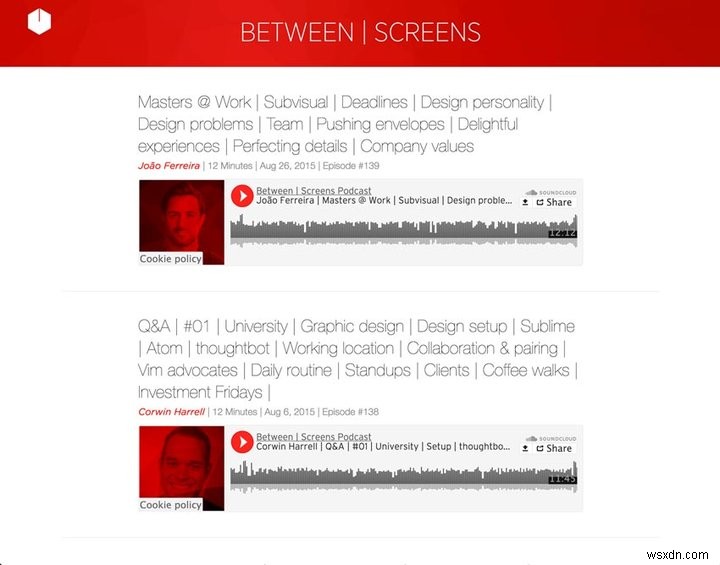
স্ক্রিনশট নতুন পডকাস্ট
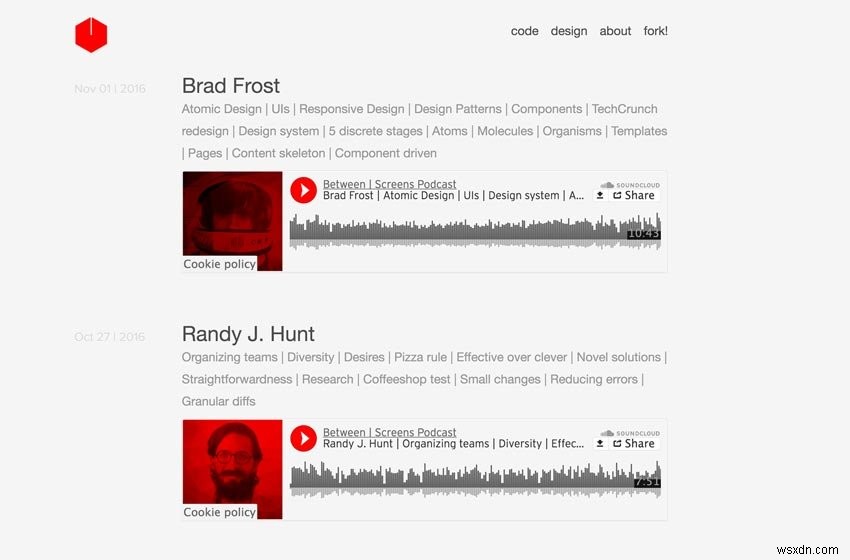
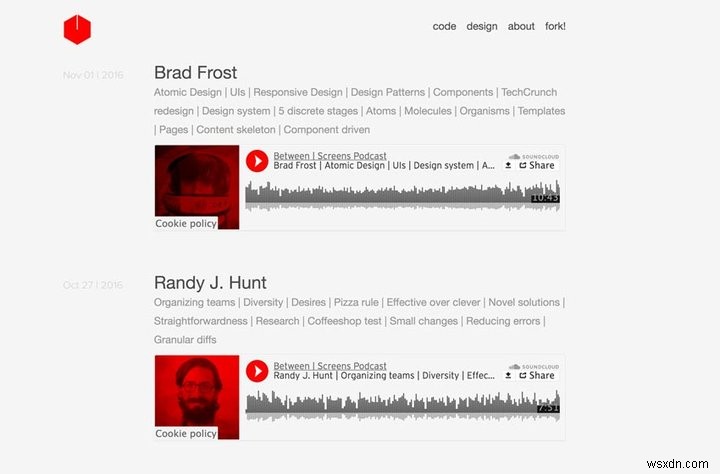
আসুন আমরা যা করতে চাই তা ভেঙে ফেলি। আমরা 139টি পর্ব থেকে নিম্নলিখিত ডেটা বের করতে চাই যা 21টি পেজিনেটেড ইনডেক্স সাইটে ছড়িয়ে আছে:
- শিরোনাম
- সাক্ষাত্কার গ্রহণকারী
- বিষয় তালিকা সহ সাবহেডার
- প্রতিটি পর্বের জন্য SoundCloud ট্র্যাক নম্বর
- তারিখ
- পর্ব সংখ্যা
- শো নোট থেকে পাঠ্য
- শো নোট থেকে লিঙ্কগুলি
আমরা পেজিনেশনের মাধ্যমে পুনরাবৃত্তি করি এবং মেকানাইজকে একটি পর্বের জন্য প্রতিটি লিঙ্কে ক্লিক করতে দিই। নিম্নলিখিত বিশদ পৃষ্ঠায়, আমরা উপরে থেকে আমাদের প্রয়োজনীয় সমস্ত তথ্য খুঁজে পাব। সেই স্ক্র্যাপ করা ডেটা ব্যবহার করে, আমরা প্রতিটি পর্বের জন্য মার্কডাউন ফাইলের সামনের ব্যাপার এবং "বডি" পূরণ করতে চাই।
আমরা যে বিষয়বস্তু বের করেছি তার সাথে আমরা কীভাবে নতুন মার্কডাউন ফাইলগুলি রচনা করব তার একটি পূর্বরূপ নীচে আপনি দেখতে পারেন৷ আমি মনে করি এটি আপনাকে আমাদের সামনের সুযোগ সম্পর্কে একটি ভাল ধারণা দেবে। এটি আমাদের ছোট স্ক্রিপ্টের চূড়ান্ত ধাপের প্রতিনিধিত্ব করে। চিন্তা করবেন না, আমরা আরও বিশদে এটি নিয়ে যাব।
def compose_markdown
def compose_markdown(options={})<<-HEREDOC--- শিরোনাম:#{options[:interviewee]}সাক্ষাত্কার গ্রহণকারী:#{options[:interviewee]}topic_list:#{options[:title]} ট্যাগ:#{options[:tags]}soundcloud_id:#{options[:sc_id]}date:#{options[:date]}episode_number:#{options[:episode_number]}---#{options[:text]}HEREDOCend
আমি কিছু কৌশল যোগ করতে চেয়েছিলাম যা পুরানো সাইটটি খেলতে পারেনি। জায়গায় একটি কাস্টমাইজড, ব্যাপক ট্যাগিং সিস্টেম থাকা আমার জন্য অত্যন্ত গুরুত্বপূর্ণ ছিল। আমি শ্রোতাদের একটি গভীর আবিষ্কারের হাতিয়ার চেয়েছিলাম। অতএব, আমার প্রত্যেক ইন্টারভিউয়ের জন্য ট্যাগ দরকার ছিল এবং সাবহেডারটিকেও ট্যাগে বিভক্ত করেছি। যেহেতু আমি একা প্রথম সিজনে 139টি এপিসোড তৈরি করেছি, তাই আমাকে এমন একটি সময়ের জন্য সাইটটি প্রস্তুত করতে হয়েছিল যখন বিষয়বস্তুর পরিমাণের মাধ্যমে আঁচড়ানো কঠিন হয়ে পড়ে। বুদ্ধিমত্তার সাথে স্থাপিত সুপারিশ সহ একটি গভীর ট্যাগিং সিস্টেম ছিল যাওয়ার উপায়। এটি আমাকে সাইটটিকে হালকা এবং দ্রুত রাখার অনুমতি দিয়েছে।
আমার সাইটের বিষয়বস্তু স্ক্র্যাপ করার জন্য সম্পূর্ণ কোডটি দেখুন। চারপাশে তাকান এবং কী ঘটছে তার বড় ছবি বের করার চেষ্টা করুন। যেহেতু আমি আশা করি আপনি বিষয়গুলির প্রাথমিক দিকে থাকবেন, তাই আমি খুব বেশি বিমূর্ত করা থেকে দূরে ছিলাম এবং স্পষ্টতার দিক থেকে ভুল করেছি। আমি কয়েকটি রিফ্যাক্টরিং করেছি যা কোডের স্পষ্টতাকে সহায়তা করার লক্ষ্যে ছিল, তবে আমি হাড়ের উপর সামান্য মাংসও রেখে দিয়েছি যখন আপনি এই নিবন্ধটি শেষ করবেন তখন আপনার সাথে খেলার জন্য। সর্বোপরি, মানসম্পন্ন শিক্ষা তখনই ঘটে যখন আপনি পড়ার বাইরে যান এবং নিজে থেকে কিছু কোড নিয়ে খেলতে যান।
পথের মধ্যে, আপনি কীভাবে আপনার সামনে কোডটি উন্নত করতে পারেন সে সম্পর্কে ভাবতে শুরু করার জন্য আমি আপনাকে উত্সাহিত করি। এই নিবন্ধের শেষে এটি আপনার চূড়ান্ত কাজ হবে। আমার কাছ থেকে একটি সামান্য ইঙ্গিত:বড় পদ্ধতিগুলিকে ছোটগুলিতে বিভক্ত করা সর্বদা একটি ভাল সূচনা পয়েন্ট। কোডটি কীভাবে কাজ করে তা আপনি একবার বুঝতে পারলে, সেই রিফ্যাক্টরিংয়ে আপনার একটি মজার সময় থাকা উচিত।
আমি ইতিমধ্যেই ছোট, ফোকাসড সাহায্যকারীদের মধ্যে একগুচ্ছ পদ্ধতি বের করে শুরু করেছি। কোড গন্ধ এবং তাদের রিফ্যাক্টরিং সম্পর্কে আপনি আমার আগের নিবন্ধগুলি থেকে যা শিখেছেন তা আপনি সহজেই প্রয়োগ করতে সক্ষম হবেন। যদি এটি এখনও আপনার মাথার উপর দিয়ে যায় তবে চিন্তা করবেন না—আমরা সবাই সেখানে ছিলাম। শুধু এটিতে থাকুন, এবং কিছু সময়ে জিনিসগুলি দ্রুত ক্লিক করতে শুরু করবে৷
৷সম্পূর্ণ কোড
require 'Mechanize'require 'Pry'require 'date'# Helper Methods# (Extraction Methods)def extract_interviewee(detail_page) interviewee_selector ='.episode_sub_title span' detail_page.search(interviewee_select)(interviewee_selector)ftract_page_detail_text. =".episode_title" detail_page.search(title_selector).text.gsub(/[?#]/, '')enddef extract_soundcloud_id(detail_page) sc =detail_page.iframes_with(href:/soundcloud.com/).to_s sc.scan (/\d{3,}/)।firstenddef extract_shownotes_text(detail_page) showote_selector ="#shownote_container> p" detail_page.search(shownote_selector)enddef extract_subtitle(detail_page) subheader_selector =".episode_subtract_selecter_details_page"। (পর্ব_সাবটাইটেল) সংখ্যা =/[#]\d*/.ম্যাচ(পর্ব_সাবটাইটেল) ক্লিন_এপিসোড_সংখ্যা(সংখ্যা)শেষ# (ইউটিলিটি পদ্ধতি)ডিএফ ক্লিন_ডেট(পর্ব_সাবটাইটেল) স্ট্রিং_ডেট =/[^|]*([,])(... ..)/.match(episode_subtitle).to_s Date.parse(string_date)endde f build_tags(title, interviewee) extracted_tags =strip_pipes(title) "#{interviewee}"+ ", #{extracted_tags}"enddef strip_pipes(text) ট্যাগ =text.tr('|', ',') ট্যাগ =ট্যাগ। gsub(/[@?#&]/, '') tags.gsub(/[w\/]{2}/, 'with')enddef clean_episode_number(number) number.to_s.tr('#', '' )enddef dasherize(text) text.lstrip.rstrip.tr('', '-')enddef extract_data(detail_page) interviewee =extract_interviewee(detail_page) title =extract_title(detail_page) sc_id =extract_soundcloud_id(detail_page) পাঠ্য =extract_page) episode_subtitle =extract_subtitle(detail_page) episode_number =extract_episode_number(episode_subtitle) তারিখ =clean_date(episode_subtitle) ট্যাগ =build_tags(title, interviewee) options ={ interviewee:interviewee, scid_tag:টেক্সট_ শিরোনাম:টেক্সট_, টেক্সট:শিরোনাম :তারিখ, পর্ব_সংখ্যা:পর্ব_সংখ্যা }enddef compose_markdown(options={})<<-HEREDOC--- শিরোনাম:#{option গুলি options[:date]}episode_number:#{options[:episode_number]}---#{options[:text]}HEREDOCenddef write_page(link) detail_page =link.click extracted_data =extract_data(detail_page) markdown_text =compose_markdown (extract_data) =extracted_data[:date] interviewee =extracted_data[:interviewee] episode_number =extracted_data[:episode_number] File.open("#{date}-#{dasherize(interviewee)}-#{episode_number}.html.erb.md", 'w') { |ফাইল| file.write(markdown_text) }enddef scrape link_range =1 এজেন্ট ||=Mechanize.new পর্যন্ত link_range ==21 পৃষ্ঠা =agent.get("https://between-screens.herokuapp.com/?page=#{link_range} ") link_range +=1 page.links[2..8].map do |link| write_page(লিংক) শেষ এন্ডএন্ডস্ক্র্যাপ
কেন আমরা require "Nokogiri" চাইনি ? মেকানাইজ আমাদের সমস্ত স্ক্র্যাপিং প্রয়োজনীয়তা সরবরাহ করে। যেমনটি আমরা পূর্ববর্তী প্রবন্ধে আলোচনা করেছি, মেকানাইজ নোকোগিরির উপরে তৈরি করে এবং আমাদেরকে বিষয়বস্তুও বের করার অনুমতি দেয়। যাইহোক, প্রথম নিবন্ধে সেই রত্নটিকে কভার করা গুরুত্বপূর্ণ ছিল যেহেতু আমাদের এটির উপরে তৈরি করা দরকার ছিল।
প্রায়
আগেরটা আগে. আমরা এখানে আমাদের কোডে ঝাঁপিয়ে পড়ার আগে, আমি ভেবেছিলাম যে আপনার কোডটি প্রতিটি ধাপে প্রত্যাশিত হিসাবে কাজ করে কিনা তা আপনি কীভাবে দক্ষতার সাথে পরীক্ষা করতে পারেন তা আপনাকে দেখানো দরকার। আপনি অবশ্যই লক্ষ্য করেছেন, আমি মিশ্রণে আরেকটি টুল যোগ করেছি। অন্যান্য জিনিসের মধ্যে, Pry ডিবাগিং জন্য সত্যিই সহজ.
আপনি Pry.start(binding) রাখলে আপনার কোডের যে কোন জায়গায়, আপনি ঠিক সেই সময়ে আপনার অ্যাপ্লিকেশন পরিদর্শন করতে পারেন। আপনি অ্যাপ্লিকেশনের নির্দিষ্ট পয়েন্টে বস্তুর মধ্যে ভ্রুক্ষেপ করতে পারেন। এটি আপনার নিজের পায়ের উপর না পড়ে ধাপে ধাপে আপনার আবেদন গ্রহণ করা সত্যিই সহায়ক। উদাহরণস্বরূপ, আসুন এটিকে আমাদের write_page এর ঠিক পরে রাখি ফাংশন এবং link কিনা তা পরীক্ষা করুন আমরা কি আশা করি।
প্রায়
...def scrape link_range =1 এজেন্ট ||=Mechanize.new পর্যন্ত link_range ==21 পৃষ্ঠা =agent.get("https://between-screens.herokuapp.com/?page=#{link_range}" ) link_range +=1 page.links[2..8].map do |link| write_page(link) Pry.start(binding) end endend...
আপনি যদি স্ক্রিপ্টটি চালান তবে আমরা এরকম কিছু পাব।
আউটপুট
»$ ruby noko_scraper.rb 321:def scrape 322:link_range =1 323:agent ||=Mechanize.new 324:326:পর্যন্ত link_range ==21 327:page =agent.get("https://between -screens.herokuapp.com/?page=#{link_range}") 328:link_range +=1 329:330:page.links[2..8].map do |link| 331:write_page(link) => 332:Pry.start(binding) 333:end 334:end 335:end[1] pry(main)>
তারপর যখন আমরা link চাই অবজেক্ট, আমরা অন্যান্য বাস্তবায়নের বিবরণে যাওয়ার আগে আমরা সঠিক পথে আছি কিনা তা পরীক্ষা করতে পারি।
টার্মিনাল
[2] pry(main)> link=> #
আমরা কি প্রয়োজন মত দেখায়. দুর্দান্ত, আমরা এগিয়ে যেতে পারি। আপনি যাতে হারিয়ে না যান এবং এটি কীভাবে কাজ করে তা আপনি সত্যিই বুঝতে পারেন তা নিশ্চিত করার জন্য পুরো অ্যাপ্লিকেশনটির মাধ্যমে ধাপে ধাপে এই কাজটি করা একটি গুরুত্বপূর্ণ অনুশীলন। আমি এখানে প্রাইকে আরও বিস্তারিতভাবে কভার করব না কারণ এটি করতে আমাকে অন্তত আরেকটি সম্পূর্ণ নিবন্ধ লাগবে। আমি শুধুমাত্র স্ট্যান্ডার্ড IRB শেলের বিকল্প হিসাবে এটি ব্যবহার করার সুপারিশ করতে পারি। আমাদের মূল কাজ ফিরে.
স্ক্র্যাপার
এখন যেহেতু আপনি জায়গায় ধাঁধার টুকরোগুলির সাথে নিজেকে পরিচিত করার সুযোগ পেয়েছেন, আমি সুপারিশ করছি যে আমরা একে একে একে একে একে চলে যাই এবং এখানে এবং সেখানে কয়েকটি আকর্ষণীয় পয়েন্ট স্পষ্ট করি। কেন্দ্রীয় টুকরা দিয়ে শুরু করা যাক।
podcast_scraper.rb
...def write_page(link) detail_page =link.click extracted_data =extract_data(detail_page) markdown_text =compose_markdown(extracted_data) date =extracted_data[:date] সাক্ষাৎকারগ্রহীতা =extracted_data[:interviewee] episode_number =extracted_number. ="#{date}-#{dasherize(interviewee)}-#{episode_number}.html.erb.md" File.open(file_name, 'w') { |file| file.write(markdown_text) }enddef scrape link_range =1 এজেন্ট ||=Mechanize.new পর্যন্ত link_range ==21 পৃষ্ঠা =agent.get("https://between-screens.herokuapp.com/?page=#{link_range} ") link_range +=1 page.links[2..8].map do |link| write_page(লিংক) শেষ শেষ...
scrape এ কি হয় পদ্ধতি? প্রথমত, আমি পুরানো পডকাস্টের প্রতিটি ইনডেক্স পৃষ্ঠা লুপ করি। আমি Heroku অ্যাপ থেকে পুরানো URL ব্যবহার করছি যেহেতু নতুন সাইটটি ইতিমধ্যে betweenscreens.fm-এ অনলাইন রয়েছে৷ আমার কাছে 20 পৃষ্ঠার পর্ব ছিল যা আমাকে লুপ করার দরকার ছিল।
আমি link_range এর মাধ্যমে লুপটি সীমাবদ্ধ করেছি পরিবর্তনশীল, যা আমি প্রতিটি লুপের সাথে আপডেট করেছি। প্রতিটি পৃষ্ঠার URL-এ এই ভেরিয়েবলটি ব্যবহার করার মতোই পৃষ্ঠা সংখ্যার মধ্য দিয়ে যাওয়া সহজ ছিল৷ সহজ এবং কার্যকর.
ডিএফ স্ক্র্যাপ
পৃষ্ঠা =agent.get("https://between-screens.herokuapp.com/?page=#{link_range}")
তারপর, যখনই আমি স্ক্র্যাপ করার জন্য আরও আটটি পর্ব সহ একটি নতুন পৃষ্ঠা পেয়েছি, আমি page.links ব্যবহার করি প্রতিটি পর্বের বিস্তারিত পৃষ্ঠায় ক্লিক করুন এবং অনুসরণ করুন। আমি লিঙ্কগুলির একটি পরিসরের সাথে যাওয়ার সিদ্ধান্ত নিয়েছি (links[2..8] ) যেহেতু এটি প্রতিটি পৃষ্ঠায় সামঞ্জস্যপূর্ণ ছিল। প্রতিটি ইনডেক্স পৃষ্ঠা থেকে আমার প্রয়োজনীয় লিঙ্কগুলিকে লক্ষ্য করার সহজতম উপায়ও ছিল। এখানে সিএসএস নির্বাচকদের সাথে ঝগড়া করার দরকার নেই।
তারপর আমরা write_page-এ বিস্তারিত পৃষ্ঠার জন্য সেই লিঙ্কটি ফিড করি পদ্ধতি এখানেই বেশিরভাগ কাজ সম্পন্ন হয়। আমরা সেই লিঙ্কটি নিয়ে যাই, এটিতে ক্লিক করি এবং বিস্তারিত পৃষ্ঠায় এটি অনুসরণ করি যেখানে আমরা এর ডেটা বের করা শুরু করতে পারি। সেই পৃষ্ঠায় আমরা নতুন সাইটের জন্য আমার নতুন মার্কডাউন পর্বগুলি রচনা করার জন্য প্রয়োজনীয় সমস্ত তথ্য খুঁজে পাই৷
def write_page
extracted_data =extract_data(detail_page)
def extract_data
<প্রি> ডিএফ এক্সট্রাক্ট_ডাটা (বিশদ_পেজ) ইন্টারভিউই =এক্সট্রাক্ট_ইন্টারভিউইইই (বিশদ_পৃষ্ঠা) শিরোনাম =এক্সট্রাক্ট_টাইটেল (বিশদ_পেজ) এসসি_আইডি =এক্সট্রাক্ট_সাউন্ডক্লাউড_আইডি (বিশদ_পেজ) =এক্সট্র্যাক্ট_সেট_সেট_সেট_সেট_স্যাক্ট_সেট_সেট_সেট_সেট_সেটস) ট্যাগ =বিল্ড_ট্যাগস(শিরোনাম, সাক্ষাত্কারকারী) বিকল্পগুলি ={ সাক্ষাত্কার গ্রহণকারী:সাক্ষাত্কারকারী, শিরোনাম:শিরোনাম, sc_id:sc_id, পাঠ্য:পাঠ্য, ট্যাগ:ট্যাগ, তারিখ:তারিখ, পর্ব_সংখ্যা:পর্ব_সংখ্যা }শেষ
আপনি উপরে দেখতে পাচ্ছেন, আমরা সেই detail_page নিয়েছি এবং এটিতে একগুচ্ছ নিষ্কাশন পদ্ধতি প্রয়োগ করুন। আমরা interviewee বের করি , title , sc_id , text , episode_title , এবং episode_number . আমি একগুচ্ছ ফোকাসড হেল্পার পদ্ধতি রিফ্যাক্টর করেছি যা এই নিষ্কাশন দায়িত্বের দায়িত্বে রয়েছে। আসুন সেগুলিকে দ্রুত দেখে নেওয়া যাক:
সহায়ক পদ্ধতি
নিষ্কাশন পদ্ধতি
আমি এই সাহায্যকারীদের বের করেছি কারণ এটি আমাকে সামগ্রিকভাবে ছোট পদ্ধতিগুলি করতে সক্ষম করেছে। তাদের আচরণকে এনক্যাপসুলেট করাও গুরুত্বপূর্ণ ছিল। কোড পাশাপাশি ভাল পড়া. তাদের অধিকাংশই detail_page নেয় একটি যুক্তি হিসাবে এবং আমাদের মিডলম্যান পোস্টের জন্য আমাদের প্রয়োজনীয় কিছু নির্দিষ্ট ডেটা বের করুন।
def extract_interviewee(detail_page) interviewee_selector ='.episode_sub_title span' detail_page.search(interviewee_selector).text.stripend
আমরা একটি নির্দিষ্ট নির্বাচকের জন্য পৃষ্ঠাটি অনুসন্ধান করি এবং অপ্রয়োজনীয় সাদা স্থান ছাড়াই পাঠ্য পাই৷
def extract_title(detail_page) title_selector =".episode_title" detail_page.search(title_selector).text.gsub(/[?#]/, '')শেষ
আমরা শিরোনাম নিয়ে ? সরিয়ে দিই এবং # যেহেতু এগুলি আমাদের পর্বগুলির জন্য পোস্টগুলির সামনের বিষয়টির সাথে সুন্দরভাবে খেলতে পারে না। সামনের বিষয় সম্পর্কে আরও নীচে।
def extract_soundcloud_id(detail_page) sc =detail_page.iframes_with(href:/soundcloud.com/).to_s sc.scan(/\d{3,}/).firstend
এখানে আমাদের হোস্ট করা ট্র্যাকগুলির জন্য সাউন্ডক্লাউড আইডি বের করার জন্য আমাদের একটু কঠিন কাজ করতে হবে। প্রথমে আমাদের href সহ Mechanize iframes দরকার soundcloud.com এর এবং এটি স্ক্যান করার জন্য একটি স্ট্রিং তৈরি করুন...
"[#<মেকানাইজ::পৃষ্ঠা::ফ্রেম\n nil\n \"https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/221003494&auto_play=false&hide_related=false&show_comments=false&show_user=true&show_reposts=false&visual=true\">\n]"
তারপরে ট্র্যাক আইডির সংখ্যাগুলির জন্য একটি রেগুলার এক্সপ্রেশন মেলে—আমাদের soundcloud_id "221003494" .
def extract_shownotes_text(detail_page) showote_selector ="#shownote_container> p" detail_page.search(shownote_selector)end
শো নোট নিষ্কাশন আবার বেশ সোজা. আমাদের শুধুমাত্র বিস্তারিত পৃষ্ঠায় শো নোটের অনুচ্ছেদগুলি সন্ধান করতে হবে। এখানে কোন চমক নেই।
def extract_subtitle(detail_page) subheader_selector =".episode_sub_title" detail_page.search(subheader_selector).textend
সাবটাইটেলের ক্ষেত্রেও একই কথা প্রযোজ্য, শুধুমাত্র এটি থেকে পর্ব নম্বরটি পরিষ্কারভাবে বের করার প্রস্তুতি মাত্র।
def extract_episode_number(episode_subtitle) সংখ্যা =/[#]\d*/.match(episode_subtitle) clean_episode_number(number)end
এখানে আমাদের নিয়মিত অভিব্যক্তির আরেকটি রাউন্ড প্রয়োজন। আসুন আমরা regex প্রয়োগ করার আগে এবং পরে দেখে নেই।
পর্ব_সাবটাইটেল
" João Ferreira | 12 মিনিট | 26 আগস্ট, 2015 | পর্ব #139 "
সংখ্যা
"#139"
আমাদের একটি পরিষ্কার নম্বর না হওয়া পর্যন্ত আরও একটি ধাপ।
def clean_episode_number(number) number.to_s.tr('#', '')end
আমরা সেই সংখ্যাটি একটি হ্যাশ # দিয়ে নিই এবং এটি সরান। Voilà, আমাদের প্রথম পর্বের নম্বর 139 আছে পাশাপাশি নিষ্কাশন করা হয়। আমি পরামর্শ দিচ্ছি যে আমরা এটিকে একসাথে আনার আগে আমরা অন্যান্য ইউটিলিটি পদ্ধতিগুলিও দেখি।
ইউটিলিটি পদ্ধতি
এই সমস্ত নিষ্কাশন ব্যবসার পরে, আমাদের কিছু পরিষ্কার করার আছে। আমরা ইতিমধ্যে মার্কডাউন রচনা করার জন্য ডেটা প্রস্তুত করা শুরু করতে পারি। উদাহরণস্বরূপ, আমি episode_subtitle কে স্লাইস করি একটি পরিষ্কার তারিখ পেতে এবং tags তৈরি করতে আরও কিছু build_tags সহ পদ্ধতি
def clean_date
def clean_date(episode_subtitle) string_date =/[^|]*([,])(.....)/.match(episode_subtitle).to_s Date.parse(string_date)end
আমরা অন্য একটি রেজেক্স চালাই যা এই মত তারিখগুলি সন্ধান করে: " Aug 26, 2015" . আপনি দেখতে পাচ্ছেন, এটি এখনও খুব সহায়ক নয়। string_date থেকে আমরা সাবটাইটেল থেকে পাই, আমাদের একটি বাস্তব Date তৈরি করতে হবে বস্তু অন্যথায় মিডলম্যান পোস্ট তৈরি করা অকেজো হবে।
string_date
" 26 আগস্ট, 2015"
তাই আমরা সেই স্ট্রিংটি নিয়ে একটি Date.parse করি . ফলাফল অনেক বেশি আশাব্যঞ্জক দেখায়।
তারিখ
2015-08-26
def build_tags
def build_tags(title, interviewee) extracted_tags =strip_pipes(title) "#{interviewee}"+ ", #{extracted_tags}"end
এটি title নেয় এবং interviewee আমরা extract_data এর ভিতরে তৈরি করেছি পদ্ধতি এবং সমস্ত পাইপ অক্ষর এবং আবর্জনা সরিয়ে দেয়। আমরা পাইপ অক্ষরকে কমা দিয়ে প্রতিস্থাপন করি, @ , ? , # , এবং & একটি খালি স্ট্রিং সহ, এবং অবশেষে with-এর সংক্ষিপ্ত রূপের যত্ন নিন .
def strip_pipes
def strip_pipes(text) ট্যাগ =text.tr('|', ',') ট্যাগ =tags.gsub(/[@?#&]/, '') tags.gsub(/[w\/] {2}/, 'সহ')শেষ
শেষ পর্যন্ত আমরা ট্যাগ তালিকায় ইন্টারভিউ গ্রহণকারীর নামও অন্তর্ভুক্ত করি এবং প্রতিটি ট্যাগকে কমা দিয়ে আলাদা করি।
আগে
"মাস্টার্স @ ওয়ার্ক | সাবভিজুয়াল | সময়সীমা | ডিজাইন ব্যক্তিত্ব | ডিজাইন সমস্যা | দল | পুশিং খাম | আনন্দদায়ক অভিজ্ঞতা | নিখুঁত বিবরণ | কোম্পানির মান"
পরে
"João Ferreira, Masters Work , Subvisual , Deadlines , Design Personality , Design Problems , Team , Pushing Envelopes , Delightful অভিজ্ঞতা , Perfecting details , Company values"
এই ট্যাগগুলির প্রতিটিই সেই বিষয়ের জন্য পোস্টগুলির একটি সংগ্রহের একটি লিঙ্ক হিসাবে শেষ হবে৷ এই সবই extract_data এর ভিতরে ঘটেছে পদ্ধতি আসুন আমরা কোথায় আছি তা আরেকবার দেখে নেওয়া যাক:
def extract_data
<প্রি> ডিএফ এক্সট্রাক্ট_ডাটা (বিশদ_পেজ) ইন্টারভিউই =এক্সট্রাক্ট_ইন্টারভিউইইই (বিশদ_পৃষ্ঠা) শিরোনাম =এক্সট্রাক্ট_টাইটেল (বিশদ_পেজ) এসসি_আইডি =এক্সট্রাক্ট_সাউন্ডক্লাউড_আইডি (বিশদ_পেজ) =এক্সট্র্যাক্ট_সেট_সেট_সেট_সেট_স্যাক্ট_সেট_সেট_সেট_সেট_সেটস) ট্যাগ =বিল্ড_ট্যাগস(শিরোনাম, সাক্ষাত্কারকারী) বিকল্পগুলি ={ সাক্ষাত্কার গ্রহণকারী:সাক্ষাত্কারকারী, শিরোনাম:শিরোনাম, sc_id:sc_id, পাঠ্য:পাঠ্য, ট্যাগ:ট্যাগ, তারিখ:তারিখ, পর্ব_সংখ্যা:পর্ব_সংখ্যা }শেষ
এখানে যা করা বাকি আছে তা হল আমাদের এক্সট্র্যাক্ট করা ডেটা সহ একটি অপশন হ্যাশ ফেরত দেওয়া। আমরা এই হ্যাশটিকে compose_markdown-এ ফিড করতে পারি পদ্ধতি, যা আমার নতুন সাইটের জন্য প্রয়োজনীয় ফাইল হিসাবে লেখার জন্য আমাদের ডেটা প্রস্তুত করে।
পোস্ট লেখা
def compose_markdown
def compose_markdown(options={})<<-HEREDOC--- শিরোনাম:#{options[:interviewee]}সাক্ষাত্কার গ্রহণকারী:#{options[:interviewee]}topic_list:#{options[:title]} ট্যাগ:#{options[:tags]}soundcloud_id:#{options[:sc_id]}date:#{options[:date]}episode_number:#{options[:episode_number]}---#{options[:text]}HEREDOCend
আমার মিডলম্যান সাইটে পডকাস্ট পর্ব প্রকাশ করার জন্য, আমি এটির ব্লগিং সিস্টেমকে পুনরায় ব্যবহার করতে বেছে নিয়েছি। "বিশুদ্ধ" ব্লগ পোস্টগুলি তৈরি করার পরিবর্তে, আমি আমার পর্বগুলির জন্য শো নোট তৈরি করি যা আইফ্রেমের মাধ্যমে সাউন্ডক্লাউড হোস্ট করা পর্বগুলি প্রদর্শন করে৷ ইনডেক্স সাইটগুলিতে, আমি শুধুমাত্র সেই iframe প্লাস শিরোনাম এবং স্টাফ প্রদর্শন করি।
এটি কাজ করার জন্য আমার যে বিন্যাসটি প্রয়োজন তা ফ্রন্ট ম্যাটার নামক কিছু দিয়ে গঠিত। এটি মূলত আমার স্ট্যাটিক সাইটগুলির জন্য একটি কী/মান স্টোর। এটি আমার পুরানো সিনাত্রা সাইট থেকে আমার ডাটাবেসের চাহিদা প্রতিস্থাপন করছে।
সাক্ষাত্কার গ্রহণকারীর নাম, তারিখ, সাউন্ডক্লাউড ট্র্যাক আইডি, পর্ব নম্বর ইত্যাদির মতো ডেটা তিনটি ড্যাশের মধ্যে যায় (--- ) আমাদের পর্বের ফাইলগুলির উপরে। নীচে প্রতিটি পর্বের বিষয়বস্তু রয়েছে—প্রশ্ন, লিঙ্ক, স্পনসর স্টাফ ইত্যাদির মতো বিষয়বস্তু।
ফ্রন্ট ম্যাটার
---কী:valuekey:valuekey:valuekey:value---পর্বের বিষয়বস্তু এখানে যায়।
compose_markdown-এ পদ্ধতি, আমি একটি HEREDOC ব্যবহার করি প্রতিটি পর্বের জন্য তার সামনের বিষয় সহ সেই ফাইলটি রচনা করতে আমরা লুপ করি। অপশন হ্যাশ থেকে আমরা এই পদ্ধতিটি ফিড করি, আমরা extract_data এ সংগ্রহ করা সমস্ত ডেটা বের করি সহায়ক পদ্ধতি।
def compose_markdown
...<<-HEREDOC--- শিরোনাম:#{options[:interviewee]}সাক্ষাৎকারকারী:#{options[:interviewee]}topic_list:#{options[:title]} ট্যাগ:#{options[:tags]}soundcloud_id:#{options[:sc_id]}তারিখ:#{options[:date]}episode_number:#{options[:episode_number]}---#{options[:text]}HEREDOC...
এটি ঠিক সেখানে একটি নতুন পডকাস্ট পর্বের নীলনকশা। এই জন্য আমরা এসেছি. সম্ভবত আপনি এই নির্দিষ্ট সিনট্যাক্স সম্পর্কে ভাবছেন: #{options[:interviewee]} . আমি স্ট্রিং দিয়ে যথারীতি ইন্টারপোলেট করি, কিন্তু যেহেতু আমি ইতিমধ্যেই একটি <<-HEREDOC এর ভিতরে আছি , আমি ডবল উদ্ধৃতি বন্ধ ছেড়ে যেতে পারেন.
শুধু নিজেদের অভিমুখী করার জন্য, আমরা এখনও লুপে আছি, write_page এর ভিতরে একটি একক পর্বের শো নোট সহ একটি বিস্তারিত পৃষ্ঠায় ক্লিক করা প্রতিটি লিঙ্কের জন্য ফাংশন। এর পরে যা ঘটবে তা হল ফাইল সিস্টেমে এই ব্লুপ্রিন্ট লেখার প্রস্তুতি। অন্য কথায়, আমরা একটি ফাইলের নাম এবং রচিত markdown_text প্রদান করে প্রকৃত পর্ব তৈরি করি .
সেই চূড়ান্ত ধাপের জন্য, আমাদের শুধুমাত্র নিম্নলিখিত উপাদানগুলি প্রস্তুত করতে হবে:তারিখ, সাক্ষাৎকারের নাম এবং পর্ব নম্বর। সাথে markdown_text অবশ্যই, যা আমরা এইমাত্র compose_markdown থেকে পেয়েছি .
def write_page
...markdown_text =compose_markdown(extracted_data)date =extracted_data[:date]interviewee =extracted_data[:interviewee]episode_number =extracted_data[:episode_number]file_name ="#{date}-#{dasherize}}-in {episode_number}.html.erb.md" ...
তারপর আমাদের শুধুমাত্র file_name নিতে হবে এবং markdown_text এবং ফাইলটি লিখুন।
def write_page
...File.open(file_name, 'w') { |file| file.write(markdown_text) }...
আসুন এটিও ভেঙে ফেলি। প্রতিটি পোস্টের জন্য, আমার একটি নির্দিষ্ট বিন্যাস প্রয়োজন:2016-10-25-Avdi-Grimm-120 . আমি ফাইলগুলি লিখতে চাই যা তারিখ দিয়ে শুরু হয় এবং ইন্টারভিউয়ের নাম এবং পর্ব নম্বর অন্তর্ভুক্ত করে।
নতুন পোস্টের জন্য মিডলম্যান যে ফর্ম্যাটটি আশা করে তার সাথে মেলে, আমাকে ইন্টারভিউ গ্রহণকারীর নাম নিতে হবে এবং dasherize করতে আমার সাহায্যকারী পদ্ধতির মাধ্যমে রাখতে হবে। আমার জন্য নাম, Avdi Grimm থেকে Avdi-Grimm . জাদু কিছুই নয়, তবে দেখার মতো:
def ড্যাশারাইজ
def dasherize(text) text.lstrip.rstrip.tr(' ', '-')end
এটি ইন্টারভিউ গ্রহণকারীর নামের জন্য স্ক্র্যাপ করা টেক্সট থেকে হোয়াইটস্পেস সরিয়ে দেয় এবং আভিডি এবং গ্রিমের মধ্যে সাদা স্থানটিকে ড্যাশ দিয়ে প্রতিস্থাপন করে। বাকি ফাইলের নাম স্ট্রিং-এ একসাথে ড্যাশ করা হয়েছে: "date-interviewee-name-episodenumber" .
def write_page
..."#{date}-#{dasherize(interviewee)}-#{episode_number}.html.erb.md"...
যেহেতু এক্সট্রাক্ট করা বিষয়বস্তু সরাসরি একটি HTML সাইট থেকে আসে, তাই আমি সহজভাবে .md ব্যবহার করতে পারি না অথবা .markdown ফাইলের নাম এক্সটেনশন হিসেবে। আমি .html.erb.md এর সাথে যাওয়ার সিদ্ধান্ত নিয়েছি . ভবিষ্যত পর্বের জন্য যেগুলি আমি স্ক্র্যাপিং ছাড়াই রচনা করি, আমি .html.erb ছেড়ে দিতে পারি অংশ এবং শুধুমাত্র .md প্রয়োজন .
এই ধাপের পরে, scrape এ লুপ ফাংশন শেষ হয়, এবং আমাদের একটি একক পর্ব থাকা উচিত যা এইরকম দেখায়:
2014-12-01-Avdi-Grimm-1.html.erb.md
--- শিরোনাম:Avdi Grimminterviewee:Avdi Grimmtopic_list:Rake কি | উৎপত্তি | জিম উইরিচ | সাধারণ ব্যবহারের ক্ষেত্রে | Raketags এর সুবিধাসমূহ:Avdi Grimm, Rake কি , Origins , Jim Weirich , Common use cases , Advantages of Rakesoundcloud_id:179619755date:2014-12-01episode_number:1---প্রশ্ন:- আপনি আমাদের কী বলতে পারেন? রেকের উৎপত্তি?- আপনি আমাদের জিম ওয়েহরিচ সম্পর্কে কী বলতে পারেন?- রেকের সবচেয়ে সাধারণ ব্যবহারের ক্ষেত্রে কী কী?- রেকের সবচেয়ে উল্লেখযোগ্য সুবিধাগুলি কী কী? লিঙ্ক:ইন">http://www.youtube.com /watch?v=2ZHJSrF52bc">মহান জিম ওয়েইরিচ রেকের স্মরণে">https://github.com/jimweirich/rake">GitHubJim-এ Rake">https://github.com/jimweirich">GitHubBasic-এ জিম ওয়েইরিচ ">http://www.youtube.com/watch?v=AFPWDzHWjEY">জিম ওয়েইরিচপাওয়ারের বেসিক রেক টক">http://www.youtube.com/watch?v=KaEqZtulOus">জিম ওয়েইরিচ লার্নের পাওয়ার রেক টক ">http://devblog.avdi.org/2014/04/30/learn-advanced-rake-in-7-episodes/">7 পর্বে অ্যাডভান্সড রেক শিখুন - Avdi Grimm থেকে ( free )Avdi">http://about.avdi.org/">Avdi GrimmAvdi Grimm এর স্ক্রিনকাস্ট:রুবি">http://www.rubytapas.com/">রুবি TapasRuby">htt p://devchat.tv/ruby-rogues/">Ruby Rogues পডকাস্ট সঙ্গে Avdi GrimmGreat ebook:Rake">http://www.amazon.com/Rake-Management-Essentials-Andrey-Koleshko/dp/1783280778"> রেক টাস্ক ম্যানেজমেন্টের প্রয়োজনীয়তা https://twitter.com/ka8725"> আন্দ্রে কোলেশকোথেকে
এই স্ক্র্যাপারটি অবশ্যই শেষ পর্বে শুরু হবে এবং প্রথম পর্যন্ত লুপ হবে। প্রদর্শনের উদ্দেশ্যে, পর্ব 01 যে কোনোটির মতোই ভালো। আমরা যে ডেটা বের করেছি তা দিয়ে আপনি সামনের বিষয়টি দেখতে পারেন।
সে সবই আগে আমার সিনাট্রা অ্যাপের ডাটাবেসে লক করা ছিল—পর্ব নম্বর, তারিখ, সাক্ষাৎকার গ্রহণকারীর নাম এবং আরও অনেক কিছু। এখন আমরা এটি আমার নতুন স্ট্যাটিক মিডলম্যান সাইটের অংশ হতে প্রস্তুত করেছি। দুটি ট্রিপল ড্যাশের নিচের সবকিছু (--- ) হল শো নোট থেকে টেক্সট:বেশিরভাগ প্রশ্ন এবং লিঙ্ক।
চূড়ান্ত চিন্তা
এবং আমরা সম্পন্ন. আমার নতুন পডকাস্ট ইতিমধ্যে আপ এবং চলমান. আমি সত্যিই আনন্দিত যে আমি মাটি থেকে জিনিসটি পুনরায় ডিজাইন করতে সময় নিয়েছি। এখন নতুন পর্ব প্রকাশ করা অনেক ঠান্ডা। নতুন বিষয়বস্তু আবিষ্কার করা ব্যবহারকারীদের জন্যও মসৃণ হওয়া উচিত।
যেমনটি আমি আগে উল্লেখ করেছি, এটি এমন সময় যেখানে আপনার কিছু মজা করার জন্য আপনার কোড এডিটরে যাওয়া উচিত। এই কোডটি নিন এবং এটির সাথে কিছুটা কুস্তি করুন। এটি সহজ করার উপায় খুঁজে বের করার চেষ্টা করুন. কোড রিফ্যাক্টর করার কয়েকটি সুযোগ রয়েছে।
সামগ্রিকভাবে, আমি আশা করি এই ছোট্ট উদাহরণটি আপনাকে আপনার নতুন ওয়েব স্ক্র্যাপিং চপগুলির সাথে কী করতে পারে তার একটি ভাল ধারণা দিয়েছে। অবশ্যই আপনি অনেক বেশি পরিশীলিত চ্যালেঞ্জ অর্জন করতে পারেন — আমি নিশ্চিত যে এই দক্ষতাগুলির সাথে তৈরি করার জন্য প্রচুর ছোট ব্যবসার সুযোগ রয়েছে।
তবে বরাবরের মতো, এটি একবারে একটি পদক্ষেপ নিন এবং জিনিসগুলি এখনই ক্লিক না করলে খুব বেশি হতাশ হবেন না। এটি বেশিরভাগ লোকের জন্যই স্বাভাবিক নয় তবে প্রত্যাশিত। এটা যাত্রার অংশ। শুভ স্ক্র্যাপিং!
