
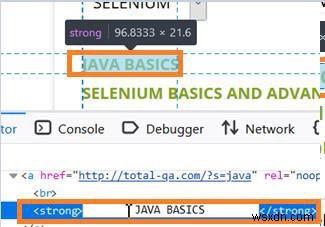
আমরা লোকেটার এক্সপাথ ব্যবহার করতে পারি অনুসন্ধান টেক্সট সহ বা স্পেস সহ উপাদান সনাক্ত করতে। প্রথমে ট্রেইলিং এবং লিডিং স্পেস সম্বলিত একটি ওয়েব এলিমেন্টের HTML কোড পরীক্ষা করা যাক। নীচের ছবিতে, ট্যাগনাম স্ট্রং সহ JAVA BASICS লেখাটিতে এইচটিএমএল কোডে প্রতিফলিত স্পেস রয়েছে৷
যদি কোনো এলিমেন্টের টেক্সটে বা কোনো অ্যাট্রিবিউটের মানের মধ্যে স্পেস থাকে, তাহলে এই ধরনের একটি এলিমেন্টের জন্য xpath তৈরি করতে আমাদের নরমালাইজ-স্পেস ফাংশন ব্যবহার করতে হবে। এটি স্ট্রিং থেকে সমস্ত পিছনের এবং অগ্রণী স্থানগুলি সরিয়ে দেয়। এটি স্ট্রিংয়ের মধ্যে বিদ্যমান সমস্ত নতুন ট্যাব বা লাইনগুলিকেও সরিয়ে দেয়৷
সিনট্যাক্স
//tagname[normalize-space(@attribute/ function) = 'value']
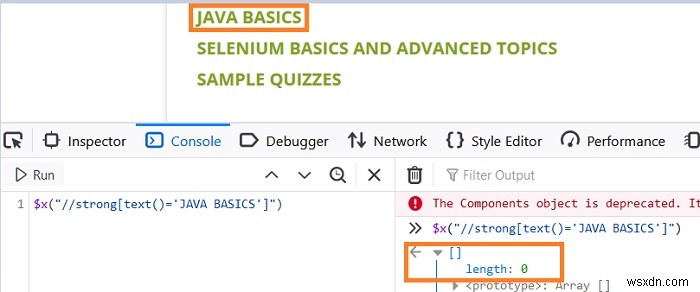
পৃষ্ঠায় প্রদর্শিত JAVA BASICS ওয়েব উপাদানটির জন্য, আসুন একটি xpath//strong[text()='JAVA BASICS'] তৈরি করি (টেক্সটে স্পেস বিবেচনা না করে)। যদি আমরা কনসোলে এক্সপ্রেশন দিয়ে এটিকে যাচাই করি - $x("//strong[text()='JAVABASICS']"), তাহলে আমরা দেখতে পাব সেখানে কোনো মিল নেই (দৈর্ঘ্য – 0 দিয়ে চিহ্নিত)।
এখন, নরমালাইজ-স্পেস ফাংশন ব্যবহার করে একটি xpath এক্সপ্রেশন তৈরি করা যাক। Thexpath এক্সপ্রেশন হওয়া উচিত - //strong[normalize-space(text())='JAVA BASICS']।
আউটপুট
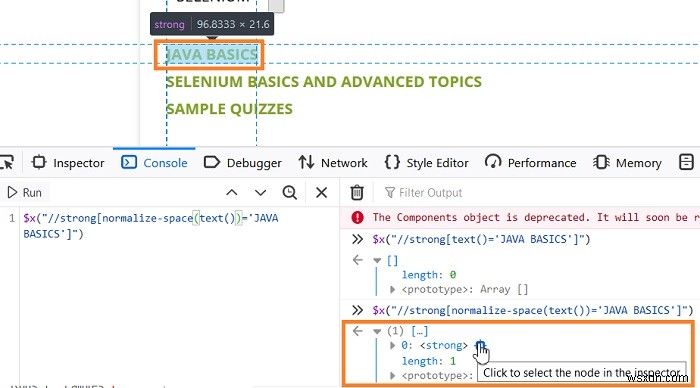
যদি আমরা কনসোলে এক্সপ্রেশন দিয়ে যাচাই করি - $x("//strong[normalizespace(text())='JAVA BASICS']"), তাহলে আমরা দেখতে পাব একটি ম্যাচিং এলিমেন্ট আছে (দৈর্ঘ্য – 1 দিয়ে চিহ্নিত করা হয়েছে)।
প্রাপ্ত ফলাফলের উপর হোভার করার সময়, আমরা পৃষ্ঠায় JAVA বেসিক্স হাইলাইট করা টেক্সট দেখতে পাব।
