

ইলাস্টিকসার্চ 5-এর সবচেয়ে দুর্দান্ত নতুন বৈশিষ্ট্যগুলির মধ্যে একটি হল ইনজেস্ট নোড, যা ইলাস্টিকসার্চ ক্লাস্টারে কিছু Logstash-স্টাইল প্রসেসিং যোগ করে, তাই এটি করার জন্য অন্য পরিষেবা এবং/অথবা অবকাঠামোর প্রয়োজন ছাড়াই সূচীভুক্ত হওয়ার আগে ডেটা রূপান্তরিত করা যেতে পারে। কিছুক্ষণ আগে, আমরা Logstash এর সাথে csv ফাইলগুলিকে পার্স করার বিষয়ে একটি দ্রুত ব্লগ পোস্ট করেছি, তাই আমি তুলনার স্বার্থে এর ইনজেস্ট পাইপলাইন সংস্করণটি প্রদান করতে চাই৷
আমরা এখানে যা দেখাব তা হল ফাইলবিট ব্যবহার করে একটি ইনজেস্ট পাইপলাইনে ডেটা পাঠাতে, এটিকে সূচীকরণ করতে এবং কিবানা দিয়ে এটিকে কল্পনা করতে।
ডেটা
বিনামূল্যে ডেটার জন্য প্রচুর দুর্দান্ত উত্স রয়েছে, কিন্তু যেহেতু অবজেক্ট রকেটের আমরা বেশিরভাগই অস্টিন, TX-এ আছি, তাই আমরা data.austintexas.gov থেকে কিছু ডেটা ব্যবহার করতে যাচ্ছি। রেস্তোরাঁ পরিদর্শন ডেটা সেট একটি ভাল আকারের ডেটা সেট যাতে আমাদের একটি বাস্তব বিশ্বের উদাহরণ দেওয়ার জন্য যথেষ্ট প্রাসঙ্গিক তথ্য রয়েছে৷
আপনাকে ডেটার গঠন সম্পর্কে ধারণা দিতে এই ডেটা সেট থেকে নীচে কয়েকটি লাইন দেওয়া হল:
Restaurant Name,Zip Code,Inspection Date,Score,Address,Facility ID,Process Description
Westminster Manor,78731,07/21/2015,96,"4100 JACKSON AVE
AUSTIN, TX 78731
(30.314499, -97.755166)",2800365,Routine Inspection
Wieland Elementary,78660,10/02/2014,100,"900 TUDOR HOUSE RD
AUSTIN, TX 78660
(30.422862, -97.640183)",10051637,Routine Inspection
DOH... এটি একটি সুন্দর, বন্ধুত্বপূর্ণ, প্রতি এন্ট্রি ক্ষেত্রে একক লাইন হতে যাচ্ছে না, তবে এটি ঠিক আছে। আপনি যেমন দেখতে চলেছেন, ফাইলবিট-এ মাল্টিলাইন এন্ট্রিগুলি পরিচালনা করার এবং ডেটাতে সমাহিত নতুন লাইনগুলির চারপাশে কাজ করার কিছু অন্তর্নির্মিত ক্ষমতা রয়েছে৷
সম্পাদকীয় দ্রষ্টব্য:আমি কয়েকটি "হিচ" সহ একটি সুন্দর সাধারণ উদাহরণের পরিকল্পনা করছিলাম, কিন্তু শেষ পর্যন্ত, আমি ভেবেছিলাম যে ইলাস্টিক স্ট্যাক আপনাকে এই পরিস্থিতিতে কাজ করার জন্য দেয় এমন কিছু সরঞ্জামগুলি দেখতে আকর্ষণীয় হতে পারে৷
ফাইলবিট সেট আপ করা হচ্ছে
প্রথম ধাপ হল আপনার ইলাস্টিকসার্চ ক্লাস্টারে ডাটা শিপিং শুরু করার জন্য Filebeat প্রস্তুত করা। একবার আপনি Filebeat ডাউনলোড হয়ে গেলে (আপনার ES ক্লাস্টারের মতো একই সংস্করণ ব্যবহার করার চেষ্টা করুন) এবং নিষ্কাশন করা হলে, অন্তর্ভুক্ত filebeat.yml কনফিগারেশন ফাইলের মাধ্যমে সেট আপ করা অত্যন্ত সহজ। আমাদের পরিস্থিতির জন্য, আমি যে কনফিগারেশনটি ব্যবহার করছি তা এখানে।
filebeat.prospectors:
- input_type: log
paths:
- /Path/To/logs/*.csv
# Ignore the first line with column headings
exclude_lines: ["^Restaurant Name,"]
# Identifies the last two columns as the end of an entry and then prepends the previous lines to it
multiline.pattern: ',\d+,[^\",]+$'
multiline.negate: true
multiline.match: before
#================================ Outputs =====================================
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["https://dfw-xxxxx-0.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-1.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-2.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-3.es.objectrocket.com:xxxxx"]
pipeline: "inspectioncsvs"
# Optional protocol and basic auth credentials.
username: "esuser"
password: "supersecretpassword"
এখানে সবকিছু বেশ সহজবোধ্য; কোথায় এবং কীভাবে ইনপুট ফাইলগুলি দখল করতে হবে তা উল্লেখ করার জন্য আপনার কাছে একটি বিভাগ এবং ডেটা কোথায় পাঠানো হবে তা উল্লেখ করার জন্য একটি বিভাগ রয়েছে। আমি বিশেষভাবে যে অংশগুলিকে কল করব তা হল মাল্টিলাইন বিট এবং ইলাস্টিকসার্চ কনফিগারেশন পিস৷
যেহেতু এই ডেটা সেটের বিন্যাসটি খুব কঠোর নয়, দ্বিগুণ উদ্ধৃতিগুলির অসামঞ্জস্যপূর্ণ ব্যবহার এবং বেশ কয়েকটি নতুন লাইন ছিটিয়ে দেওয়া হয়েছে, তাই সর্বোত্তম বিকল্পটি ছিল একটি এন্ট্রির শেষের সন্ধান করা, যা একটি পরিদর্শন টাইপ অনুসরণ করে একটি সংখ্যাসূচক আইডি নিয়ে গঠিত। অনেক ভিন্নতা বা ডবল-কোট/নতুন লাইন ছাড়াই। সেখান থেকে, Filebeat শুধুমাত্র যে কোনো অতুলনীয় লাইন সারিবদ্ধ করবে এবং প্যাটার্নের সাথে মেলে এমন চূড়ান্ত লাইনে সেগুলিকে প্রিপেন্ড করবে। যদি আপনার ডেটা পরিষ্কার হয় এবং প্রতি এন্ট্রি ফরম্যাটে একটি সাধারণ লাইনে আটকে থাকে, তাহলে আপনি মাল্টিলাইন সেটিংস উপেক্ষা করতে পারেন৷
ইলাস্টিকসার্চ আউটপুট সেকশনের দিকে তাকালে, এটি পাইপলাইনের নামের একটি ছোট সংযোজন সহ স্ট্যান্ডার্ড ইলাস্টিকসার্চ সেটিংস যা আপনি পাইপলাইনের সাথে ব্যবহার করতে চান:নির্দেশ। আপনি যদি অবজেক্ট রকেট পরিষেবাতে থাকেন, তাহলে আপনি UI-এর "কানেক্ট" ট্যাব থেকে আউটপুট স্নিপেটটি ধরতে পারেন, যা সঠিক হোস্টগুলির সাথে আগে থেকে আসবে, এবং শুধু পাইপলাইন লাইন যোগ করুন এবং আপনার ব্যবহারকারী এবং পাসওয়ার্ড পূরণ করুন . এছাড়াও, নিশ্চিত করুন যে আপনি আপনার সিস্টেমের আইপি আপনার ক্লাস্টারের ACL-তে যোগ করেছেন যদি আপনি ইতিমধ্যে এটি না করে থাকেন।
ইনজেস্ট পাইপলাইন তৈরি করা
এখন যেহেতু আমাদের কাছে ইনপুট ডেটা এবং ফাইলবিট যাওয়ার জন্য প্রস্তুত, আমরা আমাদের ইনজেস্ট পাইপলাইন তৈরি এবং টুইক করতে পারি। পাইপলাইনের প্রধান কাজগুলি সম্পাদন করতে হবে:
- সিএসভি বিষয়বস্তুকে সঠিক ক্ষেত্রগুলিতে বিভক্ত করুন
- পরিদর্শন স্কোরকে একটি পূর্ণসংখ্যাতে রূপান্তর করুন
-
@timestampসেট করুন ক্ষেত্র - অন্য কিছু ডেটা ফরম্যাটিং পরিষ্কার করুন
এখানে একটি পাইপলাইন যা এই সব করতে পারে:
PUT _ingest/pipeline/inspectioncsvs
{
"description" : "Convert Restaurant inspections csv data to indexed data",
"processors" : [
{
"grok": {
"field": "message",
"patterns": ["%{REST_NAME:RestaurantName},%{REST_ZIP:ZipCode},%{MONTHNUM2:InspectionMonth}/%{MONTHDAY:InspectionDay}/%{YEAR:InspectionYear},%{NUMBER:Score},\"%{DATA:StreetAddress}\n%{DATA:City},?\\s+%{WORD:State}\\s*%{NUMBER:ZipCode2}\\s*\n\\(?%{DATA:Location}\\)?\",%{NUMBER:FacilityID},%{DATA:InspectionType}$"],
"pattern_definitions": {
"REST_NAME": "%{DATA}|%{QUOTEDSTRING}",
"REST_ZIP": "%{QUOTEDSTRING}|%{NUMBER}"
}
}
},
{
"grok": {
"field": "ZipCode",
"patterns": [".*%{ZIP:ZipCode}\"?$"],
"pattern_definitions": {
"ZIP": "\\d{5}"
}
}
},
{
"convert": {
"field" : "Score",
"type": "integer"
}
},
{
"set": {
"field" : "@timestamp",
"value" : "//"
}
},
{
"date" : {
"field" : "@timestamp",
"formats" : ["yyyy/MM/dd"]
}
}
],
"on_failure" : [
{
"set" : {
"field" : "error",
"value" : " - Error processing message - "
}
}
]
}
Logstash এর বিপরীতে, ইনজেস্ট পাইপলাইনে (এই লেখার সময়) একটি csv প্রসেসর/প্লাগইন নেই, তাই আপনাকে csv-এর নিজেকে রূপান্তর করতে হবে। আমি ভারী উত্তোলন করতে একটি গ্রোক প্রসেসর ব্যবহার করেছি, যেহেতু প্রতিটি সারিতে মাত্র কয়েকটি কলাম ছিল। আরও অনেক কলাম সহ ডেটার জন্য, গ্রোক প্রসেসরটি বেশ লোমশ হতে পারে, তাই আরেকটি বিকল্প হল স্প্লিট প্রসেসর এবং কিছু ব্যথাহীন স্ক্রিপ্টিং ব্যবহার করে লাইনটিকে আরও পুনরাবৃত্তিমূলক ফ্যাশনে প্রক্রিয়া করা। আপনি দ্বিতীয় গ্রোক প্রসেসরটিও লক্ষ্য করতে পারেন, যা এই ডেটা সেটে জিপ কোডগুলি প্রবেশ করানো দুটি ভিন্ন উপায়ের সাথে মোকাবিলা করার জন্য রয়েছে৷
ডিবাগ উদ্দেশ্যে, আমি একটি সাধারণ on_failure বিভাগ অন্তর্ভুক্ত করেছি যা সমস্ত ত্রুটি ধরবে এবং প্রিন্ট আউট করবে কোন ধরনের প্রসেসর ব্যর্থ হয়েছে এবং কী বার্তা যা পাইপলাইন ভেঙেছে। এটি ডিবাগ উপায় সহজ করে তোলে। আমি যেকোন নথির জন্য আমার সূচী জিজ্ঞাসা করতে পারি যার ত্রুটি সেট আছে এবং তারপরে সিমুলেট API দিয়ে ডিবাগ করতে পারি। এখন সে সম্পর্কে আরও...
পাইপলাইন পরীক্ষা করা হচ্ছে
এখন যেহেতু আমরা আমাদের ইনজেস্ট পাইপলাইন কনফিগার করেছি, আসুন পরীক্ষা করি এবং সিমুলেট API দিয়ে এটি চালাই। প্রথমে আপনাকে একটি নমুনা নথির প্রয়োজন হবে। আপনি এটি কয়েকটি উপায়ে করতে পারেন। আপনি হয় পাইপলাইন সেটিং ছাড়াই ফাইলবিট চালাতে পারেন এবং তারপরে ইলাস্টিকসার্চ থেকে একটি অপ্রসেসড ডকুমেন্ট নিতে পারেন, অথবা ইলাস্টিকসার্চ বিভাগে মন্তব্য করে এবং yml ফাইলে নিম্নলিখিতগুলি যোগ করে আপনি কনসোল আউটপুট সক্ষম করে ফাইলবিট চালাতে পারেন:
output.console:
pretty: true
এখানে একটি নমুনা নথি যা আমি আমার পরিবেশ থেকে ধরেছি:
POST _ingest/pipeline/inspectioncsvs/_simulate
{
"docs" : [
{
"_index": "inspections",
"_type": "log",
"_id": "AVpsUYR_du9kwoEnKsSA",
"_score": 1,
"_source": {
"@timestamp": "2017-03-31T18:22:25.981Z",
"beat": {
"hostname": "systemx",
"name": "RestReviews",
"version": "5.1.1"
},
"input_type": "log",
"message": "Wieland Elementary,78660,10/02/2014,100,\"900 TUDOR HOUSE RD\nAUSTIN, TX 78660\n(30.422862, -97.640183)\",10051637,Routine Inspection",
"offset": 2109798,
"source": "/Path/to/my/logs/Restaurant_Inspection_Scores.csv",
"tags": [
"debug",
"reviews"
],
"type": "log"
}
}
]
}
এবং প্রতিক্রিয়া (আমরা যে ক্ষেত্রগুলি সেট করার চেষ্টা করছিলাম সেগুলিতে আমি এটিকে ছাঁটাই করেছি):
{
"docs": [
{
"doc": {
"_id": "AVpsUYR_du9kwoEnKsSA",
"_type": "log",
"_index": "inspections",
"_source": {
"InspectionType": "Routine Inspection",
"ZipCode": "78660",
"InspectionMonth": "10",
"City": "AUSTIN",
"message": "Wieland Elementary,78660,10/02/2014,100,\"900 TUDOR HOUSE RD\nAUSTIN, TX 78660\n(30.422862, -97.640183)\",10051637,Routine Inspection",
"RestaurantName": "Wieland Elementary",
"FacilityID": "10051637",
"Score": 100,
"StreetAddress": "900 TUDOR HOUSE RD",
"State": "TX",
"InspectionDay": "02",
"InspectionYear": "2014",
"ZipCode2": "78660",
"Location": "30.422862, -97.640183"
},
"_ingest": {
"timestamp": "2017-03-31T20:36:59.574+0000"
}
}
}
]
}
পাইপলাইনটি অবশ্যই সফল হয়েছে, কিন্তু সবচেয়ে গুরুত্বপূর্ণ, সমস্ত ডেটা সঠিক জায়গায় আছে বলে মনে হচ্ছে৷
চলমান ফাইলবিট
আমরা ফাইলবিট চালানোর আগে, আমরা একটি শেষ কাজ করব। এই অংশটি সম্পূর্ণ ঐচ্ছিক যদি আপনি শুধুমাত্র ইনজেস্ট পাইপলাইনের সাথে স্বাচ্ছন্দ্য পেতে চান, কিন্তু আপনি যদি অবস্থান ক্ষেত্রটি ব্যবহার করতে চান যা আমরা জিও-পয়েন্ট হিসাবে গ্রোক প্রসেসরে সেট করেছি, তাহলে আপনাকে ফাইলবিটে ম্যাপিং যোগ করতে হবে। template.json ফাইল, বৈশিষ্ট্য বিভাগে নিম্নলিখিত যোগ করে:
"Location": {
"type": "geo_point"
},
এখন যেহেতু এটির বাইরে, আমরা ./filebeat -e -c filebeat.yml -d “elasticsearch” চালিয়ে Filebeat চালু করতে পারি।
ডেটা ব্যবহার করা
GET /filebeat-*/_count
{}
{
"count": 25081,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
}
}
এটি একটি ভাল লক্ষণ! দেখা যাক আমাদের কোনো ত্রুটি ছিল কিনা:
GET /filebeat-*/_search
{
"query": {
"exists" : { "field" : "error" }
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
আরেকটি ভালো লক্ষণ!
এখন আমরা কিবানায় আমাদের ডেটা কল্পনা এবং দেখানোর জন্য প্রস্তুত। আমরা আরেকবার কিবানা ড্যাশবোর্ড তৈরি করে চলতে পারি, কিন্তু আমাদের কাছে তারিখ, রেস্তোরাঁর নাম, স্কোর এবং অবস্থান রয়েছে, আমরা কিছু দুর্দান্ত ভিজ্যুয়ালাইজেশন তৈরি করার জন্য প্রচুর স্বাধীনতা পেয়েছি।
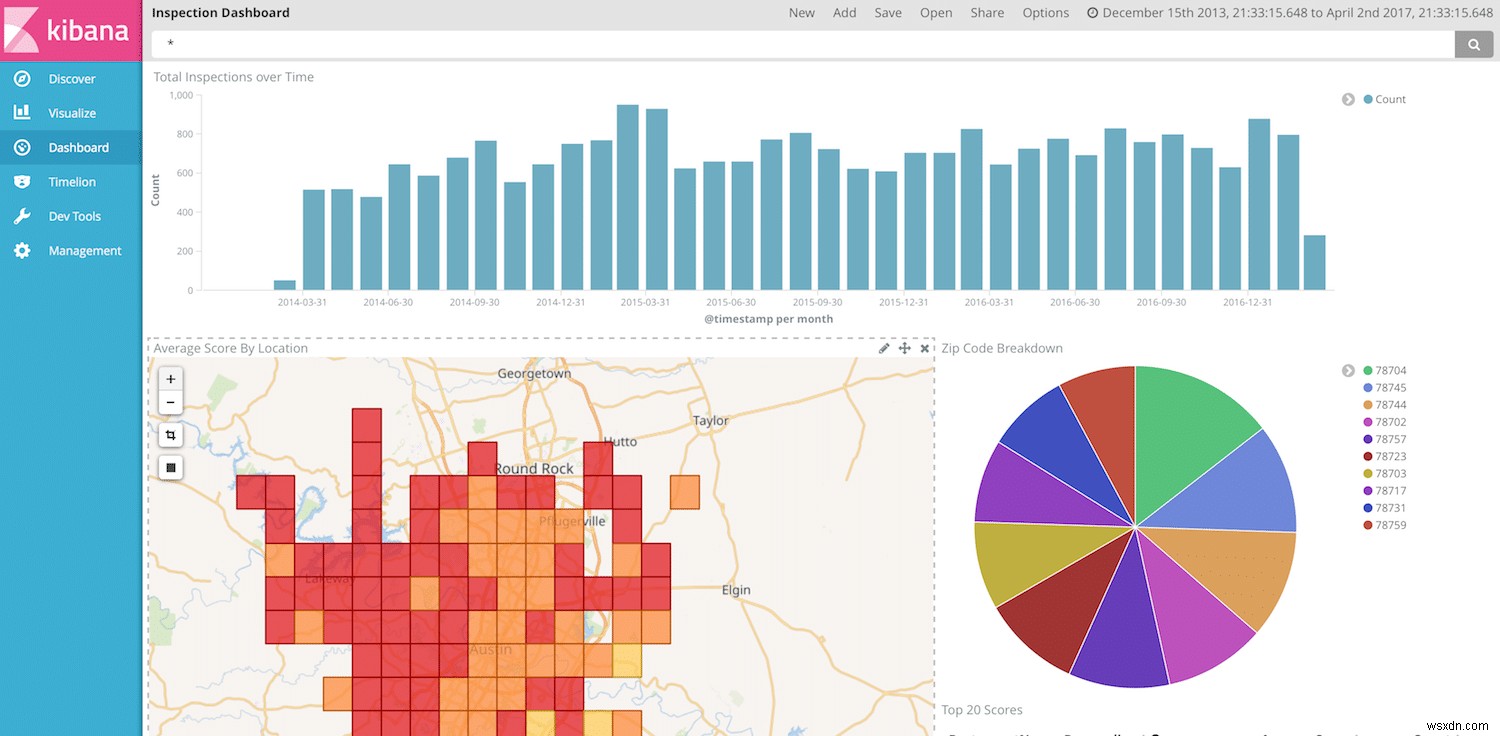
চূড়ান্ত নোট
আবার, ইনজেস্ট পাইপলাইনটি বেশ শক্তিশালী এবং রূপান্তরগুলি খুব সহজেই পরিচালনা করতে পারে। আপনি আপনার সমস্ত প্রক্রিয়াকরণ ইলাস্টিকসার্চে স্থানান্তর করতে পারেন এবং পাইপলাইনে কোথাও লগস্ট্যাশের প্রয়োজন ছাড়াই শুধুমাত্র আপনার হোস্টগুলিতে হালকা ওজনের বিট ব্যবহার করতে পারেন। যাইহোক, লগস্ট্যাশের তুলনায় ইনজেস্ট নোডে এখনও কিছু ফাঁক রয়েছে। উদাহরণস্বরূপ, ইনজেস্ট পাইপলাইনে উপলব্ধ প্রসেসরের সংখ্যা এখনও সীমিত, তাই একটি CSV পার্স করার মতো সহজ কাজগুলি Logstash-এর মতো সহজ নয়৷ ইলাস্টিকসার্চ দল নিয়মিতভাবে নতুন প্রসেসর নিয়ে আসছে বলে মনে হচ্ছে, তাই এখানে আশা করা যায় যে পার্থক্যের তালিকা আরও ছোট থেকে ছোট হতে থাকবে।
