
একটি সফ্টওয়্যার অ্যাপ্লিকেশন শুধুমাত্র মূল্যবান হিসাবে এটি তার গ্রাহকদের চাহিদা মেটাতে পারে. যখন আমরা গ্রাহকদের চাহিদা বিবেচনা করি, তখন আমরা যে প্রথম চাহিদাগুলির মুখোমুখি হই তা হল অ্যাপ্লিকেশনের গতি এবং ডেটা নির্ভরযোগ্যতা। যাইহোক, অ্যাপ্লিকেশনগুলি বিশ্বব্যাপী বৃদ্ধি এবং প্রসারিত হওয়ার সাথে সাথে, SQL ডেটাবেসগুলি প্রায়শই বর্ধিত ক্যোয়ারী ভলিউম, উচ্চতর বিলম্ব এবং ভৌগলিকভাবে ছড়িয়ে থাকা ব্যবহারকারী বেসগুলির কারণে কার্যক্ষমতার বাধা হয়ে দাঁড়ায়৷
যখন অ্যাপ্লিকেশন বৃদ্ধি পায় তখন এই সমস্যাগুলির সমাধান করার জন্য, বারবার প্রশ্নগুলির জন্য প্রাথমিক ডাটাবেসের লোড কমাতে এবং ব্যবহারকারীরা যখন প্রশ্নগুলি জমা দেয় তখন লেটেন্সি কমাতে ক্যাশিং হল প্রথম সমাধানগুলির মধ্যে একটি৷ যখন আমরা ক্যাশে সম্পর্কে কথা বলি, তখন আমাদের প্রত্যেকের জন্য একই সরঞ্জামটি মনে আসে, তাই না? হ্যাঁ, এটাই রেডিস। লোড কমাতে এবং অ্যাপ্লিকেশনগুলিকে দ্রুত করতে ডেটা ক্যাশে করার জন্য রেডিস একটি নিখুঁত সরঞ্জাম। Upstash বিশ্বব্যাপী বিতরণ করা Redis প্রতিলিপি প্রদান করে, যা অ্যাপ্লিকেশনগুলিকে এমনকি একটি নিয়মিত ক্যাশের চেয়েও দ্রুততর করে তুলবে৷
এই ব্লগে, আমরা SQL ডাটাবেসের সাথে গ্লোবাল রেডিসকে একীভূত করার প্রযুক্তিগত সুবিধাগুলি অন্বেষণ করব, লেটেন্সি এবং স্কেলেবিলিটির উপর এর প্রভাব নিয়ে আলোচনা করব এবং PostgreSQL এবং MySQL এর সাথে গ্লোবাল রেডিস ব্যবহার করার জন্য হ্যান্ড-অন উদাহরণ প্রদান করব৷
ক্যাশিংয়ের সুবিধাগুলি
আসুন প্রথমে পরীক্ষা করে দেখি কেন আমাদের ক্যাশিং ব্যবহার করা উচিত।
ক্যাশিংয়ের দুটি প্রধান সুবিধা রয়েছে যা আমি এই ব্লগে উল্লেখ করতে চাই:ডাটাবেস লোড হ্রাস করা এবং ব্যবহারকারীদের লেটেন্সি হ্রাস করা৷
ডাটাবেস লোড কমানো
এসকিউএল ডাটাবেসগুলি স্ট্রাকচার্ড ডেটা এবং জটিল প্রশ্নগুলি পরিচালনা করতে পারদর্শী, কিন্তু ভারী লোডের মধ্যে, তারা একটি বাধা হয়ে উঠতে পারে। একই ডেটার জন্য উচ্চ পরিমাণে বারবার কোয়েরি- যেমন পণ্যের বিবরণ, ব্যবহারকারীর প্রোফাইল, বা ঘন ঘন অ্যাক্সেস করা সেটিংস- উল্লেখযোগ্য CPU এবং I/O সংস্থানগুলি ব্যবহার করে। এই ফলাফলগুলি ক্যাশ করার মাধ্যমে, ডেটাবেসকে আঘাতকারী প্রশ্নের সংখ্যা ব্যাপকভাবে হ্রাস পেয়েছে, যা ডাটাবেসকে লেনদেন প্রক্রিয়াকরণ এবং আপডেটের মতো আরও জটিল কাজগুলিতে ফোকাস করার অনুমতি দেয়৷
যেমন:
- ক্যাশিং ছাড়াই:একটি ওয়েবসাইটে একটি জনপ্রিয় বৈশিষ্ট্য প্রতিদিন লক্ষ লক্ষ অভিন্ন ডাটাবেস কোয়েরি তৈরি করে, অন্যান্য ক্রিয়াকলাপের জন্য কর্মক্ষমতা কমিয়ে দেয়৷
- ক্যাশিংয়ের সাথে:প্রায়শই অ্যাক্সেস করা প্রশ্নের ফলাফলগুলি রেডিসের মতো একটি উচ্চ-গতির ক্যাশে সংরক্ষণ করা হয়, যা ডাটাবেস কোয়েরির হার 90% এর বেশি হ্রাস করে।
লেটেন্সি কমানো
ডাটাবেস লোড হ্রাস করা ছিল সিস্টেমের স্বাস্থ্যের জন্য ডেটা নির্ভরযোগ্যতা নিশ্চিত করার জন্য। ক্যাশিং ব্যবহারকারীর অনুরোধ এবং অনুসন্ধানের সময়কে উন্নত করে।
যখন অ্যাপ্লিকেশনগুলি একই ডেটার জন্য ডাটাবেসকে বারবার জিজ্ঞাসা করে, তখন ডেটা পুনরুদ্ধার সর্বদা দীর্ঘ সময় নেয়। বিশেষ করে যদি এই প্রশ্নগুলি ডাটাবেসের উপর একটি বড় লোড তৈরি করে, এই সমস্ত বিলম্ব আরও বাড়তে পারে। রিয়েল-টাইম ডেটা অ্যাক্সেস বা উচ্চ ক্যোয়ারী ভলিউম পরিচালনার প্রয়োজন হয় এমন অ্যাপ্লিকেশনগুলির জন্য এটি বিশেষত সমস্যাযুক্ত, যেখানে এমনকি ছোট বিলম্বও কার্যকারিতাকে উল্লেখযোগ্যভাবে প্রভাবিত করতে পারে৷
ক্যাশিং মেমরিতে ঘন ঘন অ্যাক্সেস করা ডেটা সঞ্চয় করে এই সমস্যার সমাধান করে, যা ডেটাবেস অনুসন্ধান করার চেয়ে পুনরুদ্ধার করা অনেক দ্রুত। বারবার অনুরোধের জন্য ডাটাবেস কোয়েরির উপর নির্ভরতা হ্রাস করে, ক্যাশিং নেটওয়ার্ক ভ্রমণকে হ্রাস করে এবং জটিল প্রশ্নগুলি চালানোর গণনাগত ওভারহেড এড়ায়। ফলস্বরূপ, প্রতিক্রিয়ার সময়গুলি নাটকীয়ভাবে উন্নত হয়, অ্যাপ্লিকেশনগুলিকে আরও দ্রুত, আরও সামঞ্জস্যপূর্ণ কার্যকারিতা প্রদান করতে সক্ষম করে, এমনকি ভারী বোঝার মধ্যেও বা বিতরণ করা পরিবেশে৷
সাধারণ ক্যাশিং কৌশলগুলি
অ্যাপ্লিকেশন পারফরম্যান্স অপ্টিমাইজেশানে ব্যবহৃত দুটি প্রাথমিক ক্যাশিং কৌশলগুলি বোঝাও গুরুত্বপূর্ণ:ক্যাশে-সাইড এবং লেখার মাধ্যমে . অ্যাপ্লিকেশনের প্রয়োজনীয়তার উপর নির্ভর করে প্রতিটি পদ্ধতির তার ব্যবহারের ক্ষেত্রে এবং ট্রেড-অফ রয়েছে।
ক্যাশে-একপাশে সবচেয়ে সাধারণ ক্যাশিং কৌশল। এই কৌশলে, অ্যাপ্লিকেশনটি প্রথমে ডেটার জন্য ক্যাশে পরীক্ষা করে। যদি ডেটা ক্যাশে না থাকে (ক্যাশে মিস), এটি ডাটাবেস থেকে ডেটা পুনরুদ্ধার করে এবং ভবিষ্যতে ব্যবহারের জন্য ক্যাশে লিখে দেয়।
এখানে একটি সাধারণ ডায়াগ্রাম রয়েছে যা দেখায় যে কীভাবে ক্যাশে-সাইড কাজ করে, যা আপনি সবাই এই ব্লগে আসার আগে কোথাও দেখেছেন।

এই ক্যাশিংয়ের সুবিধা হল ক্যাশের আকার অপ্টিমাইজ করা হয় এবং ব্যবহারকারীদের প্রয়োজন হলে ক্যাশে ডেটা পুনরায় লোড করা হয়। অন্যদিকে, অসুবিধা হল যে ক্যাশে পরিষ্কার করার পরে TTL শেষ হয়ে গেলে ডেটা পাওয়া যাবে না। সেই সময়ে, ব্যবহারকারী সেই ডেটার অনুরোধ করলে ক্যাশে পুনরায় লোড করা হবে। এই ক্ষেত্রে, সেই ব্যবহারকারীকে ক্যোয়ারী করার জন্য অপেক্ষা করতে হবে। তবে অবশ্যই, পরবর্তী অনুরোধগুলি আবার ক্যাশে থেকে ডেটা পেতে সক্ষম হবে।
লেখার মাধ্যমে কৌশল, ডাটাবেসের প্রতিটি লেখার অপারেশন অবিলম্বে ক্যাশেও লেখা হয়। এটি নিশ্চিত করে যে ডাটাবেস থেকে সর্বশেষ ডেটার সাথে ক্যাশে সর্বদা আপ-টু-ডেট থাকে।
এখানে রাইট-থ্রু ক্যাশিং-এর একটি সাধারণ ডায়াগ্রাম রয়েছে:

এই কৌশলটি ক্যাশে এবং ডাটাবেসের মধ্যে ডেটা সামঞ্জস্যতা নিশ্চিত করে এবং কোনও অনুরোধই উচ্চতর লেটেন্সি অনুভব করে না কারণ ব্যবহারকারীর অনুরোধের জন্য অপেক্ষা না করে ডেটা ইতিমধ্যেই উপলব্ধ হবে। যাইহোক, অসুবিধা হল ক্যাশে সমস্ত ডেটা ধারণ করে, এমনকি এটি প্রয়োজন না হলেও। এটি ছাড়াও, প্রতিটি লেখার ক্রিয়াকলাপ লেটেন্সি লাভ করবে যেহেতু ডেটা ক্যাশেও লেখা হবে৷
গ্লোবাল রেডিস কি? গ্লোবাল রেডিস
এর সুবিধাএসকিউএল ডাটাবেসের পারফরম্যান্সকে কীভাবে আরও উন্নত করা যায় তা এখন তদন্ত করা যাক।
লেটেন্সির আরেকটি উৎস হল ডাটাবেসের অবস্থান। বেশিরভাগ ক্ষেত্রে, প্রাথমিক ডাটাবেস নির্দিষ্ট অঞ্চলে অবস্থিত। যাইহোক, ডেটা কাছাকাছি অবস্থানে পৌঁছানো উচিত যাতে আমরা ডেটা স্টোরের দূরত্বের কারণে বিলম্ব কমাতে পারি।
Upstash দ্বারা সরবরাহিত বিশ্বব্যাপী বিতরণ করা Redis ব্যবহার করে এই সমস্যাটি প্রতিরোধ করা যেতে পারে।
গ্লোবাল রেডিস হল একটি বিতরণ করা ক্যাশিং সমাধান যা একাধিক ভৌগলিক অবস্থান জুড়ে ডেটা প্রতিলিপি করে, বিশ্বব্যাপী বিতরণ করা অ্যাপ্লিকেশনগুলির জন্য কম লেটেন্সি অ্যাক্সেস নিশ্চিত করে৷
আসুন দ্রুত দেখি কিভাবে গ্লোবাল রেডিস তৈরি করা যায়। প্রথমে, Upstash কনসোলে লগইন করুন।
লগইন করার পর, আমরা এখানে একটি Redis ডাটাবেস তৈরি করতে পারি। আপস্ট্যাশ পঠিত প্রতিলিপিগুলি সনাক্ত করতে একাধিক অবস্থান সরবরাহ করে৷
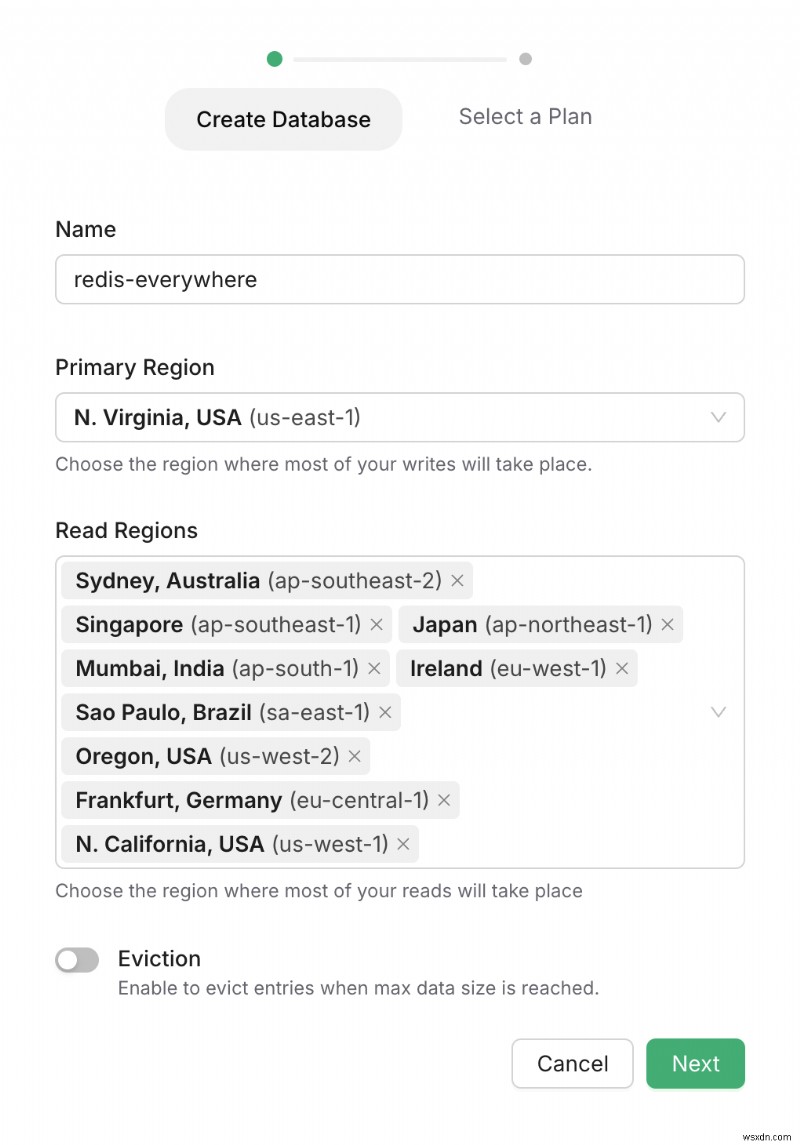
একবার পঠিত অবস্থানগুলি নির্বাচন করার পরে, আপনি আপনার পরিকল্পনা নির্বাচন করতে পারেন এবং অবশেষে আপনার রেডিস ডাটাবেস তৈরি করতে পারেন। এটাই সব!
কনসোলে, আপনি ডাটাবেস তৈরি করার পরেও অঞ্চল যোগ/মুছে ফেলতে পারেন।

গ্লোবাল রেডিস ডাটাবেসগুলি বেশিরভাগ অ্যাপ্লিকেশন দ্বারা ব্যবহৃত হয় যেগুলি বিশ্বব্যাপী বিতরণ করা হয় এবং যে অ্যাপ্লিকেশনগুলি প্রান্তে চলছে৷
বিশ্বব্যাপী বিতরণ করা অ্যাপ্লিকেশনের জন্য কম বিলম্ব
বিশ্বব্যাপী বিতরণ করা সিস্টেমে, ব্যবহারকারী এবং কেন্দ্রীয় ডাটাবেস বা ক্যাশের মধ্যে শারীরিক দূরত্বের কারণে প্রায়ই লেটেন্সি একটি বাধা হয়ে দাঁড়ায়। গ্লোবাল রেডিস একাধিক ভৌগলিকভাবে বিতরণ করা নোড জুড়ে ডেটা প্রতিলিপি করে এটির সমাধান করে৷
যখন একজন ব্যবহারকারী ডেটার অনুরোধ করেন, তখন নিকটতম ক্যাশে নোড অনুরোধটি পরিবেশন করে, যা নেটওয়ার্ক ভ্রমণের সময়কে ব্যাপকভাবে হ্রাস করে। এই স্থানীয় অ্যাক্সেস ব্যবহারকারীর অবস্থান নির্বিশেষে দ্রুত প্রতিক্রিয়ার সময় এবং একটি সামঞ্জস্যপূর্ণ ব্যবহারকারীর অভিজ্ঞতা নিশ্চিত করে৷
ধরা যাক, যদি কোনো ব্যবহারকারী টোকিওতে অবস্থিত, কিন্তু ডাটাবেসটি ডাবলিনে থাকে, তবে দূরত্ব ব্যবহারকারীর প্রতিক্রিয়া দেরি করবে। যদি ইউরোপে আপস্ট্যাশ রেডিসের একটি পঠিত প্রতিরূপ থাকে, তাহলে অনুরোধটি নিকটতম পঠিত প্রতিলিপিতে পাঠানো যেতে পারে, যা এই ক্ষেত্রে ইউরোপের একটি।
এজ রানটাইমের জন্য কম লেটেন্সি ডেটা (যেমন ক্লাউডফ্লেয়ার ওয়ার্কার)
এজ রানটাইম হল নেটওয়ার্কের প্রান্তে, শেষ ব্যবহারকারীর কাছাকাছি কোড চালানোর জন্য ডিজাইন করা পরিবেশ। এজ রানটাইম বিশ্বব্যাপী একাধিক প্রান্ত অবস্থান জুড়ে অ্যাপ্লিকেশন লজিক বিতরণ করে। এই স্থাপত্যটি ব্যবহারকারীদের মধ্যে শারীরিক দূরত্ব কমিয়ে দেয় এবং তাদের অনুরোধগুলি কার্যকর করে, উল্লেখযোগ্যভাবে বিলম্ব কমায় এবং কর্মক্ষমতা উন্নত করে৷
যদিও এজ রানটাইমগুলি কম্পিউটেশনকে ব্যবহারকারীদের কাছাকাছি নিয়ে আসে, তাদের এখনও বেশিরভাগ ক্রিয়াকলাপের জন্য ডেটা অ্যাক্সেসের প্রয়োজন হয়, যেমন ব্যবহারকারী-নির্দিষ্ট তথ্য পুনরুদ্ধার করা, সেশন টোকেন বা কনফিগারেশন। একটি ক্যাশিং স্তর ছাড়া, প্রতিটি অনুরোধের জন্য এখনও একটি কেন্দ্রীয় ডাটাবেসে একটি রাউন্ড ট্রিপ প্রয়োজন, যা অনেকটাই লেটেন্সি সুবিধাকে অস্বীকার করে৷ এখানেই গ্লোবাল রেডিস একটি গুরুত্বপূর্ণ ভূমিকা পালন করে, কারণ তারা প্রায়শই ব্যবহৃত ডেটা প্রান্তে প্রতিলিপি করে, কম লেটেন্সি অ্যাক্সেস নিশ্চিত করে।
উদাহরণ কোড 1:Node.js সহ PostgreSQL
গ্লোবাল রেডিসের সাথে ক্যাশিং নিখুঁত। এখন, আমরা একটি কোড নমুনা দেখতে পাব যা আপস্ট্যাশ রেডিস এবং একটি Postgresql ডাটাবেসের সাথে ক্যাশে-সাইড কৌশল প্রয়োগ করে৷
আমাদের প্রথমে SDK গুলি ইনস্টল করা উচিত যা আমরা ডেটা স্টোরের সাথে সংযোগ করতে ব্যবহার করব৷
৷npm install pg upstash/redis
একবার আমাদের নির্ভরতা ইনস্টল করা হয়ে গেলে, আমরা ডেটা স্টোর, Upstash Redis এবং Postgres-এর সাথে সংযোগ করতে পারি।
const { Redis } = require('@upstash/redis'); // Upstash Redis SDK
const { Client } = require('pg');
const redis = new Redis({
url: <UPSTASH_REDIS_REST_URL>,
token: <UPSTASH_REDIS_REST_TOKEN>,
})
const client = new Client({
user: 'username',
password: 'password',
host: 'host',
port: 'port_number',
database: 'database_name',
});
client.connect();এখন আমাদের ডেটা অ্যাক্সেস লেয়ারে ফাংশনটি লিখি। এই ফাংশন আপনার প্রয়োজন অনুযায়ী পরিবর্তন করা যেতে পারে.
ধরা যাক আমরা userId দ্বারা আমাদের ওয়েবসাইটে ব্যবহারকারীর তথ্য দেখাতে চাই। এই ক্ষেত্রে, আমাদের একটি ফাংশন থাকা উচিত যা পরামিতি হিসাবে userId পায়
async function getUserData(userId) {
// Check cache first
const cachedData = await redis.get(userId);
if (cachedData) {
console.log('Cache hit');
return JSON.parse(cachedData);
}
// Fallback to database
console.log('Cache miss');
const query = 'SELECT * FROM users WHERE id = $1';
const { rows } = await client.query(query, [userId]);
await redis.set(userId, JSON.stringify(rows), { EX: 300 }); // Cache for 5 minutes
return rows;
}এখানে এটা! এখন এই ফাংশনটি প্রথমে পরীক্ষা করবে যে ব্যবহারকারীর তথ্য অনুরোধকারীর অঞ্চলের নিকটতম রেডিস ডাটাবেসে উপলব্ধ কিনা। এটি উপলব্ধ না হলে, এটি Postgresql ডাটাবেস থেকে অনুরোধ করা ডেটা জিজ্ঞাসা করবে এবং ফিরিয়ে দেওয়া ডেটা Upstash Redis প্রাথমিক অঞ্চলে লিখবে৷ প্রাথমিক অঞ্চলে লেখা ডেটা স্বয়ংক্রিয়ভাবে সমস্ত পঠিত প্রতিলিপিতে অনুলিপি করা হবে।
উদাহরণ কোড 2:Python সহ MYSQL
এখন, আরেকটি উদাহরণ দেখা যাক। এইবার, আমরা একই ক্যাশে বাস্তবায়ন করব, তবে মূল ডাটাবেস হবে এইবার MYSQL। এছাড়াও, পাইথন-ভিত্তিক অ্যাপ্লিকেশনগুলিতে এটি কীভাবে কাজ করে তা দেখতে আমরা পাইথনে এই ফাংশনটি লিখব৷
যথারীতি, আমরা সেই নির্ভরতাগুলি ডাউনলোড করব যা আমরা প্রথমে ডাটাবেস সংযোগের জন্য ব্যবহার করব।
pip install upstash-redis upstash-redis
এখন, আমরা ক্লায়েন্ট শুরু করতে পারি এবং তাদের সাথে সংযোগ করতে পারি।
import upstash_redis
import mysql.connector
import json
# Initialize Upstash Redis client
redis_client = upstash_redis.Redis(
url='<your-upstash-redis-url>',
token='<your-upstash-token>'
)
# Initialize MySQL client
db = mysql.connector.connect(
host="<your-mysql-host>",
user="<your-mysql-user>",
password="<your-mysql-password>",
database="<your-database-name>"
)
cursor = db.cursor(dictionary=True)সংযোগ প্রস্তুত. এখন আমরা একই ফাংশন বাস্তবায়ন করব যা আমরা পূর্ববর্তী বিভাগে প্রয়োগ করেছি।
def get_user_data(userId):
# Check the cache for the data
cache_data = redis_client.get(key)
if cache_data:
print("Cache hit")
return json.loads(cache_data)
# If cache miss, query the MySQL database
print("Cache miss")
cursor.execute("SELECT * FROM users WHERE key = %s", (userId))
result = cursor.fetchone()
if result:
# Store the data in the cache with a TTL of 1 hour
redis_client.set(key, json.dumps(result), ex=3600)
return resultউপসংহার
আপনার আর্কিটেকচারে গ্লোবাল রেডিসকে একীভূত করার মাধ্যমে, আপনি SQL-ভিত্তিক অ্যাপ্লিকেশনের জন্য উল্লেখযোগ্য কর্মক্ষমতা অর্জন করতে পারেন, বিশেষ করে বিশ্বব্যাপী বিতরণ করা পরিবেশে। কম লেটেন্সি অ্যাক্সেস, ডাটাবেস লোড হ্রাস এবং প্রান্ত রানটাইমের সাথে সামঞ্জস্যের সাথে, গ্লোবাল রেডিস এসকিউএল ডাটাবেসগুলির সাথে অ্যাপ্লিকেশনগুলির পারফরম্যান্স চ্যালেঞ্জ মোকাবেলা করতে পারে৷
এই ব্লগ পোস্টে, আমরা গ্লোবাল রেডিসের সাথে ক্যাশে করার সুবিধাগুলি দেখেছি এবং কিছু উদাহরণ পরীক্ষা করেছি। এগুলি কেবলমাত্র মৌলিক উদাহরণ যা আপনার প্রয়োজনের উপর নির্ভর করে আরও বাড়ানো যেতে পারে৷
আমি আশা করি এই ব্লগটি বিশ্বব্যাপী Redis-এর শক্তিকে কাজে লাগানোর জন্য আপনার জন্য একটি ভাল সূচনা হতে পারে৷
৷