
এই নিবন্ধে, আমি একটি সাধারণ ওয়েব ব্যবহারের ক্ষেত্রে তিনটি সার্ভারহীন ডাটাবেস DynamoDB, FaunaDB, Upstash (Redis) এর বিলম্বের তুলনা করব৷
আমি একটি নমুনা সংবাদ ওয়েবসাইট তৈরি করেছি এবং আমি ওয়েবসাইটের প্রতিটি অনুরোধের সাথে ডেটাবেস সম্পর্কিত লেটেন্সি রেকর্ড করছি। ওয়েবসাইট এবং সোর্স কোড চেক করুন।
আমি প্রতিটি ডাটাবেসে 7001 এনওয়াই টাইমস নিবন্ধ সন্নিবেশ করেছি। নিবন্ধগুলি নিউ ইয়র্ক টাইমস আর্কাইভ API (জানুয়ারী 2021 এর সমস্ত নিবন্ধ) থেকে সংগ্রহ করা হয়েছে। আমি এলোমেলোভাবে প্রতিটি নিবন্ধ স্কোর. প্রতিটি পৃষ্ঠার অনুরোধে, আমি World-এর অধীনে সেরা 10টি নিবন্ধ অনুসন্ধান করি প্রতিটি ডাটাবেস থেকে বিভাগ।
আমি প্রতিটি ডাটাবেস থেকে নিবন্ধগুলি লোড করতে সার্ভারহীন ফাংশন (AWS Lambda) ব্যবহার করি। 10টি নিবন্ধ আনার প্রতিক্রিয়া সময় ল্যাম্বডা ফাংশনের ভিতরে লেটেন্সি হিসাবে রেকর্ড করা হচ্ছে। নোট করুন যে রেকর্ড করা লেটেন্সি শুধুমাত্র ল্যাম্বডা ফাংশন এবং ডাটাবেসের মধ্যে। এটি আপনার ব্রাউজার এবং সার্ভারের মধ্যে লেটেন্সি নয়৷
৷প্রতিটি পড়ার অনুরোধের পরে, আমি গতিশীল ডেটা অনুকরণ করতে এলোমেলোভাবে স্কোরগুলি আপডেট করি। কিন্তু আমি এই অংশটিকে লেটেন্সি গণনা থেকে বাদ দিচ্ছি।
প্রথমে আমরা আবেদন পরীক্ষা করব, তারপর ফলাফল দেখব:
AWS Lambda সেটআপ
অঞ্চল:US-West-1
মেমরি:1024Mb
রানটাইম:nodejs14.x
DynamoDB সেটআপ
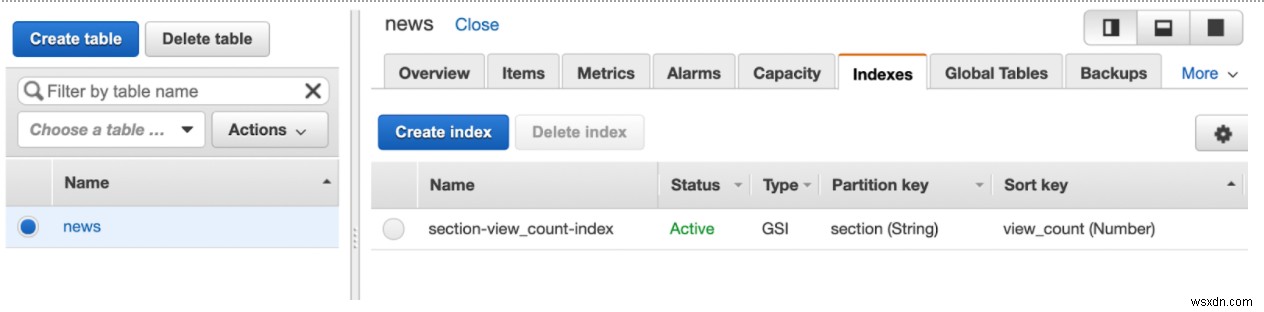
আমি US-West-1-এ একটি DynamoDB টেবিল তৈরি করেছি যাতে 50 পড়ার এবং লেখার ক্ষমতা ছিল (ডিফল্ট মান ছিল 5)।
আমার সূচী হল পার্টিশন কী section (String) সহ GSI এবং বাছাই কী view_count (Number) .
FaunaDB সেটআপ
FaunaDB একটি বিশ্বব্যাপী প্রতিলিপিকৃত ডাটাবেস, afaik একটি অঞ্চল নির্বাচন করার কোন উপায় নেই। আমি FQL ব্যবহার করেছি, অনুমান করছি GraphQL API এর কিছু ওভারহেড থাকতে পারে।
আমি নীচের মত শর্তাবলী বিভাগ এবং মান রেফ সহ একটি সূচক তৈরি করেছি। পারফরম্যান্সের উন্নতির আশায় আমি এটিকে নন-সিরিয়ালাইজ করেছি।
CreateIndex({
name: "section_by_view_count",
unique: false,
serialized: false,
source: Collection("news"),
terms: [
{ field: ["data", "section"] }
],
values: [
{ field: ["data", "view_count"], reverse: true },
{ field: ["ref"] }
]
})
Redis সেটআপ
৷
আমি Upstash-এ US-West-1 অঞ্চলে একটি স্ট্যান্ডার্ড টাইপ ডাটাবেস তৈরি করেছি। আমি প্রতিটি সংবাদ বিভাগে একটি সাজানো সেট ব্যবহার করেছি। তাই সমস্ত World সংবাদ নিবন্ধগুলি কী World দিয়ে সাজানো সেটে থাকবে .
ডাটাবেস শুরু করুন
আমি NYTimes API সাইট থেকে JSON ফাইল হিসাবে 7001 সংবাদ নিবন্ধগুলি ডাউনলোড করেছি, তারপর প্রতিটি ডাটাবেস প্রতি একটি NodeJS স্ক্রিপ্ট তৈরি করেছি যা JSON পড়ে এবং ডেটাবেসে সংবাদ রেকর্ড সন্নিবেশ করে। ফাইলগুলি দেখুন:initDynamo.js, initFauna.js, initRedis.js
কোয়েরি ডায়নামোডিবি
৷
আমি DynamoDB এর সাথে সংযোগ করতে AWS SDK ব্যবহার করেছি। বিলম্ব কমাতে, আমি DynamoDB সংযোগটিকে জীবিত রাখছি। আমি perf_hooks ব্যবহার করেছি প্রতিক্রিয়া সময় পরিমাপ করতে লাইব্রেরি। আমি শীর্ষ 10টি নিবন্ধের জন্য DynamoDB-কে জিজ্ঞাসা করার ঠিক আগে বর্তমান সময় রেকর্ড করি। আমি DynamoDB থেকে প্রতিক্রিয়া পাওয়ার সাথে সাথে লেটেন্সি গণনা করেছি। তারপরে আমি এলোমেলোভাবে নিবন্ধগুলি স্কোর করি এবং একটি Redis সাজানো সেটে লেটেন্সি নম্বর সন্নিবেশ করি তবে এই অংশগুলি লেটেন্সি গণনা অংশের বাইরে। নিচের কোডটি দেখুন:
var AWS = require("aws-sdk");
AWS.config.update({
region: "us-west-1",
});
const https = require("https");
const agent = new https.Agent({
keepAlive: true,
maxSockets: Infinity,
});
AWS.config.update({
httpOptions: {
agent,
},
});
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const tableName = "news";
var params = {
TableName: tableName,
IndexName: "section-view_count-index",
KeyConditionExpression: "#sect = :section",
ExpressionAttributeNames: {
"#sect": "section",
},
ExpressionAttributeValues: {
":section": process.env.SECTION,
},
Limit: 10,
ScanIndexForward: false,
};
const docClient = new AWS.DynamoDB.DocumentClient();
module.exports.load = (event, context, callback) => {
let start = performance.now();
docClient.query(params, (err, result) => {
if (err) {
console.error(
"Unable to scan the table. Error JSON:",
JSON.stringify(err, null, 2)
);
} else {
// response is ready so we can set the latency
let latency = performance.now() - start;
let response = {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: result,
}),
};
// we are setting random score to top-10 items to simulate real time dynamic data
result.Items.forEach((item) => {
let view_count = Math.floor(Math.random() * 1000);
var params2 = {
TableName: tableName,
Key: {
id: item.id,
},
UpdateExpression: "set view_count = :r",
ExpressionAttributeValues: {
":r": view_count,
},
};
docClient.update(params2, function (err, data) {
if (err) {
console.error(
"Unable to update item. Error JSON:",
JSON.stringify(err, null, 2)
);
}
});
});
// pushing the latency to the histogram
const client = new Redis(process.env.LATENCY_REDIS_URL);
client.lpush("histogram-dynamo", latency, (resp) => {
client.quit();
callback(null, response);
});
}
});
};
কোয়েরি FaunaDB
৷
আমি faunadb ব্যবহার করেছি FaunaDB সংযোগ এবং অনুসন্ধানের জন্য লাইব্রেরি। বাকি অংশটি ডায়নামোডিবি কোডের সাথে খুব মিল। বিলম্ব কমাতে, আমি সংযোগটি জীবিত রাখছি। আমি perf_hooks ব্যবহার করেছি প্রতিক্রিয়া সময় পরিমাপ করতে লাইব্রেরি। আমি সেরা 10টি নিবন্ধের জন্য FaunaDB-কে জিজ্ঞাসা করার ঠিক আগে বর্তমান সময় রেকর্ড করি। FaunaDB থেকে প্রতিক্রিয়া পাওয়ার সাথে সাথে আমি লেটেন্সি গণনা করেছি। তারপর আমি এলোমেলোভাবে নিবন্ধগুলি স্কোর করি এবং একটি Redis সাজানো সেটে লেটেন্সি নম্বর পাঠাই কিন্তু এই অংশগুলি লেটেন্সি গণনার অংশের বাইরে। নিচের কোডটি দেখুন:
const faunadb = require("faunadb");
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const q = faunadb.query;
const client = new faunadb.Client({
secret: process.env.FAUNA_SECRET,
keepAlive: true,
});
const section = process.env.SECTION;
module.exports.load = async (event) => {
let start = performance.now();
let ret = await client
.query(
// the below is Fauna API for "select from news where section = 'world' order by view_count limit 10"
q.Map(
q.Paginate(q.Match(q.Index("section_by_view_count"), section), {
size: 10,
}),
q.Lambda(["view_count", "X"], q.Get(q.Var("X")))
)
)
.catch((err) => console.error("Error: %s", err));
console.log(ret);
// response is ready so we can set the latency
let latency = performance.now() - start;
const rclient = new Redis(process.env.LATENCY_REDIS_URL);
await rclient.lpush("histogram-fauna", latency);
await rclient.quit();
let result = [];
for (let i = 0; i < ret.data.length; i++) {
result.push(ret.data[i].data);
}
// we are setting random scores to top-10 items asynchronously to simulate real time dynamic data
ret.data.forEach((item) => {
let view_count = Math.floor(Math.random() * 1000);
client
.query(
q.Update(q.Ref(q.Collection("news"), item["ref"].id), {
data: { view_count },
})
)
.catch((err) => console.error("Error: %s", err));
});
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: {
Items: result,
},
}),
};
};
কোয়েরি পুনরায় করা
আমি ioredis ব্যবহার করেছি আপস্ট্যাশে Redis থেকে সংযোগ এবং পড়ার জন্য লাইব্রেরি। আমি সাজানো সেট থেকে ডেটা লোড করতে ZREVRANGE কমান্ড ব্যবহার করেছি। লেটেন্সি কমানোর জন্য, আমি ফাংশনের বাইরে Redis ক্লায়েন্ট তৈরি করে সংযোগটি পুনরায় ব্যবহার করেছি। DynamoDB এবং FaunaDB-এর মতো, আমি স্কোর আপডেট করছি এবং হিস্টোগ্রাম গণনার জন্য অন্য Redis DB-তে লেটেন্সি নম্বর পাঠাচ্ছি। কোডটি দেখুন:
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const client = new Redis(process.env.REDIS_URL);
module.exports.load = async (event) => {
let section = process.env.SECTION;
let start = performance.now();
let data = await client.zrevrange(section, 0, 9);
let items = [];
for (let i = 0; i < data.length; i++) {
items.push(JSON.parse(data[i]));
}
// response is ready so we can set the latency
let latency = performance.now() - start;
// we are setting random scores to top-10 items to simulate real time dynamic data
for (let i = 0; i < data.length; i++) {
let view_count = Math.floor(Math.random() * 1000);
await client.zadd(section, view_count, data[i]);
}
// await client.quit();
// pushing the latency to the histogram
const client2 = new Redis(process.env.LATENCY_REDIS_URL);
await client2.lpush("histogram-redis", latency);
await client2.quit();
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: {
Items: items,
},
}),
};
};
হিস্টোগ্রাম গণনা
আমি hdr-histogram-js ব্যবহার করেছি হিস্টোগ্রাম গণনা করার জন্য লাইব্রেরি। এটি গিল টেনের এইচডিআর-হিস্টোগ্রাম লাইব্রেরির একটি জেএস বাস্তবায়ন। ল্যাম্বডা ফাংশনের কোড দেখুন যা লেটেন্সি নম্বরগুলি গ্রহণ করে এবং হিস্টোগ্রাম গণনা করে৷
const Redis = require("ioredis");
const hdr = require("hdr-histogram-js");
module.exports.load = async (event) => {
const client = new Redis(process.env.LATENCY_REDIS_URL);
let dataRedis = await client.lrange("histogram-redis", 0, 10000);
let dataDynamo = await client.lrange("histogram-dynamo", 0, 10000);
let dataFauna = await client.lrange("histogram-fauna", 0, 10000);
const hredis = hdr.build();
const hdynamo = hdr.build();
const hfauna = hdr.build();
dataRedis.forEach((item) => {
hredis.recordValue(item);
});
dataDynamo.forEach((item) => {
hdynamo.recordValue(item);
});
dataFauna.forEach((item) => {
hfauna.recordValue(item);
});
await client.quit();
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify(
{
redis_min: hredis.minNonZeroValue,
dynamo_min: hdynamo.minNonZeroValue,
fauna_min: hfauna.minNonZeroValue,
redis_mean: hredis.mean,
dynamo_mean: hdynamo.mean,
fauna_mean: hfauna.mean,
redis_histogram: hredis,
dynamo_histogram: hdynamo,
fauna_histogram: hfauna,
},
null,
2
),
};
};
ফলাফল
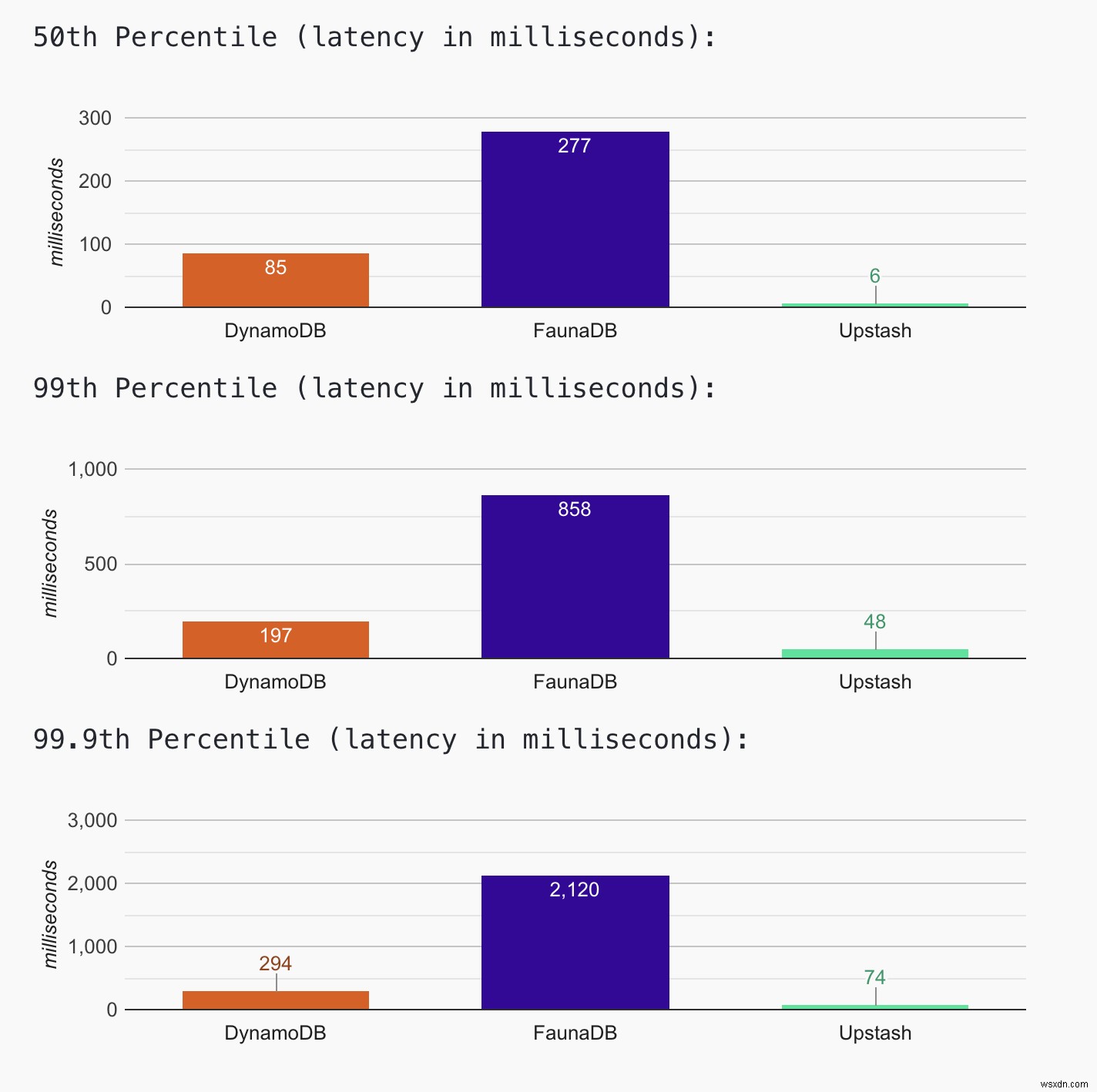
সর্বশেষ ফলাফলের জন্য ওয়েবসাইট চেক করুন. আপনি সর্বশেষ হিস্টোগ্রাম ডেটাতেও পৌঁছাতে পারেন। যতক্ষণ ওয়েবসাইটটি চালু থাকবে, ততক্ষণ আমরা ডেটা সংগ্রহ করতে এবং হিস্টোগ্রাম আপডেট করতে থাকব। আজকের ফলাফলগুলি (এপ্রিল, 12, 2021) দেখায় যে Upstash-এর সর্বনিম্ন লেটেন্সি (99 তম পার্সেন্টাইলে ~50ms) যেখানে FaunaDB-এর লেটেন্সি সর্বোচ্চ (~900ms 99th শতাংশ)। DynamoDB আছে (~200ms 99th পার্সেন্টাইলে)
কোল্ড স্টার্ট ইফেক্ট
যদিও আমরা শুধুমাত্র ক্যোয়ারী অংশের জন্য বিলম্ব পরিমাপ করি, তবুও ঠান্ডা শুরুর প্রভাব রয়েছে। আমরা ক্লায়েন্ট সংযোগ পুনরায় ব্যবহার করে আমাদের কোড অপ্টিমাইজ করি। যতক্ষণ পর্যন্ত ল্যাম্বডা পাত্রটি গরম এবং চলমান থাকে ততক্ষণ আমরা এটি থেকে উপকৃত হই। যখন AWS কন্টেইনার (কোল্ড স্টার্ট) হত্যা করে, কোডটি ক্লায়েন্টকে পুনরায় তৈরি করে, এটি একটি ওভারহেড। অ্যাপ্লিকেশন ওয়েবসাইটে, আপনি যদি পৃষ্ঠাটি রিফ্রেশ করেন; আপনি Upstash-এর জন্য লেটেন্সি সংখ্যা ~1ms-এ নেমে দেখতে পাবেন; এবং DynamoDB এর জন্য ~7ms।
কেন FaunaDB ধীর (এই বেঞ্চমার্কে)?
FaunaDB-এর স্ট্যাটাস পেজে, আপনি শত শত লেটেন্সি নম্বর দেখতে পাবেন। তাই আমি অনুমান করি আমার কনফিগারেশনে বড় ত্রুটি নেই। এই লেটেন্সি পার্থক্যের পিছনে দুটি কারণ থাকতে পারে:
দৃঢ় ধারাবাহিকতা: ডিফল্টরূপে, DynamoDB এবং Upstash উভয়ই পড়ার জন্য চূড়ান্ত ধারাবাহিকতা প্রদান করে। FaunaDB ক্যালভিন ভিত্তিক শক্তিশালী ধারাবাহিকতা এবং বিচ্ছিন্নতা প্রদান করে। পারফরম্যান্স ওভারহেডের সাথে শক্তিশালী ধারাবাহিকতা আসে।
বিশ্বব্যাপী প্রতিলিপি: Upstash এবং DynamoDB উভয়ের জন্য, আমরা একই AWS অঞ্চলে ডাটাবেস এবং ল্যাম্বডা ফাংশন কনফিগার করতে সক্ষম। FaunaDB-তে, আপনার ডেটা সারা বিশ্বে প্রতিলিপি করা হয়; তাই আপনার অঞ্চল বাছাই করার বিকল্প নেই। যদি আপনার ডাটাবেস ক্লায়েন্ট সারা বিশ্বে অবস্থিত থাকে তবে এটি একটি সুবিধা হতে পারে। কিন্তু যদি আপনি একটি নির্দিষ্ট অঞ্চলে আপনার ব্যাকএন্ড স্থাপন করেন, তাহলে এটি অতিরিক্ত লেটেন্সি সৃষ্টি করে৷
৷Redis সাব মিলিসেকেন্ড লেটেন্সি দেয়৷ এখানে কেন এটা হয় না?
AWS Lambda ফাংশনে একটি নতুন Redis সংযোগ তৈরি করা একটি উল্লেখযোগ্য ওভারহেড সৃষ্টি করে। যেহেতু অ্যাপ্লিকেশনটি একটি স্থিতিশীল ট্রাফিক পায় না, তাই AWS Lambda বেশিরভাগ সময় সংযোগ (কোল্ড স্টার্ট) পুনরায় তৈরি করে। সুতরাং হিস্টোগ্রামের বেশিরভাগ লেটেন্সি সংখ্যার মধ্যে সংযোগ তৈরির সময় অন্তর্ভুক্ত রয়েছে। আমরা একটি কাজ চালাই যা প্রতি 15 সেকেন্ডে ওয়েবসাইটটি নিয়ে আসে; আমরা দেখেছি যে Upstash-এর লেটেন্সি ~1ms এ কমে গেছে। আপনি যদি পৃষ্ঠাটি রিফ্রেশ করেন, আপনি একই রকম প্রভাব দেখতে পাবেন। কম বিলম্বের জন্য কীভাবে আপনার সার্ভারহীন অ্যাপ্লিকেশনগুলিকে অপ্টিমাইজ করবেন তার জন্য আমাদের ব্লগ পোস্টটি দেখুন৷
৷শীঘ্রই আসছে
৷Upstash শীঘ্রই প্রিমিয়াম পণ্যটি প্রকাশ করবে যেখানে ডেটা একাধিক প্রাপ্যতা অঞ্চলে প্রতিলিপি করা হয়েছে। জোন প্রতিলিপির প্রভাব দেখতে আমি এটি যোগ করব।
টুইটার বা ডিসকর্ডে আপনার প্রতিক্রিয়া আমাদের জানান।
আপডেট
৷আমার ব্যাঞ্চমার্ক এবং প্রাণীজগতের কর্মক্ষমতা সম্পর্কে হ্যাকারনিউজে একটি সক্রিয় আলোচনা ছিল। আমি পরামর্শ প্রয়োগ করেছি এবং FaunaDB অ্যাপ্লিকেশন পুনরায় চালু করেছি। সেজন্য, হিস্টোগ্রামে FaunaDB রেকর্ডের সংখ্যা অন্যদের তুলনায় কম।
