
লজিস্টিক রিগ্রেশন বাইনারি ফলাফলের পূর্বাভাস দেওয়ার একটি পরিসংখ্যানগত কৌশল। এটি একটি নতুন বিষয় নয় কারণ এটি বর্তমানে ফাইন্যান্স থেকে মেডিসিন থেকে ক্রিমিনোলজি এবং অন্যান্য সামাজিক বিজ্ঞানের ক্ষেত্রে প্রয়োগ করা হচ্ছে৷
এই বিভাগে আমরা পাইথন ব্যবহার করে লজিস্টিক রিগ্রেশন ডেভেলপ করতে যাচ্ছি, যদিও আপনি R এর মতো অন্যান্য ভাষা ব্যবহার করে একই কাজ করতে পারেন।
ইনস্টলেশন
আমরা আমাদের উদাহরণ প্রোগ্রামে নীচের লাইব্রেরিগুলি ব্যবহার করতে যাচ্ছি,
-
নম্পি :সংখ্যাসূচক অ্যারে এবং ম্যাট্রিক্স সংজ্ঞায়িত করতে
-
পান্ডা :ডেটা পরিচালনা ও পরিচালনা করতে
-
পরিসংখ্যান মডেল :প্যারামিটার অনুমান এবং পরিসংখ্যান পরীক্ষা পরিচালনা করতে
-
Pylab :প্লট তৈরি করতে
আপনি CLI-তে নীচের কমান্ডটি চালিয়ে পিপ ব্যবহার করে উপরের লাইব্রেরিগুলি ইনস্টল করতে পারেন।
>পিপ ইন্সটল নাম্পি পান্ডাস স্ট্যাটস মডেল
লজিস্টিক রিগ্রেশনের উদাহরণ ব্যবহার কেস
পাইথনে আমাদের লজিস্টিক রিগ্রেশন পরীক্ষা করার জন্য, আমরা UCLA (ইন্সটিটিউট ফর ডিজিটাল রিসার্চ অ্যান্ড এডুকেশন) দ্বারা প্রদত্ত লগিট রিগ্রেশন ডেটা ব্যবহার করতে যাচ্ছি। আপনি নীচের লিঙ্ক থেকে csv ফর্ম্যাটে ডেটা অ্যাক্সেস করতে পারেন:https://stats.idre.ucla.edu/stat/data/binary.csv
আমি এই সিএসভি ফাইলটি আমার স্থানীয় মেশিনে সংরক্ষণ করেছি এবং সেখান থেকে ডেটা পড়ব, আপনি যে কোনওটি করতে পারেন। এই csv ফাইলের সাহায্যে আমরা স্নাতক স্কুলে ভর্তিকে প্রভাবিত করতে পারে এমন বিভিন্ন কারণ চিহ্নিত করতে যাচ্ছি৷
প্রয়োজনীয় লাইব্রেরি আমদানি করুন এবং ডেটাসেট লোড করুন
আমরা পান্ডাস লাইব্রেরি (pandas.read_csv):
ব্যবহার করে ডেটা পড়তে যাচ্ছিpdimport statsmodels.api হিসাবে smimport pylab হিসাবে plimport numpy হিসাবে npdf =pd.read_csv('binary.csv')# আমরা \# df =pd.read_csv('https:) লিঙ্ক থেকে সরাসরি ডেটা পড়তে পারি //stats.idre.ucla.edu/stat/data/binary.csv')print(df.head()) আউটপুট
গ্রে জিপিএ র্যাঙ্ক0 0 380 3.61 31 1 660 3.67 32 1 800 4.00 13 1 640 3.19 44 0 520 2.93 4 স্বীকার করুন
আমরা উপরের আউটপুট থেকে দেখতে পাচ্ছি, একটি কলামের নাম হল 'র্যাঙ্ক', এটি সমস্যা তৈরি করতে পারে কারণ 'র্যাঙ্ক' পান্ডাস ডেটাফ্রেমের পদ্ধতির নামও। কোনো দ্বন্দ্ব এড়াতে, আমি র্যাঙ্ক কলামের নাম পরিবর্তন করে 'প্রতিপত্তি' করছি। তাহলে আসুন ডেটাসেট কলামের নাম পরিবর্তন করি:
df.columns =["admit", "gre", "gpa", "prestige"]print(df.columns)
আউটপুট
সূচক(['admit', 'gre', 'gpa', 'prestige'], dtype='object')এ [ ]:
এখন সবকিছু ঠিক আছে, আমরা এখন আমাদের ডেটাসেটে কী আছে তা আরও গভীরভাবে দেখতে পারি।
#ডেটা সংক্ষিপ্ত করুন
পান্ডাস ফাংশন বর্ণনা ব্যবহার করে আমরা সবকিছুর একটি সংক্ষিপ্ত দৃশ্য পাব।
প্রিন্ট(df.describe())
আউটপুট
মানা GRE জিপিএ prestigecount 400.000000 400.000000 400.000000 400.00000mean 0,317500 587,700000 3,389900 2.48500std 0,466087 115,516536 0,380567 0.94446min 0,000000 220,000000 2,260000 1,0000025% 0,000000 520,000000 3,130000 2,0000050% 0,000000 580,000000 3,395000 2,0000075% 1,000000 660,000000 3,670000 3.00000max 1,000000 800,000000 4,000000 4,00000
আমরা আমাদের ডেটার প্রতিটি কলামের স্ট্যান্ডার্ড বিচ্যুতি এবং ফ্রিকোয়েন্সি টেবিলের প্রতিপত্তি এবং কাউকে ভর্তি করা হয়েছে কিনা তা পেতে পারি।
# প্রতিটি কলামপ্রিন্ট(df.std()) এর স্ট্যান্ডার্ড বিচ্যুতি দেখে নিন
আউটপুট
0.466087gre 115.516536gpa 0.380567prestige 0.944460dtype:float64 স্বীকার করুন
উদাহরণ
# ফ্রিকোয়েন্সি টেবিল কাটিং প্রেসিটজ এবং কাউকে ভর্তি করা হয়েছে কিনা প্রিন্ট(pd.crosstab(df['admit'], df['prestige'], rownames =['admit']))
আউটপুট
প্রতিপত্তি 1 2 3 4admit0 28 97 93 551 33 54 28 12
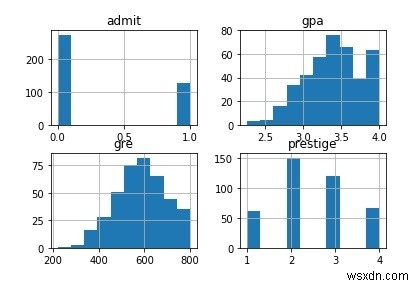
আসুন ডেটাসেটের সমস্ত কলাম প্লট করি।
# প্লট সমস্ত columnsdf.hist()pl.show()
আউটপুট
ডামি ভেরিয়েবল
পাইথন পান্ডাস লাইব্রেরি আমাদের শ্রেণীগত ভেরিয়েবলগুলিকে কীভাবে উপস্থাপন করা হয় তাতে দুর্দান্ত নমনীয়তা প্রদান করে৷
# dummify rankdummy_ranks =pd.get_dummies(df['prestige'], prefix='prestige')print(dummy_ranks.head())
আউটপুট
prestige_1 prestige_2 prestige_3 prestige_40 0 0 1 01 0 0 1 02 1 0 0 03 0 0 0 14 0 0 0 1
উদাহরণ
# regressioncols_to_keep =['admit', 'gre', 'gpa']data =df[cols_to_keep].join(dummy_ranks.ix[:, 'prestige_2':])
আউটপুট
স্বীকার করুন gre gpa prestige_2 prestige_3 prestige_40 0 380 3.61 0 1 01 1 660 3.67 0 1 02 1 800 4.00 0 0 0 03 1 640 3.19 020 3.19 020 3.19 020 3.19>রিগ্রেশন সম্পাদন করা
এখন আমরা লজিস্টিক রিগ্রেশন করতে যাচ্ছি, যা বেশ সহজ। আমরা কেবল ভেরিয়েবল সম্বলিত কলামটি নির্দিষ্ট করি যা আমরা ভবিষ্যদ্বাণী করার চেষ্টা করছি তার পরে সেই কলামগুলি যা মডেলটি ভবিষ্যদ্বাণী করতে ব্যবহার করবে৷
এখন আমরা gre, gpa এবং prestige ডামি ভেরিয়েবল prestige_2, prestige_3 এবং prestige_4 এর উপর ভিত্তি করে ভর্তি কলামের পূর্বাভাস দিচ্ছি।
train_cols =data.columns[1:]# Index([gre, gpa, prestige_2, prestige_3, prestige_4], dtype=object)logit =sm.Logit(data['admit'], data[train_cols])# মডেল ফলাফল =logit.fit()ফিট করুনআউটপুট
অপ্টিমাইজেশন সফলভাবে সমাপ্ত হয়েছে। বর্তমান ফাংশন মান:0.573147 পুনরাবৃত্তি 6ফলাফল ব্যাখ্যা করা
স্ট্যাটমডেল ব্যবহার করে সারাংশ আউটপুট তৈরি করা যাক।
print(result.summary2())আউটপুট
ফলাফল:লগিট================================================================মডেল:লগিট নং. পুনরাবৃত্তি:6.0000নির্ভরশীল পরিবর্তনশীল:স্বীকার করুন ছদ্ম আর-বর্গ:0.083 তারিখ:2019-03-03 14:16 AIC:470.5175 না. পর্যবেক্ষণ:400 BIC:494.4663Df মডেল:5 লগ-সম্ভাবনা:-229.26Df অবশিষ্টাংশ:394 LL-নাল:-249.99 একত্রিত:1.0000 স্কেল:1.0000 ------------------ ---------------------------------------------- Coef. Std.Err z P>|z| [০.০২৫ ০.৯৭৫]--------------------------------------------------------- -------------------- GRE 0.0023 0.0011 2.0699 0.0385 0.0001 0.0044GPA 0.801 0.3318 2.4231 0.0154 0.1537 1.4544Prestig_2 -0.6754 0.3165 -201342 0.0328 -1.2958 -0.0551Prestige_3 -1.3402 0.3453 -3.8812 0.0001 -2.0170 -0.6634prestige_4 -1.5515 0.4178 -3.7131 0.0002 -2.3704 -0.7325intercept -3.9900 1.1400 -3.5001 0.0005 -3.5001 0.0005===========================================================================================================6. =====================================উপরের ফলাফল বস্তুটি আমাদেরকে মডেল আউটপুটের অংশগুলিকে বিচ্ছিন্ন ও পরিদর্শন করতে দেয়৷
#প্রতিটি সহগমুদ্রণের আস্থার ব্যবধান দেখুন(result.conf_int())আউটপুট
0 1gre 0.000120 0.004409gpa 0.153684 1.454391prestige_2 -1.295751 -0.055135prestige_3 -2.016992 -0.66341692 -0.663416747prestige_2473420974734737354735প্রেস্টিজউপরের আউটপুট থেকে, আমরা দেখতে পাচ্ছি ভর্তি হওয়ার সম্ভাবনা এবং একজন প্রার্থীর স্নাতক স্কুলের প্রতিপত্তির মধ্যে একটি বিপরীত সম্পর্ক রয়েছে।
তাই একজন প্রার্থীর স্নাতক প্রোগ্রামে গৃহীত হওয়ার সম্ভাবনা উচ্চতর র্যাঙ্কের আন্ডারগ্রাজুয়েট কলেজে (prestige_1=True) পড়া ছাত্রদের জন্য বেশি, যেমনটা নিম্ন র্যাঙ্কের স্কুলের (prestige_3 বা prestige_4) বিপরীতে।
