
টেনসরফ্লো হল একটি মেশিন লার্নিং ফ্রেমওয়ার্ক যা Google প্রদান করে। এটি একটি ওপেন-সোর্স ফ্রেমওয়ার্ক যা পাইথনের সাথে অ্যালগরিদম, গভীর শিক্ষার অ্যাপ্লিকেশন এবং আরও অনেক কিছু বাস্তবায়নের জন্য ব্যবহৃত হয়। এটি গবেষণা এবং উত্পাদন উদ্দেশ্যে ব্যবহৃত হয়। এটিতে অপ্টিমাইজেশন কৌশল রয়েছে যা জটিল গাণিতিক ক্রিয়াকলাপগুলি দ্রুত সম্পাদন করতে সহায়তা করে। কারণ এটি NumPy এবং বহুমাত্রিক অ্যারে ব্যবহার করে। এই বহুমাত্রিক অ্যারেগুলি 'টেনসর' নামেও পরিচিত। ফ্রেমওয়ার্ক গভীর নিউরাল নেটওয়ার্কের সাথে কাজ করতে সহায়তা করে। এটি অত্যন্ত স্কেলযোগ্য, এবং অনেক জনপ্রিয় ডেটাসেটের সাথে আসে।
টেনসর হল টেনসরফ্লোতে ব্যবহৃত একটি ডেটা স্ট্রাকচার। এটি একটি প্রবাহ চিত্রে প্রান্তগুলিকে সংযুক্ত করতে সহায়তা করে। এই ফ্লো ডায়াগ্রামটি 'ডেটা ফ্লো গ্রাফ' নামে পরিচিত। টেনসর বহুমাত্রিক অ্যারে বা একটি তালিকা ছাড়া কিছুই নয়৷
রিগ্রেশন সমস্যার পিছনে লক্ষ্য হল একটি ক্রমাগত বা বিচ্ছিন্ন ভেরিয়েবলের আউটপুট, যেমন একটি মূল্য, সম্ভাবনা, বৃষ্টি হবে কি হবে না ইত্যাদি।
আমরা যে ডেটাসেট ব্যবহার করি তাকে বলা হয় 'অটো MPG' ডেটাসেট। এটিতে 1970 এবং 1980 এর অটোমোবাইলের জ্বালানী দক্ষতা রয়েছে। এতে ওজন, হর্সপাওয়ার, স্থানচ্যুতি এবং আরও অনেক কিছু রয়েছে। এর সাথে, আমাদের নির্দিষ্ট যানবাহনের জ্বালানী দক্ষতার পূর্বাভাস দিতে হবে।
নিচের কোডটি চালানোর জন্য আমরা Google Colaboratory ব্যবহার করছি। Google Colab বা Colaboratory ব্রাউজারে Python কোড চালাতে সাহায্য করে এবং এর জন্য শূন্য কনফিগারেশন এবং GPUs (গ্রাফিক্যাল প্রসেসিং ইউনিট) তে বিনামূল্যে অ্যাক্সেস প্রয়োজন। জুপিটার নোটবুকের উপরে কোলাবোরেটরি তৈরি করা হয়েছে।
নিচে কোড স্নিপেট দেওয়া হল যেখানে আমরা দেখব কীভাবে টেনসরফ্লো ব্যবহার করে অটো MPG ডেটাসেটের মাধ্যমে জ্বালানি দক্ষতার পূর্বাভাস দিতে ডেটা বিভক্ত এবং পরিদর্শন করা যায় −
উদাহরণ
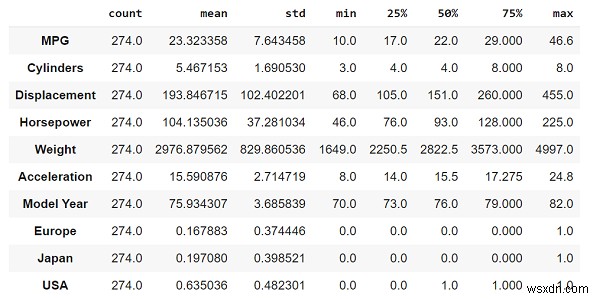
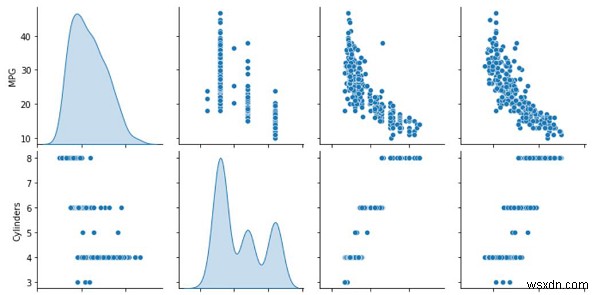
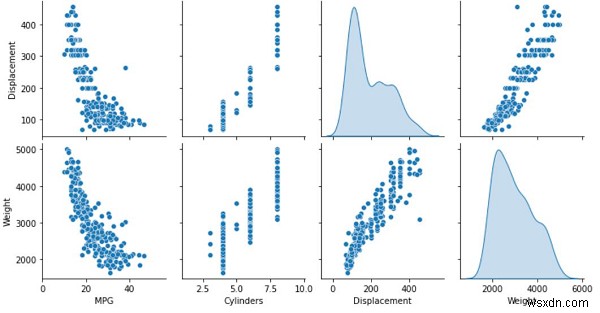
প্রিন্ট("প্রশিক্ষণ ও টেস্টিং ডেটাসেটকে বিভক্ত করা")train_dataset =dataset.sample(frac=0.7, random_state=0)test_dataset =dataset.drop(train_dataset.index)মুদ্রণ("প্রশিক্ষণ ডেটাকে ভিজ্যুয়ালাইজেশন হিসেবে প্লট করা") sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'weight']], diag_kind='kde')মুদ্রণ("ডেটার সাথে সম্পর্কিত পরিসংখ্যান বোঝা")train_dataset.describe().ট্রান্সপোজ () কোড ক্রেডিট − https://www.tensorflow.org/tutorials/keras/regression
আউটপুট
প্রশিক্ষণ বিভাজন এবং ডেটাসেট পরীক্ষা
ব্যাখ্যা
-
একবার ডেটা পরিষ্কার হয়ে গেলে, ডেটা প্রশিক্ষণ এবং পরীক্ষার ডেটাসেটে বিভক্ত হয়৷
-
70 শতাংশ ডেটা প্রশিক্ষণের জন্য এবং বাকি 30 শতাংশ পরীক্ষার জন্য ব্যবহৃত হয়৷
-
এই প্রশিক্ষণ ডেটা সমুদ্রজাত প্যাকেজ ব্যবহার করে কনসোলে ভিজ্যুয়ালাইজ করা হয়।
-
ডেটার পরিসংখ্যান, যেমন গণনা, গড়, মাঝামাঝি এবং আরও অনেক কিছু 'বর্ণনা' ফাংশন ব্যবহার করে প্রদর্শিত হয়৷
