
একটি উপসর্গ গাছ (ট্রাই নামেও পরিচিত) হল একটি ডেটা কাঠামো যা আপনাকে একটি শব্দ তালিকা সংগঠিত করতে এবং একটি নির্দিষ্ট উপসর্গ দিয়ে শুরু হওয়া শব্দগুলিকে দ্রুত খুঁজে পেতে সহায়তা করে৷
উদাহরণস্বরূপ, আপনি আপনার অভিধানে "ca" অক্ষর দিয়ে শুরু হওয়া সমস্ত শব্দ খুঁজে পেতে পারেন, যেমন "cat" বা "cape"।
এই ছবিটি দেখুন:
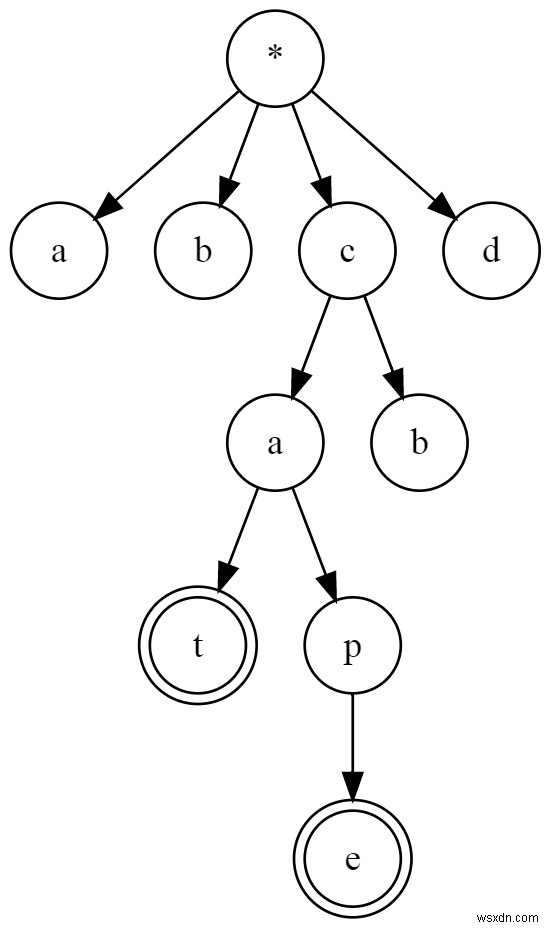
এটি একটি উপসর্গ গাছ৷
আপনি রুট থেকে অনুসরণ করতে পারেন (* ) একটি চিহ্নিত নোডে (যেমন e এবং t ) শব্দ খুঁজতে।
এই নিবন্ধে আপনি শিখবেন কিভাবে রুবিতে আপনার নিজস্ব উপসর্গ গাছ প্রয়োগ করতে হয় এবং সমস্যা সমাধানের জন্য কীভাবে এটি ব্যবহার করতে হয়!
প্রিফিক্স ট্রি ইমপ্লিমেন্টেশন
রুবিতে এটি বাস্তবায়ন করতে আমি একটি Node ব্যবহার করার সিদ্ধান্ত নিয়েছি কয়েকটি বৈশিষ্ট্য সহ ক্লাস:
- মান (একটি অক্ষর)
- "শব্দ" ভেরিয়েবল। একটি সত্য / মিথ্যা মান যা আপনাকে বলে যে এটি একটি বৈধ শব্দ কিনা
- "পরবর্তী" অ্যারে। এটি সমস্ত অক্ষর সংরক্ষণ করে (যেমন
Nodeঅবজেক্ট) যা গাছের মধ্যে এটির পরে আসে
এখানে কোডটি আছে :
class Node
attr_reader :value, :next
attr_accessor :word
def initialize(value)
@value = value
@word = false
@next = []
end
end
এখন আমাদের রুট নোড ধরে রাখার জন্য একটি ক্লাস প্রয়োজন এবং এই নোডগুলির সাথে কাজ করার পদ্ধতিগুলি।
চলুন দেখি Trie ক্লাস:
class Trie
def initialize
@root = Node.new("*")
end
end
এই ক্লাসের ভিতরে আমাদের নিম্নলিখিত পদ্ধতি রয়েছে:
def add_word(word)
letters = word.chars
base = @root
letters.each { |letter| base = add_character(letter, base.next) }
base.word = true
end
def find_word(word)
letters = word.chars
base = @root
word_found =
letters.all? { |letter| base = find_character(letter, base.next) }
yield word_found, base if block_given?
base
end
উভয় পদ্ধতিই একটি প্রদত্ত শব্দকে অক্ষরের অ্যারেতে বিভক্ত করে (chars ব্যবহার করে পদ্ধতি)।
তারপরে আমরা মূল থেকে শুরু করে গাছটি নেভিগেট করি এবং হয় একটি অক্ষর খুঁজে পাই বা এটি যোগ করি।
এখানে সমর্থনকারী পদ্ধতি রয়েছে (এছাড়াও Trie এর ভিতরে ক্লাস):
def add_character(character, trie)
trie.find { |n| n.value == character } || add_node(character, trie)
end
def find_character(character, trie)
trie.find { |n| n.value == character }
end
def add_node(character, trie)
Node.new(character).tap { |new_node| trie << new_node }
end
একটি অক্ষর যোগ করতে আমরা এটি ইতিমধ্যেই বিদ্যমান কিনা তা পরীক্ষা করি (find ব্যবহার করে পদ্ধতি)। যদি তা হয় তাহলে আমরা নোড ফেরত দিই।
অন্যথায় আমরা এটি তৈরি করি এবং নতুন নোড ফেরত দিই।
তারপর আমাদের কাছে include? আছে পদ্ধতি:
def include?(word)
find_word(word) { |found, base| return found && base.word }
end
এখন আমরা আমাদের নতুন ডেটা স্ট্রাকচার ব্যবহার শুরু করার জন্য প্রস্তুত এবং এটি দিয়ে আমরা কী করতে পারি তা দেখুন 🙂
ব্যবহার এবং উদাহরণ চেষ্টা করুন
আমাদের গাছে কিছু শব্দ যোগ করে শুরু করা যাক:
trie = Trie.new
trie.add_word("cat")
trie.add_word("cap")
trie.add_word("cape")
trie.add_word("camp")
আপনি এইভাবে গাছে একটি শব্দ অন্তর্ভুক্ত আছে কিনা তা পরীক্ষা করতে পারেন:
p trie.include?("cape")
# true
p trie.include?("ca")
# false
তাহলে এই ডেটা স্ট্রাকচারের কিছু ব্যবহার কি?
- শব্দ গেমস সমাধান করা
- বানান পরীক্ষা
- স্বয়ংসম্পূর্ণ
আপনার গাছে লোড করার জন্য আপনার একটি ভাল অভিধানের প্রয়োজন হবে৷
আমি এগুলি খুঁজে পেয়েছি যা আপনার কাজে লাগতে পারে:
- https://raw.githubusercontent.com/first20hours/google-10000-english/master/20k.txt
- https://raw.githubusercontent.com/dwyl/english-words/master/words_alpha.txt
উপসর্গযুক্ত শব্দ খোঁজা
তাই কোড উদাহরণে আমি আপনাকে দেখিয়েছি আমরা add প্রয়োগ করার আগে &find অপারেশন।
কিন্তু আমরা একটি find_words_starting_with চাই পদ্ধতি।
আমরা "ডেপথ ফার্স্ট সার্চ" (DFS) অ্যালগরিদম ব্যবহার করে এটি করতে পারি। আমরা যে শব্দটি দেখছি তার ট্র্যাক রাখার জন্যও আমাদের একটি উপায় দরকার৷
মনে রাখবেন যে আমাদের নোডগুলির প্রতিটিতে শুধুমাত্র একটি অক্ষর রয়েছে, তাই গাছের উপর দিয়ে হেঁটে প্রকৃত স্ট্রিংগুলিকে পুনর্গঠন করতে হবে৷
এখানে একটি পদ্ধতি যা এই সমস্ত কিছু করে :
def find_words_starting_with(prefix)
stack = []
words = []
prefix_stack = []
stack << find_word(prefix)
prefix_stack << prefix.chars.take(prefix.size-1)
return [] unless stack.first
until stack.empty?
node = stack.pop
prefix_stack.pop and next if node == :guard_node
prefix_stack << node.value
stack << :guard_node
words << prefix_stack.join if node.word
node.next.each { |n| stack << n }
end
words
end
আমরা এখানে দুটি স্ট্যাক ব্যবহার করি, একটি অনাভিদর্শিত নোডের ট্র্যাক রাখার জন্য (stack ) এবং অন্যটি বর্তমান স্ট্রিং (prefix_stack) ট্র্যাক রাখতে )।
আমরা লুপ করি যতক্ষণ না আমরা সমস্ত নোড পরিদর্শন করি এবং নোডের মান prefix_stack এ যোগ করি . প্রতিটি নোড শুধুমাত্র একটি অক্ষরের জন্য মান ধারণ করে, তাই একটি শব্দ গঠন করার জন্য আমাদের এই অক্ষরগুলি সংগ্রহ করতে হবে।
:guard_node প্রতীকটি prefix_stack-এ যোগ করা হয় তাই আমরা জানি কখন আমরা পিছিয়ে যাচ্ছি। আমাদের স্ট্রিং বাফার (prefix_stack) থেকে অক্ষরগুলি সরাতে আমাদের এটি প্রয়োজন ) সঠিক সময়ে।
তারপর যদি node.word এটা সত্য যে আমরা একটি সম্পূর্ণ শব্দ খুঁজে পেয়েছি এবং আমরা এটিকে আমাদের শব্দের তালিকায় যুক্ত করি৷
এই পদ্ধতি ব্যবহার করার উদাহরণ :
t.find_words_starting_with("cap")
# ["cap", "cape"]
যদি কোন শব্দ পাওয়া না যায় তাহলে আপনি একটি খালি অ্যারে পাবেন:
t.find_words_starting_with("b")
# []
এই পদ্ধতিটি একটি স্বয়ংসম্পূর্ণ বৈশিষ্ট্য বাস্তবায়ন করতে ব্যবহার করা যেতে পারে।
সারাংশ
আপনি উপসর্গ গাছ (ট্রাইস নামেও পরিচিত) সম্পর্কে শিখেছেন, একটি ডাটা স্ট্রাকচার যা একটি গাছে শব্দের তালিকা সংগঠিত করতে ব্যবহৃত হয়। একটি শব্দ বৈধ কিনা তা পরীক্ষা করতে এবং একই উপসর্গ ভাগ করে এমন শব্দগুলি খুঁজে পেতে আপনি দ্রুত এই গাছটিকে জিজ্ঞাসা করতে পারেন৷
এই পোস্টটি শেয়ার করতে ভুলবেন না যাতে আরও লোকেরা শিখতে পারে!
