
এই পোস্টে, আমরা নিউরাল নেটওয়ার্কের বুনিয়াদি এবং রুবি ব্যবহার করে কীভাবে আমরা সেগুলি বাস্তবায়ন করতে পারি তা শিখব! আপনি যদি কৃত্রিম বুদ্ধিমত্তা এবং গভীর শিক্ষার প্রতি আগ্রহী হন কিন্তু কীভাবে শুরু করবেন তা নিশ্চিত না হন, তাহলে এই পোস্টটি আপনার জন্য! মূল ধারণাগুলি হাইলাইট করার জন্য আমরা একটি সাধারণ উদাহরণের মাধ্যমে হাঁটব। মাল্টিপল-লেয়ার নিউরাল নেটওয়ার্ক লিখতে আপনি রুবি ব্যবহার করবেন এমন সম্ভাবনা খুবই কম, কিন্তু সরলতা এবং পঠনযোগ্যতার জন্য, কী ঘটছে তা বোঝার এটি একটি দুর্দান্ত উপায়। প্রথমে, আসুন একধাপ পিছিয়ে যাই এবং দেখুন কিভাবে আমরা এখানে এসেছি।
 এক্স মাচনিয়া সিনেমার একটি স্টিল। ফটো ক্রেডিট
এক্স মাচনিয়া সিনেমার একটি স্টিল। ফটো ক্রেডিট
Ex Machina 2014 সালে মুক্তিপ্রাপ্ত একটি চলচ্চিত্র। আপনি যদি Google-এ শিরোনামটি দেখেন, তাহলে এটি চলচ্চিত্রটির ধরণটিকে "ড্রামা/ফ্যান্টাসি" হিসাবে শ্রেণীবদ্ধ করে। এবং, যখন আমি প্রথম ফিল্মটি দেখেছিলাম, তখন এটি বিজ্ঞান কল্পকাহিনীর মতো মনে হয়েছিল।
কিন্তু, অনেক বেশি সময়ের জন্য?
আপনি যদি Ray Kurzweil কে জিজ্ঞেস করেন, একজন সুপরিচিত ভবিষ্যতবিদ যিনি Google-এ কাজ করেন, 2029 সাল হতে পারে যে বছর কৃত্রিম বুদ্ধিমত্তা একটি বৈধ টুরিং পরীক্ষায় উত্তীর্ণ হবে (যা একজন মানুষ একটি মেশিন/কম্পিউটার এবং অন্য মানুষের মধ্যে পার্থক্য করতে পারে কিনা তা দেখার জন্য একটি পরীক্ষা। ) তিনি আরও ভবিষ্যদ্বাণী করেছেন যে এককতা (যখন কম্পিউটারগুলি মানুষের বুদ্ধিমত্তাকে ছাড়িয়ে যায়) 2045 সালের মধ্যে আবির্ভূত হবে৷
কি Kurzweil এত আত্মবিশ্বাসী করে তোলে?
গভীর শিক্ষার উত্থান
সহজ কথায়, গভীর শিক্ষা হল মেশিন লার্নিং এর একটি উপসেট যা নিউরাল নেটওয়ার্ক ব্যবহার করে প্রচুর পরিমাণে ডেটা থেকে অন্তর্দৃষ্টি বের করে। গভীর শিক্ষার বাস্তব-বিশ্বের অ্যাপ্লিকেশনগুলির মধ্যে নিম্নলিখিতগুলি অন্তর্ভুক্ত রয়েছে:- স্ব-চালিত গাড়ি- ক্যান্সার সনাক্তকরণ- ভার্চুয়াল সহকারী, যেমন সিরি এবং অ্যালেক্সা - চরম আবহাওয়ার ঘটনাগুলির পূর্বাভাস দেওয়া, যেমন ভূমিকম্প
কিন্তু, "নিউরাল নেটওয়ার্ক কি?"
নিউরাল নেটওয়ার্কগুলি নিউরন থেকে তাদের নাম পায়, যা মস্তিষ্কের কোষ যা বৈদ্যুতিক এবং রাসায়নিক সংকেতের মাধ্যমে তথ্য প্রক্রিয়া এবং প্রেরণ করে। মজার ঘটনা:মানুষের মস্তিষ্ক 80+ বিলিয়ন নিউরন দ্বারা গঠিত!
কম্পিউটিংয়ে, একটি নিউরাল নেটওয়ার্ক দেখতে এইরকম:
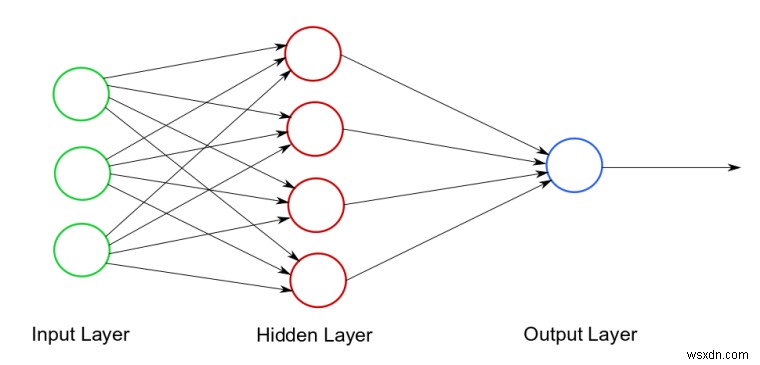 একটি উদাহরণ নিউরাল নেটওয়ার্ক ডায়াগ্রাম। ফটো ক্রেডিট
একটি উদাহরণ নিউরাল নেটওয়ার্ক ডায়াগ্রাম। ফটো ক্রেডিট
আপনি দেখতে পাচ্ছেন, তিনটি অংশ রয়েছে:1) ইনপুট স্তর - প্রাথমিক ডেটা 2) লুকানো স্তর(গুলি) - একটি নিউরাল নেটওয়ার্কে 1 (বা তার বেশি) লুকানো স্তর থাকতে পারে। এখানেই সব গণনা করা হয়! 3) আউটপুট স্তর -- শেষ ফলাফল/পূর্বাভাস
একটি দ্রুত ইতিহাস পাঠ
নিউরাল নেটওয়ার্ক নতুন নয়। প্রকৃতপক্ষে, 1950-এর দশকে কর্নেল ইউনিভার্সিটিতে প্রথম প্রশিক্ষণযোগ্য নিউরাল নেটওয়ার্ক (পারসেপ্ট্রন) তৈরি করা হয়েছিল। যাইহোক, নিউরাল নেটওয়ার্কগুলির প্রযোজ্যতাকে ঘিরে প্রচুর হতাশাবাদ ছিল, প্রধানত কারণ মূল মডেলটি শুধুমাত্র একটি লুকানো স্তর নিয়ে গঠিত। 1969 সালে প্রকাশিত একটি বই দেখিয়েছিল যে মোটামুটি সাধারণ গণনার জন্য পারসেপ্ট্রন ব্যবহার করা অবাস্তব হবে।
নিউরাল নেটওয়ার্কের পুনরুত্থান কম্পিউটার গেমগুলির জন্য দায়ী করা যেতে পারে, যার জন্য এখন অত্যন্ত উচ্চ ক্ষমতাসম্পন্ন গ্রাফিক্স প্রসেসিং ইউনিট (GPUs) প্রয়োজন, যার স্থাপত্য একটি নিউরাল নেট এর সাথে ঘনিষ্ঠভাবে সাদৃশ্যপূর্ণ। পার্থক্য লুকানো স্তর সংখ্যা. একটির পরিবর্তে, আজ প্রশিক্ষিত নিউরাল নেটওয়ার্ক 10, 15 বা এমনকি 50+ স্তর ব্যবহার করছে!
উদাহরণ সময়!
এটি কীভাবে কাজ করে তা বোঝার জন্য, আসুন একটি উদাহরণ দেখি। আপনাকে ruby-fann ইনস্টল করতে হবে মণি আপনার টার্মিনাল খুলুন এবং আপনার কাজের ডিরেক্টরিতে যান। তারপর, নিম্নলিখিত চালান:
gem install ruby-fann
একটি নতুন রুবি ফাইল তৈরি করুন (আমি আমার নাম দিয়েছি neural-net.rb )
এর পরে, আমরা Kaggle থেকে "স্টুডেন্ট অ্যালকোহল কনজাম্পশন" ডেটাসেট ব্যবহার করব৷ আপনি এখানে এটা ডাউনলোড করতে পারেন। Google Sheets-এ "student-mat.csv" ফাইল খুলুন (অথবা আপনার পছন্দের সম্পাদক।) এইগুলি ব্যতীত সমস্ত কলাম মুছুন:- Dalc (কাজের দিনে অ্যালকোহল সেবন যেখানে 1টি খুব কম এবং 5টি খুব বেশি) - Walc (সপ্তাহান্তে অ্যালকোহল সেবন যেখানে 1টি খুব কম এবং 5টি খুব বেশি) - G3 (0 এবং 20 এর মধ্যে চূড়ান্ত গ্রেড)
রুবি-ফ্যান মণি কাজ করার জন্য আমাদের চূড়ান্ত গ্রেড কলামটি বাইনারি হতে পরিবর্তন করতে হবে -- হয় 0 বা 1 --। এই উদাহরণের জন্য, আমরা ধরে নেব যে 10 এর থেকে কম বা সমান একটি "0" এবং 10 এর চেয়ে বড় একটি "1"। আপনি কোন প্রোগ্রামটি ব্যবহার করছেন তার উপর নির্ভর করে, সেলের মানের উপর ভিত্তি করে স্বয়ংক্রিয়ভাবে মানটিকে 1 বা 0 এ পরিবর্তন করতে আপনি ঘরে একটি সূত্র লিখতে সক্ষম হবেন। Google পত্রকগুলিতে, এটি এইরকম কিছু দেখায়:
=IF(C3 >= 10, 1, 0)
এই ডেটাটি একটি .CSV ফাইল হিসাবে সংরক্ষণ করুন (আমি আমার নাম দিয়েছি students.csv ) আপনার রুবি ফাইলের মতো একই ডিরেক্টরিতে।
আমাদের নিউরাল নেটওয়ার্কে নিম্নলিখিত স্তরগুলি থাকবে:- ইনপুট স্তর:2টি নোড (কাজের দিন অ্যালকোহল সেবন এবং সপ্তাহান্তে অ্যালকোহল সেবন)- লুকানো স্তর:6টি লুকানো নোড (এটি শুরু করা কিছুটা স্বেচ্ছাচারী; আপনি পরে পরীক্ষা করার সময় এটি পরিবর্তন করতে পারেন)- আউটপুট স্তর:1 নোড (হয় একটি 0 বা 1)
প্রথমে, আমাদের ruby-fann প্রয়োজন হবে রত্ন, সেইসাথে অন্তর্নির্মিত csv লাইব্রেরি আপনার রুবি প্রোগ্রামের প্রথম লাইনে এটি যোগ করুন:
require 'ruby-fann'
require 'csv'
এর পরে, আমাদের CSV ফাইল থেকে আমাদের ডেটা অ্যারেতে লোড করতে হবে।
# Create two empty arrays. One will hold our independent varaibles (x_data), and the other will hold our dependent variable (y_data).
x_data = []
y_data = []
# Iterate through our CSV data and add elements to applicable arrays.
# Note that if we don't add the .to_f and .to_i, our arrays would have strings, and the ruby-fann library would not be happy.
CSV.foreach("students.csv", headers: false) do |row|
x_data.push([row[0].to_f, row[1].to_f])
y_data.push(row[2].to_i)
end
এর পরে, আমাদের প্রশিক্ষণ এবং পরীক্ষার ডেটাতে আমাদের ডেটা ভাগ করতে হবে। একটি 80/20 বিভাজন বেশ সাধারণ, যেখানে আপনার 20% ডেটা পরীক্ষার জন্য এবং 80% প্রশিক্ষণের জন্য ব্যবহৃত হয়। এখানে "প্রশিক্ষণ" এর অর্থ হল মডেলটি এই ডেটার উপর ভিত্তি করে শিখবে এবং তারপরে মডেলটি ফলাফলের ভবিষ্যদ্বাণী কতটা ভালো করে তা দেখতে আমরা আমাদের "পরীক্ষা" ডেটা ব্যবহার করব৷
# Divide data into a training set and test set.
testing_percentage = 20.0
# Take the number of total elements and multiply by the test percentage.
testing_size = x_data.size * (testing_percentage/100.to_f)
# Start at the beginning and end at the testing_size - 1 since arrays are 0-indexed.
x_test_data = x_data[0 .. (testing_size-1)]
y_test_data = y_data[0 .. (testing_size-1)]
# Pick up where we left off until the end of the dataset.
x_train_data = x_data[testing_size .. x_data.size]
y_train_data = y_data[testing_size .. y_data.size]
শান্ত! আমরা যেতে আমাদের তথ্য প্রস্তুত আছে. এর পরের জাদু আসে!
# Set up the training data model.
train = RubyFann::TrainData.new(:inputs=> x_train_data, :desired_outputs=>y_train_data)
আমরা RubyFann::TrainData অবজেক্ট ব্যবহার করি এবং আমাদের x_train_data, পাস করি যা আমাদের কর্মদিবস এবং সপ্তাহান্তে অ্যালকোহল সেবন এবং আমাদের y_train_data, যা চূড়ান্ত কোর্স গ্রেডের উপর ভিত্তি করে 0 বা 1।
এখন, আগে আলোচনা করা লুকানো নিউরনের সংখ্যা দিয়ে আমাদের প্রকৃত নিউরাল নেটওয়ার্ক মডেল সেটআপ করা যাক।
# Set up the model and train using training data.
model = RubyFann::Standard.new(
num_inputs: 2,
hidden_neurons: [6],
num_outputs: 1 );
ঠিক আছে, প্রশিক্ষণের সময়!
model.train_on_data(train, 1000, 10, 0.01)
এখানে, আমরা train পাস করি ভেরিয়েবল আমরা আগে তৈরি করেছি। 1000 max_epochs সংখ্যার প্রতিনিধিত্ব করে, 10 রিপোর্টের মধ্যে ত্রুটির সংখ্যা উপস্থাপন করে এবং 0.1 হল আমাদের কাঙ্খিত গড়-বর্গীয় ত্রুটি। একটি যুগ হল যখন সমগ্র ডেটাসেট নিউরাল নেটওয়ার্কের মাধ্যমে পাস করা হয়। গড়-বর্গীয় ত্রুটি হল যা আমরা কমানোর চেষ্টা করছি। আপনি এখানে এর অর্থ কী তা সম্পর্কে আরও পড়তে পারেন।
এর পরে, আমরা প্রকৃত ফলাফলের সাথে আমাদের পরীক্ষার ডেটার জন্য মডেলটি কী ভবিষ্যদ্বাণী করেছে তা তুলনা করে আমাদের মডেলটি কতটা ভাল করেছে তা জানতে চাই। আমরা এই কোডটি ব্যবহার করে এটি সম্পন্ন করতে পারি:
predicted = []
# Iterate over our x_test_data, run our model on each one, and add it to our predicted array.
x_test_data.each do |params|
predicted.push( model.run(params).map{ |e| e.round } )
end
# Compare the predicted results with the actual results.
correct = predicted.collect.with_index { |e,i| (e == y_test_data[i]) ? 1 : 0 }.inject{ |sum,e| sum+e }
# Print out the accuracy rate.
puts "Accuracy: #{((correct.to_f / testing_size) * 100).round(2)}% - test set of size #{testing_percentage}%"
এর আমাদের প্রোগ্রাম চালানো যাক এবং কি হয় দেখুন!
ruby neural-net.rb
আপনি Epochs এর জন্য অনেক আউটপুট দেখতে হবে, কিন্তু নীচে, আপনি এই মত কিছু দেখতে হবে:
Accuracy: 56.82% - test set of size 20.0%
উফ, যে খুব ভালো না! কিন্তু, আসুন আমাদের নিজস্ব ডেটা পয়েন্ট নিয়ে আসা যাক এবং মডেলটি চালাই।
prediction = model.run( [1, 1] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction.map{ |e| e.round }}"
prediction_two = model.run( [5, 4] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction_two.map{ |e| e.round }}"
এখানে, আমরা দুটি উদাহরণ আছে. প্রথম জন্য, আমরা আমাদের কর্মদিবস এবং সপ্তাহান্তে অ্যালকোহল সেবনের জন্য 1s অতিক্রম করছি। আমি যদি একজন বাজি ধরা ব্যক্তি হতাম, আমি অনুমান করতাম যে এই শিক্ষার্থীর চূড়ান্ত গ্রেড 10 এর উপরে থাকবে (অর্থাৎ, একটি 1)। দ্বিতীয় উদাহরণটি অ্যালকোহল সেবনের জন্য উচ্চ মানের (5 এবং 4) পাস করে, তাই আমি অনুমান করব যে এই শিক্ষার্থীর চূড়ান্ত গ্রেড 10 এর সমান বা তার নিচে থাকবে (অর্থাৎ, একটি 0.) আসুন আমাদের প্রোগ্রামটি আবার চালাই এবং দেখুন কী হয়!
আপনার আউটপুট এই মত কিছু হওয়া উচিত:
Algorithm predicted class: [1]
Algorithm predicted class: [0]
আমাদের মডেলটি স্পেকট্রামের নিম্ন বা উচ্চতর প্রান্তের সংখ্যাগুলির জন্য আমরা যা আশা করি তা করবে বলে মনে হচ্ছে। কিন্তু, এটি সংগ্রাম করে যখন সংখ্যাগুলি বিপরীত হয় (বিভিন্ন সংমিশ্রণ চেষ্টা করতে নির্দ্বিধায় -- 1 এবং 5, বা 2 এবং 3 উদাহরণ হিসাবে) বা মাঝখানে। আমরা আমাদের Epoch ডেটা থেকেও দেখতে পাচ্ছি যে, ত্রুটি হ্রাস পেলেও এটি খুব বেশি (মাঝামাঝি-20%।) থেকে যায় এর অর্থ হল অ্যালকোহল সেবন এবং কোর্সের গ্রেডের মধ্যে সম্পর্ক নাও থাকতে পারে। আমি আপনাকে কাগলের আসল ডেটাসেটের সাথে খেলার জন্য উত্সাহিত করি -- সেখানে কি অন্য স্বাধীন ভেরিয়েবল আছে যা আমরা কোর্সের ফলাফলের পূর্বাভাস দিতে ব্যবহার করতে পারি?
র্যাপ-আপ
৷
এই সমস্ত কাজ করার জন্য হুডের নীচে অনেক জটিলতা রয়েছে (বেশিরভাগ গণিতের ক্ষেত্রে)। আপনি যদি কৌতূহলী হন এবং আরও জানতে চান, আমি FANN-এর ডক্সগুলি দেখার বা ruby-fann-এর সোর্স কোড দেখার সুপারিশ করছি। মণি আমি Netflix-এ "AlphaGo" ডকুমেন্টারিটি চেক করার পরামর্শ দিচ্ছি -- এটি উপভোগ করার জন্য প্রচুর প্রযুক্তিগত জ্ঞানের প্রয়োজন নেই এবং কম্পিউটারগুলি কী কী করতে পারে তার সীমাবদ্ধতাকে কীভাবে গভীরভাবে শিখতে পারে তার একটি দুর্দান্ত, বাস্তব-জীবনের উদাহরণ দেয়৷
Kurzweil শেষ পর্যন্ত তার ভবিষ্যদ্বাণী সঠিক হচ্ছে? শুধুমাত্র সময় বলে দেবে!
