
সফ্টওয়্যার বিকাশ করা চ্যালেঞ্জিং হতে পারে, তবে এটি বজায় রাখা অনেক বেশি চ্যালেঞ্জিং। রক্ষণাবেক্ষণের মধ্যে রয়েছে সফ্টওয়্যার প্যাচ এবং সার্ভার রক্ষণাবেক্ষণ। এই পোস্টে, আমরা সার্ভার পরিচালনা এবং রক্ষণাবেক্ষণের উপর ফোকাস করব।
ঐতিহ্যগতভাবে, সার্ভারগুলি প্রাঙ্গনে ছিল, যার অর্থ শারীরিক হার্ডওয়্যার কেনা এবং বজায় রাখা। ক্লাউড কম্পিউটিং সহ, এই সার্ভারগুলিকে আর শারীরিকভাবে মালিকানাধীন হতে হবে না। 2006 সালে, যখন Amazon AWS শুরু করে এবং তার EC2 পরিষেবা চালু করে, তখন আধুনিক ক্লাউড কম্পিউটিং এর যুগ শুরু হয়। এই ধরনের পরিষেবার সাথে, আমাদের আর শারীরিক সার্ভার বজায় রাখার বা শারীরিক হার্ডওয়্যার আপগ্রেড করার প্রয়োজন নেই। এটি অনেক সমস্যার সমাধান করেছে, কিন্তু সার্ভার রক্ষণাবেক্ষণ এবং সংস্থান ব্যবস্থাপনা এখনও আমাদের উপর নির্ভর করে। এই উন্নয়নগুলিকে পরবর্তী স্তরে নিয়ে যাওয়া, আমাদের কাছে এখন সার্ভারহীন প্রযুক্তি রয়েছে৷
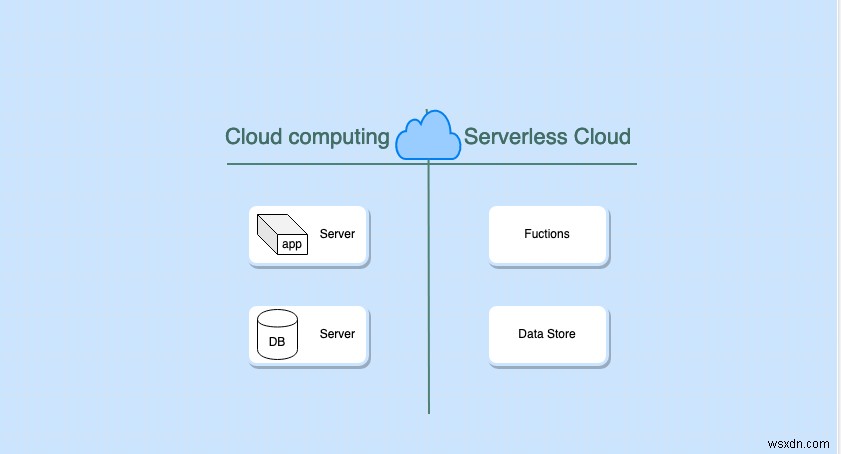
সার্ভারহীন প্রযুক্তি কি?
সার্ভারহীন প্রযুক্তি একটি ক্লাউড প্রদানকারীর সার্ভার পরিচালনা এবং ব্যবস্থা করার কাজ অফলোড করতে সহায়তা করে। এই পোস্টে, আমরা AWS নিয়ে আলোচনা করব।
সার্ভারহীন শব্দটির অর্থ এই নয় যে কোনও সার্ভার নেই। একটি সার্ভার আছে, কিন্তু এটি সম্পূর্ণরূপে ক্লাউড প্রদানকারী দ্বারা পরিচালিত হয়। এক অর্থে, সার্ভারহীন প্রযুক্তি ব্যবহারকারীদের জন্য, কোন দৃশ্যমান সার্ভার নেই। সার্ভারগুলি আমাদের কাছে সরাসরি দৃশ্যমান নয় এবং সেগুলি পরিচালনা করার কাজটি ক্লাউড প্রদানকারী দ্বারা স্বয়ংক্রিয়। এখানে কিছু বৈশিষ্ট্য রয়েছে যা এটিকে সার্ভারহীন করে তোলে:
- কোনও অপারেশনাল ম্যানেজমেন্ট নেই - সার্ভার প্যাচ করার বা উচ্চ প্রাপ্যতার জন্য সেগুলি পরিচালনা করার প্রয়োজন নেই;
- প্রয়োজন অনুসারে স্কেল করুন - শুধুমাত্র কিছু ব্যবহারকারীকে পরিবেশন করা থেকে লক্ষ লক্ষ ব্যবহারকারীকে পরিবেশন করা পর্যন্ত;
- যেমন যেতে হবে সেইভাবে অর্থ প্রদান করুন - খরচটি ব্যবহারের উপর ভিত্তি করে পরিচালিত হয়।
সার্ভারহীন প্রযুক্তিকে নিম্নরূপ শ্রেণীবদ্ধ করা যেতে পারে:
- গণনা (যেমন, Lambda এবং Fargate)
- স্টোরেজ (যেমন, S3)
- ডেটা স্টোর (যেমন, DynamoDB এবং Aurora)
- ইন্টিগ্রেশন (যেমন, API গেটওয়ে, SNS, এবং SQS)
- বিশ্লেষণ (যেমন, কাইনেসিস এবং অ্যাথেনা)
কেন সার্ভারহীন প্রযুক্তি ব্যবহার করবেন?
খরচ
সার্ভারহীন প্রযুক্তি ব্যবহার করার প্রধান সুবিধাগুলির মধ্যে একটি হল আপনি যান হিসাবে অর্থ প্রদান করুন৷ যখন ট্র্যাফিক ভলিউমে একটি অপ্রত্যাশিত পরিবর্তন হয়, তখন আপনাকে ব্যবহারের ধরণগুলির উপর ভিত্তি করে সার্ভারকে উপরে বা নীচে স্কেল করতে হবে, তবে স্ব-পরিচালিত অটোস্কেলিংয়ের সাথে স্কেল করা কঠিন এবং অকার্যকর হতে পারে। সার্ভারবিহীন কম্পিউটিং, যেমন AWS Lambda, সহজেই খরচ বাঁচাতে সাহায্য করতে পারে কারণ অলস সময়ে অর্থপ্রদান করার প্রয়োজন নেই৷
ডেভেলপার উৎপাদনশীলতা
যেহেতু সার্ভারহীন কম্পিউটিং একটি ক্লাউড প্রদানকারীর দ্বারা প্রদত্ত সম্পূর্ণরূপে পরিচালিত পরিষেবাগুলিকে বোঝায়, তাই বিকাশকারীদের সার্ভারের ব্যবস্থা করার বা সার্ভার অ্যাপ্লিকেশনগুলি বিকাশ করার কোন প্রয়োজন নেই৷ বিকাশকারীরা সার্ভার পরিচালনার প্রয়োজন ছাড়াই কোডিং শুরু করতে পারে। এই পদ্ধতিটি প্যাচিং সার্ভার বা অটোস্কেলিং পরিচালনার প্রয়োজনীয়তাও সরিয়ে দেয়। এই সব সময় বাঁচানো ডেভেলপারদের উৎপাদনশীলতা বাড়াতে সাহায্য করে।
স্থিতিস্থাপকতা
সার্ভারহীন কম্পিউটিং অত্যন্ত স্থিতিস্থাপক এবং ব্যবহারের উপর ভিত্তি করে স্কেল আপ বা ডাউন করতে পারে। ব্যবহারকারীদের একটি স্পাইক সহজেই পরিচালনা করা যেতে পারে। এটি একটি বড় সুবিধা হতে পারে এবং ডেভেলপারদের জন্য অনেক সময় বাঁচাতে সাহায্য করে৷
৷উচ্চ প্রাপ্যতা
যখন কম্পিউটিং সার্ভারহীন হয় এবং ক্লাউড প্রদানকারী দ্বারা পরিচালিত হয় এবং সার্ভারের আপটাইম বেশি থাকে, তখন ব্যর্থতা স্বয়ংক্রিয়ভাবে পরিচালনা করা হয়। এই ধরনের সমস্যাগুলি পরিচালনার জন্য বিশেষ দক্ষতা প্রয়োজন। সার্ভারহীন পদ্ধতির সাথে, অপারেশন এবং ডেভেলপারদের কাজ একজন একক ব্যক্তি দ্বারা করা যেতে পারে।
রুবিতে কিভাবে সার্ভারহীন কার্যকারিতা প্রয়োগ করা যায়
AWS-এর মতে, রুবি হল AWS-এ সর্বাধিক ব্যবহৃত ভাষাগুলির মধ্যে একটি। Lambda 2018 সালের নভেম্বরে রুবিকে সমর্থন করা শুরু করেছে৷ আমরা শুধুমাত্র AWS দ্বারা প্রদত্ত সার্ভারহীন প্রযুক্তি ব্যবহার করে রুবিতে একটি ওয়েব API তৈরি করব৷
AWS-এ একটি সার্ভারহীন ইনফ্রা তৈরি করতে, আমরা কেবল AWS কনসোলে লগ ইন করতে পারি এবং সেগুলি তৈরি করা শুরু করতে পারি। যাইহোক, আমরা এমন কিছু বিকাশ করতে চাই যা সহজেই পরীক্ষাযোগ্য এবং দুর্যোগ পুনরুদ্ধারের সুবিধা দেয়। আমরা একটি কোড হিসাবে সার্ভারহীন বৈশিষ্ট্য লিখব. এটি করার জন্য, AWS সার্ভারহীন অ্যাপ্লিকেশন মডেল (SAM) প্রদান করে। SAM হল একটি ফ্রেমওয়ার্ক যা AWS-এ সার্ভারহীন অ্যাপ্লিকেশন তৈরি করতে ব্যবহৃত হয়। এটি ল্যাম্বডা, ডাটাবেস এবং এপিআই ডিজাইন করার জন্য YAML-ভিত্তিক সিনট্যাক্স প্রদান করে। AWS SAM অ্যাপ্লিকেশনগুলি AWS SAM-CLI ব্যবহার করে তৈরি করা যেতে পারে, যা এই লিঙ্কের মাধ্যমে ডাউনলোড করা যেতে পারে৷
AWS SAM CLI AWS ক্লাউডফর্মেশনের উপরে নির্মিত। আপনি যদি CoudFormation এর সাথে IaC লেখার সাথে পরিচিত হন তবে এটি খুব সহজ হবে। বিকল্পভাবে, আপনি সার্ভারহীন ফ্রেমওয়ার্কও ব্যবহার করতে পারেন। এই পোস্টে, আমি AWS SAM ব্যবহার করব।
SAM CLI ব্যবহার করার আগে, নিশ্চিত করুন যে আপনার কাছে নিম্নলিখিতগুলি আছে:
- AWS প্রোফাইল সেটআপ
- ডকার ইনস্টল করা হয়েছে
- SAM CLI ইনস্টল করা হয়েছে
আমরা একটি সার্ভারহীন অ্যাপ্লিকেশন বিকাশ করব। আমরা আমাদের অ্যাপ্লিকেশনে DynamoDB এবং Lambda এর মতো কিছু সার্ভারহীন ইনফ্রা তৈরি করে শুরু করব। ডাটাবেস দিয়ে শুরু করা যাক:
DynamoDB
৷DynamoDB হল একটি সার্ভারবিহীন AWS-পরিচালিত ডাটাবেস পরিষেবা। যেহেতু এটি সার্ভারহীন, এটি খুব দ্রুত এবং সেটআপ করা সহজ। DynamoDB তৈরি করতে, আমরা SAM টেমপ্লেটকে নিম্নরূপ সংজ্ঞায়িত করি:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
UsersTable:
Type: AWS::Serverless::SimpleTable
Properties:
PrimaryKey:
Name: id
Type: String
TableName: users
SAM CLI এবং উপরের টেমপ্লেট দিয়ে, আমরা একটি মৌলিক DynamoDB টেবিল তৈরি করতে পারি। প্রথমে, আমাদের সার্ভারহীন অ্যাপের জন্য একটি প্যাকেজ তৈরি করতে হবে। এই জন্য, আমরা নিম্নলিখিত কমান্ড রান. এটি প্যাকেজটি তৈরি করবে এবং এটিকে s3 এ পুশ করবে। নিশ্চিত করুন যে আপনি serverless-users-bucket নামের সাথে s3 বালতি তৈরি করেছেন কমান্ড চালানোর আগে:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
s3 এখন আমাদের সার্ভারহীন অ্যাপের টেমপ্লেট এবং কোডের উৎস হয়ে ওঠে, যার জন্য আমরা একটি ল্যাম্বডা ফাংশন তৈরি করার সময় এই বিষয়ে কথা বলব৷
DynamoDB:
তৈরি করতে আমরা এখন এই টেমপ্লেটটি স্থাপন করতে পারি$ sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
এর সাথে, আমাদের কাছে DynamoDB সেটআপ রয়েছে। এর পরে, আমরা একটি ল্যাম্বডা তৈরি করব, যেখানে এই টেবিলটি ব্যবহার করা হবে।
ল্যাম্বদা
Lambda হল AWS দ্বারা প্রদত্ত একটি সার্ভারহীন কম্পিউটিং পরিষেবা। এটি প্রকৃত সার্ভার পরিচালনার প্রয়োজন ছাড়াই প্রয়োজনীয় ভিত্তিতে কোড চালানোর জন্য ব্যবহার করা যেতে পারে, যেখানে কোডটি কার্যকর করা হয়। Lambda Async প্রসেস, REST API, বা যেকোনো নির্ধারিত কাজ চালানোর জন্য ব্যবহার করা যেতে পারে। আমাদের যা করতে হবে তা হল একটি হ্যান্ডলার ফাংশন লিখতে এবং ফাংশনটি AWS Lambda-তে পুশ করুন। Lambda ইভেন্টের উপর ভিত্তি করে কাজটি সম্পাদনের কাজ করবে . একটি ইভেন্ট বিভিন্ন উত্স দ্বারা ট্রিগার করা যেতে পারে, যেমন API গেটওয়ে, SQS, বা S3; এটি অন্য কোডবেস দ্বারা ট্রিগার করা যেতে পারে। ট্রিগার করা হলে, এই Lambda ফাংশন ঘটনা এবং প্রসঙ্গ পরামিতি গ্রহণ করে। ট্রিগারের উত্সের উপর ভিত্তি করে এই পরামিতিগুলির মানগুলি পৃথক হয়। হ্যান্ডলারের কাছে এই ইভেন্টগুলি প্রেরণ করে আমরা ম্যানুয়ালি বা প্রোগ্রাম্যাটিকভাবে ল্যাম্বডা ফাংশনটি ট্রিগার করতে পারি। একজন হ্যান্ডলার দুটি আর্গুমেন্ট নেয়:
ইভেন্ট - ইভেন্টগুলি সাধারণত ট্রিগারের উত্স থেকে পাস করা একটি কী-মান হ্যাশ। এই মানগুলি স্বয়ংক্রিয়ভাবে পাস হয় যখন সেগুলি বিভিন্ন উত্স, যেমন SQS, Kinesis, বা একটি API গেটওয়ে দ্বারা ট্রিগার করা হয়। ম্যানুয়ালি ট্রিগার করার সময়, আমরা এখানে ইভেন্টগুলি পাস করতে পারি। ইভেন্টে ল্যাম্বডা ফাংশন হ্যান্ডলারের জন্য ইনপুট ডেটা রয়েছে। উদাহরণস্বরূপ, একটি API গেটওয়েতে, অনুরোধের মূল অংশটি এই ইভেন্টের মধ্যে থাকে৷
৷প্রসঙ্গ - প্রসঙ্গ হ্যান্ডলার ফাংশনের দ্বিতীয় আর্গুমেন্ট। এতে ট্রিগারের উৎস, ল্যাম্বডা ফাংশনের নাম, সংস্করণ, অনুরোধ-আইডি এবং আরও অনেক কিছু সহ নির্দিষ্ট বিবরণ রয়েছে।
হ্যান্ডলারের আউটপুট সেই পরিষেবাতে ফেরত পাঠানো হয় যা ল্যাম্বডা ফাংশনটিকে ট্রিগার করেছিল। একটি Lambda ফাংশনের আউটপুট হ্যান্ডলার ফাংশনের রিটার্ন মান।
AWS Lambda সাতটি ভিন্ন ভাষা সমর্থন করে যেখানে আপনি রুবি সহ কোড করতে পারেন। এখানে, আমরা DynamoDB এর সাথে সংযোগ করতে AWS Ruby-sdk ব্যবহার করব।
কোড লেখার আগে, আসুন একটি SAM টেমপ্লেট ব্যবহার করে ল্যাম্বডার জন্য একটি ইনফ্রা তৈরি করি:
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: "Serverless users app"
Resources:
CreateUserFunction:
Type: AWS::Serverless::Function
Properties:
Handler: users.create
Runtime: ruby2.7
Policies:
- DynamoDBWritePolicy:
TableName: !Ref UsersTable
Environment:
Variables:
USERS_TABLE: !Ref UsersTable
হ্যান্ডলারে, আমরা Handler: <filename>.<method_name> হিসাবে কার্যকর করা ফাংশনের রেফারেন্স লিখি। .
একটি নীতির জন্য সার্ভারহীন নীতি টেমপ্লেটটি পড়ুন যা আপনি এটি যে সংস্থান ব্যবহার করে তার উপর ভিত্তি করে ল্যাম্বডাতে সংযুক্ত করতে পারেন। যেহেতু আমাদের Lambda ফাংশন DynamoDB-তে লেখে, তাই আমরা DynamoDBWritePolicy ব্যবহার করেছি নীতি বিভাগে।
আমরা ল্যাম্বডা ফাংশনে env ভেরিয়েবল USERS_TABLE প্রদান করছি যাতে এটি নির্দিষ্ট ডাটাবেসে অনুরোধ পাঠাতে পারে।
সুতরাং, ল্যাম্বডা ইনফ্রার জন্য আমাদের এটিই দরকার। এখন, DynamoDB-তে ব্যবহারকারী তৈরি করার জন্য কোড লিখি, যেটি Lambda ফাংশন কার্যকর করবে।
জেমফাইলে AWS রেকর্ড যোগ করুন:
# Gemfile
source 'https://rubygems.org' do
gem 'aws-record', '~> 2'
end
ডায়নামোডিবিতে ইনপুট লিখতে কোড যোগ করুন:
# users.rb
require 'aws-record'
class UsersTable
include Aws::Record
set_table_name ENV['USERS_TABLE']
string_attr :id, hash_key: true
string_attr :body
end
def create(event:,context:)
body = event["body"]
id = SecureRandom.uuid
user = UsersTable.new(id: id, body: body)
user.save!
user.to_h
end
এটা খুব দ্রুত এবং সহজ. AWS aws-record প্রদান করে DynamoDB অ্যাক্সেস করার জন্য রত্ন, যা Rails' activerecord-এর মতোই .
এরপরে, নির্ভরতাগুলি ইনস্টল করতে নিম্নলিখিত কমান্ডগুলি চালান৷
৷দ্রষ্টব্য:নিশ্চিত করুন যে আপনার কাছে Lambda তে সংজ্ঞায়িত রুবির একই সংস্করণ রয়েছে। এখানে উদাহরণের জন্য, আপনার মেশিনে Ruby2.7 ইনস্টল করতে হবে।
# install dependencies
$ bundle install
$ bundle install --deployment
পরিবর্তনগুলি প্যাকেজ করুন:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
স্থাপন করুন:
sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
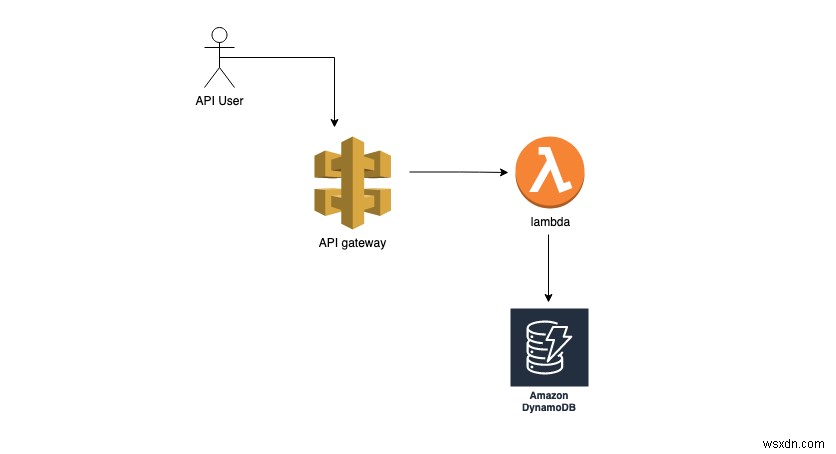
এই কোড দিয়ে, আমাদের এখন ল্যাম্বডা চলছে, যা ডাটাবেসে ইনপুট লিখতে পারে। আমরা ল্যাম্বডার সামনে একটি API গেটওয়ে যুক্ত করতে পারি যাতে আমরা এটি HTTP কলের মাধ্যমে অ্যাক্সেস করতে পারি। একটি API গেটওয়ে অনেকগুলি API ব্যবস্থাপনা কার্যকারিতা প্রদান করে, যেমন হার সীমিতকরণ এবং প্রমাণীকরণ। যাইহোক, এটি ব্যবহারের উপর ভিত্তি করে ব্যয়বহুল হতে পারে। API ব্যবস্থাপনা ছাড়া শুধুমাত্র একটি HTTP API ব্যবহার করার একটি সস্তা বিকল্প আছে। ব্যবহারের ক্ষেত্রের উপর ভিত্তি করে, আপনি সবচেয়ে উপযুক্ত একটি চয়ন করতে পারেন।
AWS Lambda এর কিছু সীমা আছে। তাদের মধ্যে কিছু সংশোধন করা যেতে পারে, কিন্তু অন্যগুলি সংশোধন করা হয়েছে:
- মেমরি - ডিফল্টরূপে, একটি Lambda এর সম্পাদনের সময় 128 MB মেমরি থাকে। এটি 64 MB বৃদ্ধিতে 3,008 MB পর্যন্ত বাড়ানো যেতে পারে৷
- টাইম আউট - ল্যাম্বডা ফাংশনের কোড কার্যকর করার জন্য একটি সময়সীমা রয়েছে। ডিফল্ট সীমা 3 সেকেন্ড। এটি 900 সেকেন্ড পর্যন্ত বাড়ানো যেতে পারে।
- স্টোরেজ - Lambda একটি
/tmpপ্রদান করে স্টোরেজ জন্য ডিরেক্টরি। এই স্টোরেজের সীমা 512 এমবি। - অনুরোধ এবং প্রতিক্রিয়ার আকার - একটি সিঙ্ক্রোনাস ট্রিগারের জন্য 6 MB পর্যন্ত এবং একটি অ্যাসিঙ্ক্রোনাস ট্রিগারের জন্য 256 MB পর্যন্ত৷
- পরিবেশ পরিবর্তনশীল - 4KB পর্যন্ত
যেহেতু ল্যাম্বডার এই সীমার কিছু আছে, তাই এই সীমাবদ্ধতার মধ্যে মানানসই কোড লেখাই ভালো। যদি তারা না করে, আমরা কোডটি বিভক্ত করতে পারি যাতে একটি ল্যাম্বডা অন্যটিকে ট্রিগার করে। এছাড়াও AWS দ্বারা প্রদত্ত একটি ধাপ ফাংশন রয়েছে, যা একাধিক Lambda ফাংশন সিকোয়েন্স করতে ব্যবহার করা যেতে পারে।
আমরা কীভাবে স্থানীয়ভাবে সার্ভারহীন অ্যাপ্লিকেশন পরীক্ষা করতে পারি?
সার্ভারবিহীন অ্যাপ্লিকেশনের জন্য, আমাদের এমন একটি বিক্রেতা থাকা দরকার যা পরিচালিত সার্ভারহীন পরিষেবা প্রদান করে। আমরা আমাদের আবেদন পরীক্ষা করার জন্য AWS-এর উপর নির্ভরশীল। অ্যাপ্লিকেশন পরীক্ষা করার জন্য, AWS দ্বারা উপলব্ধ কয়েকটি স্থানীয় বিকল্প রয়েছে। AWS সার্ভারহীন প্রযুক্তির সাথে সামঞ্জস্যপূর্ণ কিছু ওপেন-সোর্স টুলও স্থানীয়ভাবে অ্যাপ্লিকেশন পরীক্ষা করতে ব্যবহার করা যেতে পারে।
আমাদের Lambda ফাংশন এবং DynamoDB পরীক্ষা করা যাক। এটি করার জন্য, আমাদের স্থানীয়ভাবে এগুলি চালাতে হবে৷
৷প্রথমত, একটি ডকার নেটওয়ার্ক তৈরি করুন। নেটওয়ার্ক Lambda ফাংশন এবং DynamoDB এর মধ্যে যোগাযোগ করতে সাহায্য করবে।
$ docker network create lambda-local --docker-network lambda-local
DynamoDB লোকাল AWS দ্বারা প্রদত্ত DynamoDB এর একটি স্থানীয় সংস্করণ, যা আমরা স্থানীয়ভাবে পরীক্ষা করতে ব্যবহার করতে পারি। নিম্নলিখিত ডকার ইমেজটি চালিয়ে DynamoDB লোকাল চালান:
$ docker run -p 8000:8000 --network lambda-local --name dynamodb amazon/dynamodb-local
user.rb-এ নিম্নলিখিত লাইনটি যোগ করুন ফাইল এটি ল্যাম্বডাকে স্থানীয় DynamoDB এর সাথে সংযুক্ত করবে:
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'http://dynamodb:8000'
)
UsersTable.configure_client(client: local_client)
একটি input.json যোগ করুন ফাইল, যা ল্যাম্বডা:
{
"name": "Milap Neupane",
"location": "Global"
}
ল্যাম্বডা কার্যকর করার আগে, আমাদের স্থানীয় ডায়নামোডিবিতে টেবিলটি যুক্ত করতে হবে। এটি করার জন্য, আমরা aws-migrate দ্বারা প্রদত্ত মাইগ্রেশন কার্যকারিতা ব্যবহার করব। আসুন migrate.rb ফাইল তৈরি করি এবং নিম্নলিখিত মাইগ্রেশন যোগ করি:
require 'aws-record'
require './users.rb'
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'http://localhost:8000'
)
migration = Aws::Record::TableMigration.new(UsersTable, client: local_client)
migration.create!(
provisioned_throughput: {
read_capacity_units: 5,
write_capacity_units: 5
}
)
migration.wait_until_available
অবশেষে, নিম্নলিখিত কমান্ডটি ব্যবহার করে স্থানীয়ভাবে ল্যাম্বডা চালান:
$ sam local invoke "CreateUserFunction" -t sam.yaml \
-e input.json \
--docker-network lambda-local
এটি DynamoDB টেবিলে ব্যবহারকারীর ডেটা তৈরি করবে।
স্থানীয়ভাবে AWS স্ট্যাক চালানোর জন্য লোকালস্ট্যাকের মতো বিকল্প রয়েছে।
কখন সার্ভারহীন কম্পিউটিং ব্যবহার করা উচিত
সার্ভারহীন কম্পিউটিং ব্যবহার করার সিদ্ধান্ত নেওয়ার সময়, আমাদের এর সুবিধা এবং ত্রুটি উভয়ই সম্পর্কে সচেতন হতে হবে। নিম্নলিখিত বৈশিষ্ট্যগুলির উপর ভিত্তি করে, আমরা কখন সার্ভারহীন পদ্ধতি ব্যবহার করব তা নির্ধারণ করতে পারি:
খরচ
- অ্যাপ্লিকেশানের অলস সময় এবং অসামঞ্জস্যপূর্ণ ট্রাফিক থাকলে, ল্যাম্বডাস ভাল কারণ তারা খরচ কমাতে সাহায্য করে।
- যখন অ্যাপ্লিকেশনটির একটি ধারাবাহিক ট্রাফিক ভলিউম থাকে, তখন AWS Lambda ব্যবহার করা ব্যয়বহুল হতে পারে।
কর্মক্ষমতা
- অ্যাপ্লিকেশানটি কর্মক্ষমতা-সংবেদনশীল না হলে, AWS Lambda ব্যবহার করা একটি ভাল পছন্দ।
- ল্যাম্বডাসের কোল্ড বুট টাইম থাকে, যা কোল্ড বুটের সময় ধীর প্রতিক্রিয়ার কারণ হতে পারে।
পটভূমি প্রক্রিয়াকরণ
- ব্যাকগ্রাউন্ড প্রসেসিংয়ের জন্য ল্যাম্বডা একটি ভালো পছন্দ। কিছু ওপেন সোর্স টুল, যেমন Sidekiq, সার্ভার স্কেলিং এবং রক্ষণাবেক্ষণ ওভারহেড আছে। আমরা সার্ভার রক্ষণাবেক্ষণের ঝামেলা ছাড়াই ব্যাকগ্রাউন্ড জব প্রক্রিয়া করার জন্য AWS Lambda এবং AWS SQS সারি একত্রিত করতে পারি।
সমসাময়িক প্রক্রিয়াকরণ
- যেমন আমরা জানি, রুবিতে একত্রিত হওয়া এমন কিছু নয় যা আমরা সহজে করতে পারি। ল্যাম্বডার সাথে, আমরা প্রোগ্রামিং ভাষা সমর্থনের প্রয়োজন ছাড়াই একত্রিততা অর্জন করতে পারি। Lambda একযোগে কার্যকর করা যেতে পারে এবং কর্মক্ষমতা উন্নত করতে সাহায্য করে।
পর্যায়ক্রমিক বা এক-কালীন স্ক্রিপ্ট চলছে
- রুবি কোডগুলি চালানোর জন্য আমরা ক্রন জব ব্যবহার করি, কিন্তু বড় আকারের অ্যাপ্লিকেশনগুলির জন্য ক্রন কাজের জন্য সার্ভার রক্ষণাবেক্ষণ কঠিন হতে পারে। ইভেন্ট-ভিত্তিক ল্যাম্বডাস ব্যবহার করা অ্যাপ্লিকেশন স্কেলিং করতে সাহায্য করে।
সার্ভারহীন অ্যাপ্লিকেশনগুলিতে ল্যাম্বডা ফাংশনের জন্য এইগুলি কিছু ব্যবহারের ক্ষেত্রে। আমাদের সবকিছু সার্ভারহীন তৈরি করতে হবে না; আমরা উপরোক্ত-নির্দিষ্ট ব্যবহারের ক্ষেত্রে একটি হাইব্রিড মডেল তৈরি করতে পারি। এটি অ্যাপ্লিকেশনগুলিকে স্কেলিং করতে সহায়তা করে এবং বিকাশকারীদের উত্পাদনশীলতা বাড়ায়। সার্ভারহীন প্রযুক্তি বিকশিত হচ্ছে এবং উন্নত হচ্ছে। অন্যান্য সার্ভারহীন প্রযুক্তি রয়েছে, যেমন AWS Fatgate এবং Google CloudRun, যেগুলিতে AWS Lambda-এর সীমাবদ্ধতা নেই৷
